mapreduce v1.0学习笔记
它是什么?
一个用于处理大数据开源的分布式计算框架,它由java实现,原生提供java编程交互接口,其它语言通过hadoop streaming方式和mapreduce框架交互。
可以做什么?
利用框架提供的简单编程接口,对海量数据进行离线统计分析编程。程序员只需要实现map接口(数据分解),reduce接口(数据汇总)即可,实现简单。
适用场景
离线情况下对海量数据进行分析
怎么使用?
示例 - 对文章单词进行计数(使用Python实现)
准备
1 搭建好hadoop 1.0集群
2 网上找一篇英语文章,上传到hdfs集群中,假如上传后文件路径为: /data/the_english_article.txt
说明
1 单词之间使用空格分隔
实现map接口(map.py)
import sys
for line in sys.stdin:
ss = line.strip().split(" ")
for s in ss:
s = s.strip()
if s != "":
print "\t".join([s, 1])
实现reduce接口(reduce.py)
import sys
cur_word = None
sum = 0
for line in sys.stdin:
word, cnt = line.strip().split("\t")
if cur_word == None:
cur_word = word
if cur_word != word:
print "\t".join([cur_word, sum])
cur_word = word
sum = 0
sum += int(cnt)
print "\t".join([cur_word, sum])
本地模拟mapreduce执行
集群上调试效率很低,正常情况下,先在本地调试,确定代码无问题后,再在集群上跑测试
cat ./the_english_article.txt | python map.py | sort -k1 | python reduce.py | head -n 20
mapreduce集群上执行
1 创建一个shell脚本(run.sh)
HADOOP_CMD=hadoop命令完整路径
HADOOP_STREAMING_JAR=streaming jar包完整路径
INPUT_FILE=/data/the_english_article
OUTPUT_DIR=/output/wc
$HADOOP_CMD fs -rmr -skipTrash $OUTPUT_DIR
$HADOOP_CMD jar $HADOOP_STREAMING_JAR \
-input $INPUT_FILE \
-output $OUTPUT_DIR \
-mapper "python map.py" \
-reducer "python reduce.py" \
-file ./map.py
-file ./reduce.py
2 执行mapreduce任务
bash run.sh
3 查看结果
如果执行成功,hdfs上/output/wc会有part-00000这个文件,结果就保存在这个文件中(一个reduce对应一个输出文件,如果没有指定reduce任务数量,默认是1个reduce汇总)
4 杀死job
hadoop job -kill job_id
如何实现?
思想
分而治之 - mapreduce框架精髓所在
数据处理:分解 -> 求解 -> 合并
数据不移动,计算移动
代码数据量小,移动代码比移动数据性能要高,只针对map阶段
技术架构

| 角色 | 描述 |
|---|---|
