如何在高并发分布式系统中生成全局唯一Id
最近公司用到,并且在找最合适的方案,希望大家多参与讨论和提出新方案。我和我的小伙伴们也讨论了这个主题,我受益匪浅啊……
博文示例:
今天分享的主题是:如何在高并发分布式系统中生成全局唯一Id。
但这篇博文实际上是“半分享半讨论”的博文:
1) 半分享是我将说下我所了解到的关于今天主题所涉及的几种方案。
2) 半讨论是我希望大家对各个方案都说说自己的见解,更加希望大家能提出更好的方案。(我还另外提问在此:http://q.cnblogs.com/q/53552/)
我了解的方案如下……………………………………………………………………
1、 使用数据库自增Id
优势:编码简单,无需考虑记录唯一标识的问题。
缺陷:
1) 在大表做水平分表时,就不能使用自增Id,因为Insert的记录插入到哪个分表依分表规则判定决定,若是自增Id,各个分表中Id各自增长就会重复
2) 在业务上操作父、子表(即关联表)插入时,需要在插入数据库之前获取max(id)用于标识父表和子表关系,若存在并发获取max(id)的情况,max(id)会同时被别的线程获取到。
3) DB数据记录都是可以根据ID号进行推测出来,对于一些数据敏感的场景,不建议采用
结论:适合小应用,无需分表,低并发。
2、 单独开一个数据库,获取全局唯一的自增序列号或各表的MaxId
使用MaxId表存储各表的MaxId值
专门一个数据库,记录各个表的MaxId值,建一个存储过程来取Id,逻辑大致为:开启事物,对于在表中不存在记录,直接返回一个默认值为1的键值,同时插入该条记录到table_key表中。而对于已存在的记录,key值直接在原来的key基础上加1更新到MaxId表中并返回key。(给table_key中为每个表初始化一条key为1的记录,这样就不用每次if来判断了---@辉_辉 提议)
使用此方案的问题是:每次的查询MaxId是一个性能损耗;
详细可参考:《使用MaxId表存储各表的MaxId值,以获取全局唯一Id》
我截取此文中的sql语法如下:
第一步:创建表
create table table_key
(
table_name varchar(50) not null primary key,
key_value int not null
) 第二步:创建存储过程来取自增ID
create procedure up_get_table_key
(
@table_name varchar(50),
@key_value int output
)
as
begin
begin tran
declare @key int --initialize the key with 1
set @key=1
--whether the specified table is exist
if not exists(select table_name from table_key where table_name=@table_name)
begin
insert into table_key values(@table_name,@key) --default key vlaue:1
end
-- step increase
else
begin
select @key=key_value from table_key with (nolock) where table_name=@table_name
set @key=@key+1
--update the key value by table name
update table_key set key_value=@key where table_name=@table_name
end
--set ouput value
set @key_value=@key --commit tran
commit tran
if @@error>0
rollback tran
end
2. (@乐活的CodeMonkey)提醒提高获取ID时存储过程的隔离级别,避免读取到未提交事务导致并发ID重复的问题。(MSSQL事务隔离级别详解)
eg:
SET TRANSACTION ISOLATION LEVEL READ COMMITTED
GO
BEGIN TRANSACTION;
……
GO
COMMIT TRANSACTION;
3. (@土豆烤肉)存储过程中不使用事物,一旦使用到事物性能就急剧下滑。直接使用UPDATE获取到的更新锁,即SQL SERVER会保证UPDATE的顺序执行。(已在用户过千万的并发系统中使用)
create procedure [dbo].[up_get_table_key]
(
@table_name varchar(50),
@key_value int output
)
as
begin SET NOCOUNT ON;
DECLARE @maxId INT
UPDATE table_key
