图解Http协议 url长度限制
http请求报文的格式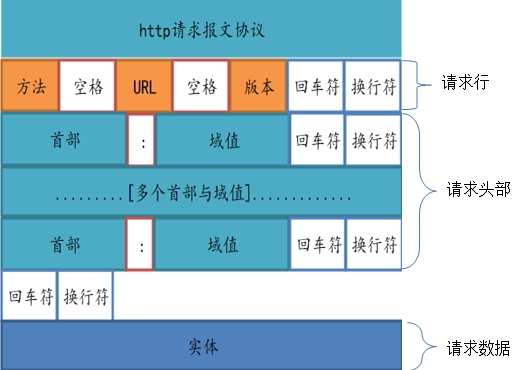
一般请求所带有的属性:
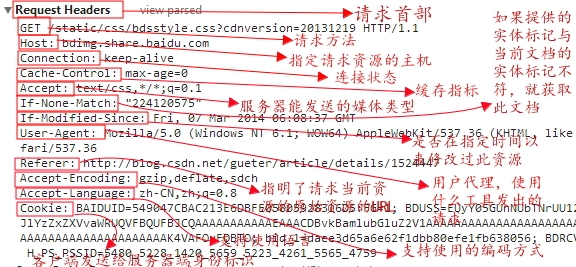
http响应报文的格式: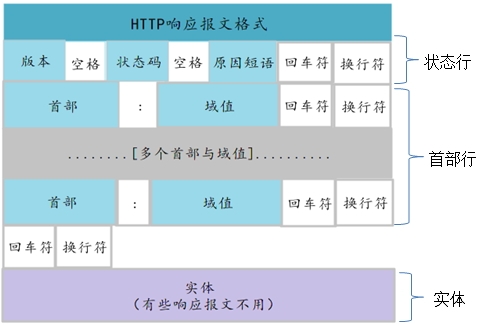
响应首部一般包含如下内容:
一、技术基石及概述
问:什么是HTTP? 答:HTTP是一个客户端和服务器端请求和响应的标准TCP。其实建立在TCP之上的。
当我们打开百度网页时,是这样的:
https://www.baidu.com
多了个S,其实S表示TLS、SSL。在这里不做解释,因此HTTP的技术基石如图所示:

那HTTP协议呢?HTTP协议(HyperText Transfer Protocol),即超文本传输协议是用于服务器传输到客户端浏览器的传输协议。Web上,服务器和客户端利用HTTP协议进行通信会话。有OOP思想的得出结论:其会话的结构是一个简单的请求/响应序列,即浏览器发出请求和服务器做出响应。

二、深入理解技术基石和工作流程
既然HTTP是基于传输层的TCP协议,而TCP协议是面向连接的端到端的协议。因此,使用HTTP协议传输前,首先建立TCP连接,就是因此在谈的TCP链接过程的“三次握手”。如图

在Web上,HTTP协议使用TCP协议而不是UDP协议的原因在于一个网页必须传送很多数据,而且保证其完整性。TCP协议提供传输控制,按顺序组织数据和错误纠正的一系列功能。
一次HTTP操作称为一个事务,其工作过程可分为四步:
1、客户端与服务器需要建立连接。(比如某个超级链接,HTTP就开始了。)
2、建立连接后,发送请求。
3、服务器接到请求后,响应其响应信息。
4、客户端接收服务器所返回的信息通过浏览器显示在用户的显示屏上,然后客户机与服务器断开连接。
建立连接,其实建立在TCP连接基础之上。图解核心工作过程(即省去连接过程)如下:

三、详解工作过程的HTTP报文
HTTP报文由从客户机到服务器的请求和从服务器到客户机的响应构成。
一、请求报文格式如下:
请求行
通用信息头
请求头
实体头
(空行)
报文主体
如图,请求我博客一篇文章时发送的报文内容:

对于其中请求报文详解:
1、请求行
方法字段 + URL + Http协议版本
2、通用信息头
Cache-Control头域:指定请求和响应遵循的缓存机制。
keep-alive 是其连接持续有效【在下面百度的例子,会得到验证】
3、请求头
Host头域,脑补吧
Referer头域:允许客户端指定请求URL的资源地址。
User-Agent头域:请求用户信息。【可以看出一些客户端浏览器的内核信息】
4、报文主体
如图中的 “ p=278 ”一般来说,请求主体少不了请求参数。
二、应答报文格式如下:
状态行
通用信息头
响应头
实体头
(空行)
报文主体
如图,就是这篇博客响应的内容:

对其中响应报文详解:
1、状态行
HTTP协议版本 + 状态码 + 状态代码的文本描述
【比如这里,200 代表请求成功】
2、通用信息头
keep-alive 是其连接持续有效【在下面百度的例子,会得到验证】
Date头域:时间描述
3、响应头
Server头:处理请求的原始服务器的软件信息。
4、实体头
Content-Type头:便是接收方实体的介质类型。(这也表示了你的报文主体是什么。)
(空行)
5、报文主体
这里就是HTML响应页面了,在截图tab页中的response中可查看。
一次简单的请求/响应就完成了。
三、HTTP协议知识补充
请求报文相关:
请求行-请求方法
GET 请求获取Request-URI所标识的资源 POST 在Request-URI所标识的资源后附加新的数据 HEAD 请求获取由Request-URI所标识的资源的响应消息报头 PUT 请求服务器存储一个资源,并用Request-URI作为其标识 DELETE 请求服务器删除Request-URI所标识的资源 TRACE 请求服务器回送收到的请求信息,主要用于测试或诊断 CONNECT 保留将来使用 OPTIONS 请求查询服务器的性能,或者查询与资源相关的选项和需求
响应报文相关:
响应行-状态码
1xx:指示信息–表示请求已接收,继续处理 2xx:成功–表示请求已被成功接收、理解、接受 3xx:重定向–要完成请求必须进行更进一步的操作 4xx:客户端错误–请求有语法错误或请求无法实现 5xx:服务器端错误–服务器未能实现合法的请求