| Job Tracker | 集群计算资源管理和任务调度以及任务监控,客户端提交任务给Job Tracker,计算框架的大脑 |
| Task Tracker | 执行计算任务,任务状态上报以及资源使用情况上报,通过心跳方式,默认每隔3秒,资源slot管理 |
提交任务流程
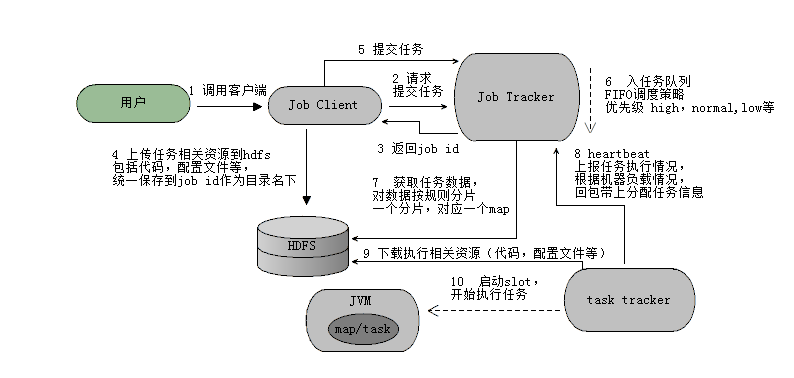
mapreduce执行流程(偏宏观角度)
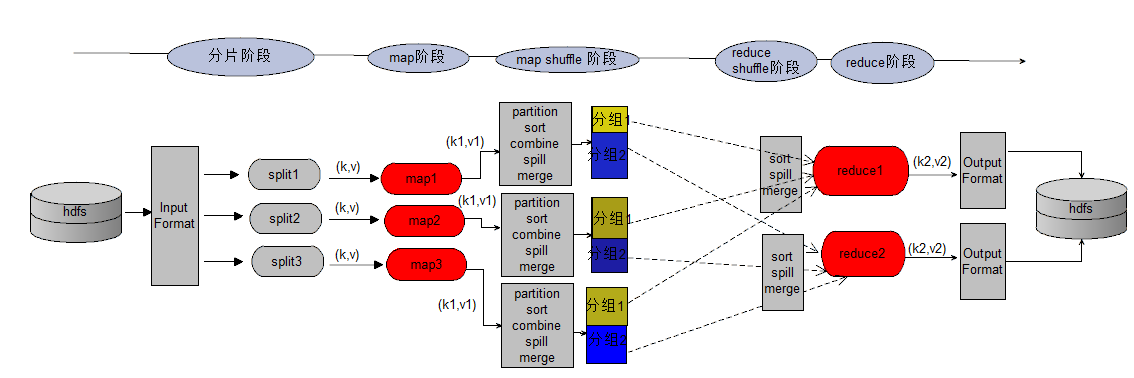
1 红色部分是需要编程的部分,其它是mapreduce框架自带的功能
2 一个分片对应一个map
3 如果一行分片时中间被截断了,整行属于前一部分的分片
4 一个reduce会输出一个结果文件
5 map/reduce默认缓存区是100M,阀值是80%,达到这个阀值开始往硬盘溢写
6 reduce数据从map所在节点拷贝过来,会产生网络io,map不是
7 map/reduce是进程模型,有自己独立的空间,可以更好的控制资源
8 所有map任务执行完毕,才会开始执行reduce任务
9 同一分区下所有小文件归并为一个文件完成后,才开始执行reduce程序
10 数据分片规则:max(min.split,min(max.split,block))
| 操作 | 含义 |
|---|---|
| partition | 对key进行分组,有几个reduce就会通过哈希取模的方式分成几个组,这个操作可以确保相同的key一定会分配到同一个reduce |
| sort | 同一个组下对key进行排序,按字符串排序,确保数据有序 |
| combine | 对相同key进行数据合并,实际上是提前对部分数据执行reduce操作,可以减少reduce阶段数据传输量,但是有些场景不适合,比如求中位数,会得到错误的结果 |
| spill | 对缓冲区数据进行溢写,map会不断的产生数据,而内存缓冲区大小是有限的,当内存超过或者等于阀值的80%时,会锁住这部分内存,把这部分数据写入硬盘,生成一个spill.n的小文件,写入之前会分好组排好序 |
| merge | 对溢写生成的小文件进行合并,生成一个更大的文件,合并的文件也是分好组排好序的数据,合并文件采用归并排序 |
mapreduce执行流程(偏微观角度)
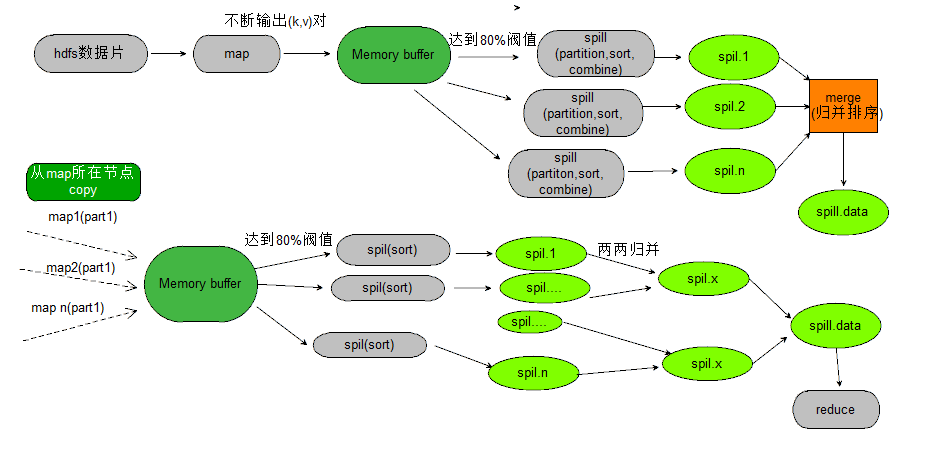
实践总结
1 TaskTracker节点map,reduce slot数量确定
机器CPU核数 - 1
2 单个map/reduce任务占用内存最好不要超过500M
3 单个map/reduce任务执行时间最好控制在1~3分钟,最好不要超过20分钟
4 压缩文件不能分片,目前为止只有text file, sequence file可以分片
5 ulimit查看open max files,这个值不能太小
6 reduce个数不能设置太少(执行慢,出错再试成本高),也不能设置太多(shuffle开销大,输出大量小文件)
hadoop streaming
技术架构
streaing在JVM和map/reduce进程之间,通过系统标准输入和系统标准输出交换数据
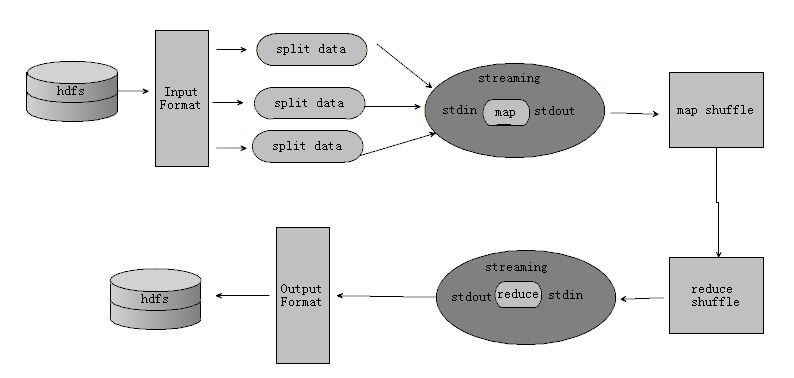
优点
1 支持任意语言编程
2 开发效率高
缺点
1 会造成数据的二次拷贝
2 默认只能处理文本数据
常用命令行选项
| 选项 | 含义 | 必填/可选 | 备注 |
|---|---|---|---|
| -input | 指定作业的输入文件的hdfs路径 | 必填 | 支持使用*通配符,支持指定多个文件或目录(多个使用,分隔),可以多次使用 |
| -output | 指定作业输出的hdfs目录 | 必填 | 目录必须不存在,并且执行作业任务的用户拥有创建该目录的权限,只能使用一次 |