SET @maxId = key_value,key_value = key_value + 1
WHERE table_name=@table_name
SELECT @maxId end
结论:适用中型应用,此方案解决了分表,关联表插入记录的问题。但是无法满足高并发性能要求。存在单点问题
改进方案:时间信息 + 缓存总的maxid (@wee616 提议)
从redis中用lpop指令取指定key值的数据。(lpop:移除并返回列表的头元素)
如果将指定key值的数据取完了,会触发初始化。
初次初始化:
1)用for update锁表,存储最小值1和最大值50到数据库中。
2)将这50个数字放入redis中。
下次初始化:
1)用for update锁表,存储最小值51和最大值100到数据库中。
2)将这50个数字放入redis中。
数据库每天有脚本定时清理这个表,每天都将最小值归0,避免最大值过大。
结论:适合大型应用,生成Id顺序性,可读性比较好。
3、 Sequence特性
这个特性在SQL Server 2012、Oracle中可用。这个特性是数据库级别的,允许在多个表之间共享序列号。它可以解决分表在同一个数据库的情况,但倘若分表放在不同数据库,那将共享不到此序列号。(eg:Sequence使用场景:你需要在多个表之间公用一个流水号。以往的做法是额外建立一个表,然后存储流水号)
相关Sequence特性资料:
SQL Server2012中的SequenceNumber尝试
SQL Server 2012 开发新功能——序列对象(Sequence)
Difference between Identity and Sequence in SQL Server 2012
结论:适用中型应用,此方案不能完全解决分表问题。
4、 通过数据库集群编号+集群内的自增类型两个字段共同组成唯一主键
优点:实现简单,维护也比较简单。
缺点:关联表操作相对比较复杂,需要两个字段。并且业务逻辑必须是一开始就设计为处理复合主键的逻辑,倘若是到了后期,由单主键转为复合主键那改动成本就太大了。
结论:适合大型应用,但需要业务逻辑配合处理复合主键。
5、 通过设置每个集群中自增 ID 起始点(auto_increment_offset),将各个集群的ID进行绝对的分段来实现全局唯一。当遇到某个集群数据增长过快后,通过命令调整下一个 ID 起始位置跳过可能存在的冲突。
优点:实现简单,且比较容易根据 ID 大小直接判断出数据处在哪个集群,对应用透明。缺点:维护相对较复杂,需要高度关注各个集群 ID 增长状况。
结论:适合大型应用,但需要高度关注各个集群 ID 增长状况。
6、 GUID(Globally Unique Identifier,全局唯一标识符)
GUID通常表示成32个16进制数字(0-9,A-F)组成的字符串,如:{21EC2020-3AEA-1069-A2DD-08002B30309D},它实质上是一个128位长的二进制整数。
GUID制定的算法中使用到用户的网卡MAC地址,以保证在计算机集群中生成唯一GUID;在相同计算机上随机生成两个相同GUID的可能性是非常小的,但并不为0。所以,用于生成GUID的算法通常都加入了非随机的参数(如时间),以保证这种重复的情况不会发生。
优点:GUID是最简单的方案,跨平台,跨语言,跨业务逻辑,全局唯一的Id,数据间同步、迁移都能简单实现。
缺点:
1) 存储占了32位,且无可读性;
2) 插入时因为GUID是无需的,在聚集索引的排序规则下可能移动大量的记录。
有两位园友主推GUID,无须顺序GUID方案原因如下:
@徐少侠 GUID无序在并发下效率高,并且一个数据页内添加新行,是在B树内增加,本质没有什么数据被移动,唯一可能的,是页填充因子满了,需要拆页。而GUID方案导致的拆页比顺序ID要低太多了
@无色 我们要明白id是什么,是身份标识,标识身份是id最大的业务逻辑,不要引入什么时间,什么用户业务逻辑,那是另外一个字段干的事,使用base64(guid,uuid),是通盘考虑,完全可以更好的兼容nosql,key-value存储。
结论:适合大型应用;生成的Id不够友好;占据了32位;
改进:
1) (@dudu告知)在SQL Server 2005中新增了NEWSEQUENTIALID函数。
详细请看:《理解newid()和newsequentialid()》
在指定计算机上创建大于先前通过该函数生成的任何 GUID 的 GUID。 newsequentialid 产生的新的值是有规律的,则索引B+树的变化是有规律的,就不会导致索引列插入时移动大量记录的问题。
但一旦服务器重新启动,其再次生成的GUID可能反而变小(但仍然保持唯一)。这在很大程度上提高了索引的性能,但并不能保证所生成的GUID一直增大。SQL的这个函数产生的GUID很简单就可以预测,因此不适合用于安全目的。
a) 只能做为数据库列的DEFAULT VALUE,不能执行类似SELECT NEWSEQUENTIALID()的语句.
