HA 高可用软件系统保养指南

又过了一年 618,六月是公司一年一度的大促月,一般提前一个月各系统就会减少需求和功能的开发,转而更多去关注系统可用性、稳定性和管控性等方面的非功能需求。大促前的准备工作一般叫作「备战」,可以把线上运行系统想象成一辆车,大促即是它即将面临的一次严峻驾驶考验。
每次去长途自驾旅行时,我会把车送去对车况做一个全面的检测。汽车工业的历史有一百多年了,而车的构造组成部件又相对固定,已经形成了规范且全面的检查事项,我在保养检查手册上看到的检查项目包括:
- 轮胎
- 刹车
- 灯光
- 电瓶
- 油液
- 雨刷
- 底盘
- 电路
- 滤清器
- 随车工具
上面简单列了每一个检查大项,而里面又包括一些细节的小项。当技师按这个检查项目列表执行一遍后没有发现问题,就是得出车况良好的结论。然而软件系统的组成部件并不像汽车那样固定,不同的软件系统可能千差万别,这方面有点像「人」的特性,每个人是不同的,但又是有共性的,所以医学才能为人建立共同的检测标准,但又需要考虑差异化并针对个体建立健康档案,这样才能根据检测结果作出相对准确的诊断。
结合这次 618 备战准备,考虑系统的共性和个性,我想尝试看看能不能抽象出一个针对此类商业在线应用所需的高可用系统保养指南,按此对系统做一个全面地检测后得到对系统运行的一个整体性认识,帮助更好的诊断系统可能潜藏的问题,以便做出及时的优化改进。
检测
我们先从检测开始。
资源
系统应用运行总是需要依托于硬件物理资源,操作系统提供了一些基本的资源使用消耗情况,包括:
- CPU
- 内存
- 磁盘
- 网络
操作系统提供的仅仅是单机的资源使用情况,而在一个分布式系统中我们通常需要更高维度的资源使用报告,按集群,按应用等,所以这需要我们自己去做在单机粒度上的聚合和可视化呈现。
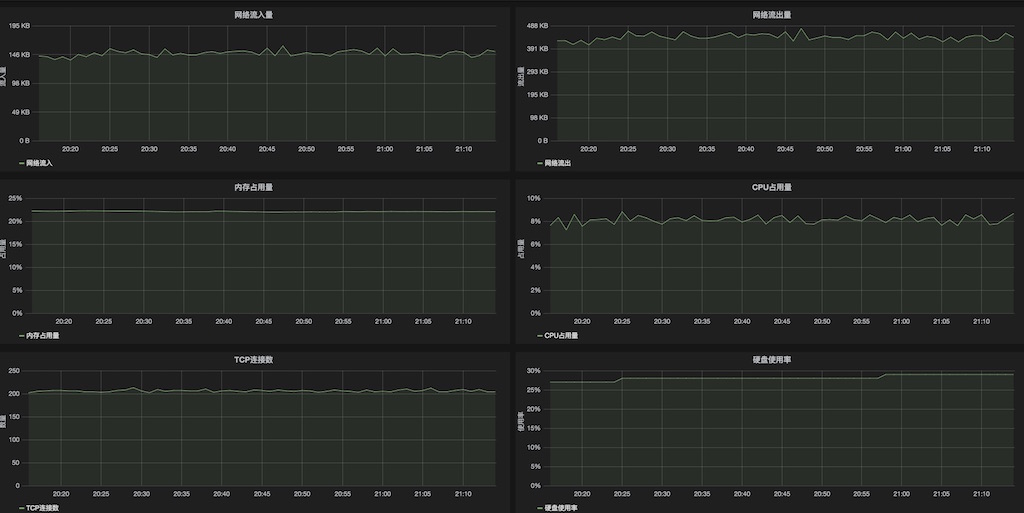
CPU 除了机器整体使用情况,最好能监测到进程级的使用,若一个进程内的 CPU 消耗明显不正常,需要有捕捉到进程内线程 CPU 使用的方法。内存以 Java 应用为例,会更多关心 JVM 内部的内存使用和 GC 情况;而类似 Redis 这样的内存数据库则更多关注其内存的增长趋势。磁盘 I/O 是存储类应用(SQL/NoSQL 数据库)关注的重点,而对于大部分服务类应用一般只会打打日志,只关心磁盘存储容量的消耗。网络,站在应用的角度主要关心可靠性(丢包率、延时)、带宽和连接数。
