构建Spark的Eclipse开发环境
前言
无论Windows 或Linux 操作系统,构建Spark 开发环境的思路一致,基于Eclipse 或Idea,通过Java、Scala 或Python 语言进行开发。安装之前需要提前准备好JDK、Scala 或Python 环境,然后在Eclipse 中下载安装Scala 或Python 插件(Spark支持Java、Python等语言)。基本步骤如下:
第一步:安装JDK
第二步:安装Scala
第三步: 配置Spark环境变量
第四步:安装Hadoop工具包
第五步:安装Eclipse
第六步:安装Eclipse Scala IDE插件
第一步:安装JDK
(1)下载JDK(1.7以上版本)
下载地址:http://www.oracle.com/technetwork/java/javase/downloads/index.html
(2)配置环境变量(以Windows为例)
新增JAVA_HOME 变量,值:C:\Program Files\Java\jdk1.7.0_71
新增CLASSPATH 变量,值:.;%JAVA_HOME%\lib
增加PATH 变量,补充:;%JAVA_HOME%\bin
进入cmd 界面测试JDK 是否安装成功:
C:\Users\admin>java -version
java version "1.7.0_71"
Java(TM) SE Runtime Environment (build 1.7.0_71-b14)
第二步:安装Scala
(1)下载Scala(下载 Scala 包)
下载地址(Scala 主页):http://www.scala-lang.org/download/(Scala 2.9.3版本可以直接点击该地址下载:Scala 2.9.3 下载后直接点击安装即可)
(2)下载完成后解压,增加PATH 变量
比如解压目录是C:\Program Files (x86)\scala,然后将“C:\Program Files (x86)\scala\bin;”加到环境变量path中
进入cmd 界面测试Scala 是否安装成功:
C:\Users\admin>scala
Welcome to Scala version 2.10.5 (Java HotSpot(TM) 64-Bit Server VM, Java 1.7.0_7
Type :help for more information.
第三步: 配置Spark环境变量
(1)下载Spark
下载地址:http://spark.apache.org/downloads.html
下载相应Hadoop对应的版本,比如spark-1.6.2-bin-hadoop2.6.tgz,spark版本是1.6.2,对应的hadoop版本是2.6
(2)下载完成后解压,配置Spark的环境变量(以Windows为例)
新增SPARK_HOME 变量,值:C:\Apache Spark\spark-1.6.2-bin-hadoop2.6
新增SPARK_CLASSPATH 变量,值:;C:\Apache Spark\spark-1.6.2-bin-hadoop2.6\lib\spark-assembly-1.6.2-hadoop2.6.0.jar;
增加PATH变量,补充:;C:\Apache Spark\spark-1.6.2-bin-hadoop2.6\bin
第四步:安装Hadoop工具包
Spark是基于Hadoop之上的,运行过程中会调用相关Hadoop库,如果没配置相关Hadoop运行环境,会提示相关出错信息,虽然也不影响运行。Windows下开发Spark不需要在本地安装Hadoop,但是需要winutils.exe、hadoop.dll等文件。
(1)下载Windows下Hadoop工具包(分为32位和64位的),比如hadoop-2.6.0.tar.gz
下载地址:https://github.com/sdravida/hadoop2.6_Win_x64/tree/master/bin
https://www.barik.net/archive/2015/01/19/172716/
(2)下载完成后解压,配置Hadoop的环境变量(以Windows为例)
在本地新建一个hadoop目录,其中必须包含有bin目录,例如“D:\spark\hadoop-2.6.0\bin”,然后将winutil等文件放在bin目录下
将相关库添加到系统Path变量中:D:\hadoop-2.6.0\bin;同时新建HADOOP_HOME变量,变量值为:D:\hadoop-2.6.0
第五步:安装Eclipse
在官网下载Eclipse,解压缩到本地后直接使用即可。
第六步:安装Eclipse Scala IDE插件
(1)下载Eclipse Scala IDE插件
下载地址:Scala IDE(for Scala 2.9.x and Eclipse Juno)
http://www.scala-lang.org/download/2.7.6.final.html
(2)安装Scala 插件
1.将Eclipse Scala IDE插件中features和plugins两个目录下的所有文件拷贝到Eclipse解压后所对应的目录中。
2.重新启动Eclipse,点击Eclipse右上角方框按钮,如下图所示,展开后点击“Other….”,查看是否有“Scala”一项,若有则可直接点击打开,否则进行下一步操作。