b) 如何获得生成的GUID.
如果生成的GUID所在字段做为外键要被其他表使用,我们就需要得到这个生成的值。通常,PK是一个IDENTITY字段,我们可以在INSERT之后执行 SELECT SCOPE_IDENTITY()来获得新生成的ID,但是由于NEWSEQUENTIALID()不是一个INDETITY类型,这个办法是做不到了,而他本身又只能在默认值中使用,不可以事先SELECT好再插入,那么我们如何得到呢?有以下两种方法:
--1. 定义临时表变量
DECLARE @outputTable TABLE(ID uniqueidentifier)
INSERT INTO TABLE1(col1, col2)
OUTPUT INSERTED.ID INTO @outputTable
VALUES('value1', 'value2')
SELECT ID FROM @outputTable --2. 标记ID字段为ROWGUID(一个表只能有一个ROWGUID)
INSERT INTO TABLE1(col1, col2)
VALUES('value1', 'value2')
--在这里,ROWGUIDCOL其实相当于一个别名
SELECT ROWGUIDCOL FROM TABLE1
结论:适合大型应用,解决了GUID无序特性导致索引列插入移动大量记录的问题。但是在关联表插入时需要返回数据库中生成的GUID;生成的Id不够友好;占据了32位。
2) “COMB”(combined guid/timestamp,意思是:组合GUID/时间截)
(感谢:@ ethan-luo ,@lcs-帅 )
COMB数据类型的基本设计思路是这样的:既然GUID数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么能不能通过组合的方式,保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime),这样我们将时间信息与GUID组合起来,在保留GUID的唯一性的同时增加了有序性,以此来提高索引效率。
在NHibernate中,COMB型主键的生成代码如下所示:
/// <summary> /// Generate a new <see cref="Guid"/> using the comb algorithm.
/// </summary>
private Guid GenerateComb()
{
byte[] guidArray = Guid.NewGuid().ToByteArray(); DateTime baseDate = new DateTime(1900, 1, 1);
DateTime now = DateTime.Now; // Get the days and milliseconds which will be used to build
//the byte string
TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);
TimeSpan msecs = now.TimeOfDay; // Convert to a byte array
// Note that SQL Server is accurate to 1/300th of a
// millisecond so we divide by 3.333333
byte[] daysArray = BitConverter.GetBytes(days.Days);
byte[] msecsArray = BitConverter.GetBytes((long)
(msecs.TotalMilliseconds / 3.333333)); // Reverse the bytes to match SQL Servers ordering
Array.Reverse(daysArray);
Array.Reverse(msecsArray); // Copy the bytes into the guid
Array.Copy(daysArray, daysArray.Length - 2, guidArray,
