spark-2.2.0安装和部署——Spark集群学习日记
前言
在安装后hadoop之后,接下来需要安装的就是Spark。
scala-2.11.7下载与安装
具体步骤参见上一篇博文
Spark下载
为了方便,我直接是进入到了/usr/local文件夹下面进行下载spark-2.2.0
wget https://d3kbcqa49mib13.cloudfront.net/spark-2.2.0-bin-hadoop2.7.tgz
Spark安装之前的准备
文件的解压与改名
tar -zxvf spark-2.2.0-bin-hadoop2.7.tgz
rm -rf spark-2.2.0-bin-hadoop2.7.tgz
为了我后面方便配置spark,在这里我把文件夹的名字给改了
mv spark-2.2.0-bin-hadoop2.7 spark-2.2.0
配置环境变量
vi /etc/profile
在最尾巴加入
export SPARK_HOME=/usr/local/spark-2.2.0
export PATH=$PATH:$SPARK_HOME/bin

配置Spark环境
打开spark-2.2.0文件夹
cd spark-2.2.0
此处需要配置的文件为两个
spark-env.sh和slaves
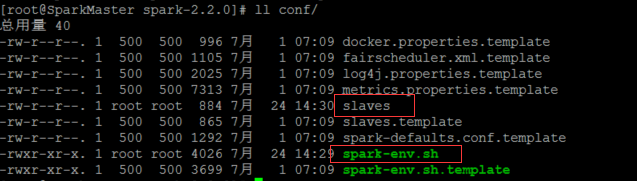
首先我们把缓存的文件spark-env.sh.template改为spark识别的文件spark-env.sh
cp conf/spark-env.sh.template conf /spark-env.sh
修改spark-env.sh文件
vi conf/spark-env.sh
在最尾巴加入
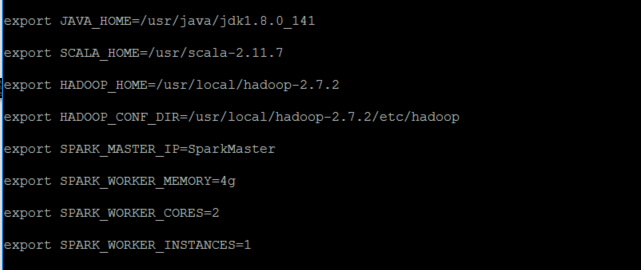
export JAVA_HOME=/usr/java/jdk1.8.0_141
export SCALA_HOME=/usr/scala-2.11.7
export HADOOP_HOME=/usr/local/hadoop-2.7.2
export HADOOP_CONF_DIR=/usr/local/hadoop-2.7.2/etc/hadoop
export SPARK_MASTER_IP=SparkMaster
export SPARK_WORKER_MEMORY=4g
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
变量说明
- JAVA_HOME:Java安装目录
- SCALA_HOME:Scala安装目录
- HADOOP_HOME:hadoop安装目录
- HADOOP_CONF_DIR:hadoop集群的配置文件的目录
- SPARK_MASTER_IP:spark集群的Master节点的ip地址
- SPARK_WORKER_MEMORY:每个worker节点能够最大分配给exectors的内存大小
- SPARK_WORKER_CORES:每个worker节点所占有的CPU核数目
- SPARK_WORKER_INSTANCES:每台机器上开启的worker节点的数目
修改slaves文件
vi conf/slaves
在最后面修成为
SparkWorker1
SparkWorker2

同步SparkWorker1和SparkWorker2的配置
在此我们使用rsync命令
rsync -av /usr/local/spark-2.2.0/ SparkWorker1:/usr/local/spark-2.2.0/
rsync -av /usr/local/spark-2.2.0/ SparkWorker2:/usr/local/spark-2.2.0/
启动Spark集群
因为我们只需要使用
hadoop的HDFS文件系统,所以我们并不用把hadoop全部功能都启动。
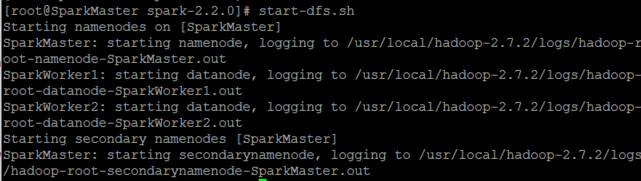
启动hadoop的HDFS文件系统
start-dfs.sh
但是在此会遇到一个情况,就是使用
start-dfs.sh,启动之后,在SparkMaster已经启动了namenode,但在SparkWorker1和SparkWorker2都没有启动了datanode,这里的原因是:datanode的clusterID和namenode的clusterID不匹配。是因为SparkMaster多次使用了hadoop namenode -format格式化了。
解决的办法:
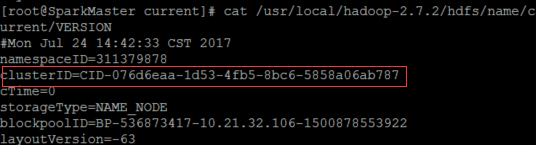
在SparkMaster使用
cat /usr/local/hadoop-2.7.2/hdfs/name/current/VERSION
查看clusterID,并将其复制。
在SparkWorker1和SparkWorker2上使用
vi /usr/local/hadoop-2.7.2/hdfs/name/current/VERSION
将里面的clusterID,更改成为SparkMasterVERSION里面的clusterID