应用
由于应用的形式千差万别,我们先看共性的方面。共有的方面主要包括:
- 服务 Performance 性能指标。
比如 API 的每秒调用量(TPS),处理延时(TP99,TP=Time Percentage),可用率(系统成功执行次数占比) - 服务 SLA 满足率。
SLA 是 Service Level Agreement(服务等级协议)的缩写,通过静态评估得到要承接预期量的用户数时,各应用服务需要保证的并 - 服务 HA 可用率。
服务是否业务强制需要?可用率要求有多高,必要情况下是否可降级? - 服务 Isolation 隔离性。
轻、重处理业务流程如何隔离?同、异步业务流程如何隔离?重要、次要的业务间如何隔离? - 服务 Extension 扩展性。
无状态服务理论上可以无限横向扩展,但实际大部分无状态服务仅仅是把状态外移到类似缓存和数据库中,横向的扩展瓶颈点就转移到了缓存或数据库的横向扩展能力上。
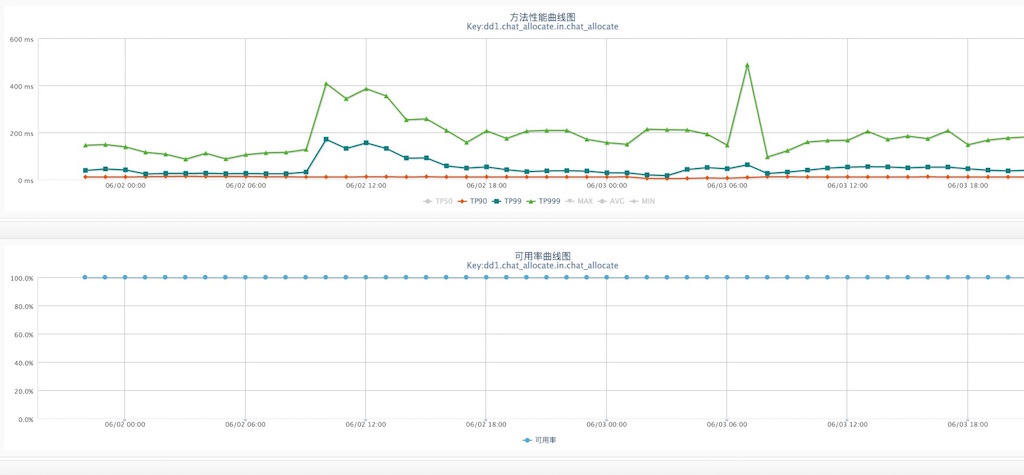
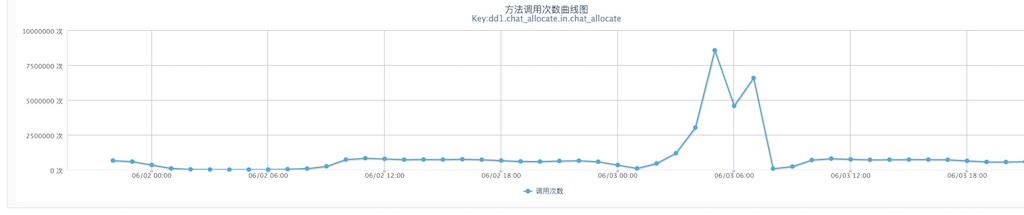
上面属于在应用层能抽象出的共性点,但对于具体的业务逻辑则属于个性的地方,这就需要具体问题具体分析。比如,若实现采用了类似像异步内存队列的方式,是否可以显性化监测?但若想通过代码巡检来发现这样的个性化场景,投入产出比低,也不太现实。所以,今年 618 我们采用了针对主要业务流程的梳理问答方式,主要用于重新思考代码实现流程,发现一些潜在逻辑炸弹。所谓逻辑炸弹,就是在正常时一切良好,但遇到某些边界条件可能导致系统性能急剧下降甚至宕机,在今年的备战中确实发现了两枚这样的逻辑炸弹,幸甚。
依赖
应用系统运行除了依托的环境,还会有对其他应用或数据库、缓存、消息队列等这些基础服务的依赖。每种依赖都需要单独去分析依赖的强弱、可替代性,并提供其可用率、性能等基本监控指标,为诊断提供依据。
强依赖的高可用通常使用主、备方案,而弱依赖除了主、备还可以在特定情况下通过解除依赖实现业务降级,这有点像壁虎断尾求生的场景。
收集
