XML学习总结(1)——XML入门
一、XML语法学习
学习XML语法的目的就是编写XML
一个XML文件分为如下几部分内容:
- 文档声明
- 元素
- 属性
- 注释
- CDATA区 、特殊字符
- 处理指令(processing instruction)
1.1、xml语法——文档声明
在编写XML文档时,需要先使用文档声明,声明XML文档的类型。
最简单的声明语法: <?xml
version="1.0" ?>
例如:
1 <?xml version="1.0"?>
2 <softCompany>
3 <company>MicroSoft</company>
4 <company>google</company>
5 <company>Apple</company>
6 </softCompany>
浏览器解析结果如下:

用encoding属性说明文档的字符编码:<?xml version="1.0" encoding="GB2312" ?>
当XML文件中有中文时,必须使用encoding属性指明文档的字符编码,例如:encoding="GB2312"或者encoding="utf-8",并且在保存文件时,也要以相应的文件编码来保存,否则在使用浏览器解析XML文件时,就会出现解析错误的情况。
例如:

1 <?xml version="1.0"?>
2 <softCompany>
3 <company>MicroSoft</company>
4 <company>google</company>
5 <company>Apple</company>
6 <company>百度</company>
7 </softCompany>
这个XML文件中没有使用encoding属性来指明文档的字符编码,但文档里面有“百度”这样的中文字符,在使用IE浏览器解析该XML文件时,IE就不知道该使用什么编码去解析该文件,就无法解析了,出现的错误如下图(图-1)所示:

图-1
要想正确解析该XML文档,就可以使用encoding属性指明该文档的字符编码。
例如:
1 <?xml version="1.0" encoding="GB2312"?>
2 <softCompany>
3 <company>MicroSoft</company>
4 <company>google</company>
5 <company>Apple</company>
6 <company>百度</company>
7 </softCompany>
此时再次使用IE浏览器来解析该XML文件,就可以正常解析出里面的中文字符了,如下图(图-2)所示:

图-2
1.2、编写XML文件常遇到的一个问题
XML文件一般使用国际化通用的编码“utf-8”,所以平时看到的XML文件的头部都会有这样的代码:
1 <?xml version="1.0" encoding="utf-8"?>
如果我们使用“记事本”或者“EditPlus”等文本编辑工具编写XML文件时,例如使用“EditPlus”编写如下的XML文件:
1 <?xml version="1.0" encoding="utf-8"?>
2 <CharacterEncoding>
3 <中国>
4 <encoding>GB2312</encoding>
5 <encoding>GBK</encoding>
6 </中国>
7 <日本>
8 <encoding>JIS</encoding>
9 </日本>
10 </CharacterEncoding>
当我们在保存文件时,文件的编码默认是以“ANSI”来保存的,如下图(图-3)所示:
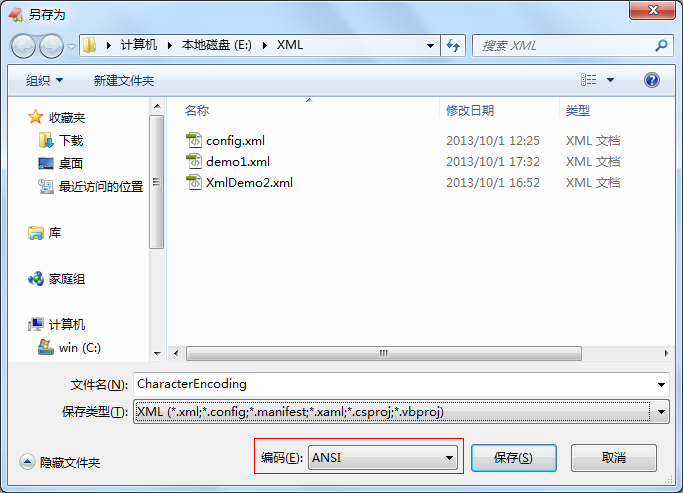
图-3
我们编写XML文件时,使用encoding="utf-8"来指明了文档的字符编码,但是在保存的时候却使用了“ANSI”编码来保存文件,由于我们在XML文件中使用encoding="utf-8"来指明了文档的字符编码,所以当浏览器解析该XML文件时,就是使用“utf-8”编码来解析,解析结果如下图(图-4)所示:

图-4
可以看到,浏览器解析失败了,这是为什么呢?我们明明指定了文档的字符编码是“UTF-8”了呀,为什么里面的中文解析不出来呢?这里不得不说说ANSI编码到底代表的是神马意思了。
不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表GB2312 编码,在日文操作系统下,ANSI 编码代表JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段ANSI 编码的文本中。
下面分析一下为什么IE浏览器X无法解析ML文件的原因:如下图(图-5)所示:
图-5
所以千万要记住,使用“记事本”或者“EditPlus”等文本编辑工具编写XML文件时一定要以XML文件的encoding属性指明的编码来保存文件,这样才能保证浏览器解析XML文件时可以正常解析。
上述的问题将CharacterEncoding.xml文件再以“UTF-8”编码保存一次就可以正常解析出CharacterEncoding.xml

图-6
浏览器的解析结果如下图(图-7)所示:

图-7
在使用一些比较智能的IDE编写XML文件时,IDE在保存XML文件时,会自动以encoding属性指明的编码来保存文件,例如在MyEclipse中编写XML文件时,就可以根据encoding属性指明的字符编码,指明为encoding="GB2312"时,保存XML文件时就自动将文件保存成GB2312编码 (如图-8),指明为encoding="UTF-8"时,就自动保存为UTF-8 (如图-9)。

图-8

图-9
用standalone属性说明文档是否独立:
1 <?xml version="1.0" encoding="GB2312" standalone="yes" ?>
1.3、xml语法——元素
XML元素指XML文件中出现的标签,一个标签分为开始标签和结束标签,一个标签有如下几种书写形式,例如:
- 包含标签体:<a>www.cnblogs.com/</a>
- 不含标签体的:<a></a>, 简写为:<a/>
一个标签中也可以嵌套若干子标签。但所有标签必须合理的嵌套,绝对不允许交叉嵌套 ,例如:
错误的写法:<a>welcome to <b>www.cnblogs.com/</a></b>
格式良好的XML文档必须有且仅有一个根标签,其它标签都是这个根标签的子孙标签。
对于XML标签中出现的所有空格和换行,XML解析程序都会当作标签内容进行处理。例如:下面两段内容的意义是不一样的。
第一段:
1 <网址>http://www.cnblogs.com/</网址>
第二段:
1 <网址>
2 http://www.cnblogs.com/
3 </网址>
由于在XML中,空格和换行都作为原始内容被处理,所以,在编写XML文件时,使用换行和缩进等方式来让原文件中的内容清晰可读的“良好”书写习惯可能要被迫改变。
一个XML元素可以包含字母、数字以及其它一些可见字符,但必须遵守下面的一些规范:
- 区分大小写,例如,<P>和<p>是两个不同的标记。
- 不能以数字或"_" (下划线)开头。
- 不能以xml(或XML、或Xml 等)开头。
- 不能包含空格。
- 名称中间不能包含冒号(:)
1.4、XML语法——属性
一个标签可以有多个属性,每个属性都有它自己的名称和取值,例如: <input name=“text”> ,属性值一定要用双引号(")或单引号(')引起来,定义属性必须遵循与标签相同的命名规范
。
多学一招:在XML技术中,标签属性所代表的信息,也可以被改成用子元素的形式来描述,例如:
1 <input>
2 <name>text</name>
3 </input>
1.5、XML语法——注释
Xml文件中的注释采用: <!--注释--> 格式。
注意:
- XML声明之前不能有注释
- 注释不能嵌套,例如:
<!--大段注释 …… <!--局部注释--> …… -->
1.6、XML语法——CDATA区
在编写XML文件时,有些内容可能不想让解析引擎解析执行,而是当作原始内容处理,遇到此种情况,可以把这些内容放在CDATA区里,对于CDATA区域内的内容,XML解析程序不会处理,而是直接原封不动的输出。
语法:<![CDATA[ 内容 ]]>
例如:
1 <?xml version="1.0" encoding="utf-8"?>
2 <soft>
3 <![CDATA[
4 <a className="gacl.xdp">
5 <a1>gacl</a1>
6 <a2>xdp</a2>
7 </a>
8 ]]>
9 <b>
10 <b1>孤傲苍狼</b1>
11 <b2>徐达沛</b2>
12 </b>
13 </soft>
该XML文件使用IE浏览器解析引擎解析执行后,结果如下图(图-10)所示:
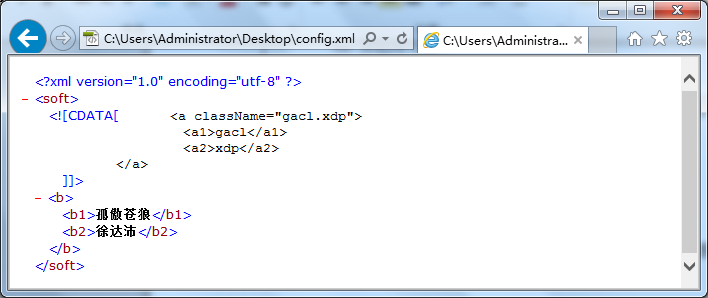
图-10
对于一些单个字符,若想显示其原始样式,也可以使用转义的形式予以处理。

