SQL server高级语法
1. 公共表达式CTE
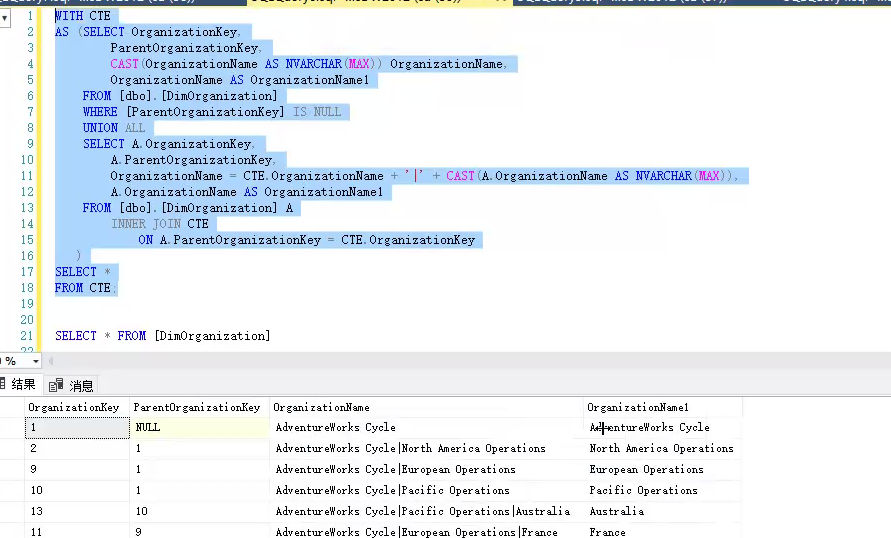
公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE。递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式。
如下面的例子,可以递归把组织名放到一起。
其实CTE的作用就相当于子查询
2.窗口函数、分区函数
窗口函数和聚集函数一样都是对定义的行集(组)进行聚集,但是不像聚集一样只返回一个值,窗口函数可以为每个组返回多个值,执行聚集的行组是窗口(因此称为‘窗口函数’)。窗口函数是在聚集函数的基础上加了一个 over(),所有的聚集函数都可以利用这种方式转换成窗口函数。窗口函数是最后才执行的,在order by 之前,where和group
by之后
Partition By分区子句:可以根据partition by子句定义行的分区或组,以完成聚集,如果使用空括号,那么整个结果集就是分区,窗口函数将对它进行聚集计算,可以把Partition By看成是移动的Group By,可以用Partition By对定义的行组计算聚集(当遇到新的组时复位),并返回每个值(每个组中的成员),而不是用一个组表示表中这个值的所有实例。

窗口函数除了用于聚集函数sum,count,avg等之外,还有row_number(计算行数),rank(排名),lead()
,lag()前移后移 在日常工作中使用也很大;
3.FOR XML Path
这个在sql server中的作用主要是把行数据转列。在mysql中有group_concat,DB2中有listagg,而sql server中没有,所以用for xml path
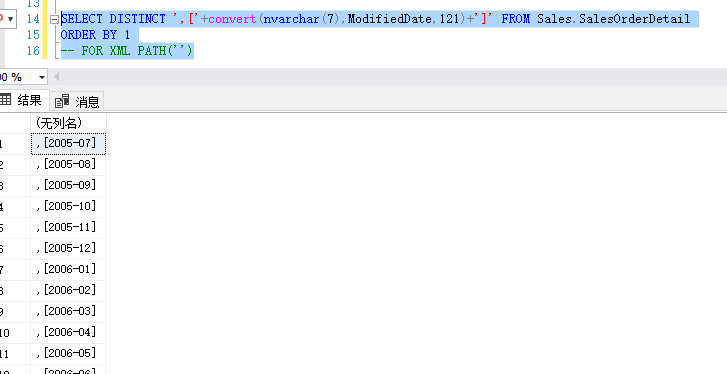
如下,我要取得年月,直接查询是这样的
当我在后面加上了for xml path 后就得到了一行的结果:
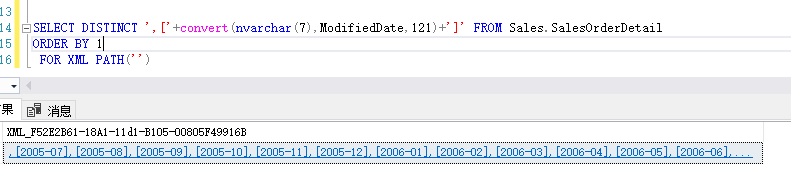
用字符串处理函数去掉前面的第一个逗号,就可以得到一个可用的字符串,用于存储过程之类的;
4.PIVOT 和UNPIVOT 行列转换函数