做了以上两步之后,便可重新使用start-dfs.sh开启HDFS文件系统。
启动之后使用jps命令可以查看到SparkMaster已经启动了namenode,SparkWorker1和SparkWorker2都启动了datanode,说明hadoop的HDFS文件系统已经启动了。



启动Spark
因为
hadoop/sbin以及spark/sbin均配置到了系统的环境中,它们同一个文件夹下存在同样的start-all.sh文件。最好是打开spark-2.2.0,在文件夹下面打开该文件。
./sbin/start-all.sh
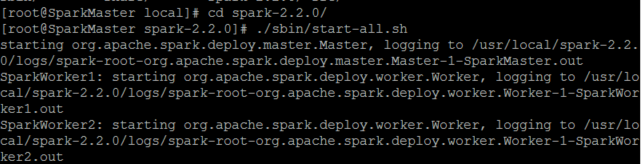
成功打开之后使用jps在SparkMaster、parkWorker1和SparkWorker2节点上分别可以看到新开启的Master和Worker进程。



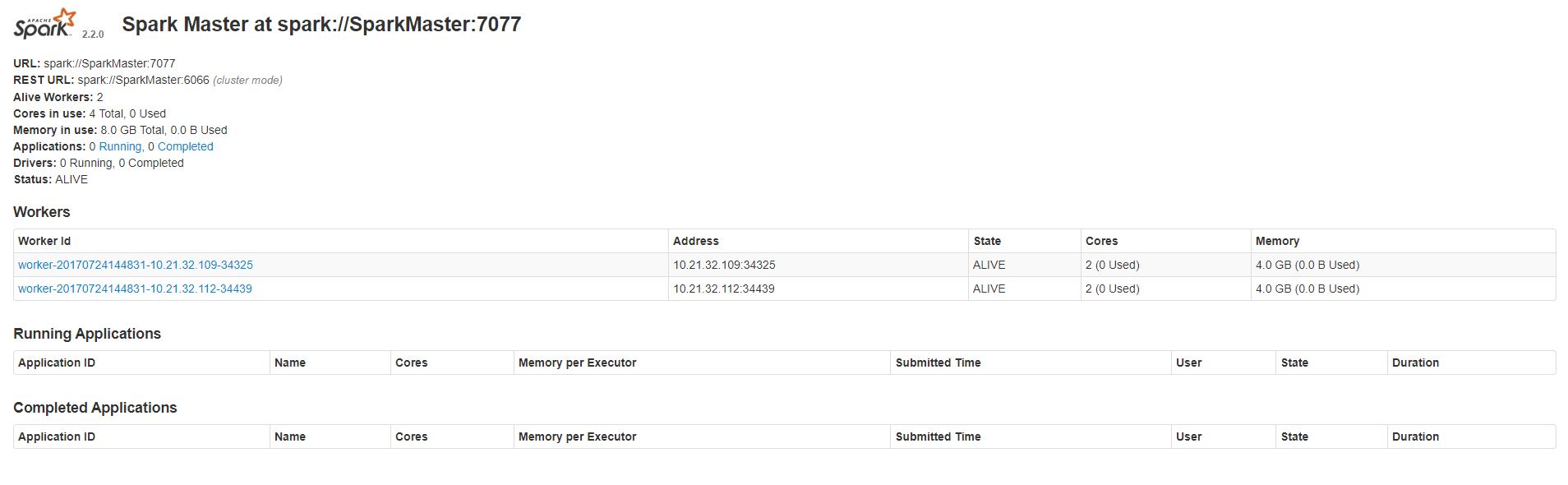
成功打开Spark集群之后可以进入Spark的WebUI界面,可以通过
SparkMaster_IP:8080
访问,可见有两个正在运行的Worker节点。
打开Spark-shell
使用
spark-shell
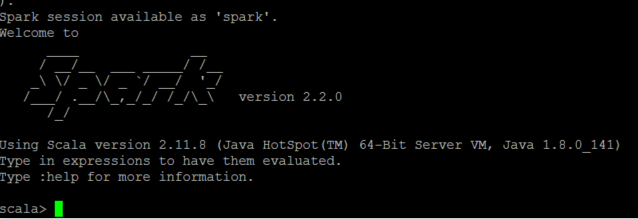
便可打开Spark的shell
同时,因为shell在运行,我们也可以通过
SparkMaster_IP:4040
访问WebUI查看当前执行的任务。
结言
到此我们的Spark集群就搭建完毕了。搭建spark集群原来知识网络是挺庞大的,涉及到Linux基本操作,设计到ssh,设计到hadoop、Scala以及真正的Spark。在此也遇到不少问题,通过翻阅书籍以及查看别人的blog得到了解决。在此感谢分享知识的人。
参见 王家林/王雁军/王家虎的《Spark 核心源码分析与开发实战》
文章出自kwongtai'blog,转载请标明出处!
spark-2.2.0安装和部署——Spark集群学习日记的更多相关文章
- 安装Scala-2.11.7——集群学习日记
前言 在安装Spark之前,我们需要安装Scala语言的支持.在此我选择的是scala-2.11.7版本. scala-2.11.7下载 为了方便,我现在我的SparkMaster主机上先安装,把目录 ...
- 在Docker中安装和部署MongoDB集群
此文已由作者袁欢授权网易云社区发布. 欢迎访问网易云社区,了解更多网易技术产品运营经验. 在Docker中安装mongodb 采用的mongodb镜像:https://registry.hub.doc ...
- websphere8 从安装到部署 测试集群应用程序 安装j2ee程序(非常详细)
目录1. 准备安装文件2. 安装Installation Manager3. 为Installation Manager指定安装资源库4. 创建部署管理器概要文件5. 创建定制概要文件并联合到部署管理 ...
- zookeeper的安装与部署-伪集群
1.Zookeeper的下载与解压 通过后面的链接下载Zookeeper: Zookeeper下载在此我们下载zookeeper-3.4.5下载后解压至安装目录下,本文我们解压到目录:/ ...
- kafka系列一、kafka安装及部署、集群搭建
一.环境准备 操作系统:Cent OS 7 Kafka版本:kafka_2.10 Kafka官网下载:请点击 JDK版本:1.8.0_171 zookeeper-3.4.10 二.kafka安装配置 ...
