python异常处理,多线程,多进程
什么是异常?
异常即是一个事件,该事件会在程序执行过程中发生,影响了程序的正常执行。
一般情况下,在Python无法正常处理程序时就会发生一个异常。
异常是Python对象,表示一个错误。
当Python脚本发生异常时我们需要捕获处理它,否则程序会终止执行。
异常处理
捕捉异常可以使用try / except语句。
try/except语句用来检测try语句块中的错误,从而让except语句捕获异常信息并处理。
如果你不想在异常发生时结束你的程序,只需在try里捕获它。
以下为简单的try....except...else的语法:
正常的操作
......................
except: #可以多次使用except捕捉多个错误
发生异常,执行这块代码
......................
else: #可有可无
如果没有异常执行这块代码
例:索引错误
l = [1, 2, 3, 4]
try:
l[5]
except IndexError:
print('索引错误')
else:
print('成功')
运行结果:
l = [1, 2, 3, 4]
try:
l[5]
except IndexError as i: #可以给错误个别名
print(i) #然后打印错误,会出现原生错误
else:
print('成功')
运行结果:
try-finally 语句
try-finally 语句无论是否发生异常都将执行最后的代码。
try:
<语句>
finally:
<语句> #退出try时总会执行
raise
例:
l = [1, 2, 3, 4]
try:
l[5]
except IndexError:
print('索引错误')
finally:
print('happy')
运行结果: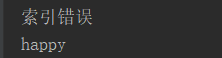
自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
以下为与RuntimeError相关的实例,实例中创建了一个类,基类为RuntimeError,用于在异常触发时输出更多的信息。
在try语句块中,用户自定义的异常后执行except块语句,变量 e 是用于创建Networkerror类的实例。
例:
class 异常错误名字(Exception): #自定义异常,继承Exception类的形式
def __init__(self, msg): #初始化
self.message = msg
# def __str__(self):
# return self.message
try:
raise 异常错误名字('我的异常') #固定格式
except 异常错误名字 as e:
print(e)
多任务多线程
线程的并发是利用cpu的上下文的切换,在python3里是假的多线程,它不是真真正正的并行,其实就是串行,只不过利用了cpu上下文的切换而已
线程是程序最小的调度单位
例:串行
def test1():
for i in range(3):
print('test1=======>%s' % i)
def test2():
for i in range(3):
print('test2=======>%s' % i) test1()
test2()
运行结果: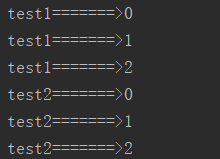
例:并发
import threading #导入线程模块
import time #导入time模块
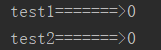
def test1():
for i in range(3):
time.sleep(1) #为了看出效果,延迟1秒
print('test1=======>%s' % i)
def test2():
for i in range(3):
time.sleep(1) #为了看出效果,延迟1秒
print('test2=======>%s' % i)
t1 = threading.Thread(target=test1) #实例化一个线程,用Thread方法 ,目标是test1(不加括号,是内存地址)
t2 = threading.Thread(target=test2)
t1.start() #执行这个线程
t2.start() #执行这个线程
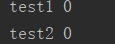
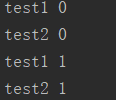
运行结果:图一出现后1秒,再次出现两行,如图二,再1秒后,再次出现两行,如图三


多线程执行的顺序是无序的
def test1(n):
time.sleep(1)
print('task', n)
for i in range(10):
t = threading.Thread(target=test1, args=('t-%s' % i,)) #传参args,必须元组形式,必须要加逗号
t.start()
运行结果: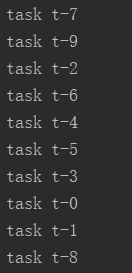
多线程共享全局变量
因为函数内得不到函数外的数据,所以要global声明
g_num = 0 #全局变量
def update():
global g_num #global声明全局变量(才可以修改)
for i in range(10):
g_num += 1
update()
print(g_num)
运行结果:
g_num = 0 #全局变量
def update():
global g_num #global声明全局变量(才可以修改)
for i in range(10):
g_num += 1
def reader():
global g_num
print(g_num) t1 = threading.Thread(target=update)
t2 = threading.Thread(target=reader)
