一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例
本想抓取网易摄影上的图,但发现查看html源代码时找不到图片的url,但firebug却能定位得到。(不知道为什么???)
目标是抓取前50页的爆乳图,代码如下:
import urllib2,urllib,re,os
'''
http://www.dbmeizi.com/category/2?p=%
'''
def get_url_from_douban():
url_list=[]
p=re.compile(r'''<img.*?src="(.+?\.jpg)''') #找出发布人的标题和url
for i in range(1,50):
target = r"http://www.dbmeizi.com/category/2?p=%d"%i
# print target
req=urllib2.urlopen(target)
result=req.read()
matchs=p.findall(result)
url_list.extend(matchs)
# print matchs
# print "-----"*40
return url_list
def download_pic(url_list):
# print url_lists
count=0
if not os.path.exists('/tmp/pic'):
os.mkdir('/tmp/pic/')
for url in url_list:
urllib.urlretrieve(url,'/tmp/pic/'+str(count)+'.jpg')
count+=1 if __name__=='__main__':
# start_time=time.time()
print "start getting url..."
url_lists=get_url_from_douban()
print "url getted! downloading..."
download_pic(url_lists)
print "download finish!!!"
# cost_time=time.time() - start_time()
# print cost_time
# download_pic(url_lists) ------------------------------------------------------------------------------
/System/Library/Frameworks/Python.framework/Versions/2.7/bin/python /Users/lsf/PycharmProjects/some_subject/get_doubanmeizi_pic.py
start getting url...
url getted! downloading...
download finish!!!
Process finished with exit code 0
运行结果如图:
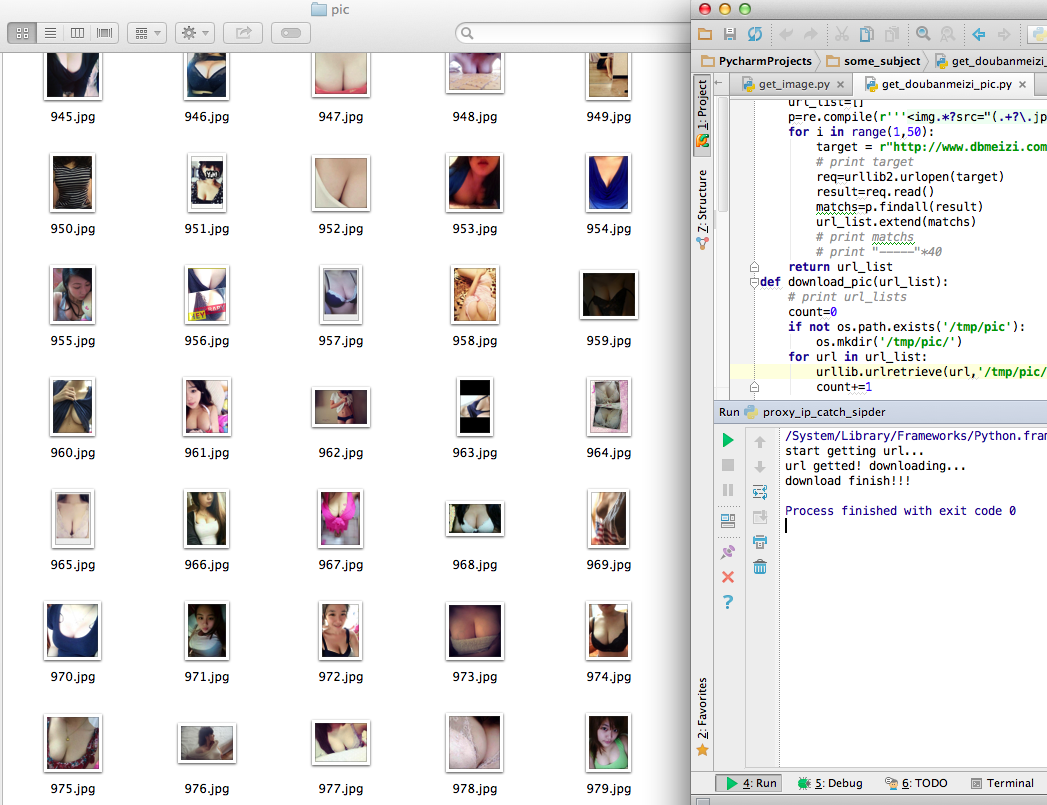
只是一个简单的实现方式,没有考虑性能,速度挺慢的。
ps:贴图会不会被查水表!!??