常见的状态码
200 OK
请求成功(其后是对GET和POST请求的应答文档。)
304 Not Modified
未按预期修改文档。客户端有缓冲的文档并发出了一个条件性的请求(一般是提供If-Modified-Since头表示客户只想比指定日期更新的文档)。服务器告诉客户,原来缓冲的文档还可以继续使用。
404 Not Found
服务器无法找到被请求的页面。
500 Internal Server Error
请求未完成。服务器遇到不可预知的情况。
比如304,在浏览器第一次打开百度时,如图所示:

刷新一下:

这上面的304就证明了
1、304状态码:有些图片和js文件在本地客户端缓存,再次请求后,缓存的文件可以使用。
2、以上所以HTTP请求,只靠一个TCP连接,这就是所谓的持久连接。
四、关于HTTP协议的Web应用框架或者规范
JavaEE的人会知道Servlet规范。其中Web应用容器都实现了HTTP协议中的对象,即请求和响应对象。比如 javax.servlet.http.HttpServletResponse 对象中肯定有对状态码描述,如图

至于如何使用它们,坐等系列文章吧。
五、总结
回顾全文,HTTP协议其实就是我们对话一样,语言就是其中的协议。所以掌握HTTP协议明白以下几点就好:
1、用什么通过HTTP协议通信
2、怎么通过HTTP协议通信
http://www.cnblogs.com/Alandre/p/4515323.html
HTTP消息中header头部信息的讲解
HTTP Request的Header信息
1、HTTP请求方式
如下表:
|
GET |
向Web服务器请求一个文件 |
|
POST |
向Web服务器发送数据让Web服务器进行处理 |
|
PUT |
向Web服务器发送数据并存储在Web服务器内部 |
|
HEAD |
检查一个对象是否存在 |
|
DELETE |
从Web服务器上删除一个文件 |
|
CONNECT |
对通道提供支持 |
|
TRACE |
跟踪到服务器的路径 |
|
OPTIONS |
查询Web服务器的性能 |
说明:
主要使用到“GET”和“POST”。
实例:
POST /test/tupian/cm HTTP/1.1
分成三部分:
(1)POST:HTTP请求方式
(2)/test/tupian/cm:请求Web服务器的目录地址(或者指令)
(3)HTTP/1.1: URI(Uniform Resource Identifier,统一资源标识符)及其版本
备注:
在Ajax中,对应method属性设置。
2、Host
说明:
请求的web服务器域名地址
3、User-Agent
说明:
HTTP客户端运行的浏览器类型的详细信息。通过该头部信息,web服务器可以判断到当前HTTP请求的客户端浏览器类别。
实例:
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.8.1.11) Gecko/20071127 Firefox/2.0.0.11
4、Accept
说明:
指定客户端能够接收的内容类型,内容类型中的先后次序表示客户端接收的先后次序。
例如:
Accept:text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,text/plain;q=0.8,image/png,*/*;q=0.5
备注:
在Prototyp(1.5)的Ajax代码封装中,将Accept默认设置为“text/javascript, text/html, application/xml, text/xml, */*”。这是因为Ajax默认获取服务器返回的Json数据模式。
在Ajax代码中,可以使用XMLHttpRequest 对象中setRequestHeader函数方法来动态设置这些Header信息。
5、Accept-Language
说明:
指定HTTP客户端浏览器用来展示返回信息所优先选择的语言。
实例:
Accept-Language: zh-cn,zh;q=0.5
这里默认为中文。
6、Accept-Encoding
说明:
指定客户端浏览器可以支持的web服务器返回内容压缩编码类型。表示允许服务器在将输出内容发送到客户端以前进行压缩,以节约带宽。而这里设置的就是客户端浏览器所能够支持的返回压缩格式。