转义字符表
例如:
1 <?xml version="1.0" encoding="utf-8"?>
2 <soft>
3 <b>
4 <b1>孤傲苍狼</b1>
5 <b2>徐达沛</b2>
6 </b>
7 </soft>
解析器解析的结果如下图(图-11)所示:

图-11
1.7、XML语法-处理指令
处理指令,简称PI (processing instruction)。处理指令用来指挥解析引擎如何解析XML文档内容。例如,在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用css文件显示xml文档内容,标签名为中文时,css不起作用。
<?xml-stylesheet type="text/css" href="css文件名.css"?>
例如:
1 <?xml version="1.0" encoding="utf-8"?>
2 <!--在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,应用country.css文件显示xml文档内容-->
3 <?xml-stylesheet type="text/css" href="country.css"?>
4 <Country>
5 <c1>中国</c1>
6 <c2>美国</c2>
7 <c3>日本</c3>
8 <c4>韩国</c4>
9 </Country>
Country.css样式文件代码如下:
1 c1{
2 font-size:200px;
3 color:red;
4 }
5 c2{
6 font-size:150px;
7 color:green;
8 }
9 c3{
10 font-size:100px;
11 color:#ccc;
12 }
13 c4{
14 font-size:130px;
15 color:blue;
16 }
在浏览器中解析该XML文件的结果如下图(图-12)所示:

图-12
处理指令必须以"<?"作为开头,以"?>"作为结尾,XML声明语句(<?xml version="1.0" encoding="utf-8"?>)就是最常见的一种处理指令。
到此,关于XML语法方面的讲解就全部讲完了。
XML学习总结(1)——XML入门的更多相关文章
- XML学习总结(二)——XML入门
XML学习总结(二)——XML入门 一.XML语法学习 学习XML语法的目的就是编写XML 一个XML文件分为如下几部分内容: 文档声明 元素 属性 注释 CDATA区 .特殊字符 处理指令(proc ...
- XML学习笔记(1)--XML概述
XML基本概念 XML—extensible Markup Language(可扩展标记语言) XML最基本的三个概念 1)XML语言---描述事物本身(可扩展) 2)XSL语言---展现事物表现形式 ...
- C#操作XML学习之创建XML文件的同时新建根节点和子节点(多级子节点)
最近工作中遇到一个问题,要求创建一个XML文件,在创建的时候要初始化该XML文档,同时该文档打开后是XML形式,但是后缀名不是.在网上找了好些资料没找到,只能自己试着弄了一下,没想到成功了,把它记下来 ...
- XML学习总结(一)——XML介绍
一.XML概念 Extensible Markup Language,翻译过来为可扩展标记语言.Xml技术是w3c组织发布的,目前推荐遵循的是W3C组织于2000发布的XML1.0规范. 二.学习XM ...
- XML学习笔记之XML的简介
最近,自学了一段时间xml,希望通过学习笔记的整理能够巩固一下知识点,也希望把知识分享给你们(描红字段为重点): XML(extensible Markup language):可扩展的标记语言,解决 ...
- XML学习——java解析xml文件
递归获取每个标签 package test; import java.io.File; import java.util.List; import org.dom4j.Document; import ...
- XML学习笔记——关于XML解析器
本篇文章基于W3C而写 在Firefox及其他浏览器中的XML解析器(除IE) var xmlDoc=document.implementation.createDocument("&quo ...
- XML 学习介绍 收藏
XML学习总结(一)——XML介绍 一.XML概念 Extensible Markup Language,翻译过来为可扩展标记语言.Xml技术是w3c组织发布的,目前推荐遵循的是W3C组织于2000发 ...
- delphi操作xml学习笔记 之一 入门必读
Delphi 对XML的支持---TXMLDocument类 Delphi7 支持对XML文档的操作,可以通过TXMLDocument类来实现对XML文档的读写.可以利用TXMLDocum ...
随机推荐
- Java Web Application——servlet
概述 是一个部署于web服务器中的实现了servlet接口的Java类,用于响应web请求 Web容器(也称为servlet容器)本质上是与servlet交互的Web服务器的组件.Web容器负责管理s ...
- Git学习笔记 1,GitHub常用命令1
廖雪峰Git教程 莫烦Git教程 莫烦Git视频教程 --------------- init > apt-get install git # 安装 > mkdir /home/yzn_g ...
- HDU 4889 Scary Path Finding Algorithm
其实这个题是抄的题解啦…… 题解给了一个图,按照那个图模拟一遍大概就能理解了. 题意: 有一段程序,给你一个C值(程序中某常量),让你构造一组数据,使程序输出"doge" 那段代码 ...
- shiro整合thymeleaf
1.引入依赖 <!--thymeleaf中使用shiro--> <dependency> <groupId>com.github.theborakompanioni ...
- ECNUOJ 2616 游黄山
游黄山 Time Limit:1000MS Memory Limit:65536KB Total Submit:165 Accepted:52 Special Judge Description Po ...
- Spring Cloud学习笔记【十】配置中心(消息驱动刷新配置)
上一篇中讲到,如果需要客户端获取到最新的配置信息需要执行refresh,我们可以利用 Webhook 的机制每次提交代码发送请求来刷新客户端,当客户端越来越多的时候,需要每个客户端都执行一遍,这种方案 ...
- ADL & 实参相依的查找 & 成员与非成员的查找
也就是会根据实参,所处在的名字空间,来查找对应名字空间里面的函数. 对于<<也是常见的场景,会根据实际要打印出来的下一个操作数,来决定调用哪个命名空间里面的函数. 注意,不同命名空间里面的 ...
- VS中,打开文件时自动定位到目录树中
工具--选项--项目和解决方案--常规--在解决方案资源管理器中跟踪活动项 这样就能快速跟踪了.
- Java中二进制字节与十六进制互转
在Java中字节与十六进制的相互转换主要思想有两点: 1.二进制字节转十六进制时,将字节高位与0xF0做"&"操作,然后再左移4位,得到字节高位的十六进制A;将字节低位与0 ...
- Android View体系(十)自定义组合控件
相关文章 Android View体系(一)视图坐标系 Android View体系(二)实现View滑动的六种方法 Android View体系(三)属性动画 Android View体系(四)从源 ...