t1.start()
t2.start()
运行结果:
线程是继承在进程里的,没有进程就没有线程
GIL全局解释器锁
GIL的全称是:Global Interpreter Lock,意思就是全局解释器锁,这个GIL并不是python的特性,他是只在Cpython解释器里引入的一个概念,而在其他的语言编写的解释器里就没有这个GIL例如:Jython,Pypy
为什么会有GIL?:
随着电脑多核cpu的出现核cpu频率的提升,为了充分利用多核处理器,进行多线程的编程方式更为普及,随之而来的困难是线程之间数据的一致性和状态同步,而python也利用了多核,所以也逃不开这个困难,为了解决这个数据不能同步的问题,设计了gil全局解释器锁。
例:
def test1():
global global_num #声明全局变量
for i in range(1000000):
global_num += 1 #加1
print("test1", global_num) def test2():
global global_num
for i in range(1000000):
global_num += 1
print("test2", global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
# # t1.join() #等t1线程执行完毕
# # t2.join()
print(global_num)
执行结果:会发现每次都是不同的
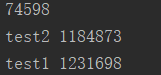

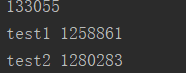
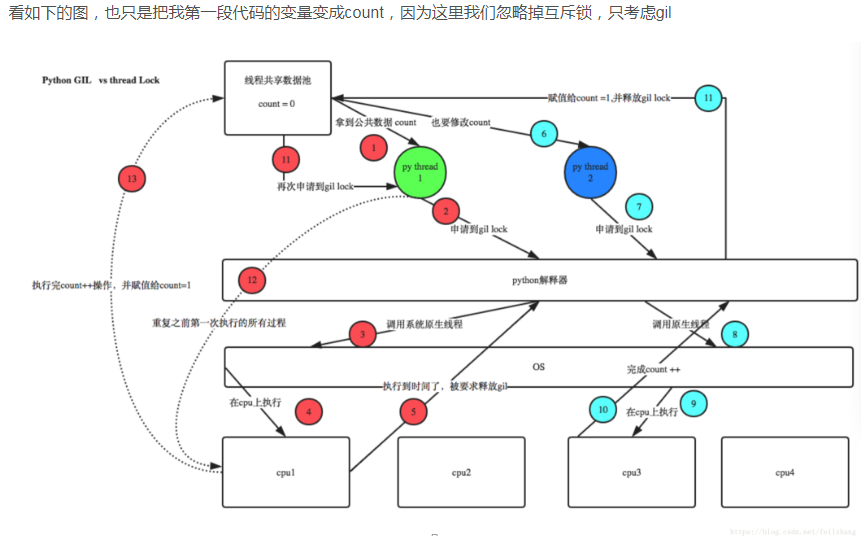
那么问题来了,为什么每次的执行结果都不一样呢,让我们结合上面的大图,分析一下:
上图和实例解析:
线程共享数据池,就相当于声明的全局变量,线程1拿到公共数据后,首先会申请到gil锁,就是在它进行操作时,不允许其他线程的操作,通过python解释器,调用系统原生线程,,然后假设在cpu上执行,若执行时间到了,线程1 还没有执行结束,那么将会被要求释放gil锁,相当于暂停,释放后线程2会拿到公共数据,同样申请到gil锁,通过python解释器调用原生线程,假设在cpu3上执行,并且完成+1的赋值,全局变量将会从0变成1,并且 ,线程2释放gil锁,线程1再次开始执行,将从暂停的位置开始,当结束+1赋值时,释放gil锁,这里线程1的从0到1赋值的过程将会覆盖掉线程2的赋值,所以,全局变量还是1,接下来还是同样的道理,不管线程1还是线程2,每一次赋值都是覆盖形式的,所以当主线程结束的时候,每次的结果就不一样了。
那么上面的结果并不是我们想要的,针对上面的情况我们的解决的方案是再加一把锁
互斥锁,要么不作,要么做完
GIL全局解释器锁
import threading
global_num = 0 lock = threading.Lock() #申请一把锁
def test1():
global global_num
lock.acquire() #上锁
for i in range(1000000):
global_num += 1
lock.release() #释放锁
print("test1", global_num) def test2():
global global_num
lock.acquire() #上锁
for i in range(1000000):
global_num += 1
lock.release() #释放锁
print("test2", global_num)
t1 = threading.Thread(target=test1)
t2 = threading.Thread(target=test2)
t1.start()
t2.start()
t1.join() #为了防止主线程结束的太快,等t1线程执行完毕
t2.join() #为了防止主线程结束的太快,等t2线程执行完毕
print(global_num)
运行结果: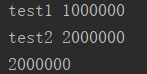
那么上过锁之后,实际就变成了串行
例:下面代码开了10个进程,跑了多久的时间
import time
def run(n):
time.sleep(2)
print('this is running======>%s' % n) for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
解决方案:
import time
def run(n):
time.sleep(2)
print('this is running======>%s' % n)
l = [] #建立一个空列表
start = time.time() #记录开始的时间
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
l.append(t) #把创建的实例加入列表
for j in l: #循环l列表
j.join() #等待循环进程结束
end = time.time() #记录结束的时间
print('cost', (end-start))
只要在进行耗时的IO操作的时候,能释放GIL,所以只要在IO密集型的代码里,用多线程就很合适
进程
一个程序运行起来之后,代码+用到的资源称之为进程,它是操作系统分配资源的基本单位,不仅可以通过线程完成多任务,进程也是可以的,cpu密集的时候适合用多进程
多进程的并发
import time
import multiprocessing #导入多重处理模块
def test1():
for i in range(10):
time.sleep(1)
print('test1====>', i) def test2():
for i in range(10):
time.sleep(1)