guidArray.Length - 6, 2);
Array.Copy(msecsArray, msecsArray.Length - 4, guidArray,
guidArray.Length - 4, 4); return new Guid(guidArray);
}
结论:适合大型应用。即保留GUID的唯一性的同时增加了GUID有序性,提高了索引效率;解决了关联表业务问题;生成的Id不够友好;占据了32位。
3) 长度问题,使用Base64或Ascii85编码解决。(要注意的是上述有序性方案在进行编码后也会变得无序)
如:
GUID:{3F2504E0-4F89-11D3-9A0C-0305E82C3301}
当需要使用更少的字符表示GUID时,可能会使用Base64或Ascii85编码。Base64编码的GUID有22-24个字符,如:
7QDBkvCA1+B9K/U0vrQx1A
7QDBkvCA1+B9K/U0vrQx1A==
Ascii85编码后是20个字符,如:
5:$Hj:Pf\4RLB9%kU\Lj
代码如:
Guid guid = Guid.NewGuid();
byte[] buffer = guid.ToByteArray();
var shortGuid = Convert.ToBase64String(buffer);
结论:适合大型应用,缩短GUID的长度。生成的Id不够友好;
7、 GUID TO Int64
对于GUID的可读性,有园友给出如下方案:(感谢:@黑色的羽翼)
即将GUID转为了19位数字,数字反馈给客户可以一定程度上缓解友好性问题。EG:
GUID: cfdab168-211d-41e6-8634-ef5ba6502a22 (不友好)
Int64: 5717212979449746068 (友好性还行)
不过我的小伙伴说ToInt64后就不唯一了。因此我专门写了个并发测试程序,后文将给出测试结果截图及代码简单说明。
(唯一性、业务适合性是可以权衡的,这个唯一性肯定比不过GUID的,一般程序上都会安排错误处理机制,比如异常后执行一次重插的方案……)
结论:适合大型应用,生成相对友好的Id(纯数字)。
8、 自己写编码规则
优点:全局唯一Id,符合业务后续长远的发展(可能具体业务需要自己的编码规则等等)。
缺陷:根据具体编码规则实现而不同;还要考虑倘若主键在业务上允许改变的,会带来外键同步的麻烦。
我这边写两个编码规则方案:(可能不唯一,只是个人方案,也请大家提出自己的编码规则)
1) 12位年月日时分秒+5位随机码+3位服务器编码 (这样就完全单机完成生成全局唯一编码)---共20位
缺陷:因为附带随机码,所以编码缺少一定的顺序感。(生成高唯一性随机码的方案稍后给给出程序)
2) 12位年月日时分秒+5位流水码+3位服务器编码 (这样流水码就需要结合数据库和缓存)---共20位 (将影响顺序权重大的“流水码”放前面,影响顺序权重小的服务器编码放后)
缺陷:因为使用到流水码,流水码的生成必然会遇到和MaxId、序列表、Sequence方案中类似的问题
(为什么没有毫秒?毫秒也不具备业务可读性,我改用5位随机码、流水码代替,推测1秒内应该不会下99999[五位]条语法)
结论:适合大型应用,从业务上来说,有一个规则的编码能体现产品的专业成度。
GUID生成Int64值后是否还具有唯一性测试
测试环境

主要测试思路:
1. 根据内核数使用多线程并发生成Guid后再转为Int64位值,放入集合A、B、…N,多少个线程就有多少个集合。
2. 再使用Dictionary字典高效查key的特性,将步骤1中生成的多个集合全部加到Dictionary中,看是否有重复值。
示例注解:测了 Dictionary<long,bool> 最大容量就在5999470左右,所以每次并发生成的唯一值总数控制在此范围内,让测试达到最有效话。
主要代码:
for (int i = 0; i <= Environment.ProcessorCount - 1; i++)
{
ThreadPool.QueueUserWorkItem(
(list) =>
{
