[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<2>
前言:上篇[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>中介绍了ES ,Kibana的单机到分布式的安装,这里主要是介绍Elasticsearch5.3.1的一些概念。官方示例的基本数据导入,数据查询以及ES,kibana的功能组件的认识和熟悉。
一、Elasticsearch中的基本概念:
Elasticsearch所涉及到的每一项技术都不是创新或者革命性的,全文检索,分析系统以及分布式数据库这些早就已经存在了。它的革命性在于将这些独立且有用的技术整合成一个一体化的、实时的应用。它对新用户的门槛很低,当然它也会跟上你技能和需求增长的步伐。-《Elasticsearch权威指南》
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档 (document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在 Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之 一。 -《Elasticsearch权威指南》
在数据库的学习中我们就知道了索引这个概念,索引是为提高查询效率而诞生的。索引让我们更快的定位需要查询的关键字。以Mysql来说:[从索引的数据结构划分]Mysql数据库中包含FULLTEXT,HASH,BTREE,RTREE这几种索引,分别是全文索引(全文索引是MyISAM的一个特殊索引类型,主要用于全文检索),hash索引(只有Memory存储引擎显示支持hash索引),B-tree B树索引(目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构),R-tree 空间索引(MyISAM支持空间索引,主要用于地理空间数据类型)。
全文索引(FULL-TEXT):用于全文检索(在一个文件中搜索匹配的词),又被称为倒排文档索引,是现代搜索引擎的关键技术。这也是ES的核心侧重点,致力于用户以前所未有的速度检索和分析大数据。
1、Mapping:相当于数据库表的schema,即定义这张表的字段和类型
2、Index:索引相当于数据库
3、Type:相当于数据库的表
4、Document:行数据
5、Fileds:字段
6、Id:相当于记录的编号
7、shared:分片,这是ES提供分布式搜索的基础,其含义为将一个完整的index分成若干部分存储在相同或不同的节点上,这些组成index的部分就叫做shard
二、Elasticsearch官方示例数据的导入:[localhost换成本机IP即可]
1、获取示例数据:
wget https://download.elastic.co/demos/kibana/gettingstarted/shakespeare.json
wget https://download.elastic.co/demos/kibana/gettingstarted/accounts.zip
wget https://download.elastic.co/demos/kibana/gettingstarted/logs.jsonl.gz解压缩:
unzip accounts.zip
gunzip logs.jsonl.gz
2、导入示例数据:随便选取一个节点导入,这里为分布式环境,单机版同理。
- 创建mapping: 以下下指令可以直接在终端运行,也可以在Kibana的控制台运行。
curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/shakespeare -d '
{"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}';curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.18 -d '
{"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}';curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.19 -d '
{"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}';curl -H 'Content-Type: application/json' -XPUT http://localhost:9200/logstash-2015.05.20 -d '
{"mappings": {
"log": {
"properties": {
"geo": {
"properties": {
"coordinates": {
"type": "geo_point"
}
}
}
}
}
}
}';- 导入数据:
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/bank/account/_bulk?pretty' --data-binary @accounts.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/shakespeare/_bulk?pretty' --data-binary @shakespeare.json
curl -H 'Content-Type: application/x-ndjson' -XPOST 'localhost:9200/_bulk?pretty' --data-binary @logs.jsonl
3、查看是否导入成功:
curl 'localhost:9200/_cat/indices?v'

