LDA-math-文本建模
http://cos.name/2013/03/lda-math-text-modeling/
4. 文本建模
我们日常生活中总是产生大量的文本,如果每一个文本存储为一篇文档,那每篇文档从人的观察来说就是有序的词的序列 d=(w1,w2,⋯,wn)。
包含M 篇文档的语料库
统计文本建模的目的就是追问这些观察到语料库中的的词序列是如何生成的。统计学被人们描述为猜测上帝的游戏,人类产生的所有的语料文本我们都可以看成是一个伟大的上帝在天堂中抛掷骰子生成的,我们观察到的只是上帝玩这个游戏的结果 —— 词序列构成的语料,而上帝玩这个游戏的过程对我们是个黑盒子。所以在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,具体一点,最核心的两个问题是
- 上帝都有什么样的骰子;
- 上帝是如何抛掷这些骰子的;
第一个问题就是表示模型中都有哪些参数,骰子的每一个面的概率都对应于模型中的参数;第二个问题就表示游戏规则是什么,上帝可能有各种不同类型的骰子,上帝可以按照一定的规则抛掷这些骰子从而产生词序列。


上帝掷骰子
4.1 Unigram Model
假设我们的词典中一共有 V 个词 v1,v2,⋯vV,那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。

上帝的这个唯一的骰子各个面的概率记为 p→=(p1,p2,⋯,pV), 所以每次投掷骰子类似于一个抛钢镚时候的贝努利实验, 记为 w∼Mult(w|p→)。
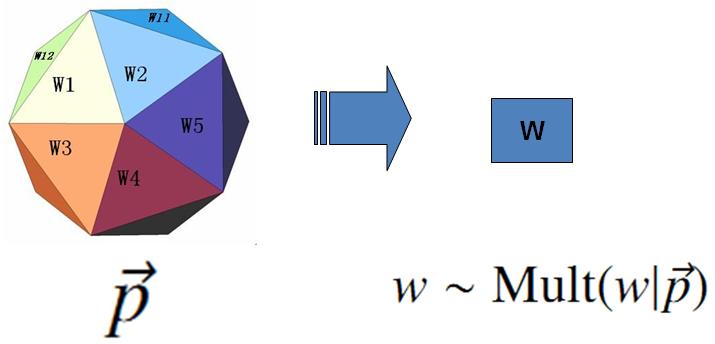 上帝投掷V 个面的骰子
上帝投掷V 个面的骰子
对于一篇文档d=w→=(w1,w2,⋯,wn), 该文档被生成的概率就是
而文档和文档之间我们认为是独立的, 所以如果语料中有多篇文档 W=(w1−→−,w2−→−,…,wm−→−−),则该语料的概率是
在 Unigram Model 中, 我们假设了文档之间是独立可交换的,而文档中的词也是独立可交换的,所以一篇文档相当于一个袋子,里面装了一些词,而词的顺序信息就无关紧要了,这样的模型也称为词袋模型(Bag-of-words)。
假设语料中总的词频是N, 在所有的 N 个词中,如果我们关注每个词 vi 的发生次数 ni,那么 n→=(n1,n2,⋯,nV) 正好是一个多项分布
此时, 语料的概率是
当然,我们很重要的一个任务就是估计模型中的参数p→,也就是问上帝拥有的这个骰子的各个面的概率是多大,按照统计学家中频率派的观点,使用最大似然估计最大化P(W),于是参数pi的估计值就是