List<long> tempList = list as List<long>;
for (int j = 1; j < listLength; j++)
{
byte[] buffer = Guid.NewGuid().ToByteArray();
tempList.Add(BitConverter.ToInt64(buffer, 0));
}
barrier.SignalAndWait();
}, totalList[i]);
}
测试数据截图:

数据一(循环1000次,测试数:1000*5999470)
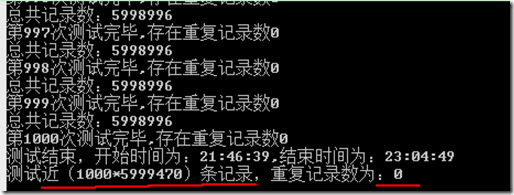
数据二(循环5000次,测试数:5000*5999470)--跑了一个晚上……
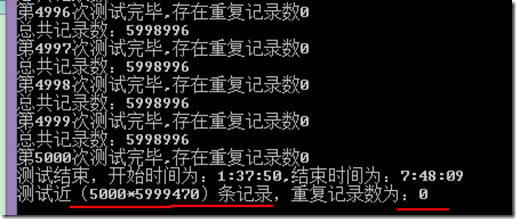
感谢@Justany_WhiteSnow的专业回答:(大家分析下,我数学比较差,稍后再说自己的理解)
GUID桶数量:(2 ^ 4) ^ 32 = 2 ^ 128
Int64桶数量: 2 ^ 64
倘若每个桶的机会是均等的,则每个桶的GUID数量为:
(2 ^ 128) / (2 ^ 64) = 2 ^ 64 = 18446744073709551616
也就是说,其实重复的机会是有的,只是概率问题。
楼主测试数是29997350000,发生重复的概率是:
1 - ((1 - (1 / (2 ^ 64))) ^ 29997350000) ≈ 1 - ((1 - 1 / (2 ^ 64)) ^ (2 ^ 32)) < 1 - 1 + 1 / (2 ^ 32) = 1 / (2 ^ 32) ≈ 2.3283064e-10
(唯一性、业务适合性是可以权衡的,这个唯一性肯定比不过GUID的,一般程序上都会安排错误处理机制,比如异常后执行一次重插的方案……)
(唯一性、业务适合性是可以权衡的,这个唯一性肯定比不过GUID的,一般程序上都会安排错误处理机制,比如异常后执行一次重插的方案……)
结论:GUID转为Int64值后,也具有高唯一性,可以使用与项目中。
Random生成高唯一性随机码
我使用了五种Random生成方案,要Random生成唯一主要因素就是种子参数要唯一。
不过该测试是在单线程下的,多线程应使用不同的Random实例,所以对结果影响不会太大。
1. 使用Environment.TickCount做为Random参数(即Random的默认参数),重复性最大。
2. 使用DateTime.Now.Ticks做为Random参数,存在重复。
3. 使用unchecked((int)DateTime.Now.Ticks)做为Random参数,存在重复。
4. 使用Guid.NewGuid().GetHashCode()做为random参数,测试不存在重复(或存在性极小)。
5. 使用RNGCryptoServiceProvider做为random参数,测试不存在重复(或存在性极小)。
即:
static int GetRandomSeed()
{
byte[] bytes = new byte[4];
System.Security.Cryptography.RNGCryptoServiceProvider rng
= new System.Security.Cryptography.RNGCryptoServiceProvider();
rng.GetBytes(bytes);
return BitConverter.ToInt32(bytes, 0);
}
测试结果:
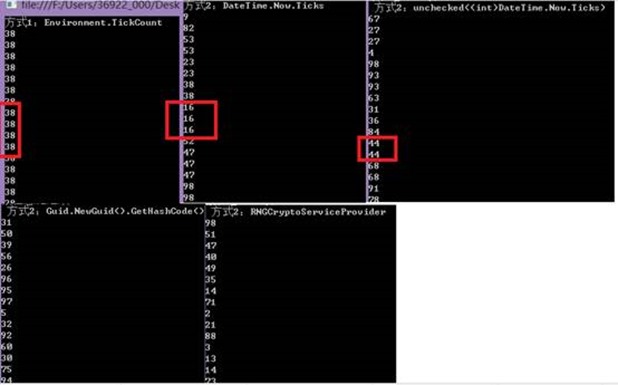
结论:随机码使用RNGCryptoServiceProvider或Guid.NewGuid().GetHashCode()生成的唯一性较高。
一些精彩评论(部分更新到原博文对应的地方)
一、
数据库文件体积只是一个参考值,可水平扩展系统性能(如nosql,缓存系统)并不和文件体积有高指数的线性相关。
如taobao/qq的系统比拼byte系统慢,关键在于索引的命中率,缓存,系统的水平扩展。
如果数据库很少,你搞这么多byte能提高性能?
