K-means之matlab实现
引入
作为练手,不妨用matlab实现K-means
要解决的问题:n个D维数据进行聚类(无监督),找到合适的簇心。
这里仅考虑最简单的情况,数据维度D=2,预先知道簇心数目K(K=4)
理论步骤
关键步骤:
(1)根据K个簇心(clusters,下标从1到K),确定每个样本数据Di(D为所有数据整体,Di为某个数据,i=1...n)所属簇,即欧氏距离最近的那个。
簇心编号:
c_i = arg min_{j} {D_i - clusters_j}, 即使得欧氏距离最近的那个j
(2) 更新簇心:所属簇编号c_i相同的样本数据D_i的元素们,用他们均值来替代原有簇心(D维向量均值)
代码
% my_kmeans
% By Chris, zchrissirhcz@gmail.com
% 2016年9月30日 19:13:43
% 簇心数目k
K = 4;
% 准备数据,假设是2维的,80条数据,从data.txt中读取
%data = zeros(100, 2);
load 'data.txt'; % 直接存储到data变量中
x = data(:,1);
y = data(:,2);
% 绘制数据,2维散点图
% x,y: 要绘制的数据点 20:散点大小相同,均为20 'blue':散点颜色为蓝色
s = scatter(x, y, 20, 'blue');
title('原始数据:蓝圈;初始簇心:红点');
% 初始化簇心
sample_num = size(data, 1); % 样本数量
sample_dimension = size(data, 2); % 每个样本特征维度
% 暂且手动指定簇心初始位置
clusters = zeros(K, sample_dimension);
clusters(1,:) = [-3,1];
clusters(2,:) = [2,4];
clusters(3,:) = [-1,-0.5];
clusters(4,:) = [2,-3];
hold on; % 在上次绘图(散点图)基础上,准备下次绘图
% 绘制初始簇心
scatter(clusters(:,1), clusters(:,2), 'red', 'filled'); % 实心圆点,表示簇心初始位置
c = zeros(sample_num, 1); % 每个样本所属簇的编号
PRECISION = 0.0001;
iter = 100; % 假定最多迭代100次
for i=1:iter
% 遍历所有样本数据,确定所属簇。公式1
for j=1:sample_num
%t = arrayfun(@(item) item
%[min_val, idx] = min(t);
gg = repmat(data(j,:), K, 1);
gg = gg - clusters; % norm:计算向量模长
tt = arrayfun(@(n) norm(gg(n,:)), (1:K)');
[minVal, minIdx] = min(tt);
% data(j,:)的所属簇心,编号为minIdx
c(j) = minIdx;
end
% 遍历所有样本数据,更新簇心。公式2
convergence = 1;
for j=1:K
up = 0;
down = 0;
for k=1:sample_num
up = up + (c(k)==j) * data(k,:);
down = down + (c(k)==j);
end
new_cluster = up/down;
delta = clusters(j,:) - new_cluster;
if (norm(delta) > PRECISION)
convergence = 0;
end
clusters(j,:) = new_cluster;
end
figure;
f = scatter(x, y, 20, 'blue');
hold on;
scatter(clusters(:,1), clusters(:,2), 'filled'); % 实心圆点,表示簇心初始位置
title(['第', num2str(i), '次迭代']);
if (convergence)
disp(['收敛于第', num2str(i), '次迭代']);
break;
end
end
disp('done');
使用到的数据(data.txt)
1.658985 4.285136
-3.453687 3.424321