实例:
Accept-Encoding: gzip,deflate
备注:
其实在百度很多产品线中,apache在给客户端返回页面数据之前,将数据以gzip格式进行压缩。
7、Accept-Charset
说明:
浏览器可以接受的字符编码集。
实例:
Accept-Charset: gb2312,utf-8;q=0.7,*;q=0.7
8、Content-Type
说明:
显示此HTTP请求提交的内容类型。一般只有post提交时才需要设置该属性。
实例:
Content-type: application/x-www-form-urlencoded;charset:UTF-8
有关Content-Type属性值可以如下两种编码类型:
(1)“application/x-www-form-urlencoded”: 表单数据向服务器提交时所采用的编码类型,默认的缺省值就是“application/x-www-form-urlencoded”。 然而,在向服务器发送大量的文本、包含非ASCII字符的文本或二进制数据时这种编码方式效率很低。
(2)“multipart/form-data”: 在文件上载时,所使用的编码类型应当是“multipart/form-data”,它既可以发送文本数据,也支持二进制数据上载。
当提交为单单数据时,可以使用“application/x-www-form-urlencoded”;当提交的是文件时,就需要使用“multipart/form-data”编码类型。
在Content-Type属性当中还是指定提交内容的charset字符编码。一般不进行设置,它只是告诉web服务器post提交的数据采用的何种字符编码。
一般在开发过程,是由前端工程与后端UI工程师商量好使用什么字符编码格式来post提交的,然后后端ui工程师按照固定的字符编码来解析提交的数据。所以这里设置的charset没有多大作用。
9、Connection
说明:
表示是否需要持久连接。如果web服务器端看到这里的值为“Keep-Alive”,或者看到请求使用的是HTTP 1.1(HTTP 1.1默认进行持久连接),它就可以利用持久连接的优点,当页面包含多个元素时(例如Applet,图片),显著地减少下载所需要的时间。要实现这一点, web服务器需要在返回给客户端HTTP头信息中发送一个Content-Length(返回信息正文的长度)头,最简单的实现方法是:先把内容写入ByteArrayOutputStream,然 后在正式写出内容之前计算它的大小。
实例:
Connection: keep-alive
10、Keep-Alive
说明:
显示此HTTP连接的Keep-Alive时间。使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
以前HTTP请求是一站式连接,从HTTP/1.1协议之后,就有了长连接,即在规定的Keep-Alive时间内,连接是不会断开的。
实例:
Keep-Alive: 300
11、cookie
说明:
HTTP请求发送时,会把保存在该请求域名下的所有cookie值一起发送给web服务器。
12、Referer
说明:
包含一个URL,用户从该URL代表的页面出发访问当前请求的页面
Responses 部分
| Header | 解释 | 示例 |
|---|---|---|
| Accept-Ranges | 表明服务器是否支持指定范围请求及哪种类型的分段请求 | Accept-Ranges: bytes |
| Age | 从原始服务器到代理缓存形成的估算时间(以秒计,非负) | Age: 12 |
| Allow | 对某网络资源的有效的请求行为,不允许则返回405 | Allow: GET, HEAD |
| Cache-Control | 告诉所有的缓存机制是否可以缓存及哪种类型 | Cache-Control: no-cache |
| Content-Encoding | web服务器支持的返回内容压缩编码类型。 | Content-Encoding: gzip |
| Content-Language | 响应体的语言 | Content-Language: en,zh |
| Content-Length | 响应体的长度 | Content-Length: 348 |
| Content-Location | 请求资源可替代的备用的另一地址 | Content-Location: /index.htm |
