Python爬虫基础--爬取车模照片
import urllib
from urllib import request, parse
from lxml import etree
class CarModel:
def __init__(self, search_name='车模', search_page=50, begin_page=1):
self.name = search_name
self.url = 'https://tieba.baidu.com/f?'
self.search_page = search_page
self.begin_page = begin_page
self.tie_ba_list = []
self.number = 0
self.header = {'User_agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36'}
def download_img(self, link, page_num, index01, index02):
img_ = urllib.request.Request(link)
respos = urllib.request.urlopen(img_)
img_data = respos.read()
file = open('../image/{0}_{1}_{2}.jpg'.format(page_num, index01, index02), 'wb')
file.write(img_data)
file.close()
def find_image(self, link, page_num, index01):
requests = urllib.request.Request(headers=self.header, url=link)
responses = urllib.request.urlopen(requests)
html = responses.read() # 获取html信息
new_html = etree.HTML(html) # 将html转换
image_link = new_html.xpath('//img[@class="BDE_Image"]/@src') # xpath进行信息抽取
tmp_num = 0
for i in image_link:
tmp_num += 1 # 进行图片编号
self.download_img(i, page_num, index01, tmp_num)
def find_link(self, link, page_num):
requests = urllib.request.Request(headers=self.header, url=link)
responses = urllib.request.urlopen(requests)
html = responses.read().decode('utf-8')
new_html = etree.HTML(html)
# 寻找图片超链接
link_list = new_html.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href')
tmp_num = 0
for i in link_list:
tmp_num += 1
tmp_link = 'https://tieba.baidu.com{0}'.format(i)
self.find_image(tmp_link, page_num, tmp_num)
def begin(self):
for i in range(self.begin_page, self.search_page+1):
tmp_pn = (i-1)*50
words_01 = {'kw': self.name}
words_02 = {'pn': tmp_pn}
words_01 = urllib.parse.urlencode(words_01)
words_02 = urllib.parse.urlencode(words_02)
tmp_url ='{0}{1}&ie=utf-8&{2}'.format(self.url, words_01, words_02)
self.find_link(tmp_url, tmp_pn/50)
if __name__ == '__main__':
car = CarModel()
car.begin()
最终爬取效果
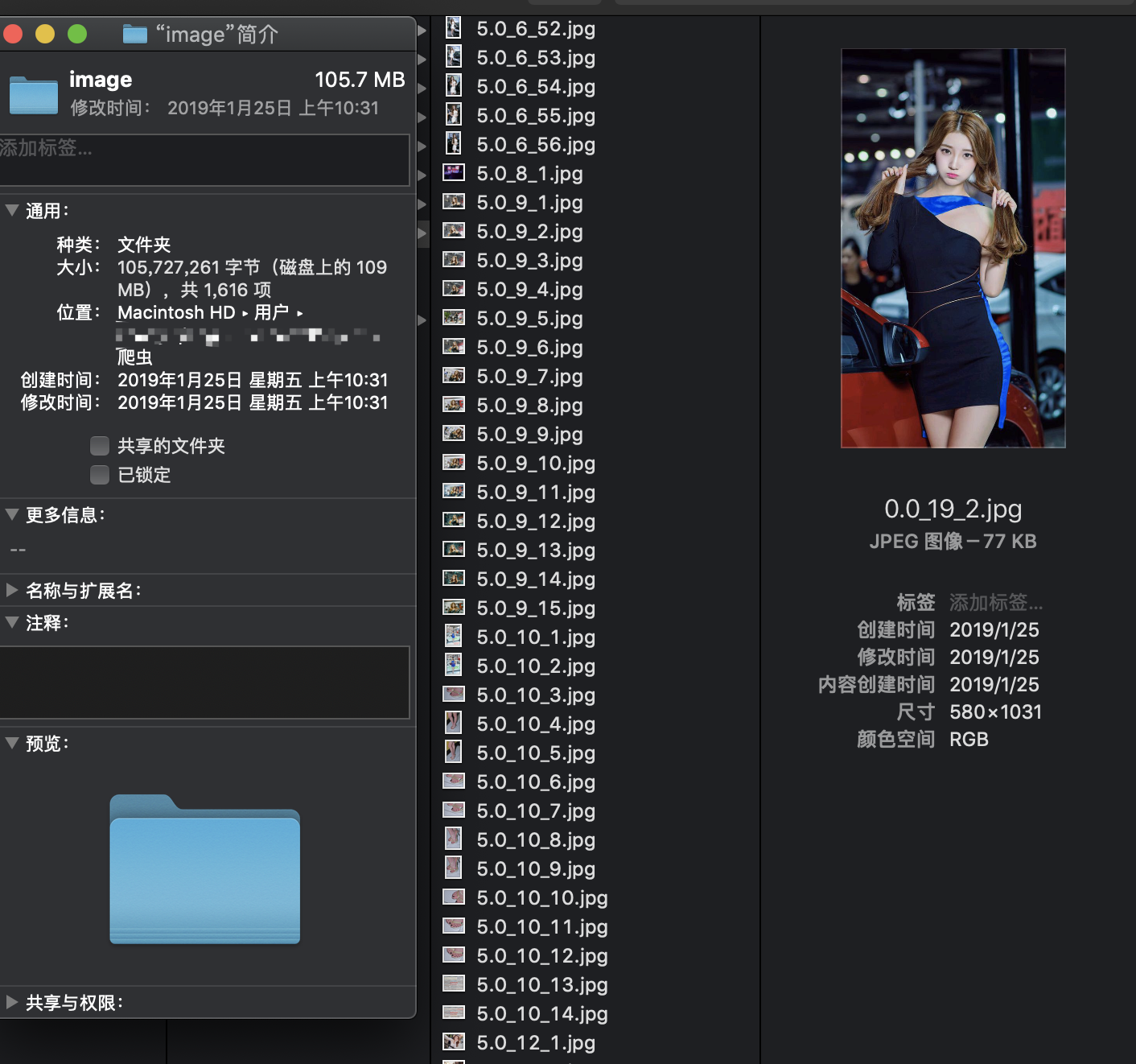
Python爬虫基础--爬取车模照片的更多相关文章
- Python爬虫之爬取淘女郎照片示例详解
这篇文章主要介绍了Python爬虫之爬取淘女郎照片示例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧 本篇目标 抓取淘宝MM ...