4.838138 -1.151539
-5.379713 -3.362104
0.972564 2.924086
-3.567919 1.531611
0.450614 -3.302219
-3.487105 -1.724432
2.668759 1.594842
-3.156485 3.191137
3.165506 -3.999838
-2.786837 -3.099354
4.208187 2.984927
-2.123337 2.943366
0.704199 -0.479481
-0.392370 -3.963704
2.831667 1.574018
-0.790153 3.343144
2.943496 -3.357075
-3.195883 -2.283926
2.336445 2.875106
-1.786345 2.554248
2.190101 -1.906020
-3.403367 -2.778288
1.778124 3.880832
-1.688346 2.230267
2.592976 -2.054368
-4.007257 -3.207066
2.257734 3.387564
-2.679011 0.785119
0.939512 -4.023563
-3.674424 -2.261084
2.046259 2.735279
-3.189470 1.780269
4.372646 -0.822248
-2.579316 -3.497576
1.889034 5.190400
-0.798747 2.185588
2.836520 -2.658556
-3.837877 -3.253815
2.096701 3.886007
-2.709034 2.923887
3.367037 -3.184789
-2.121479 -4.232586
2.329546 3.179764
-3.284816 3.273099
3.091414 -3.815232
-3.762093 -2.432191
3.542056 2.778832
-1.736822 4.241041
2.127073 -2.983680
-4.323818 -3.938116
3.792121 5.135768
-4.786473 3.358547
2.624081 -3.260715
-4.009299 -2.978115
2.493525 1.963710
-2.513661 2.642162
1.864375 -3.176309
-3.171184 -3.572452
2.894220 2.489128
-2.562539 2.884438
3.491078 -3.947487
-2.565729 -2.012114
3.332948 3.983102
-1.616805 3.573188
2.280615 -2.559444
-2.651229 -3.103198
2.321395 3.154987
-1.685703 2.939697
3.031012 -3.620252
-4.599622 -2.185829
4.196223 1.126677
-2.133863 3.093686
4.668892 -2.562705
-2.793241 -2.149706
2.884105 3.043438
-2.967647 2.848696
4.479332 -1.764772
-4.905566 -2.911070
运行结果

缺点
非常naive的kmeans,对于K个簇心初始位置非常敏感,有时候会产生dead point,即有些簇心被孤立而没有样本数据归属它。
第一次改进:簇心向量的每个维度,在样本数据的各自维度的最小值和最大值之间取值
clusters = zeros(K, sample_dimension);
minVal = min(data); % 各维度计算最小值
maxVal = max(data); % 各维度计算最大值
for i=1:K
clusters(i, :) = minVal + (maxVal - minVal) * rand();
end
效果:
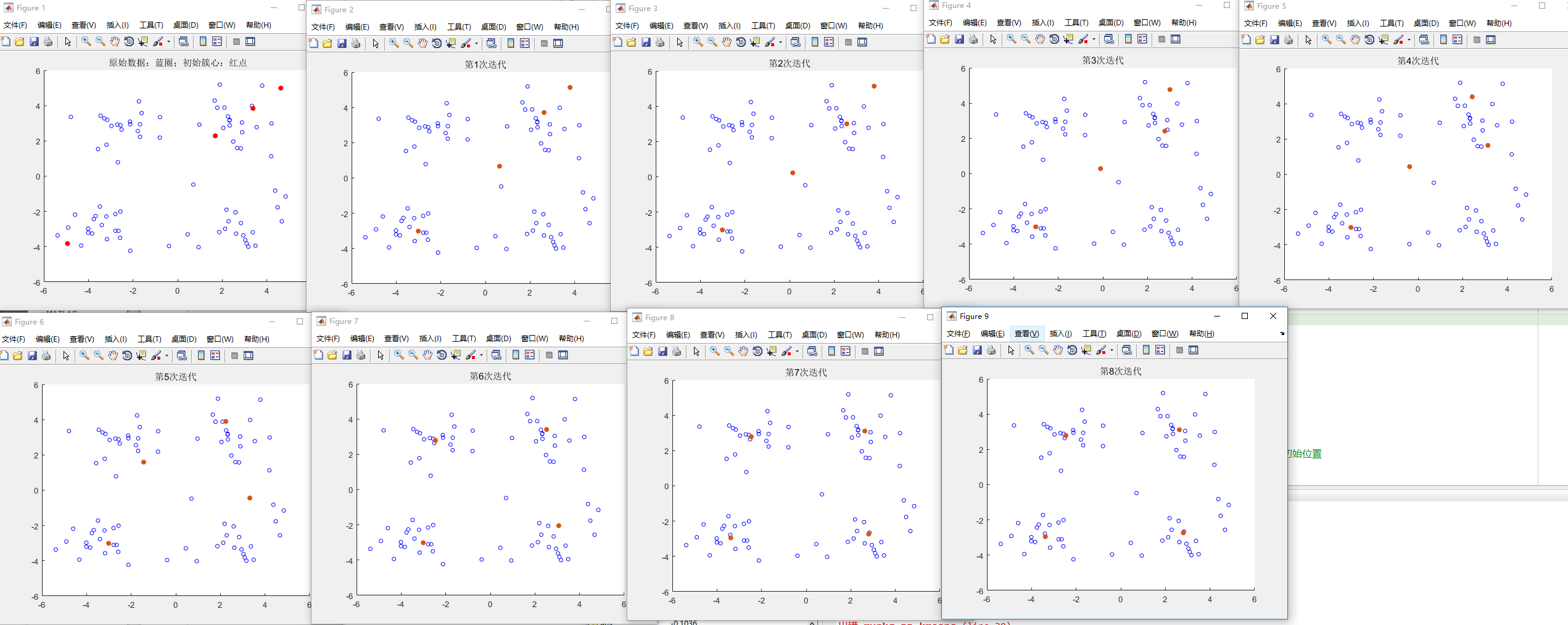
第二次改进:在线K-means,使用随机梯度下降SGD替代批量梯度下降BGD
思路是,每次仅仅取出一个样本数据x_i,找出离他最近的簇心cluster_j,并把簇心往x_i的方向拉。这替代了原来使用“所有的、类别编号为c_j的样本,算出一个均值,作为新簇心”策略.