三、ES-head集群管理:
1、分布式环境中只需选取一个节点启动ES-head,无论是不是Master节点,都能连接到整个集群,这里选取node-1(192.168.230.150)导入。导入之后重新访问192.168.230.150:9100查看head界面可得到如下:
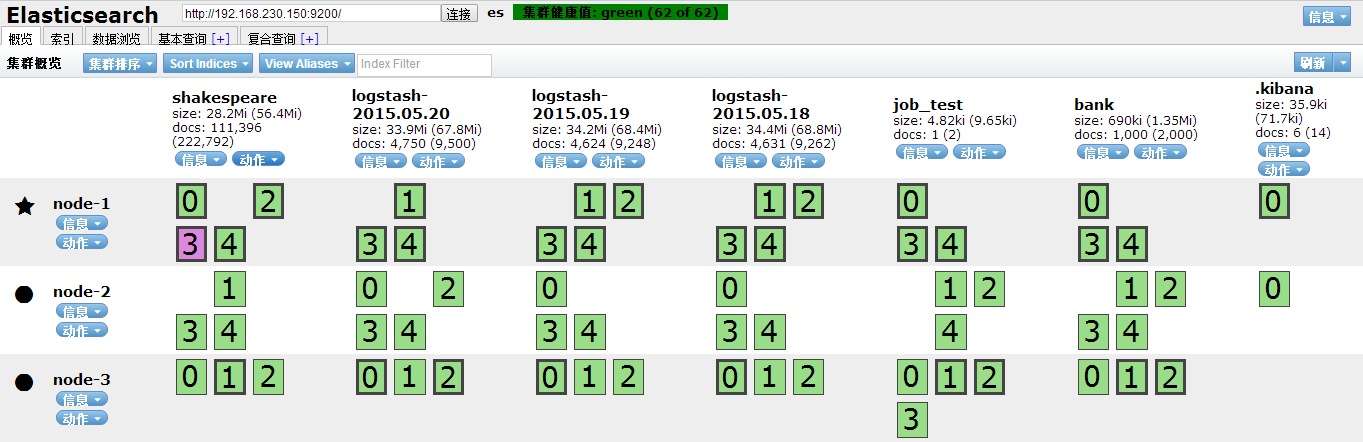
2、所有数据导入后会分片存储在不同的节点上,默认是5个分片,一个副本。每一个分片的副本都不会和本体存在一个节点上从而保证一个节点数据丢失可已得到恢复。我们可以修改连接的节点:结果同上,说明无论连接哪个节点都能获取集群的信息。


3、关闭其中一个节点(这里关闭node-1,master节点看看会出现什么结果)

我们发现集群健康值由green变为了yellow,重新选举了node-3为主节点Master。我们重新启动node-1查看:
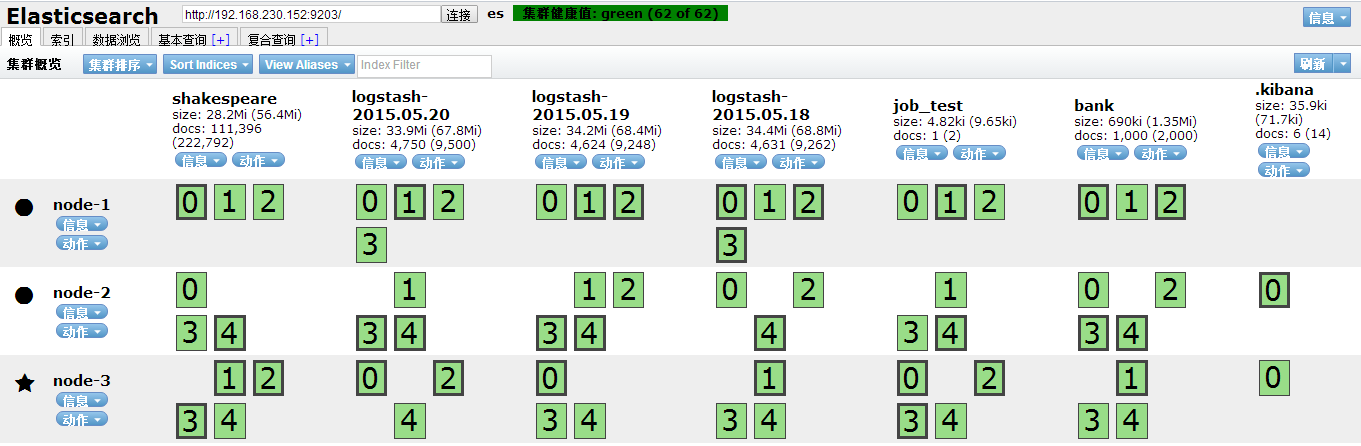
node-1节点恢复了,所存储的数据分片也恢复了,node-3仍是Master。
4、ES-head做一个简单的查询示例:
ES-head可以清楚的查看集群的各种信息,节点,索引,数据。这里简单示例一个查询,具体功能后面在探索。查询type为account的数据条件是年龄范围在10-50之间。
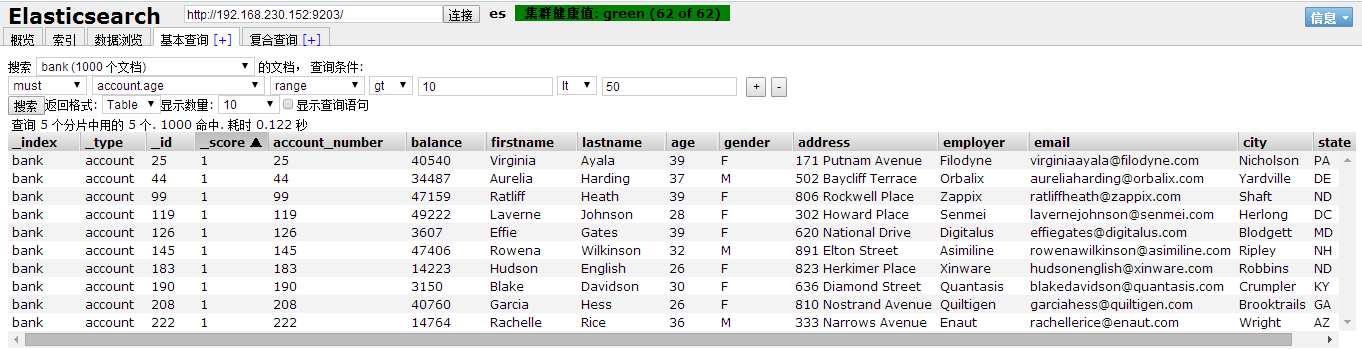
四、Kibana功能组件:
1、开启Kibana,访问5601端口:http://ip:5601 创建Index pattern :ba*,log*,sh*(Management->Index Patterns->add New->取消所有选项->Create)