| Content-MD5 | 返回资源的MD5校验值 | Content-MD5: Q2hlY2sgSW50ZWdyaXR5IQ== |
| Content-Range | 在整个返回体中本部分的字节位置 | Content-Range: bytes 21010-47021/47022 |
| Content-Type | 返回内容的MIME类型 | Content-Type: text/html; charset=utf-8 |
| Date | 原始服务器消息发出的时间 | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| ETag | 请求变量的实体标签的当前值 | ETag: “737060cd8c284d8af7ad3082f209582d” |
| Expires | 响应过期的日期和时间 | Expires: Thu, 01 Dec 2010 16:00:00 GMT |
| Last-Modified | 请求资源的最后修改时间 | Last-Modified: Tue, 15 Nov 2010 12:45:26 GMT |
| Location | 用来重定向接收方到非请求URL的位置来完成请求或标识新的资源 | Location: http://www.zcmhi.com/archives/94.html |
| Pragma | 包括实现特定的指令,它可应用到响应链上的任何接收方 | Pragma: no-cache |
| Proxy-Authenticate | 它指出认证方案和可应用到代理的该URL上的参数 | Proxy-Authenticate: Basic |
| refresh | 应用于重定向或一个新的资源被创造,在5秒之后重定向(由网景提出,被大部分浏览器支持) |
Refresh: 5; url=
http://www.zcmhi.com/archives/94.html
|
| Retry-After | 如果实体暂时不可取,通知客户端在指定时间之后再次尝试 | Retry-After: 120 |
| Server | web服务器软件名称 | Server: Apache/1.3.27 (Unix) (Red-Hat/Linux) |
| Set-Cookie | 设置Http Cookie | Set-Cookie: UserID=JohnDoe; Max-Age=3600; Version=1 |
| Trailer | 指出头域在分块传输编码的尾部存在 | Trailer: Max-Forwards |
| Transfer-Encoding | 文件传输编码 | Transfer-Encoding:chunked |
| Vary | 告诉下游代理是使用缓存响应还是从原始服务器请求 | Vary: * |
| Via | 告知代理客户端响应是通过哪里发送的 | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | 警告实体可能存在的问题 | Warning: 199 Miscellaneous warning |
| WWW-Authenticate | 表明客户端请求实体应该使用的授权方案 | WWW-Authenticate: Basic |
Http协议中的各种长度限制总结
HTTP1.0的格式
request(HTTP请求消息)
结构:一个请求行.部分消息头,以及实体内容,其中的一些消息内容都是可选择的.消息头和实体内容之间要用空行分开.
GET /index.html HTTP/1.1 //请求头,下面都是消息头.
Accept: */*
Accept-Languang:en-us
Connection:keep-alive
Host:localhost
Referer:HTTP://localhost/index.html
User-Agent:Mozilla/4.0
Accept-Encoding:gzip,deflate//到上面都是消息头,下面一个空行表示完了,接下来是实体内容.
Response响应消息头
在接收并解析请求消息后,服务器以 HTTP 响应消息响应。相当服务器对客户的http的回应
结构:一个状态行.部分消息
头,以及实体内容,其中的一些消息内容都是可选择的.消息头和实体内容之间要用空行分开.