一个简单的python爬虫,以豆瓣妹子“http://www.dbmeizi.com/category/2?p= ”为例的更多相关文章
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 【Python学习笔记三】一个简单的python爬虫
这里写爬虫用的requests插件 1.一般那3.x版本的python安装后都带有相应的安装文件,目录在python安装目录的Scripts中,如下: 2.将scripts的目录配置到环境变量pa ...
- 一个简单的python爬虫(转)
# -*- coding: utf-8 -*- #--------------------------------------- # 程序:百度贴吧爬虫 # 版本:0.1 # 作者:why # 日期: ...
- 一个简单的Python爬虫
写了一个抓taobao图片的爬虫,全是用if,for,while写的,比较简陋,入门作品. 从网页http://mm.taobao.com/json/request_top_list.htm?type ...
- python实现的一个简单的网页爬虫
学习了下python,看了一个简单的网页爬虫:http://www.cnblogs.com/fnng/p/3576154.html 自己实现了一个简单的网页爬虫,获取豆瓣的最新电影信息. 爬虫主要是获 ...
- Python爬虫(四)——豆瓣数据模型训练与检测
前文参考: Python爬虫(一)——豆瓣下图书信息 Python爬虫(二)——豆瓣图书决策树构建 Python爬虫(三)——对豆瓣图书各模块评论数与评分图形化分析 数据的构建 在这张表中我们可以发现 ...
- 做一个简单的scrapy爬虫
前言: 做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程.我们就抓取扇贝上的单词书,python的高频词汇. 步骤: 一,新建一个工程scrapy_shanbay 二,在工程中中 ...
- 作业1开发一个简单的python计算器
开发一个简单的python计算器 实现加减乘除及拓号优先级解析 用户输入 1 - 2 * ( (60-30 +(-40/5) * (9-2*5/3 + 7 /3*99/4*2998 +10 * 568 ...
随机推荐
- 微信jssdk,实现多图上传的一点心得
一.首先在common.js里封装一个函数,在需要调用jsSDK的页面引用此方法即可实现微信的信息配置function signatureJSSDK() { var url = window.loca ...
- 关于SAP的视图类型
1 sap的视图的类型sap的视图的类型有五种 Database views (数据库视图):和数据库的视图形同,连接条件是必须自定义. Projection views(投影视图): 用于屏蔽一些字 ...
- C#知识点总结【2】
此文章只是 记录在C#当中一些我个人认为比较重要的知识点,对于有些基础实现或者用法并未说明: 继承 C#当中可以实现两种继承方式 1.实现继承:一个类派生于一个类,它拥有基类的所有成员字段和函数. 2 ...
- iOS远程推送之友盟Push
更新记录: 1.2015年10月23日上午10:10分更新,优化了该类,去除了不必要的方法. ----------------------------------------------------- ...
- 【读书笔记】iOS-使用应用内支付注意事项
一,iOS端开发. 如果购买成功,我们需要将凭证发送到服务器上进行验证.考虑到网络异常情况,iOS端的发送凭证操作应该可以持久化,如果程序退出,崩溃或网络异常,可以恢复重试. 二,服务器端开发. 服务 ...
- IOS 网络浅析-(三 NSURLConnection代理)
对于现在的iOS开发,用法简单,最古老最经典最直接的NSURLConnection的作用不是很大,但是作为一名ios开发者,我们应该拥有一颗热爱学习的心,下面通过代码的实现简单介绍一下NSURLCon ...
- OC-分类
1.不能再分类里面添加属性, 只能添加方法. 2.如果在分类里面使用@property,那么他只生成sette,getter的声明而没有实现. 3.如在在分类中写了与本类同名的方法,优先调用分类里面的 ...
- c语言 拼接字符串
#include<stdio.h> #include<stdlib.h> void main() { ] = "ca"; ] = "lc" ...
- Git+GitHub 使用小结
1.Git安装完成后需要做的配置 $ git config --global user.name "Your Name" $ git confi ...
- Sql server存储过程中常见游标循环用法
用游标,和WHILE可以遍历您的查询中的每一条记录并将要求的字段传给变量进行相应的处理 DECLARE ), ), @A3 INT DECLARE YOUCURNAME CURSOR FOR SELE ...