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子 p→不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的

上帝的这个坛子里面,骰子可以是无穷多个,有些类型的骰子数量多,有些类型的骰子少,所以从概率分布的角度看,坛子里面的骰子p→ 服从一个概率分布 p(p→),这个分布称为参数p→ 的先验分布。
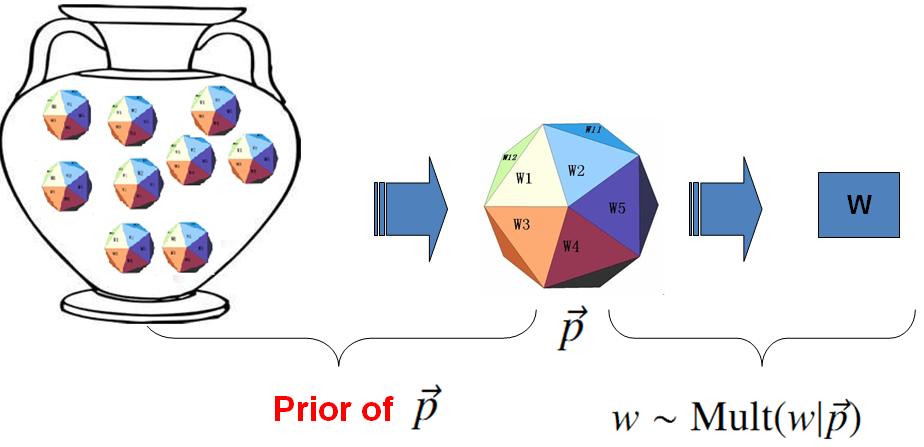 贝叶斯观点下的 Unigram Model
贝叶斯观点下的 Unigram Model
以上贝叶斯学派的游戏规则的假设之下,语料W产生的概率如何计算呢?由于我们并不知道上帝到底用了哪个骰子p→,所以每个骰子都是可能被使用的,只是使用的概率由先验分布p(p→)来决定。对每一个具体的骰子p→,由该骰子产生数据的概率是 p(W|p→), 所以最终数据产生的概率就是对每一个骰子p→上产生的数据概率进行积分累加求和
在贝叶斯分析的框架下,此处先验分布p(p→) 就可以有很多种选择了,注意到
实际上是在计算一个多项分布的概率,所以对先验分布的一个比较好的选择就是多项分布对应的共轭分布,即 Dirichlet 分布
此处,Δ(α→) 就是归一化因子Dir(α→),即
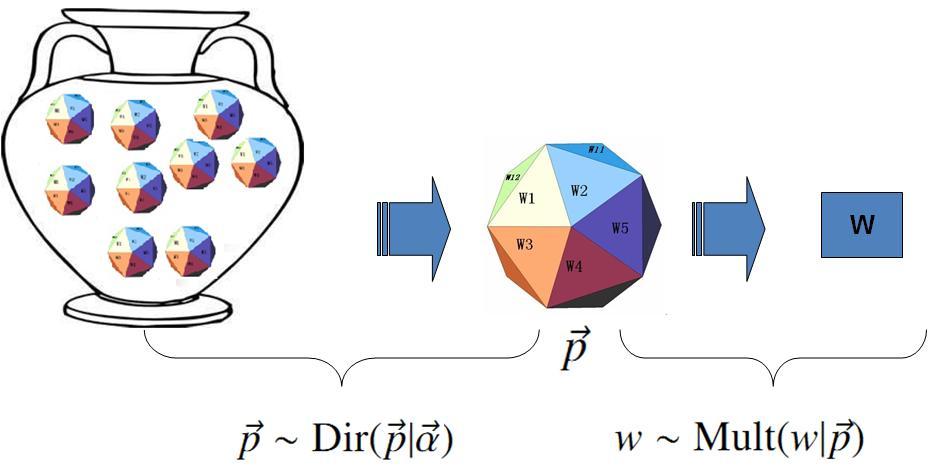
Dirichlet 先验下的 Unigram Model
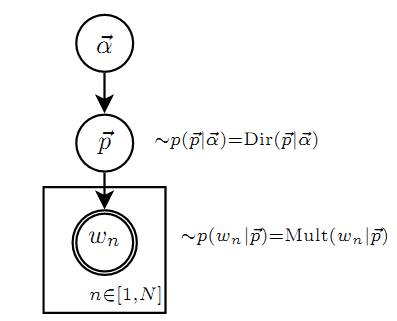
Unigram Model的概率图模型
回顾前一个小节介绍的 Drichlet 分布的一些知识,其中很重要的一点就是
Dirichlet 先验 + 多项分布的数据 → 后验分布为 Dirichlet 分布
于是,在给定了参数 p→的先验分布 Dir(p→|α→) 的时候,各个词出现频次的数据 n→∼Mult(n→|p→,N) 为多项分布, 所以无需计算,我们就可以推出后验分布是
在贝叶斯的框架下,参数p→如何估计呢?由于我们已经有了参数的后验分布,所以合理的方式是使用后验分布的极大值点,或者是参数在后验分布下的平均值。在该文档中,我们取平均值作为参数的估计值。使用上个小节中的结论,由于 p→ 的后验分布为Dir(p→|n→+α→),于是
也就是说对每一个 pi, 我们用下式做参数估计
考虑到 αi 在 Dirichlet 分布中的物理意义是事件的先验的伪计数,这个估计式子的含义是很直观的:每个参数的估计值是其对应事件的先验的伪计数和数据中的计数的和在整体计数中的比例。
进一步,我们可以计算出文本语料的产生概率为
4.2 Topic Model 和 PLSA
以上 Unigram Model 是一个很简单的模型,模型中的假设看起来过于简单,和人类写文章产生每一个词的过程差距比较大,有没有更好的模型呢?
