Mysqldump逻辑备份与恢复
文档结构:
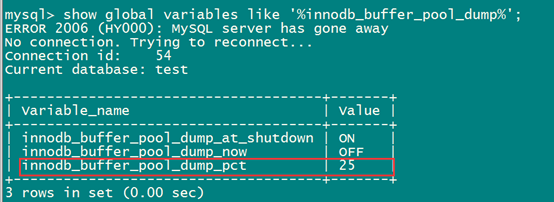
mysqldump备份影响性能,可能会把内存里面的热数据给冲刷掉,5.7后,新增一个参数,innodb_buffer_pool_dump_pct,控制每个innodb_buffer中转存活跃的使用innodb buffer pages的比例,只有当数据在1s内再次被访问时,才能放到热区域内,避免热数据被刷掉,默认值25%。
重要的参数说明:
--single-transaction
用于保证innodb 备份数据时的一致性,配合RR隔离级别一起使用;当发起事物时,读取一个事实的快照,直到备份结束时,都不会读取到本事物开始之前提交的任何数据(这个参数相当重要)
--all-databases (-A)
备份所有数据库。
--master-data
该参数有1和2,如果等于1 ,就会在备份出来的文件中添加一个change master的语句(后期配置搭建主从架构);如果值等于2,就会在备份出来的文件中添加一个change master语句,并在语句前面添加注释符号(后期配置搭建主从架构)。
--dump-slave
该参数用于从库端备份数据,在线搭建新的从库时使用。
该参数也有1,2两个值,值为1是,也是在备份出来的文件中添加一个change master的语句;值为2时,则会在change master命令前增加注释信息。
--no-create-info(-t)
备份过程中,只备份表数据,并不备份表结构。
--no-data
备份过程中,只备份表结构,并不备份表数据。
--complete-insert
使用完整的insert语句会包含表中的列信息,这么做可以提高插入效率。
--databases
备份多个数据库。
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --set-gtid-purged=OFF --databases sys test > sys_test.sql
--default-character-set
字符集,MYSQL目前默认字符集,要与备份出的表的字符集保持一致。
--quick
相当于加 sql_no_query,意味着并不会读取缓存中的数据。
--where=name
按条件备份出想要的数据。
备份所有数据库

/usr/local/mysql5.7/bin/mysqldump --single-transaction -S /tmp/mysql3307.sock --set-gtid-purged=OFF -uroot -pmysql -A >all_20180524.sql
5.7已经开启了GTID,备份过程中不想带GTID信息,加上--set-gtid-purged=OFF
恢复全库的过程
先删除test 测试库
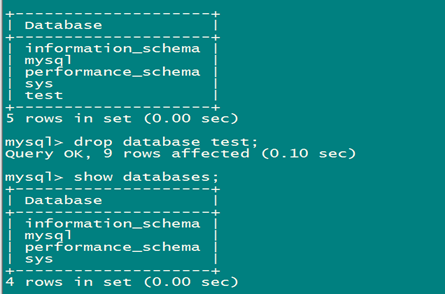
mysql -S /tmp/mysql3307.sock -uroot -pmysql < all_20180524.sql

查看恢复后的数据库:
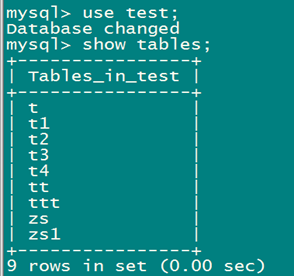
备份单个数据库test的过程:
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF test > 20180524test.sql

恢复单库test的过程:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
| test |
+--------------------+
5 rows in set (0.00 sec)
mysql> drop database test;
Query OK, 9 rows affected (0.18 sec)
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
mysql> create database test;
Query OK, 1 row affected (0.00 sec)
mysql -S /tmp/mysql3307.sock -uroot -pmysql test < 20180524test.sql