HTTP/1.1 200ok //状态行.下面为消息头
Server:Apache2.2
Date:Thu, 13 Jul 2008 16:29:46 GMT
Content-Length:2222
Content-Type:text/html
Cache_control:private //和请求消息头一样下面有一个空行
注意:使用get的方法的请求消息中是不能包含实体内容的,只有使用post,put和delete的方法请求消息中才能有实体内容.对 HTTP1.1来讲,如果HTTP中有实体内容,但没有使用权chunked传输编码.那么消息头部分必须包含内容长度字段.不然不知什么时候内容才结 束。HTTP1.1中一定要有host字段
以上消息头的结构:每个消息头都包含一个头字段名称,然后依次是冒号,空格值,回车和换行符,字段不区分大小写.对消息头中的消息头可以任何顺序排列.
消息头可以分为信息头,请求头,响应头,实体头四类
如果有多个选项,可以用逗号分隔Accept-Encoding:gzip ,deflate
1. URL长度限制
在Http1.1协议中并没有提出针对URL的长度进行限制,RFC协议里面是这样描述的,HTTP协议并不对URI的长度做任何的限制,服务器端必须能够处理任何它们所提供服务多能接受的URI,并且能够处理无限长度的URI,如果服务器不能处理过长的URI,那么应该返回414状态码。
虽然Http协议规定了,但是Web服务器和浏览器对URI都有自己的长度限制。
服务器的限制:我接触的最多的服务器类型就是Nginx和Tomcat,对于url的长度限制,它们都是通过控制http请求头的长度来进行限制的,
nginx的配置参数为large_client_header_buffers,
tomcat的请求配置参数为maxHttpHeaderSize,都是可以自己去进行设置。
浏览器的限制:每种浏览器也会对url的长度有所限制,下面是几种常见浏览器的url长度限制:(单位:字符)
IE : 2803
Firefox:65536
Chrome:8182
Safari:80000
Opera:190000
对于get请求,在url的长度限制范围之内,请求的参数个数没有限制。
2. Post数据的长度限制
Post数据的长度限制与url长度限制类似,也是在Http协议中没有规定长度限制,长度限制可以在服务器端配置最大http请求头长度的方式来实现。
3. Cookie的长度限制
Cookie的长度限制分这么几个方面来总结。
(1) 浏览器所允许的每个域下的最大cookie数目,没有去自己测试,从网上找到的资料大概是这么个情况
IE :原先为20个,后来升级为50个
Firefox: 50个
Opera:30个
Chrome:180个
Safari:无限制
当Cookie数超过限制数时浏览器的行为:IE和Opera会采用LRU算法将老的不常使用的Cookie清除掉,Firefox的行为是随机踢出某些Cookie的值。当然无论怎样的策略,还是尽量不要让Cookie数目超过浏览器所允许的范围。
(2) 浏览器所允许的每个Cookie的最大长度
Firefox和Safari:4079字节
Opera:4096字节
IE:4095字节
(3) 服务器中Http请求头长度的限制。Cookie会被附在每次http请求头中传递给服务器,因此还会受到服务器请求头长度的影响。
4. Html5 LocalStorage
Html5提供了本地存储机制来供Web应用在客户端存储数据,尽管这个并不属于Http协议的一部分,但是随着Html5的流行,我们可能需要越来越多使用LocalStorage,甚至当它普及的时候跟它打交道就会同今天我们跟Cookie打交道一样多。
对于LocalStorage的长度限制,同Cookie的限制类似,也是浏览器针对域来限制,只不过cookie限制的是个数,LocalStorage限制的是长度:
Firefox\Chrome\Opera都是允许每个域的最大长度为5MB
但是这次IE比较大方,允许的最大长度是10MB
https://blog.csdn.net/liayn523/article/details/70243694
图解Http协议 url长度限制的更多相关文章
- Java EE : 一、图解Http协议
目录 Java EE : 一.图解Http协议 Java EE : 二.图解 Cookie(小甜饼) Java EE : 三.图解Session(会话) 概述 一.技术基石及概述 二.深入理解技术基石 ...
- HTTP中的URL长度限制(资料整理)
HTTP中的URL长度限制 首先,其实http 1.1 协议中对url的长度是不受限制的,协议原文: The HTTP protocol does not place any a priori l ...
- 浏览器和服务器 对http请求(post get) url长度限制
1. GET URL长度限制 在Http1.1协议中并没有提出针对URL的长度进行限制,RFC协议里面是这样描述的,HTTP协议并不对URI的长度做任何的限制,服务器端 必须能够处理任何它们所提供服 ...
- HTTP中的URL长度限制
首先,其实http 1.1 协议中对url的长度是不受限制的,协议原文: The HTTP protocol does not place any a priori limit on the leng ...