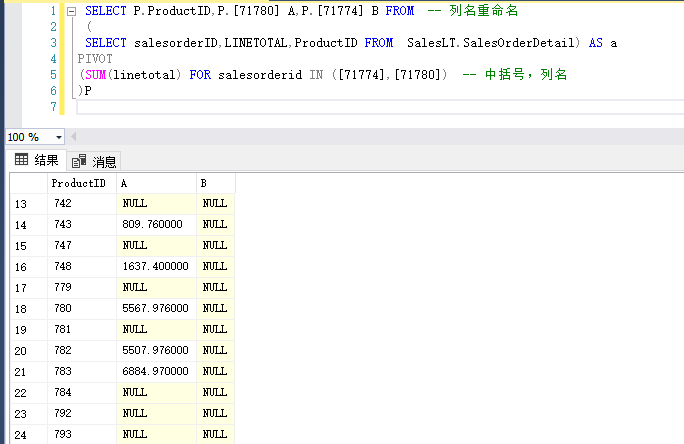
PIVOT:行转列,下面的代码实现的是,选择orderid为71774和71780的两个产品作为列名,以productID作为行,得到汇总数据
UNPIVOT 列转行
贴一个官方教程的例子:
运行结果:

5.Merge 的应用 主要用于更新数据,贴一个我写的存储
6.动态sql
文本拼接语句 缺点:1.容易被注入,被黑 最好不用
2.容易报错,如西安的拼音 xi'an
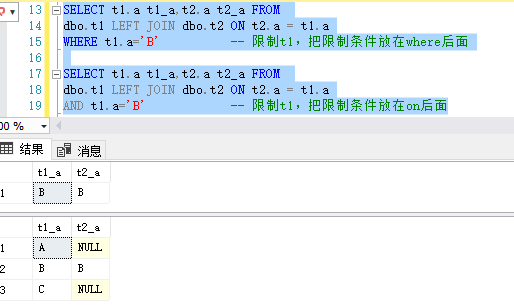
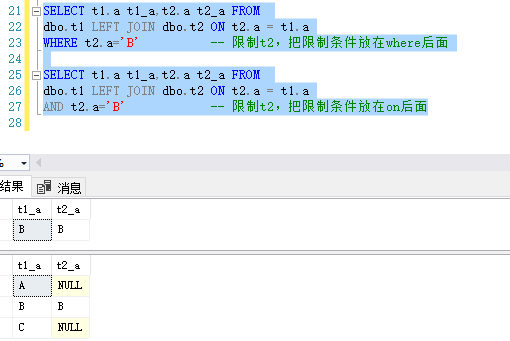
7.ON条件 在使用left jion时,on和where条件的区别如下:
on条件是在生成临时表时使用的条件,它不管on中的条件是否为真,都会返回左边表中的记录。
where条件是在临时表生成好后,再对临时表进行过滤的条件。这时已经没有left join的含义(必须返回左边表的记录)了,条件不为真的就全部过滤掉
举个例子:
先创建t1,t2两个表
以下是限制left join 左边的表的结果,可以看到上面的才是我们想要的结果
以下是限制t2的结果,可以发现把条件放在on后面才是我们想要的结果
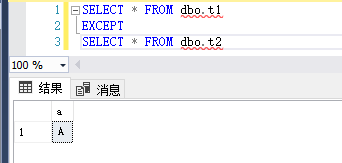
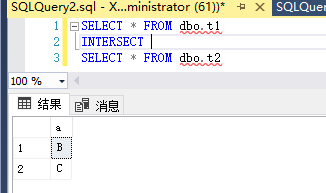
8.Except 和Intersect
比较两个查询的结果,返回非重复值。
EXCEPT 从左查询中返回右查询没有找到的所有非重复值。
INTERSECT 返回 INTERSECT 操作数左右两边的两个查询都返回的所有非重复值,即二者交集。
还是用刚刚的表,t1中是ABC,t2中是BCD
那么EXCEPT返回的是A
INTERSECT返回的是BC
SQL server高级语法的更多相关文章
- 15 个经常使用的 SQL Server 高级语法
1.case-end (详细的值) case后面有值,相当于c#中的switch case 注意:case后必须有条件,而且when后面必须是值不能为条件. -----------------case ...