如果数据库很大,你搞这么多byte不兼容索引不兼容缓存,不是害自已吗?
如果数据库要求伸缩性,你搞这么多byte,需要不断改程序,不是自找苦吗?
如果数据库要求移植性,你搞这么多byte,移植起来不如重新设计,这是不是很多公司不断加班的原因?
不依赖于数据存储系统是分层设计思想的精华,实现战略性能最大化,而不是追求战术单机性能最大化。
不要迷信数据库性能,不要迷信三范式,不要使用外键,不要使用byte,不要使用自增id,不要使用存储过程,不要使用内部函数,不要使用非标准sql,存储系统只做存储系统的事。当出现系统性能时,如此设计的数据库可以更好的实现迁移数据库(如mysql->oracle),实现nosql改造((mongodb/hadoop),实现key-value缓存(redis,memcache)。
二、
很多程序员有对性能认识有误区,如使用存储过程代替正常程序,其实使用存储过程只是追求单服务器的高性能,当需要服务器水平扩展时,存储过程中的业务逻辑就是你的噩运。(web服务器可以简单伸缩,但是数据库伸缩比较复杂)
三、
除数字日期,能用字符串存储的字段尽量使用字符串存储,不要为节省那不值钱的1个g的硬盘而使用类似字节之类的字段,进而大幅牺牲系统可伸缩性和可扩展性。
不要为了追求所谓的性能,引入byte,使用byte注定是短命和难于移植,想想为什么html,email一直流行,因为它们使用的是字符串表示法,只要有人类永远都能解析,如email把二进制转成base64存储。除了实时系统,视频外,建议使用字符串来存储数据,系统性能的关键在于分布式,在于水平扩展。
本次博文到此结束,希望大家对本次主题“如何在高并发分布式系统中生成全局唯一Id”多提出自己宝贵的意见。另外看着感觉舒服,还请多帮推荐…推荐……
推荐阅读
如何在高并发分布式系统中生成全局唯一Id的更多相关文章
- 如何在高并发分布式系统中生成全局唯一Id(转)
http://www.cnblogs.com/heyuquan/p/global-guid-identity-maxId.html 又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文, ...
- (转)如何在高并发分布式系统中生成全局唯一Id
又一个多月没冒泡了,其实最近学了些东西,但是没有安排时间整理成博文,后续再奉上.最近还写了一个发邮件的组件以及性能测试请看 <NET开发邮件发送功能的全面教程(含邮件组件源码)> ,还弄了 ...
- 高并发分布式系统中生成全局唯一Id汇总
数据在分片时,典型的是分库分表,就有一个全局ID生成的问题.单纯的生成全局ID并不是什么难题,但是生成的ID通常要满足分片的一些要求: 1 不能有单点故障. 2 以时间为序,或者ID里包含时间 ...
- 高并发分布式系统中生成全局唯一(订单号)Id js返回上一页并刷新、返回上一页、自动刷新页面 父页面操作嵌套iframe子页面的HTML标签元素 .net判断System.Data.DataRow中是否包含某列 .Net使用system.Security.Cryptography.RNGCryptoServiceProvider类与System.Random类生成随机数
高并发分布式系统中生成全局唯一(订单号)Id 1.GUID数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么通过组合的方式,保留GUID的10个字节,用另6个字节表示GUID生成的时间(D ...
- 高并发分布式系统中生成全局唯一(订单号)Id
1.GUID数据因毫无规律可言造成索引效率低下,影响了系统的性能,那么通过组合的方式,保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime),这样我们将时间信息与GUID组合 ...