- url长度
今天在测试Email Ticket的时候发现在进行Mark as Read/Unread操作时,请求是通过GET方式进行的.URL中列出了所有参与该操作的Ticket Id.于是,我想起GET请求是有 ...
- 浏览器和服务器 对post get请求 url长度限制
1. URL长度限制 2. Post数据的长度限制 3. Cookie的长度限制 1. GET URL长度限制 在Http1.1协议中并没有提出针对URL的长度进行限制,RFC协议里面是这样描述的, ...
- 图解ARP协议
前置知识:MAC地址 在说到ARP协议之前,需要了解MAC地址,在OSI七层模型中,第三层是网络层,要解决的是下一跳机制确定的设备位置,具体来说就是网卡地址,MAC地址用于在网络中唯一标示一个网卡,一 ...
- ASP.NET MVC, Url长度过长问题解决,404.15问题
最近在处理一个问题的时候,发现他们存在一个大量数据放在URL中传递的过程,当数据达到一定数量的时候就会报出404.15问题. 运行环境是在IIS8,经过查询之后发现,URL此时最大长度为2048,肯定 ...
- URL长度过长的问题
最近项目中很多跨域的问题,有时候跨域要传递很多参数,甚至有时候要传递整个对象,处理的方法是把对象转换成JSON形式的字符串再传递.此时该JSON字符串就比较长,作为参数附加到URL后面,URL就会变得 ...
随机推荐
- 【3005】拦截导弹问题(noip1999)
Time Limit: 3 second Memory Limit: 2 MB 某国为了防御帝国的导弹袭击,开发出一种导弹拦截系统,但是这种拦截系统有一个缺陷:虽然他的第一发炮弹能达到任意的高度,但是 ...
- iOS开发Quartz2D十二:手势解锁实例
一:效果如图: 二:代码: #import "ClockView.h" @interface ClockView() /** 存放的都是当前选中的按钮 */ @property ( ...
- css3-7 如何让页面元素水平垂直都居中(元素定位要用css定位属性)
css3-7 如何让页面元素水平垂直都居中(元素定位要用css定位属性) 一.总结 一句话总结:元素定位要用css定位属性,而且一般脱离文档流更加好操作.先设置为绝对定位,上左都50%,然后margi ...
- mysqldump 不需要密码
-p 参数比较特殊,正确语法是 -ppassword,即-p和密码中间不能有空格. 请教:数据库备份命令如果这样写mysqldump -u root -p dataname>/home/data ...
- CentOS下安装和配置MySQL-JDK-Tomcat-Nginx(个人官网环境搭建手册)
今天,重新弄我的个人云主机的环境,准备运营自己用Java写的个人官网等网站. 服务器环境:阿里云CentOS 6.4位 包括以下脚本在内的绝大部分命令和脚本,都是我亲自执行过,靠谱的. 完整的&quo ...
- css样式继承规则详解
css样式继承规则详解 一.总结 一句话总结:继承而发生样式冲突时,最近祖先获胜(最近原则). 1.继承中哪些样式不会被继承? 多数边框类属性,比如象Padding(补白),Margin(边界),背景 ...
- 编辑器sublime、终端运行python
sublime编辑器 Sublime Text 是一个代码编辑器(Sublime Text 2是收费软件,但可以无限期试用) Sublime Text是由程序员Jon Skinner于2008年1月份 ...
- 关于http传输base64加密串的问题
问题场景: 在使用luacurl进行http post请求的时候,post的内容是一串json串.json传里面的某个字段带上了base64加密的串. 如post的内容如下: xxxxxx{" ...
- 以Graphicslayer为管理组来管理Element.
转自原文 以Graphicslayer为管理组来管理Element. 前言 在AE开发过程中,我们经常使用Element(元素).它的出现让地图与用户之间的交互增加了不少的效果.在地图上,可以通过各种 ...
- 小强的HTML5移动开发之路(34)——jQuery中的选择器
一.jQuery是什么? jQuery是由美国人John Resig创建,至今吸引了来自世界各地的众多javascript高手加入其中. jQuery的创始人和技术领袖,目前在Mozilla担任Jav ...