第一个python爬虫程序
1.安装Python环境
官网https://www.python.org/下载与操作系统匹配的安装程序,安装并配置环境变量
2.IntelliJ Idea安装Python插件
我用的idea,在工具中直接搜索插件并安装(百度)
3.安装beautifulSoup插件
https://www.crummy.com/software/BeautifulSoup/bs4/doc.zh/#attributes
4.爬虫程序:爬博客园的闪存内容
#!/usr/bin/python
# -*- coding: UTF-8 -*-
import urllib2
import time
import bs4 '''ing.cnblogs.com爬虫类'''
class CnBlogsSpider: url = "https://ing.cnblogs.com/ajax/ing/GetIngList?IngListType=All&PageIndex=${pageNo}&PageSize=30&Tag=&_=" #获取html
def getHtml(self):
request = urllib2.Request(self.pageUrl)
response = urllib2.urlopen(request)
self.html = response.read() #解析html
def analyze(self):
self.getHtml()
bSoup = bs4.BeautifulSoup(self.html)
divs = bSoup.find_all("div",class_='ing-item')
for div in divs:
img = div.find("img")['src']
item = div.find("div",class_='feed_body')
userName = item.find("a",class_='ing-author').text
text = item.find("span",class_='ing_body').text
pubtime = item.find("a",class_='ing_time').text
star = item.find("img",class_='ing-icon') and True or False
print '( 头像: ',img,'昵称: ',userName,',闪存: ',text,',时间: ',pubtime,',星星: ',star,')' def run(self,page):
pageNo = 1
while (pageNo <= page):
self.pageUrl = self.url.replace('${pageNo}', str(pageNo))+str(int(time.time()))
print '-------------\r\n第 ',pageNo,' 页的数据如下:',self.pageUrl
self.analyze()
pageNo = pageNo + 1 CnBlogsSpider().run(3)
5.执行结果
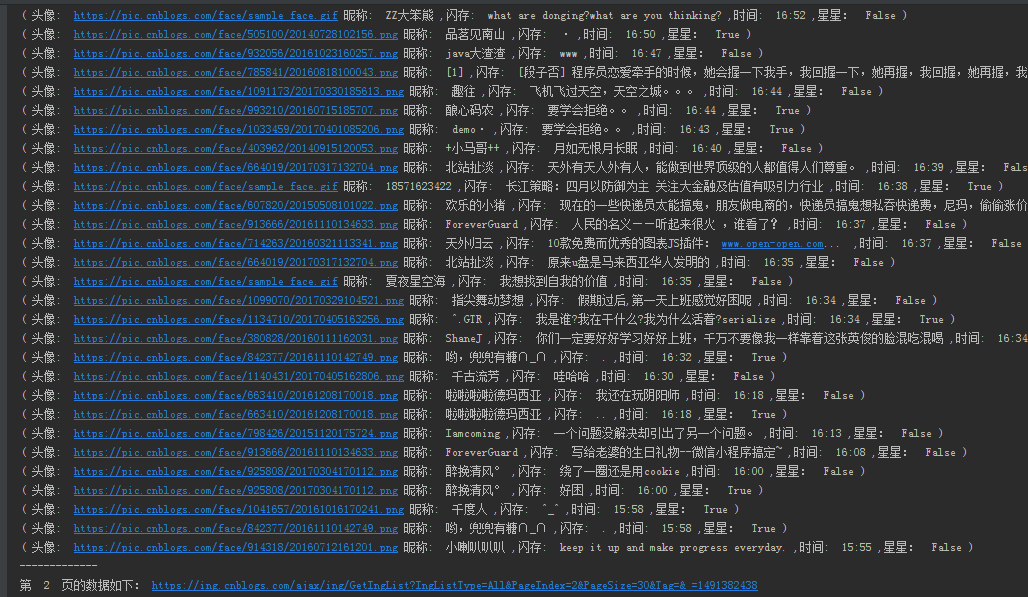
第一个python爬虫程序的更多相关文章
- 我的第一个python爬虫程序
程序用来爬取糗事百科上的图片的,程序设有超时功能,具有异常处理能力 下面直接上源码: #-*-coding:utf-8-*- ''' Created on 2016年10月20日 @author: a ...