我们可以看看日常生活中人是如何构思文章的。如果我们要写一篇文章,往往是先确定要写哪几个主题。譬如构思一篇自然语言处理相关的文章,可能 40\% 会谈论语言学、30\% 谈论概率统计、20\% 谈论计算机、还有10\%谈论其它的主题:
- 说到语言学,我们容易想到的词包括:语法、句子、乔姆斯基、句法分析、主语…;
- 谈论概率统计,我们容易想到以下一些词: 概率、模型、均值、方差、证明、独立、马尔科夫链、…;
- 谈论计算机,我们容易想到的词是: 内存、硬盘、编程、二进制、对象、算法、复杂度…;
我们之所以能马上想到这些词,是因为这些词在对应的主题下出现的概率很高。我们可以很自然的看到,一篇文章通常是由多个主题构成的、而每一个主题大概可以用与该主题相关的频率最高的一些词来描述。
以上这种直观的想法由Hoffman 于 1999 年给出的PLSA(Probabilistic Latent Semantic Analysis) 模型中首先进行了明确的数学化。Hoffman 认为一篇文档(Document) 可以由多个主题(Topic) 混合而成, 而每个Topic 都是词汇上的概率分布,文章中的每个词都是由一个固定的 Topic 生成的。下图是英语中几个Topic 的例子。
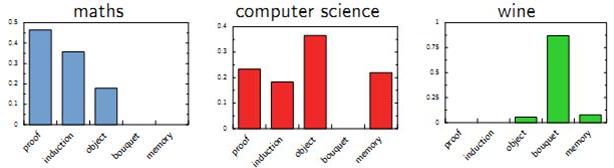 Topic 就是Vocab 上的概率分布
Topic 就是Vocab 上的概率分布
所有人类思考和写文章的行为都可以认为是上帝的行为,我们继续回到上帝的假设中,那么在 PLSA 模型中,Hoffman 认为上帝是按照如下的游戏规则来生成文本的。

以上PLSA 模型的文档生成的过程可以图形化的表示为
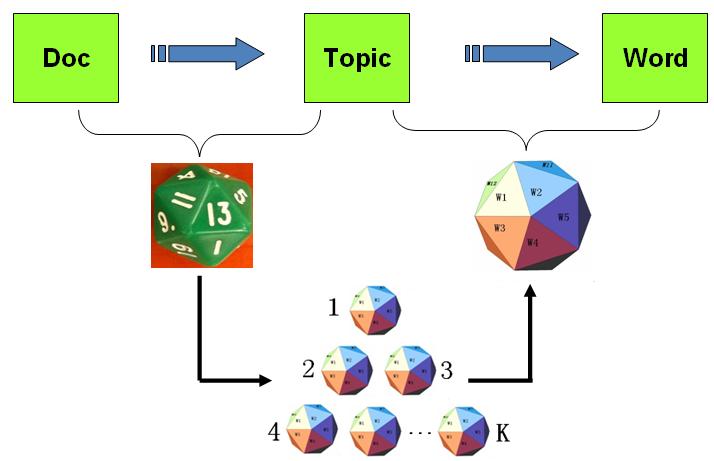 PLSA 模型的文档生成过程
PLSA 模型的文档生成过程
我们可以发现在以上的游戏规则下,文档和文档之间是独立可交换的,同一个文档内的词也是独立可交换的,还是一个 bag-of-words 模型。游戏中的K 个topic-word 骰子,我们可以记为 φ→1,⋯,φ→K, 对于包含M篇文档的语料 C=(d1,d2,⋯,dM) 中的每篇文档dm,都会有一个特定的doc-topic骰子θ→m,所有对应的骰子记为 θ→1,⋯,θ→M。为了方便,我们假设每个词w 都是一个编号,对应到topic-word 骰子的面。于是在 PLSA 这个模型中,第m篇文档 dm 中的每个词的生成概率为
所以整篇文档的生成概率为
由于文档之间相互独立,我们也容易写出整个语料的生成概率。求解PLSA 这个 Topic Model 的过程汇总,模型参数并容易求解,可以使用著名的 EM 算法进行求得局部最优解,由于该模型的求解并不是本文的介绍要点,有兴趣的同学参考 Hoffman 的原始论文,此处略去不讲。
LDA-math-文本建模的更多相关文章
- LDA-math-LDA 文本建模
http://cos.name/2013/03/lda-math-lda-text-modeling/ 5. LDA 文本建模 5.1 游戏规则 对于上述的 PLSA 模型,贝叶斯学派显然是有意见的, ...