| -mapper | 用户自己写的map程序 | 必填 | 指示怎么执行map程序 |
| -reducer | 用户自己写的reduce程序 | 可选 | 指示怎么执行reduce程序 |
| -file | 提交单个文件到hdfs中 | 可选 | 程序代码文件,配置文件等,用于计算节点下载到本地,然后运行 |
| -jobconf | 提交作业时的一些配置属性 | 可选 | 配置作业相关的参数,示例:mapred.job.name="xxxx" |
| -cacheFile | 任务相关文件已上传至hdfs,希望从hdfs拉取文件到本地 | 可选 | hdfs://host:port/path/to/file#linkname选项在计算节点缓存文件,Streaming程序通过./linkname访问文件 |
| -cacheArchive | 同-cacheFile类似,只不过由文件变成了压缩后的目录 | 可选 | 同上 |
| -partitioner | 指定用于分区的类 | 可选 | 示例:org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner |
常用提交作业时配置属性
| 选项 | 含义 |
|---|---|
| mapred.reduce.tasks | 指定作业reduce任务数量,默认是1个 |
| mapred.job.name | 作业名 |
| mapred.job.priority | 作业优先级 |
| mapred.job.map.capacity | 最多同时运行map任务数 |
| mapred.job.reduce.capacity | 最多同时运行reduce任务数 |
| mapred.task.timeout | 任务没有响应(输入输出)的最大时间 |
| mapred.compress.map.output | map的输出是否压缩 |
| mapred.map.output.compression.codec | map的输出压缩格式 |
| mapred.output.compress | reduce的输出是否压缩 |
| mapred.output.compression.codec | reduce的输出压缩方式 |
| stream.map.output.field.separator | map输出分隔符 |
| stream.num.map.output.key.fields | map输出中指定用于key的字段数 |
| num.key.fields.for.partition | map输出中指定用于分区的字段数 |
| mapred.text.key.partitioner.options | 指定用于分区的字段,示例:指定第2个,第3个字段用于分区,xx=-k2,3 |
参考资料
【0】八斗学院mapreduce内部学习资料
【1】MapReduce Tutorial
https://hadoop.apache.org/docs/current1/mapred_tutorial.html
【2】Hadoop Streaming
http://hadoop.apache.org/docs/current/hadoop-streaming/HadoopStreaming.html
mapreduce v1.0学习笔记的更多相关文章
- HDFS v1.0学习笔记
hdfs是一个用于存储大文件的分布式文件系统,是apache下的一个开源项目,使用java实现.它的设计目标是可以运行在廉价的设备上,运行在大多数的系统平台上,高可用,高容错,易于扩展. 适合场景 存 ...