- 一个python爬虫小程序
起因 深夜忽然想下载一点电子书来扩充一下kindle,就想起来python学得太浅,什么“装饰器”啊.“多线程”啊都没有学到. 想到廖雪峰大神的python教程很经典.很著名.就想找找有木有pdf版的 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- python爬虫程序
http://blog.csdn.net/pleasecallmewhy/article/details/8922826 此人的博客关于python爬虫程序分析得很好!
- 使用PyQt来编写第一个Python GUI程序
原文:使用PyQt来编写第一个Python GUI程序 本文由 伯乐在线 - Lane 翻译,Daetalus 校稿.未经许可,禁止转载!英文出处:pythonforengineers.com.欢迎加 ...
- Day1:第一个python小程序
Day1:第一个python小程序与开发工具Pycharm 一.Hello World C:\Users\wenxh>python Python 3.6.2 (v3.6.2:5fd33b5, J ...
- 记我的第一个python爬虫
捣鼓了两天,终于完成了一个小小的爬虫代码.现在才发现,曾经以为那么厉害的爬虫,在自己手里实现的时候,也不过如此.但是心里还是很高兴的. 其实一开始我是看的慕课上面的爬虫教学视屏,对着视屏的代码一行行的 ...
- 我的第一个Python爬虫——谈心得
2019年3月27日,继开学到现在以来,开了软件工程和信息系统设计,想来想去也没什么好的题目,干脆就想弄一个实用点的,于是产生了做“学生服务系统”想法.相信各大高校应该都有本校APP或超级课程表之类的 ...
- 一个Python爬虫工程师学习养成记
大数据的时代,网络爬虫已经成为了获取数据的一个重要手段. 但要学习好爬虫并没有那么简单.首先知识点和方向实在是太多了,它关系到了计算机网络.编程基础.前端开发.后端开发.App 开发与逆向.网络安全. ...
随机推荐
- devexpress表格gridcontrol实现列统计,总计,平均,求和等。
1.在许多项目中,经常要实现对某些列的统计.devexpress控件gridcontrol实现这些功能只需要设置某些属性,就可以达到要求了.以下例举了一个统计班级总数,人数总计,分数总计的案例.效果图 ...
- tornado学习 - TCPClient 实现聊天功能
之前完成了一个简单的聊天服务器,连接服务器使用的是系统自带nc命令,接下来就是通过自己实现TCPClient. 客户端与服务器功能大致相仿,相对与服务器只是少了转发消息环节. 首先,定义TCPClie ...
- MySQL备份说明
第一次发布博客,发现目录居然不会生成,后续慢慢熟悉博客园的设置.回正文--- 1 使用规范 1.1 实例级备份恢复 使用innobackupex,在业务空闲期执行,考虑到IO影响及 FLUSH TAB ...
- 0CSS样式表与HTML结合的方法
从此王子和公主幸福的生活在了一起:) 层叠样式表(英文全称:Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文 ...
- BASH SHELL not a valid identifier
解决BASH SHELL脚本报错 ‘: not a valid identifier当在shell编辑脚本时,运行时出现了" ‘: not a valid identifier " ...
- 《你不知道的JavaScript》整理(五)——值与原生函数
一.值 1)数字 JavaScript只有一种数值类型:number(数字),包括"整数"和带小数的十进制数. //数字的语法 a.toExponential(); // &quo ...
- 提交Sublime Text 插件到Package Control
最近写了一个lua智能提示的插件LuaSmartTips.这个插件一直都是自己一个人在用,昨天突然想把插件提交到Package Control,如果其他的人有这样的需求就可以直接安装. Package ...
- ThinkPhp框架的数据库操作(查询)
TP框架有一套自己的数据库操作的代码,包括数据库的增.删.改.查.本文主要讲解TP框架的数据库查询操作. 找到入口文件的控制器: 我这里的入口文件是Show文件夹下的控制器. 打开Login控制器. ...
- 算法模板——AC自动机
实现功能——输入N,M,提供一个共计N个单词的词典,然后在最后输入的M个字符串中进行多串匹配(关于AC自动机算法,此处不再赘述,详见:Aho-Corasick 多模式匹配算法.AC自动机详解.考虑到有 ...
- spring循环依赖问题分析
新搞了一个单点登录的项目,用的cas,要把源码的cas-webapp改造成适合我们业务场景的项目,于是新加了一些spring的配置文件. 但是在项目启动时报错了,错误日志如下: 一月 , :: 下午 ...