mysql> use test;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+----------------+
| Tables_in_test |
+----------------+
| t |
| t1 |
| t2 |
| t3 |
| t4 |
| tt |
| ttt |
| zs |
| zs1 |
+----------------+
9 rows in set (0.00 sec)
备份单表:
mysql> select TABLE_SCHEMA,TABLE_NAME,TABLE_TYPE,ENGINE,TABLE_ROWS from information_schema.TABLES where table_schema='test';
+--------------+------------+------------+--------+------------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_TYPE | ENGINE | TABLE_ROWS |
+--------------+------------+------------+--------+------------+
| test | t | BASE TABLE | InnoDB | 6 |
| test | t1 | BASE TABLE | InnoDB | 971290 |
| test | t2 | BASE TABLE | InnoDB | 3 |
| test | t3 | BASE TABLE | InnoDB | 3 |
| test | t4 | BASE TABLE | InnoDB | 3 |
| test | tt | BASE TABLE | InnoDB | 4 |
| test | ttt | BASE TABLE | InnoDB | 2 |
| test | zs | BASE TABLE | InnoDB | 3 |
| test | zs1 | BASE TABLE | InnoDB | 4 |
+--------------+------------+------------+--------+------------+
9 rows in set (0.00 sec)

mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF test t1 >20180524_t1.sql
恢复表的过程:
先删除,在恢复。
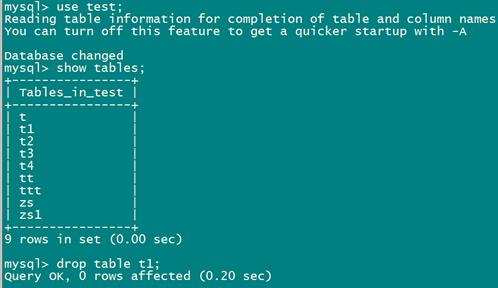
mysql -S /tmp/mysql3307.sock -uroot -pmysql test < 20180524_t1.sql

注意:
单表恢复的时候,不需要写表的名字,只需要写库的名字。
备份test库t1表的where 条件
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF test t1 --where='RECEIVETIME >="2018-08-31 00:00:00" and RECEIVETIME <="2018-10-09 00:00:00"' >/data_returnreport.sql
备份test库t1表的结构
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF -d test t1 > 20180504t1_meta.sql

或者
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF --no-data test t1 > 20180504t1_meta01.sql

把-d 换成--no-date
备份test库中t表中数据信息:
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF -t test t1 >20180524t1_data.sql

从表结构备份和表数据备份中恢复单表
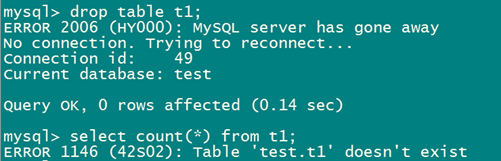
先恢复表结构,在往里面导数据

查看表结构:
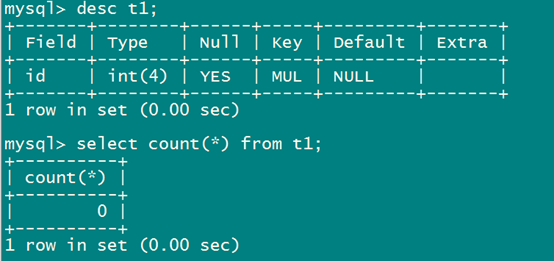
恢复数据:
mysql -S /tmp/mysql3307.sock -uroot -pmysql test <20180524t1_data.sql
备份test库指定条件数据
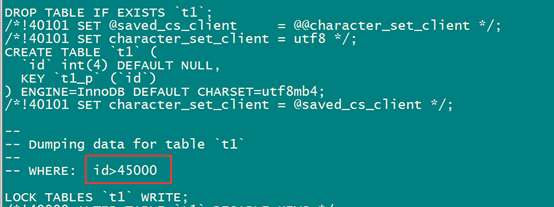
mysqldump -S /tmp/mysql3307.sock -uroot -pmysql --single-transaction --set-gtid-purged=OFF test t1 --where="id>45000" >20180524_t_part.sql