- SQL server存储过程语法及实例(转)
存储过程如同一门程序设计语言,同样包含了数据类型.流程控制.输入和输出和它自己的函数库. --------------------基本语法-------------------- 一.创建存储过程cr ...
- Sql Server 基础语法
来自:http://www.cnblogs.com/AaronYang/archive/2012/04/24/2468093.html Sql Server 基础语法 -- 查看数据表 select ...
- SQL SERVER常用语法记录
用于记录SQL SERVER常用语法,以及内置函数. 以下语句包含: WITH 临时表语法 ROW_NUMBER()内置函数,我一般主要是用来分页.针对于查出来的所有数据做一个数字排序 分页的BETW ...
- SQL Server高级内容之case语法函数
1.Case函数的用法 (1)使用类似:switch-case与if-else if. (2)语法: case [字段] when 表达式 then 显示数据 when 表达式 then 显示数据 ...
- SQL SERVER常用语法汇总
阅读目录 一.SQL分类 二.基础语句 三.sql技巧 四.(MS SQL Server)SQL语句导入导出大全 回到目录 一.SQL分类 DDL—数据定义语言(CREATE,ALTER,DROP,D ...
- SQL SERVER With语法[转]
今天在论坛上看到一个举例,关于sql server 的示例.1/25/50/100美分,多少种可能拼凑成2美元. 看了其中第一条语法,放在SQL SERVER中测试,发现真的列举出所有组合成2美元的方 ...
- SQL Server 事务语法
事务全部是关于原子性的.原子性的概念是指可以把一些事情当做一个单元来看待.从数据库的角度看,它是指应全部执行或全部都不执行的一条或多条语句的最小组合. 为了理解事务的概念,需要能够定义非常明确的边界. ...
- 数往知来 SQL SERVER 基本语法<七>
sqlserver学习_01 启动数据库 开始->cmd->进入控制台 sqlcmd->-S .\sqlexpress 1> 如果出现表示数据库"sqle ...
随机推荐
- 六、Scrapy中Download Middleware的用法
本文转载自: https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/downloader-middleware.html https://doc. ...
- 10.多shard场景下relevence score可能不准确
主要知识点 多shard场景下relevence score可能不准确的原因 多shard场景下relevence score可能不准确解决方式 一.多shard场景下relevance sc ...
- Sessions共享技术设计
概述 分布式session是实现分布式部署的前提, 当前项目由于历史原因未实现分布式session, 但是由于在kubernets中部署多个pod时, 负载均衡的调用链太长, 导致会话不能保持, 所以 ...
- Problem 29
Problem 29 Consider all integer combinations of ab for 2 ≤ a ≤ 5 and 2 ≤ b ≤ 5: 仔细看看以下a与b的组合 22=4, 2 ...
- redis 和 memcached的区别
redis和memcached的区别 Redis 和 Memcache 都是基于内存的数据存储系统.Memcached是高性能分布式内存缓存服务:Redis是一个开源的key-value存储系统. ...
- Git 基础教程 之 远程推送
当你从远程仓库克隆时,实际上Git自动把本地的master分支和远程的master分支对应了起来,并且,远程仓库默认名称是origin. git remote 查看远程库信息 git remote - ...
- How to start a pdf reader from a Linux command line?
Before you do this, you should be in a GOME or KDE environment, then type the following commands to ...
- Huawei-R&S-网络工程师实验笔记20190609-VLAN划分综合(Access和Trunk端口)
>Huawei-R&S-网络工程师实验笔记20190609-VLAN划分综合(Access和Trunk端口) >>实验开始,先上拓扑图参考: >>>实验目标 ...
- 敏捷开发系列学习总结(2)——Bug修改流程
原则,力求各司其职,简单明了. 1. 测试人员提交bug ⑴ 标题: [ 模块名称 ] 问题描述 ⑵ 内容: 问题重现步骤的描述,最好贴上图片. 因为一图胜万言. ⑶ 指定责任人: 根据bug指定责任 ...
- java中Long 和long的区别
Java的数据类型分两种:1.基本类型:long,int,byte,float,double,char2. 对象类型(类): Long,Integer,Byte,Float,Double,Char,S ...