- DirectX 总结和DirectX 9.0 学习笔记
转自:http://www.cnblogs.com/graphics/archive/2009/11/25/1583682.html DirectX 总结 DDS DirectXDraw Surfac ...
- 一起学ASP.NET Core 2.0学习笔记(二): ef core2.0 及mysql provider 、Fluent API相关配置及迁移
不得不说微软的技术迭代还是很快的,上了微软的船就得跟着她走下去,前文一起学ASP.NET Core 2.0学习笔记(一): CentOS下 .net core2 sdk nginx.superviso ...
- vue2.0学习笔记之路由(二)路由嵌套+动画
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- vue2.0学习笔记之路由(二)路由嵌套
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- hdcms v5.7.0学习笔记
hdcms v5.7.0学习笔记 https://note.youdao.com/ynoteshare1/index.html?id=c404d63ac910eb15a440452f73d6a6db& ...
- dhtmlxgrid v3.0学习笔记
dhtmlxgrid v3.0学习笔记 分类: dhtmlx JavaScript2012-01-31 15:41 1744人阅读 评论(0) 收藏 举报 stylesheetdatecalendar ...
- OAuth 2.0学习笔记
文章目录 OAuth的作用就是让"客户端"安全可控地获取"用户"的授权,与"服务商提供商"进行互动. OAuth在"客户端&quo ...
- 一起学ASP.NET Core 2.0学习笔记(一): CentOS下 .net core2 sdk nginx、supervisor、mysql环境搭建
作为.neter,看到.net core 2.0的正式发布,心里是有点小激动的,迫不及待的体验了一把,发现速度确实是快了很多,其中也遇到一些小问题,所以整理了一些学习笔记: 阅读目录 环境说明 安装C ...
随机推荐
- [Swift通天遁地]四、网络和线程-(6)检测网络连接状态
★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★★➤微信公众号:山青咏芝(shanqingyongzhi)➤博客园地址:山青咏芝(https://www.cnblogs. ...
- $P2299 Mzc和体委的争夺战$
\(problem\) #ifdef Dubug #endif #include <bits/stdc++.h> using namespace std; typedef long lon ...
- javascript特殊值常量
Infinity 表示无穷大的特殊值.当数字运算结果超出javascript能表示的数字范围时. Nan 特殊的非数字值(not a number).0除0.数字运算符的操作数为字符等情况. Numb ...
- 浅谈Java中的hashcode方法以及equals方法
哈希表这个数据结构想必大多数人都不陌生,而且在很多地方都会利用到hash表来提高查找效率.在Java的Object类中有一个方法: public native int hashCode(); 根据这个 ...
- 整合springboot,angular2,可以前后台交互数据
改造了一下angular2官方文档中的hero项目,让其可以进行后台的交互, https://github.com/DACHUYIN 源码在上面...博客就不写了....
- C#——数据库的访问
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- mybatis中映射文件和实体类的关联性
mybatis的映射文件写法多种多样,不同的写法和用法,在实际开发过程中所消耗的开发时间.维护时间有很大差别,今天我就把我认为比较简单的一种映射文件写法记录下来,供大家修改建议,争取找到一个最优写法~ ...
- python发送文本邮件
#!/usr/bin/env python #coding=utf-8 #Author: Ca0Gu0 import time import smtplib from email.mime.text ...
- HDU_5734_数学推公式
题意:给一个向量W={w1,w2……,wn},和一个向量B,B的分量只能为1和-1.求||W-αB||²的最小值. 思路:一来一直在想距离的问题,想怎么改变每一维的值才能使这个向量的长度最小,最后无果 ...
- Object.keys() https://developer.mozilla.org/zh-CN/docs/Web/JavaScript/Reference/Global_Objects/Object/keys
Object.keys() 方法会返回一个由一个给定对象的自身可枚举属性组成的数组,数组中属性名的排列顺序和使用for...in 循环遍历该对象时返回的顺序一致 (两者的主要区别是 一个 for-in ...