注意:
where 后面建议为双引号,以防止不识别条件。
查看备份文件:
Mysqldump逻辑备份与恢复的更多相关文章
- Oracle逻辑备份与恢复
1. 备份的类型 按照备份方式的不同,可以把备份分为两类: 1.1 逻辑备份:指通过逻辑导出对数据进行备份.将数据库中的用户对象导出到一个二进制文件中,逻辑备份使用导入导出工具:EXPDP/IMP ...
- 数据库(表)的逻辑备份与恢复<四>
数据库(表)的逻辑备份与恢复 介绍 逻辑备份是指使用工具 export 将数据对象的结构和数据导出到文件的过程,逻辑恢复是指当数据库对象被误操作而损坏后使用 工具 import 利用备份的文件把数 ...
- 3. Oracle数据库逻辑备份与恢复
一. Oracle逻辑备份介绍 Oracle逻辑备份的核心就是复制数据:Oracle提供的逻辑备份与恢复的命令有exp/imp,expdp/impdp.当然像表级复制(create table tab ...
- mysqldump 逻辑备份的正确方法【转】
1. 利用mysqldump进行逻辑备份 1)全逻辑备份: mysqldump -uxxx -p --flush-logs --delete-master-logs --all-databases & ...
- Oracle 数据库、表、方案的逻辑备份与恢复
数据库(表)的逻辑备份与恢复 逻辑备份是指使用工具export将数据对象的结构和数据导出到文件的过程,逻辑恢复是指当数据库对象被破坏而使用工具import利用备份的文件把数据对象导入到数据库的过程,逻 ...
- Oracle逻辑备份与恢复(Data Pump)
1. 备份的类型 按照备份方式的不同,可以把备份分为两类: 1.1 逻辑备份:指通过逻辑导出对数据进行备份.将数据库中的用户对象导出到一个二进制文件中,逻辑备份使用导入导出工具:EXPDP/IMPDP ...
- oracle数据处理之逻辑备份与恢复
逻辑备份与恢复 17.1 传统的导入导出exp/imp:传统的导出导入程序指的是exp/imp,用于实施数据库的逻辑备份和恢复. 导出程序exp将数据库中的对象定义和数据备份到一个操作系统二进制文件中 ...
- mysql 开发进阶篇系列 42 逻辑备份与恢复(mysqldump 的完全恢复)
一.概述 在作何数据库里,备份与恢复都是非常重要的.好的备份方法和备份策略将会使得数据库中的数据更加高效和安全.对于DBA来说,进行备份或恢复操作时要考虑的因素大概有如下: (1) 确定要备份的表的存 ...
- mysql 开发进阶篇系列 43 逻辑备份与恢复(mysqldump 的基于时间和位置的不完全恢复)
一. 概述 在上篇讲到了逻辑备份,使用mysqldump工具来备份一个库,并使用完全恢复还原了数据库.在结尾也讲到了误操作是不能用完全恢复的.解决办法是:我们需要恢复到误操作之前的状态,然后跳过误操作 ...
随机推荐
- linux HBA 卡驱动安装
系统环境操作系统 : RHEL5.0设备 DL580G5 HBA 卡:Qlogic 2343连接存储: EVA8100---------------------------------------- ...
- 更改python字符编码以便使用UTF-8的编码url路径
url编码分两种, 一种是unicode, 另一种是gb2312, 今天遇到的一个网站是要将字符编码按照gb2312来编码,用来得到一个先填写blanks后再返回页面的数据,废话少说,需要做的就是先查 ...
- SparkSQL 与 Spark Core的关系
不多说,直接上干货! SparkSQL 与 Spark Core的关系 Spark SQL构建在Spark Core之上,专门用来处理结构化数据(不仅仅是SQL). Spark SQL在Spark C ...
- 聊聊 TCP 中的 KeepAlive 机制
KeepAlive并不是TCP协议规范的一部分,但在几乎所有的TCP/IP协议栈(不管是Linux还是Windows)中,都实现了KeepAlive功能 RFC1122#TCP Keep-Alives ...
- ZBrush为电影制作设计独特的生物概念
任何一个从事3D行业的艺术家,在雕刻和画画方面,都要有牢固的基本技能,还要会使用一些软件.比如今天我们提到的这位概念设计师.插画师和艺术导演Ian Joyner,他在创作新角色之前,都会思考如何以及为 ...
- TensorFlow初学
TensorFlow初学 基本概念 1.激活函数和成本函数 激活函数(activation function):一般是非线性函数,就是每个神经元通过这个函数将原有的来自其他神经的输入做一个非线性变化, ...
- JS怎样写闰年
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- 关于layui.laypage.render 刷新首页没有分页问题
前言: 最近写项目遇到一个问题,就是使用vue里的layui.laypage.render 分页时,刷新首页会只有一页,但后台传来的数据是有50多页的,所有的数据也都一一对应,调了好久debug,终于 ...
- Pyhton学习——Day59
参考博客: http://www.cnblogs.com/wupeiqi/articles/6144178.html Form 1. 验证 2. 生成HTML(保留上次输入内容) 3. 初始化默认是 ...
- Spark 代码走读之 Cache
Spark是基于内存的计算模型,但是当compute chain非常长或者某个计算代价非常大时,能将某些计算的结果进行缓存就显得很方便了.Spark提供了两种缓存的方法 Cache 和 checkPo ...