print('test2====>', i) if __name__=='__main__': #main的固定格式,如果没有将报错不支持
p1 = multiprocessing.Process(target=test1) #进程1的调用
p2 = multiprocessing.Process(target=test2) #进程2的调用
p1.start()
p2.start()
一这两个进程任务为例,如果cpu核数>=2,那么就是真真正正的 并行
运行结果: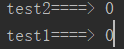
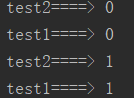
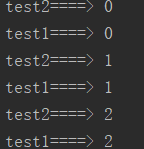 以此类推
以此类推
进程之间是相互独立的
import multiprocessing
import time
g_num = 0
def update(): #写函数
global g_num
for i in range(100):
g_num += 1
print(g_num) def reader(): #读函数
print(g_num) if __name__ == '__main__':
p1 = multiprocessing.Process(target=update)
p2 = multiprocessing.Process(target=reader)
p1.start()
p2.start()
运行结果: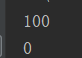 ,由此看出读函数没有读到写函数更改的内容,所以得出,进程之间互相独立,互不影响
,由此看出读函数没有读到写函数更改的内容,所以得出,进程之间互相独立,互不影响
进程池
什么时候用进程池?
当不知道有多少个进程池要跑的时候,用进程池最合适。
import multiprocessing
from multiprocessing import Pool #或者用 multiprocessing.Pool(),再给他赋变量
import time
import threading
g_num = 0
def test1(n):
for i in range(n):
time.sleep(1)
print('test1', i) def test2(n):
for i in range(n):
time.sleep(1)
print('test2', i) if __name__ == '__main__': pool = Pool() #声明进程池 #括号内没有声明进程数,默认无限(根据电脑配置情况)
pool.apply_async(test1, (10,)) #使用方法并且加参数
pool.apply_async(test2, (10,))
pool.close() #进程池关闭
pool.join() #进程池等待(注意的是:join必须放在close后边)
这就是进程池的并发,运行结果:
 等等
等等
协程
进程是资源分配的单位,切换需要的资源最大,效率低
线程是操作系统调度的单位,切换需要的资源一般,效率一般
协程是寄生在线程里的,所以协程切换任务资源很小,效率高。IO操作密集的时候首选协程
多进程、多线程根据cpu核数不一样可能是并行的,但是协成在一个线程中
协程,其实就是串行
例:
import gevent,time
def test1():
for i in range(10):
time.sleep(1) #遇见延迟就切换
print('test1', i) def test2():
for i in range(10):
time.sleep(1) #遇见延迟就切换
print('test2', i)
g1 = gevent.spawn(test1) #声明实例,调用函数的方法就是spawn
g2 = gevent.spawn(test2)
g1.join() #调用方式join,不是start
g2.join()
运行结果:依次出现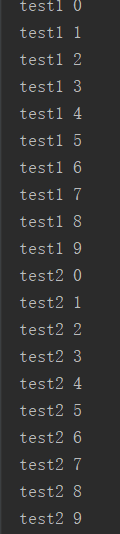 ,由此看出是串行
,由此看出是串行
协程,可以自动切换
由于协程工作时遇见延迟就会切换,所以会在test1,test2来回切换,因为test1延迟1秒,test2,延迟2秒,所以会按照2个test1,一个test2 的规律打印
import gevent,time
# from gevent import monkey #打个补丁支持time.sleep()
# monkey.patch_all() #让gevent支持time.sleep()
def test1():
for i in range(10):
# time.sleep(1) #遇见延迟就切换
gevent.sleep(1) #延迟1秒
print('test1', i) def test2():
for i in range(10):
# time.sleep(2) #遇见延迟就切换
gevent.sleep(2) #延迟2秒
print('test2', i)
g1 = gevent.spawn(test1) #声明实例,调用函数的方法就是spawn
g2 = gevent.spawn(test2)
g1.join() #调用方式join,不是start
g2.join()
运行结果:
python异常处理,多线程,多进程的更多相关文章
- python进阶--多线程多进程
一.线程和进程 进程是拥有独立内存,能够独立运行的最小单位,也是程序执行的最小单位,线程是程序运行过程中,一个单一的顺序控制流程,是程序执行流的最小单位,一个进程至少包含一个线程,多线程共享进程的内存 ...
- 静听网+python爬虫+多线程+多进程+构建IP代理池
目标网站:静听网 网站url:http://www.audio699.com/ 目标文件:所有在线听的音频文件 附:我有个喜好就是听有声书,然而很多软件都是付费才能听,免费在线网站虽然能听,但是禁ip ...