- Hbase的安装与部署(集群版)
HBase 部署与使用 部署 Zookeeper 正常部署 $ ~/modules/zookeeper-3.4.5/bin/zkServer.sh start 首先保证 Zookeeper 集群的正常 ...
- 二十八. Ceph概述 部署Ceph集群 Ceph块存储
client :192.168.4.10 node1 :192.168.4.11 ndoe2 :192.168.4.12 node3 :192.168.4.13 1.实验环境 准备四台KVM虚 ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
随机推荐
- python之matplotlib绘图基础
Python之matplotlib基础 matplotlib是Python优秀的数据可视化第三方库 matplotlib库的效果可参考 http://matplotlib.org/gallery.ht ...
- Java代码编写规范(不是标准规范,自行整理,无须纠结)
最近回过头来给以前的项目增加功能,发现之前写的注释非常不全,代码也非常的不整洁,有些地方写的''窝七八烂的,看着很不舒服:又恰好经理最近也经常跟我提起代码规范,我们就讨论了一下代码规范的重要性和必要性 ...
- [翻译]怎么写一个React组件库(二)
本文同步发布于知乎专栏 https://zhuanlan.zhihu.com/p/27434018,喜欢本文的就去知乎点个赞支持下吧- 引言 该系列文章将通过创建一个组件库来引导你学习如何构建自己的组 ...
- 关于并发,关于IIS你真的了解吗?(一)
本文仅代表带个人观点及理解,本人只是一个编程小菜鸟,如果有不对的地方.请大佬轻喷! 前言:对于很多工作时间短或者编程经验不足的程序员来说,大多数会觉得并发这个词离自己太遥远,之所以知道并发也不过是因为 ...
- python cookbook第三版学习笔记 一
数据结构 假设有M个元素的列表,需要从中分解出N个对象,N<M,这会导致分解的值过多的异常.如下: record=['zhf','zhf@163.com','775-555-1212','847 ...
- java中的vo、dto 、dao
VO是跟数据库里表的映射,一个表对应一个VO DAO是用VO来访问真实的表,对数据库的操作都在DAO中完成 BO是业务层,做逻辑处理的 VO , PO , BO , QO, DAO ,POJO ...
- Phpcms V9缩略图裁剪存在黑边的解决方法
最近用Phpcms v9又碰到一个老问题:在内容页缩略图裁剪的时候出现黑边,这种情况很久没碰到,估计是长宽不同或者会在首页.列表页.内容页不同地方偶然出现的情况,在这里分享下Phpcms V9缩略图裁 ...
- Java学习笔记--异常描述
异常描述 1.简介 为了全面了解"异常"的概念,先来分析一个实例.假定要编写一个Java程序,该程序读取用户输入的一行文本,并在终端显示该文本.这里是一个演示Java语言I/O功能 ...
- hibernate sql查询转换成VO返回list
hibernate sql查询转换成VO @Override public List<FenxiVo> getTuanDuiFenxiList(FenxiVo FenxiVo,Intege ...
- mysql 转义字符
在用户提交表单的时候,有的用户会提交一些特殊字符,比如单引号双引号,此时,如果直接按正常字符串插入数据库的话,可能会出现无法正确插入数据库 PDO::quote 转义mysql语句中的单引号和双引号 ...