- 分布式系统中生成全局ID的总结与思考
世间万物,都有自己唯一的标识,比如人,每个人都有自己的指纹(白夜追凶给我科普的,同卵双胞胎DNA一样,但指纹不一样).又如中国人,每个中国人有自己的身份证.对于计算机,很多时候,也需要为每一份数据生成 ...
- 高并发分布式环境中获取全局唯一ID[分布式数据库全局唯一主键生成]
需求说明 在过去单机系统中,生成唯一ID比较简单,可以使用MySQL的自增主键或者Oracle中的sequence, 在现在的大型高并发分布式系统中,以上策略就会有问题了,因为不同的数据库会部署到不同 ...
- 常见的生成全局唯一id有哪些?他们各有什么优缺点?
分布式系统中全局唯一id是我们经常用到的,生成全局id方法由很多,我们选择的时候也比较纠结.每种方式都有各自的使用场景,如果我们熟悉各种方式及优缺点,使用的时候才会更方便.下面我们就一起来看一下常见的 ...
- 面试官:如何在分布式场景下生成全局唯一 ID?
在分布式系统中,有一些场景需要使用全局唯一 ID ,可以和业务场景有关,比如支付流水号,也可以和业务场景无关,比如分库分表后需要有一个全局唯一 ID,或者用作事务版本号.分布式链路追踪等等,好的全局唯 ...
随机推荐
- In-Memory:内存优化表的事务处理
内存优化表(Memory-Optimized Table,简称MOT)使用乐观策略(optimistic approach)实现事务的并发控制,在读取MOT时,使用多行版本化(Multi-Row ve ...
- SignalR系列续集[系列8:SignalR的性能监测与服务器的负载测试]
目录 SignalR系列目录 前言 也是好久没写博客了,近期确实很忙,嗯..几个项目..头要炸..今天忙里偷闲.继续我们的小系列.. 先谢谢大家的支持.. 我们来聊聊SignalR的性能监测与服务器的 ...
- 【翻译】MongoDB指南/CRUD操作(二)
[原文地址]https://docs.mongodb.com/manual/ MongoDB CRUD操作(二) 主要内容: 更新文档,删除文档,批量写操作,SQL与MongoDB映射图,读隔离(读关 ...
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- 关于 devbridge-autocomplete 插件多选操作的实现方法
目前据我所知最好用的 autocomplete 插件就是 jquery-ui 的 autocomplete 以及 devbridge 的 autocomplete 插件. 我最终选择了 devbrid ...
- jQuery学习之路(8)- 表单验证插件-Validation
▓▓▓▓▓▓ 大致介绍 jQuery Validate 插件为表单提供了强大的验证功能,让客户端表单验证变得更简单,同时提供了大量的定制选项,满足应用程序各种需求.该插件捆绑了一套有用的验证方法,包括 ...
- 基于ASP.NET/C#开发国外支付平台(Paypal)学习心得。
最近一直在研究Paypal的支付平台,因为本人之前没有接触过接口这一块,新来一家公司比较不清楚流程就要求开发两个支付平台一个是支付宝(这边就不再这篇文章里面赘述了),但还是花了2-3天的时间通 ...
- [.NET] C# 知识回顾 - 委托 delegate (续)
C# 知识回顾 - 委托 delegate (续) [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/6046171.html 序 上篇<C# 知识回 ...
- Xamarin+Prism开发详解二:Xaml文件如何简单绑定Resources资源文件内容
我们知道在UWP里面有Resources文件xxx.resx,在Android里面有String.Xml文件等.那跨平台如何统一这些类别不一的资源文件以及Xaml设计文件如何绑定这些资源?应用支持多国 ...
- 【uwp】浅谈China Daily 中划词翻译的实现
学习uwp开发也有一段时间了,最近上架了一个小应用(China Daily),现在准备将开发中所学到的一些东西拿出来跟大家分享交流一下. 先给出应用的下载链接:China Daily , 感兴趣的童鞋 ...