同时考虑到收敛速度,每次将“最近的簇心”向数据项“拉取”的时候,乘以一个学习率eta,eta最好是随着迭代次数增加而有所减小,即迭代次数t的减函数。此处代码实现中使用倒数(eta = basic_eta/i),你也可以用更精致的函数替代。
参考代码:
% 簇心数目k
K = 4;
% 准备数据,假设是2维的,80条数据,从data.txt中读取
%data = zeros(100, 2);
load 'data.txt'; % 直接存储到data变量中
x = data(:,1);
y = data(:,2);
% 绘制数据,2维散点图
% x,y: 要绘制的数据点 20:散点大小相同,均为20 'blue':散点颜色为蓝色
s = scatter(x, y, 20, 'blue');
title('原始数据:蓝圈;初始簇心:红点');
% 初始化簇心
sample_num = size(data, 1); % 样本数量
sample_dimension = size(data, 2); % 每个样本特征维度
% 暂且手动指定簇心初始位置
% clusters = zeros(K, sample_dimension);
% clusters(1,:) = [-3,1];
% clusters(2,:) = [2,4];
% clusters(3,:) = [-1,-0.5];
% clusters(4,:) = [2,-3];
% 簇心赋初值:计算所有数据的均值,并将一些小随机向量加到均值上
clusters = zeros(K, sample_dimension);
minVal = min(data); % 各维度计算最小值
maxVal = max(data); % 各维度计算最大值
for i=1:K
clusters(i, :) = minVal + (maxVal - minVal) * rand();
end
hold on; % 在上次绘图(散点图)基础上,准备下次绘图
% 绘制初始簇心
scatter(clusters(:,1), clusters(:,2), 'red', 'filled'); % 实心圆点,表示簇心初始位置
c = zeros(sample_num, 1); % 每个样本所属簇的编号
PRECISION = 0.001;
iter = 100; % 假定最多迭代100次
% Stochastic Gradient Descendant 随机梯度下降(SGD)的K-means,也就是Competitive Learning版本
basic_eta = 0.1; % learning rate
for i=1:iter
pre_acc_err = 0; % 上一次迭代中,累计误差
acc_err = 0; % 累计误差
for j=1:sample_num
x_j = data(j, :); % 取得第j个样本数据,这里体现了stochastic性质
% 所有簇心和x计算距离,找到最近的一个(比较簇心到x的模长)
gg = repmat(x_j, K, 1);
gg = gg - clusters;
tt = arrayfun(@(n) norm(gg(n,:)), (1:K)');
[minVal, minIdx] = min(tt);
% 更新簇心:把最近的簇心(winner)向数据x拉动。 eta为学习率.
eta = basic_eta/i;
delta = eta*(x_j-clusters(minIdx,:));
clusters(minIdx,:) = clusters(minIdx,:) + delta;
acc_err = acc_err + norm(delta);
end
if(rem(i,10) ~= 0)
continue
end
figure;
f = scatter(x, y, 20, 'blue');
hold on;
scatter(clusters(:,1), clusters(:,2), 'filled'); % 实心圆点,表示簇心初始位置
title(['第', num2str(i), '次迭代']);
if (abs(acc_err-pre_acc_err) < PRECISION)
disp(['收敛于第', num2str(i), '次迭代']);
break;
end
disp(['累计误差:', num2str(abs(acc_err-pre_acc_err))]);
pre_acc_err = acc_err;
end
disp('done');
因为学习率eta选得比较随意,以及收敛条件的判断也比较随意,收敛效果只能说还凑合,运行结果:

K-means之matlab实现的更多相关文章
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 软件——机器学习与Python,聚类,K——means
K-means是一种聚类算法: 这里运用k-means进行31个城市的分类 城市的数据保存在city.txt文件中,内容如下: BJ,2959.19,730.79,749.41,513.34,467. ...