前面从资源、应用、依赖三个大类来全面检测评估系统,但检测是需要数据收集支持的。而以上三类检测项目的数据来源都不一样,在一个大型的分布式环境下就需要将其整合汇总提供面向更高层次的抽象视图。
收集的方式无外乎两种:
- Agent 采集上报
- 应用主动上报
对于系统资源和一些使用的开源软件,一般都是 Agent 采集上报到中心服务器,而自研的应用多采用主动上报方式的,最后在中心监控平台上提供抽象视图呈现。如下图,一个针对 Redis 集群的数据收集整合视图,视图最高按集群提供整体数据监视,若有异常可下钻到具体集群中某一台机器上。
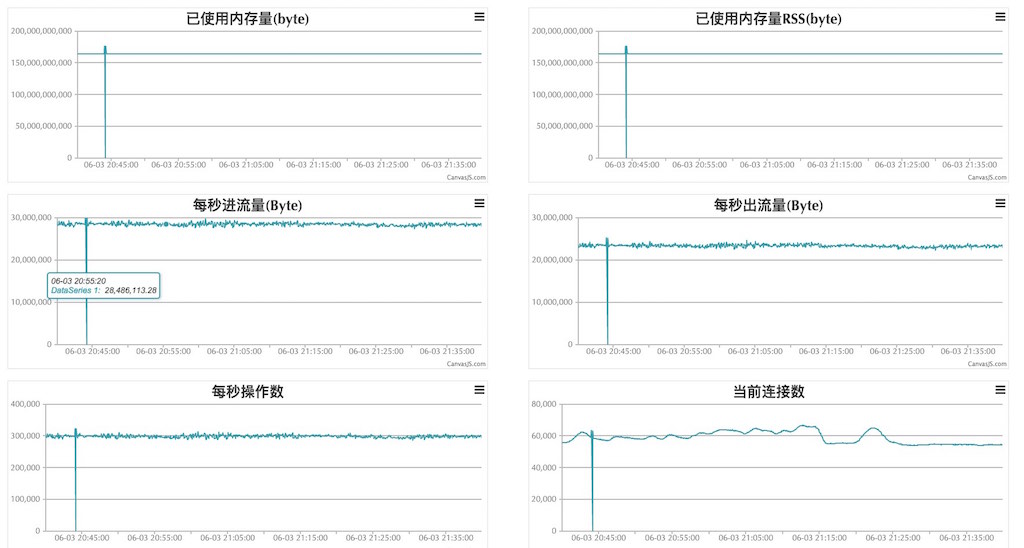
告警
监测数据收集上来后,如何去分析、预警这是一个乍一看简单实际很不简单的事情。
当汽车没油了就会亮一个灯提醒你加油,胎压不足了再亮另外一个灯提醒你加气,总之汽车的保养手册上画了一大堆指示灯提醒或警示你不同的注意事项,简单直接明了。但我们前面说了软件系统更像一个人,每年我去医院体检,一共几十项大小检查,总有那么几项指标数字不正常,医生有时也没法简单根据一两项指标异常就能开出正确的诊断处方。
目前的通用监控预警系统一般只能根据收集的各类系统指标,设定一个合理范围,若偏离合理范围则发出告警。此类一一映射式的告警,仅仅完成了最初阶段的任务,提醒研发去及时响应。这里面存在的问题就是,当在一个大规模分布式应用系统中,若有一个核心系统出现问题,很可能引发连锁反应,导致告警风暴产生。在这样的风暴中,研发有时也是抓瞎,到处都在喊着火,人人手上都有一个灭火器,却不是知道该往哪里喷。这种情况一方面只能自己做好系统防火隔离带,另一方面就是增强报警分析诊断。
在应激式报警的基础上,增加分析和诊断逻辑,形成针对应用系统特有的分级诊断式告警。这种告警是一般通用监控预警系统做不了的,而需要应用系统自己在通用数据收集和告警的基础上来做。可惜的是这目前还只是一个设想,但方向我感觉是没错的。
预案
预案就是假如某意外事件发生那么我们就执行某个措施,将意外造成的损失减至最低,迅速恢复系统运行。这是建立在能快速诊断的基础上。前面告警一节说了,若没有针对应用特有的分级诊断式告警,后续的分析、决策是很耗时的,很难达到快速恢复系统的预期目标。
把针对应用日常运营的常见问题归类并做到告警、分析、决策和预案执行程序化后,才有可能真正真正满足 4 个 9 或以上的系统可用性。
...