- python --爬虫基础 --爬取今日头条 使用 requests 库的基本操作, Ajax
'''思路一: 由于是Ajax的网页,需要先往下划几下看看XHR的内容变化二:分析js中的代码内容三:获取一页中的内容四:获取图片五:保存在本地 使用的库1. requests 网页获取库 2.fro ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- from appium import webdriver 使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium)
使用python爬虫,批量爬取抖音app视频(requests+Fiddler+appium) - 北平吴彦祖 - 博客园 https://www.cnblogs.com/stevenshushu/p ...
- Python爬虫之爬取站内所有图片
title date tags layut Python爬虫之爬取站内所有图片 2018-10-07 Python post 目标是 http://www.5442.com/meinv/ 如需在非li ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- python 爬虫之爬取大街网(思路)
由于需要,本人需要对大街网招聘信息进行分析,故写了个爬虫进行爬取.这里我将记录一下,本人爬取大街网的思路. 附:爬取得数据仅供自己分析所用,并未用作其它用途. 附:本篇适合有一定 爬虫基础 crawl ...
随机推荐
- [ACM] hdu 1035 Robot Motion (模拟或DFS)
Robot Motion Problem Description A robot has been programmed to follow the instructions in its path. ...
- 【cl】Red Hat Linux虚拟机安装Vmware Tools
1.选择虚拟机,选中导航栏虚拟机>VMware Tool安装 选择右键>extract to 选择/home,新建了自己的文件夹,然后点击extract 一直enter,一直到 然后reb ...
- POJ3570 Fund Management 动态规划
题目大意 Frank从个人投资者获得了c美元的资金,可用于m天的投资.Frank可以对n(n<=8)支股票进行投资.对于每一支股票:都有一个交易上限si,表示一天最多能交易的股数:还有一个上限k ...
- js获取验证码 秒表效果(原创)
<script src="http://code.jquery.com/jquery-latest.js"></script> <input type ...
- Java IO-InputStream家族 -装饰者模式
最近看到一篇文章,初步介绍java.io.InputStream,写的非常通俗易懂,在这里我完全粘贴下来. 来源于 https://mp.weixin.qq.com/s/hDJs6iG_YPww7ye ...
- JS中的数据类型及判断数据类型的方法
简单类型(基本类型): number,string,boolean,null,undefined 复杂类型(引用类型):object typeof 只能判断基本数据类型 instanceof 能够判断 ...
- 前端总结·基础篇·CSS
前端总结·基础篇·CSS 1 常用重置+重置插件(Normalize.css,IE8+) * {box-sizing:border-box;} /* IE8+ */body {margin:0;} ...
- 在Mac OSX上安装ffmpeg && ffmpeg命令行将h264封装为mp4
ffmpeg功能强大,可以通过命令行来对音视频进行处理.为了使用其功能,我在Mac上对其进行了安装. 我的Mac OS X 系统版本:OS X Yosemite, 10.10.14 关于ffmpeg在 ...
- .net中的母版页中使用FindControl的使用
前几天,遇到一个字段比较多的用户填写的页面(数据库表中就将近100个字段),怎么讲这些input的标签的值,保存数据库了?(使用的是母版页下面的aspx,不包括前段获取input的值,传给后台) 作为 ...
- css处理图片下方留白问题
引用图片的时候,图片和下方内容会有一点小空白,大概如下图紫色横条: 不是说有margin还是padding,是因为ing是行级元素,浏览器就会默认留白了,这时候处理方法很简单,给img加上样式disp ...