- Bert不完全手册9. 长文本建模 BigBird & Longformer & Reformer & Performer
这一章我们来唠唠如何优化BERT对文本长度的限制.BERT使用的Transformer结构核心在于注意力机制强大的交互和记忆能力.不过Attention本身O(n^2)的计算和内存复杂度,也限制了Tr ...
- 文本建模、文本分类相关开源项目推荐(Pytorch实现)
Awesome-Repositories-for-Text-Modeling repo paper miracleyoo/DPCNN-TextCNN-Pytorch-Inception Deep Py ...
- 文本主题抽取:用gensim训练LDA模型
得知李航老师的<统计学习方法>出了第二版,我第一时间就买了.看了这本书的目录,非常高兴,好家伙,居然把主题模型都写了,还有pagerank.一路看到了马尔科夫蒙特卡罗方法和LDA主题模型这 ...
- [IR] Concept Search and LDA
重要的是通过实践更深入地了解贝叶斯思想,先浅浅地了解下LDA. From: http://blog.csdn.net/huagong_adu/article/details/7937616/ 传统方法 ...
- [Bayes] Concept Search and LDA
重要的是通过实践更深入地了解贝叶斯思想,先浅浅地了解下LDA. 相关数学知识 LDA-math-MCMC 和 Gibbs Sampling LDA-math - 认识 Beta/Dirichlet 分 ...
- 计算LDA模型困惑度
http://www.52nlp.cn/lda-math-lda-%E6%96%87%E6%9C%AC%E5%BB%BA%E6%A8%A1 LDA主题模型评估方法--Perplexity http:/ ...
- 基于LDA对关注的微博用户进行聚类
转自:http://www.datalab.sinaapp.com/?p=237 最近看了LDA以及文本聚类的一些方法,写在这里算是读书笔记.文章最后进行了一个小实验,通过爬取本人在微博上关注的人的微 ...
- 【转】LDA数学八卦
转自LDA数学八卦 在 Machine Learning 中,LDA 是两个常用模型的简称: Linear Discriminant Analysis 和 Latent Dirichlet Alloc ...
- R语言︱LDA主题模型——最优主题数选取(topicmodels)+LDAvis可视化(lda+LDAvis)
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:在自己学LDA主题模型时候,发现该模 ...
随机推荐
- MongoDB过过瘾
MongoDB 中默认的数据库为 test,连接后尝试以下操作 连接 插入数据:用过json的同学看到这格式相信不会陌生吧! db.person.insert({}) db.person.insert ...
- for循环数据节点
1.需要实现的功能,动态填充多条银行卡信息 2.dom结构 3.数据节点 4.实现方式 //获取银行卡基本信息 CmnAjax.PostData("Handler/Users/Users.a ...
- NSURLConnection同步与异步请求 问题
NSURLConnection目前有两个异步请求方法,异步请求中其中一个是代理.一个同步方法.有前辈已经详细介绍,见:http://blog.csdn.net/xyz_lmn/article/deta ...
- 验证整数、小数、实数、有效位小数最简单JavaScript正则表达式
输入完按回车后即可验证!(自认为最简单!) 正整数: 负整数: 整 数: 正小数: 负小数: 小 数: 实 数: 保留1位小数: 保留2位小数: 保留3位小数: 说明:IE6.0.IE7 ...
- [LeetCode]题解(python):093 Restore IP Addresses
题目来源 https://leetcode.com/problems/restore-ip-addresses/ Given a string containing only digits, rest ...
- Selenium2学习-012-WebUI自动化实战实例-010-解决元素失效:StaleElementReferenceException: stale element reference: element is not attached to the page document
元素失效的想象提示信息如下图所示,此种问题通常是因为元素页面刷新之后,为重新获取元素导致的. 解决此类问题比较简单,只需要在页面刷新之后,重新获取一下元素,就可以消除此种错误了. 以下以易迅网搜索为例 ...
- oracle 中的存储过程
oracle 中的存储过程 --oracle 中的存储过程, --不带任何参数的 CREATE OR REPLACE PROCEDURE PRO_TEST AS -- AS 和is 没有任何区别 ...
- Android java判断字符串包含某个字符段(或替换)
String str = "; ) { System.out.println("包含该字符串"); }
- 关闭不安全的HTTP方法
关闭不安全的HTTP方法 在项目或tomcat下的web.xml中,添加如下配置: <!-- 关闭不安全的HTTP方法 --> <security-constraint> &l ...
- matlab将多条曲线绘制在一起
figure; hold on; : plot(x(i,:),y(i,:)); end x=:*pi); hold on : y=sin(x+i*pi/)+exp(x/); plot(x,y, -(] ...