最后总结下,一份高可用系统的的保养指南包括下面四个方面:
- 检测
- 收集
- 告警
- 预案
最终要做的就是把这四件事都做成程序化、系统化和自动化的,其中唯一需要人工参与的,我认为只有代码分析一项,这也是程序员的最大价值所在。经历了本次 618 后,我们还才完成了一半多点,只是半自动化,路漫漫其修远兮。
以前忙于业务开发,每到大促都是停下或减缓业务需求来还真正的技术负债,记得好像谁说过这样一句话:
研发水平的体现在于工具的打造和使用。
后面,我想应该需要继续做下去的就是不断打磨工具,让工具可以无人值守的随时为系统做好保驾护航。
写点程序世间的文字,画点生活瞬间的画儿。
微信公众号「瞬息之间」,遇见了不妨就关注看看。

HA 高可用软件系统保养指南的更多相关文章
- CentOS7+Hadoop2.7.2(HA高可用+Federation联邦)+Hive1.2.1+Spark2.1.0 完全分布式集群安装
1 2 2.1 2.2 2.3 2.4 2.5 2.6 2.7 2.8 2.9 2.9.1 2.9.2 2.9.2.1 2.9.2.2 2.9.3 2.9.3.1 2.9.3.2 2.9.3.3 2. ...
- HA高可用的搭建
HA 即 (high available)高可用,又被叫做双机热备,用于关键性业务. 简单理解就是,有两台机器A和B,正常是A提供服务,B待命闲置,当A宕机或服务宕掉,会切换至B机器继续提供服务.常用 ...
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- hadoop 集群HA高可用搭建以及问题解决方案
hadoop 集群HA高可用搭建 目录大纲 1. hadoop HA原理 2. hadoop HA特点 3. Zookeeper 配置 4. 安装Hadoop集群 5. Hadoop HA配置 搭建环 ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- 大数据Hadoop的HA高可用架构集群部署
1 概述 在Hadoop 2.0.0之前,一个Hadoop集群只有一个NameNode,那么NameNode就会存在单点故障的问题,幸运的是Hadoop 2.0.0之后解决了这个问题,即支持N ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
随机推荐
- jQuery UI resizable使用注意事项、实时等比例拉伸及你不知道的技巧
这篇文章总结的是我在使用resizable插件的过程中,遇到的问题及变通应用的奇思妙想. 一.resizable使用注意事项 以下是我在jsfiddle上写的测试demo:http://jsfiddl ...
- 从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点)
从0开始搭建SQL Server AlwaysOn 第四篇(配置异地机房节点) 第一篇http://www.cnblogs.com/lyhabc/p/4678330.html第二篇http://www ...
- OpenCASCADE Expression Interpreter by Flex & Bison
OpenCASCADE Expression Interpreter by Flex & Bison eryar@163.com Abstract. OpenCASCADE provide d ...
- [C#] 走进异步编程的世界 - 开始接触 async/await
走进异步编程的世界 - 开始接触 async/await 序 这是学习异步编程的入门篇. 涉及 C# 5.0 引入的 async/await,但在控制台输出示例时经常会采用 C# 6.0 的 $&qu ...
- Xamarin+Prism开发详解三:Visual studio 2017 RC初体验
Visual studio 2017 RC出来一段时间了,最近有时间就想安装试试,随带分享一下安装使用体验. 1,卸载visual studio 2015 虽然可以同时安装visual studio ...
- 使用RequireJS并实现一个自己的模块加载器 (一)
RequireJS & SeaJS 在 模块化开发 开发以前,都是直接在页面上引入 script 标签来引用脚本的,当项目变得比较复杂,就会带来很多问题. JS项目中的依赖只有通过引入JS的顺 ...
- spring的BeanFactory加载过程
ApplicationContext spring = new ClassPathXmlApplicationContext("classpath*:spring/applicationCo ...
- 页面布局class常见命名规范
头:header 内容:content/container 尾:footer 导航:nav 侧栏:sidebar 栏目:column 页面外围控制整体布局宽度:wrapper 左右中:left rig ...
- [OC] NSURLSession
有的程序员老了,还没听过NSURLSession 有的程序员还嫩,没用过NSURLConnection 有的程序员很单纯,他只知道AFN. NSURLConnection在iOS9被宣布弃用,NSUR ...
- java.lang.NoSuchFieldError: org.apache.http.message.BasicLineFormatter.INSTANCE
Android发出HTTP请求时出现了这个错误: java.lang.NoSuchFieldError: org.apache.http.message.BasicLineFormatter.INST ...