- 快速查找无序数组中的第K大数?
1.题目分析: 查找无序数组中的第K大数,直观感觉便是先排好序再找到下标为K-1的元素,时间复杂度O(NlgN).在此,我们想探索是否存在时间复杂度 < O(NlgN),而且近似等于O(N)的高 ...
- 利用matlab编写实现显示fmri切片slice图像 混合显示 不同侧面显示 可叠加t检验图显示 by DR. Rajeev Raizada
1.参考 reference 1. tutorial主页:http://www.bcs.rochester.edu/people/raizada/fmri-matlab.htm. 2.speech_b ...
- matlab中常用见的小知识点
矩阵相关: 在matlab中,矩阵或向量是 column-major 表示形式.用 [] 来构建向量或矩阵, 用()来引用向量或矩阵中的元素:用:表示矩阵中的该index下的所以元素: matlab中 ...
- 网络费用流-最小k路径覆盖
多校联赛第一场(hdu4862) Jump Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- numpy.ones_like(a, dtype=None, order='K', subok=True)返回和原矩阵一样形状的1矩阵
Return an array of ones with the same shape and type as a given array. Parameters: a : array_like Th ...
- Torch7学习笔记(二)nn Package
神经网络Package [目前还属于草稿版,等我整个学习玩以后会重新整理] 模块Module module定义了训练神经网络需要的所有基础方法,并且是可以序列化的抽象类. module有两种状态变量: ...
- [C6] Andrew Ng - Convolutional Neural Networks
About this Course This course will teach you how to build convolutional neural networks and apply it ...
- [C2P3] Andrew Ng - Machine Learning
##Advice for Applying Machine Learning Applying machine learning in practice is not always straightf ...
随机推荐
- php的一些小细节
1.今天看见 $arr3 = array_filter($arr, create_function('$v', 'return strlen($v);')); 作用就是去掉为空的元素,其实当callb ...
- Xcode里-ObjC, -all_load, -force_load
最近在做一个项目的时候,需要使用到一个第三方库,这个库的使用向导里面特别说明,在添加完该库后,需要在Xcode的Build Settings下Other Linker Flags里面加入-ObjC标志 ...
- ios更新UI时请尝试使用performSelectorOnMainThread方法
最近开发项目时发现联网获取到数据后,使用通知方式让列表刷新会存在死机的问题. 经过上网查找很多文章,都建议使用异步更新的方式,可是依然崩溃. 最后尝试使用performSelectorOnMainTh ...
- Construct Binary Tree from Inorder and Postorder Traversal
Construct Binary Tree from Inorder and Postorder Traversal Given inorder and postorder traversal of ...
- node基础04:模块调用
1.模块调用 node遵循AMD规范 //server.js var http = require("http"); var Teacher = require("./t ...
- 如何获取Flickr图片链接地址作为外链图片
Flickr,雅虎旗下图片分享网站.为一家提供免费及付费数位照片储存.分享方案之线上服务,也提供网络社群服务的平台.其重要特点就是基于社会网络的人际关系的拓展与内容的组织.这个网站的功能之强大,已超出 ...
- Struts2 动态结果和带参数的跳转
完整代码:Struts16ActionResultsDemo.rar 1.动态结果. 有时我们需要在Action里取得我个要转跳的页面 看一下我们的struts.xml <?xml versio ...
- 基于DDD的.NET开发框架 - ABP的Entity设计思想
返回ABP系列 ABP是“ASP.NET Boilerplate Project (ASP.NET样板项目)”的简称. ASP.NET Boilerplate是一个用最佳实践和流行技术开发现代WEB应 ...
- Linux vmstat命令实战详解
vmstat命令是最常见的Linux/Unix监控工具,可以展现给定时间间隔的服务器的状态值,包括服务器的CPU使用率,内存使用,虚拟内存交换情况,IO读写情况.这个命令是我查看Linux/Unix最 ...
- HTC Vive 与Leap Motion 出现位置错误的问题
Leap Motion已经支持VR, 但是官方没有支持HTC Vive的例子. 按照官方的文档, 其实是有问题的: https://developer.leapmotion.com/documenta ...