3.在Eclipse中,依次选择“Help” –> “Install New Software…”,在弹出的对话框里填入http://download.scala-ide.org/sdk/e38/scala29/stable/site,并按回车键,可看到以下内容,选择Scala IDE for Eclipse 和Scala IDE for Eclipse development support 即可完成Scala 插件在Eclipse上的安装(由于上一步已经将jar包拷贝到Eclipse中,安装很快,只是疏通一下)。

安装完后,再操作一遍步骤2便可。
使用Java语言进行Spark程序开发
1.新建java工程
2.将Spark开发程序包“spark-assembly-1.6.2-hadoop2.6.0.jar”添加到工程中,作为三方依赖库
使用Java语言进行Spark Standalone模式应用程序开发
1. 创建Maven Project,依次选择File->New->Other->Maven Project

2. 编写Java源程序

/* SimpleApp.java */
import org.apache.spark.api.java.*;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function;
public class SimpleApp {
public static void main(String[] args) {
String logFile = "file:///spark-bin-0.9.1/README.md";
SparkConf conf =new SparkConf().setAppName("Spark Application in Java");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> logData = sc.textFile(logFile).cache();
long numAs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("a"); }
}).count();
long numBs = logData.filter(new Function<String, Boolean>() {
public Boolean call(String s) { return s.contains("b"); }
}).count();
System.out.println("Lines with a: " + numAs +",lines with b: " + numBs);
}
}
3. 修改pom.xml添加依赖包
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.cas.siat.dolphin</groupId>
<artifactId>spark.SimpleApp</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spark.SimpleApp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.0.2</version>
</dependency>
</dependencies>
</project>
4. 编译打包
分别执行Maven clean、Maven install,这样在工程项目下的target目录中会生成项目的jar包,如下图:

5. 运行Spark应用
上传编译好的jar包至spark集群client,执行以下命令运行程序
./spark-submit --class "foo.App" --master spark://172.21.5.235:7077 /home/hadoop121/Dolphin/Spark1.0.2/spark.SimpleApp-0.0.1-SNAPSHOT.jar
6.执行结果

Web UI结果如下:



搭建spark maven项目程序
第一步:创建自己的spark maven项目,勾选create a simple project

第二步:如图,其中Packaging即maven生成的包,这里要选择jar,因为spark程序一般是打包为jar包的

第三步:添加spark的jar包到刚才新建的maven项目的build path中,找到集群安装的spark安装目录,在lib目录下会看到jar包
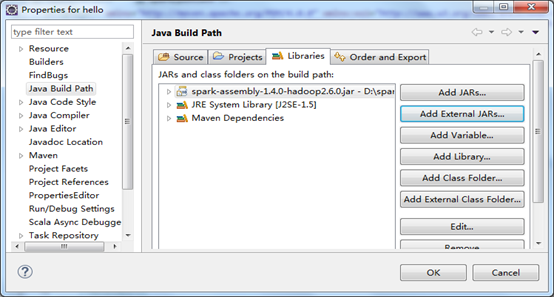
第四步:pom中添加自己的spark、hadoop maven依赖,例如:
第五部:spark程序的入口是main函数,至此可以编写程序代码并运行和调试
构建Spark的Eclipse开发环境的更多相关文章
- 使用Git下载Hadoop的到本地Eclipse开发环境
使用Git下载Hadoop的到本地Eclipse开发环境 博客分类: Hadoop *n*x MacBook Air hadoopgitmaveneclipsejava 问题场景 按照官网http: ...
- 突破瓶颈,对比学习:Eclipse开发环境与VS开发环境的调试对比
曾经看了不少Java和Android的相关知识,不过光看不练易失忆,所以,还是写点文字,除了加强下记忆,也证明我曾经学过~~~ 突破瓶颈,对比学习: 学习一门语言,开发环境很重,对于VS的方形线条开发 ...
- zookeeper Eclipse 开发环境搭建及简单示例
一,下载Zookeeper安装包 从官方网站下载稳定版安装包后,解压. 其中ZK_HOME 为:D:\Program Files\zookeeper-3.4.9 二,启动Zookeeper Serve ...
- 配置Hadoop的Eclipse开发环境
前言 在先前的文章中,已经介绍了如何在Ubuntu Kylin操作系统下搭建Hadoop运行环境,而现在将在之前工作的基础上搭建Eclipse开发环境. 配置 开发环境:Eclipse 4.2 其他同 ...
- [转]MonkeyRunner在Windows下的Eclipse开发环境搭建步骤(兼解决网上Jython配置出错的问题)
MonkeyRunner在Windows下的Eclipse开发环境搭建步骤(兼解决网上Jython配置出错的问题) 网上有一篇shangdong_chu网友写的文章介绍如何在Eclipse上配置M ...
- 大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建
大数据应用之Windows平台Hbase客户端Eclipse开发环境搭建 大数据应用之Windows平台Hbase客户端Eclipse环境搭建-Java版 作者:张子良 版权所有,转载请注明出处 引子 ...
- 配置hadoop-1.2.1 eclipse开发环境
写这篇文章的目的是记录解决配置过程中的问题 首先我们先看下这篇博文 配置hadoop-1.2.1 eclipse开发环境 但是在[修改 Hadoop 源码]这里,作者发布的 hadoop-core-1 ...
- Win10构建Python全栈开发环境With WSL
目录 Win10构建Python全栈开发环境With WSL 启动WSL 总结 对<Dev on Windows with WSL>的补充 Win10构建Python全栈开发环境With ...
- [转] 从零构建 vue2 + vue-router + vuex 开发环境到入门,实现基本的登录退出功能
这是一个创建于 738 天前的主题,其中的信息可能已经有所发展或是发生改变. 前言 vue2 正式版已经发布将近一个月了, 国庆过后就用在了公司的两个正式项目上, 还有一个项目下个月也会采用 vue2 ...
随机推荐
- java.lang.UnsatisfiedLinkError: C:\apache-tomcat-8.0.21\bin\tcnative-1.dll: Can't load IA 32-bit .dll on a AMD 64-bit platform
Tomcat启动报错: 25-Mar-2016 10:40:43.478 SEVERE [main] org.apache.catalina.startup.Catalina.stopServer C ...
- HDFS分布式文件系统资源管理器开发总结
HDFS,全称Hadoop分布式文件系统,作为Hadoop生态技术圈底层的关键技术之一,被设计成适合运行在通用硬件上的分布式文件系统.它和现有的分布式文件系统有很多共同点,但同时,它和其他的分布式 ...
- linux下使用Apache+php实现留言板功能的网站
一.首先我们的linux服务器上要安装Apache和php 请参考:http://www.cnblogs.com/dagege/p/5949620.html 二.关闭防火墙服务,关闭selinux 请 ...
- android中的数据存取-方式一:preference(配置)
这种方式应该是用起来最简单的Android读写外部数据的方法了.他的用法基本上和J2SE(java.util.prefs.Preferences)中的用法一样,以一种简单. 透明的方式来保存一些用户个 ...
- Angular+Flask搭建一个记录工具
平时用的最多的文本编辑器就是Notepad++,很多东西都是通过Notepad++直接记录的: 没有看完的网页链接 要整理.收藏的网页 读书笔记 要处理的事情 待看/看过的文档和电子书 等等... 随 ...
- AWS国际版的Route 53和CloudFront
注册AWS国际版账号后,却发现Route 53和CloudFront功能是无法使用的.于是提交了一个Service Request,得到的答复是这两个功能需要验证后才能激活. 在控制台中点击进入Rou ...
- 准备使用 Office 365 中国版--购买
Office 365中国版支持两种购买方式,Web Direct(在线购买)和CSP(代理商购买).如果客户的企业规模不大(几十个用户,小于100用户)或者是个人/家庭购买,可以直接选择在线购买方式. ...
- 工欲善其事必先利其器——dreamweaver
1.内置了一个webkit内核,所以实时视图与chrome浏览器效果一样. 2.DW中主浏览器的快捷键是f12,所以可以f12快速打开浏览器. 3.DW中首选项无法恢复到默认值. 4.有用首选项 5. ...
- webdriver的工作原理
selenium1的原理就是使用js来驱动浏览器,因为现在基本不用,所以不做过多讨论,下面是我整理的webdriver的工作原理,大致就是通过命令请求webdriver,然后webdriver通过浏览 ...
- Apache http Server 2.4 安装与配置
前言 Apache官网从2.2之后,不再提供windows的msi或exe安装版本,现在Apache http Server有两个分支2.2及2.4 注意事项 如果之前有安装2.2的版本,请先卸载 A ...