- python 爬虫 多线程 多进程
一.程序.进程和线程的理解 程序:就相当于一个应用(app),例如电脑上打开的一个程序. 进程:程序运行资源(内存资源)分配的最小单位,一个程序可以有多个进程. 线程:cpu最小的调度单位,必须依赖 ...
- Python之多线程多进程
(一)进程 1.定义 进程:就是一组资源的集合.一个程序就是一个进程. 线程是用来干活的,只有进程的话是没办法运行的,进程里其实是线程在具体干活的. import threading import t ...
- Python的多线程(threading)与多进程(multiprocessing )
进程:程序的一次执行(程序载入内存,系统分配资源运行).每个进程有自己的内存空间,数据栈等,进程之间可以进行通讯,但是不能共享信息. 线程:所有的线程运行在同一个进程中,共享相同的运行环境.每个独立的 ...
- 学习笔记--python中使用多进程、多线程加速文本预处理
一.任务描述 最近尝试自行构建skip-gram模型训练word2vec词向量表.其中有一步需要统计各词汇的出现频率,截取出现频率最高的10000个词汇进行保留,形成常用词词典.对于这个问题,我建立了 ...
- Python之多线程和多进程
一.多线程 1.顺序执行单个线程,注意要顺序执行的话,需要用join. #coding=utf-8 from threading import Thread import time def my_co ...
- Python的多线程和多进程
(1)多线程的产生并不是因为发明了多核CPU甚至现在有多个CPU+多核的硬件,也不是因为多线程CPU运行效率比单线程高.单从CPU的运行效率上考虑,单任务进程及单线程效率是最高的,因为CPU没有任何进 ...
- Python【多线程与多进程】
import time,threading print("=======串行方式.并行两种方式调用run()函数=======")def run(): print('哈哈哈') # ...
- 聊聊Python中的多进程和多线程
今天,想谈一下Python中的进程和线程. 最近在学习Django的时候,涉及到了多进程和多线程的知识点,所以想着一下把Python中的这块知识进行总结,所以系统地学习了一遍,将知识梳理如下. 1. ...
随机推荐
- HDU 1164 Eddy's research I( 试除法 & 筛法改造试除法 分解整数 )
链接:传送门 题意:给出一个整数 n ,输出整数 n 的分解成若干个素因子的方案 思路:经典的整数分解题目,这里采用试除法 和 用筛法改造后的试除法 对正整数 n 进行分解 方法一:试除法对正整数 n ...
- HDU 4704 Sum( 费马小定理 + 快速幂 )
链接:传送门 题意:求 N 的拆分数 思路: 吐嘈:求一个数 N 的拆分方案数,但是这个拆分方案十分 cd ,例如:4 = 4 , 4 = 1 + 3 , 4 = 3 + 1 , 4 = 2 + 2 ...
- [2] day 02
1. df.memory_usage()将返回每列占用多少 要包含索引,请传递index=True所以要获得整体内存消耗: 2. numpy.iinfo 3. shift函数 https://blog ...
- MySQL数据库中字段类型为tinyint,读取出来为true/false的问题
由于MySQL中没有boolean类型,所以会用到tinyint类型来表示. 数据库一个表中有一个tinyint类型的字段,值为0或者1,如果取出来的话,0会变成false,1会变成true.
- 搞定PHP面试 - 函数知识点整理
一.函数的定义 1. 函数的命名规则 函数名可以包含字母.数字.下划线,不能以数字开头. function Func_1(){ } //合法 function func1(){ } //合法 func ...
- JavaScript中的XMLDOM对象
测试: demo.xml中的内容: js文件内容: window.onload=function(){ //var v=returnXMLDOM(); //v.loadXML('<root> ...
- 【转】sql 基本语法
简单语法:http://www.cnblogs.com/lyhabc/p/3691555.html 数据类型宽度:http://www.cnblogs.com/lyhabc/p/3696629.htm ...
- [SharePoint2010开发入门经典]创建你的第一个SPS2010程序
本章概要: 1.创建一个解决方案,使他能读写数据从列表中,使用服务器端对象模型和可视的web部件 2.使用VS2010构建部署解决方案 3.使用图标web部件渲染列表数据 4.在一个解决方案中集成不同 ...
- hdu 1754 I Hate It 线段树 点改动
// hdu 1754 I Hate It 线段树 点改动 // // 不多说,裸的点改动 // // 继续练 #include <algorithm> #include <bits ...
- 【LeetCode-面试算法经典-Java实现】【033-Search in Rotated Sorted Array(在旋转数组中搜索)】
[033-Search in Rotated Sorted Array(在旋转数组中搜索)] [LeetCode-面试算法经典-Java实现][全部题目文件夹索引] 原题 Suppose a sort ...