2、Discover数据查询展示:根据条件过滤选择要展示的字段右侧点击add,点开数据详情可以选择table和json两种格式展示。

3、Visualize可视化:多种可选择图形可视化。
- 可选图形有:饼状图,折线图,条形图,坐标图。。。等。

- 下面根据示例创建一个饼状图:(Visualizer->Create a Visualizer->pie chart->From a New Search, Select Index选择ba*)得到下图:
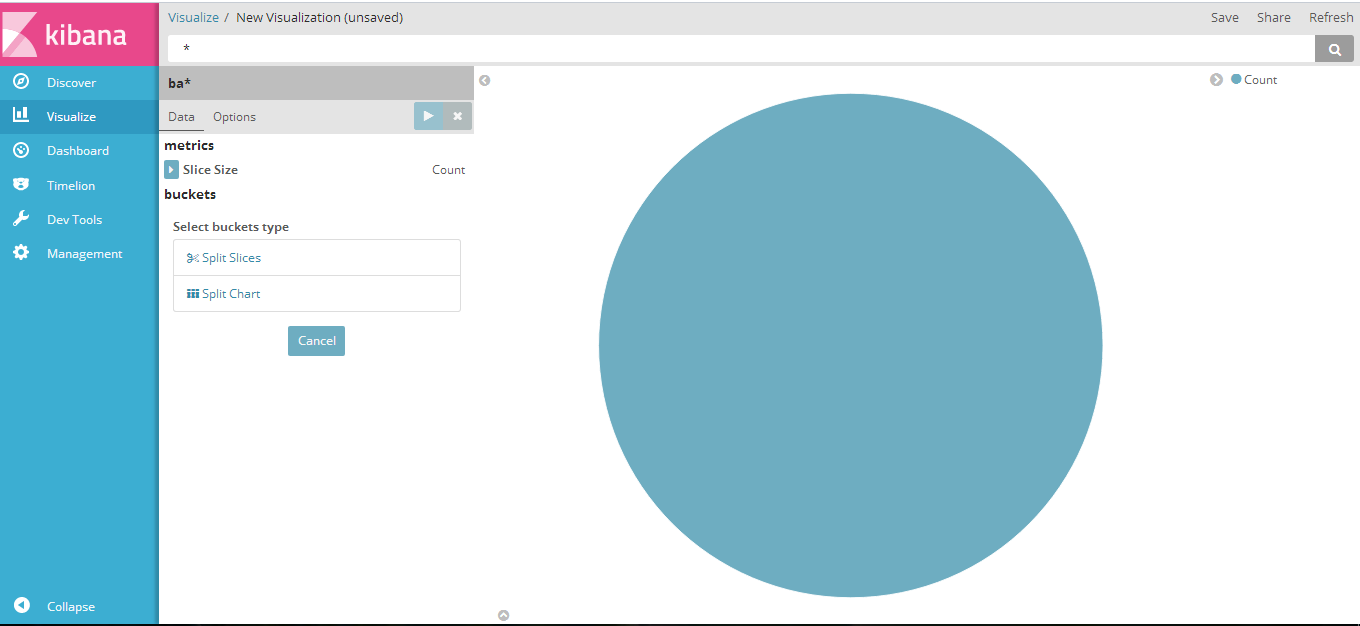
选择过滤条件和聚合函数:(buckets:Split Slices->Aggregation->Range->Field->balance-add Range选择数据的范围 )
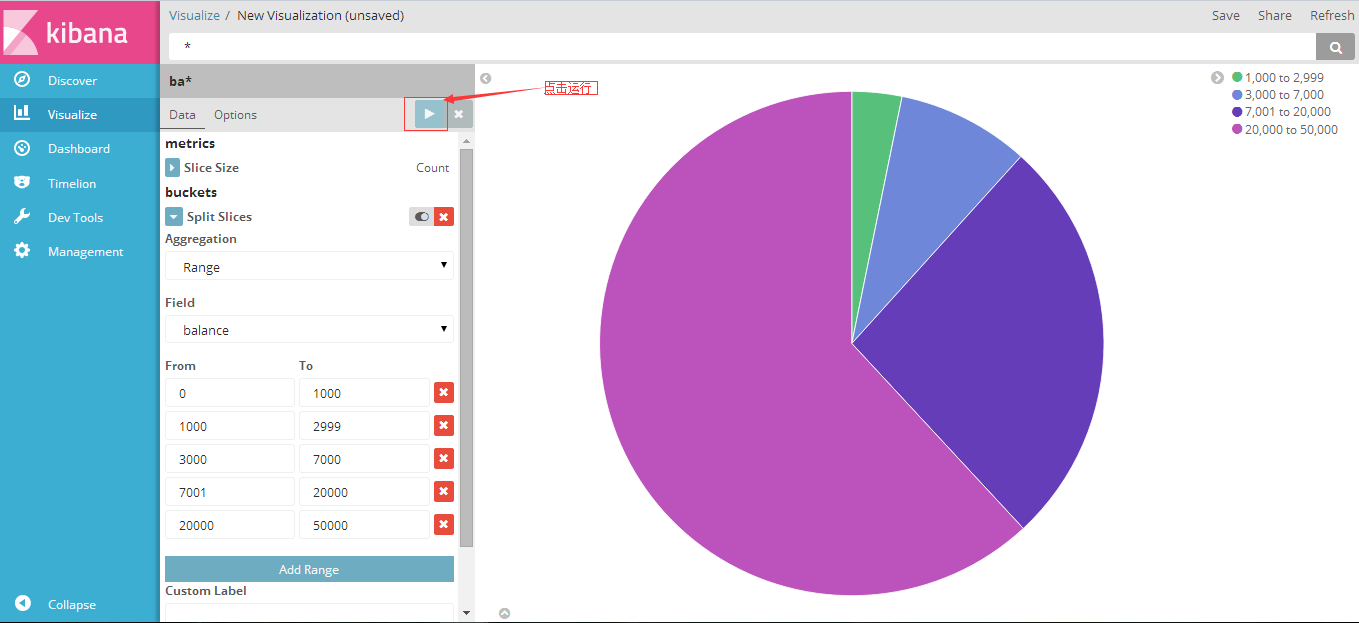
在此基础上再添加条件:(Add sub-buckets->Split Slices->aggregation ->Terms ->field ->age ->Apply changes运行):

点击右上角的save保存为pie-ba-example.
- 创建条形图:参考官方文档https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html得到结果如下:

- 保存为log-Vertical-example。
- 创建坐标图:参考官方文档https://www.elastic.co/guide/en/kibana/current/tutorial-visualizing.html得到结果如下:
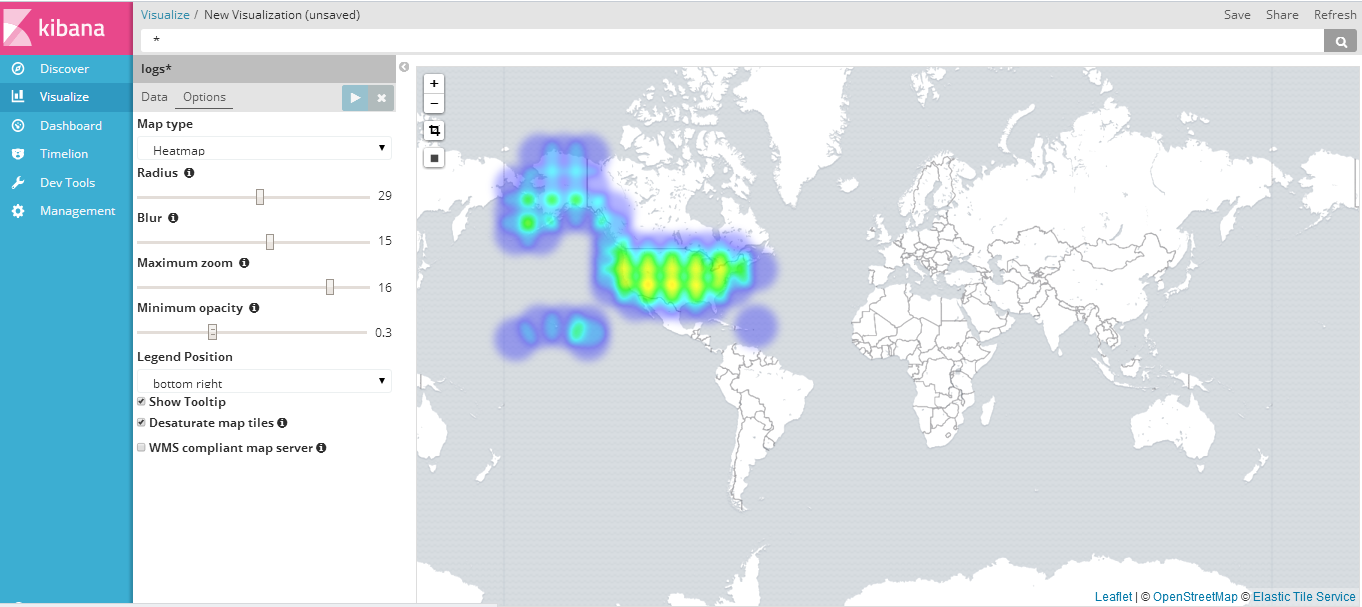
- 保存为log-map-example
4、dashboard:仪表盘,进行多图组合展示。
- dashboard->create a dashboard->add,然后根据过滤条件选择我们需要的图点击图选择,可将多图放在一起展示。将上几步做的进行展示如下:

- 保存为dashboard-example。
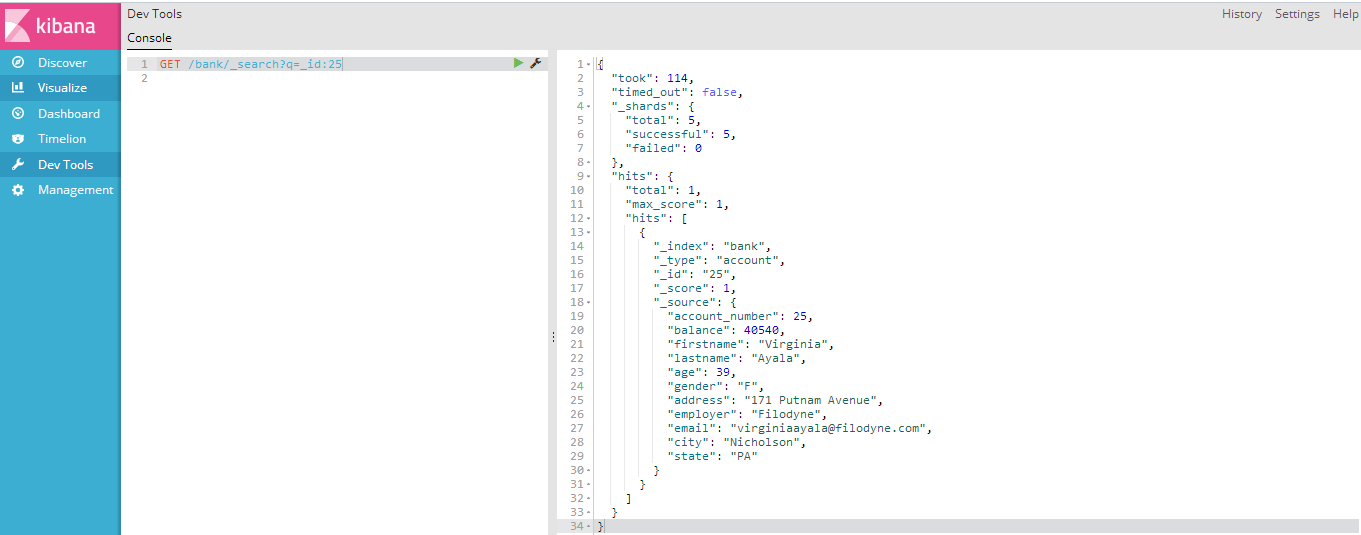
5、Dev Tools:控制台,可以发送http请求,用Curl可以做的请求,在这里都可以做。只要能和ES的REST API对接,都可以在这里做。
- GET:
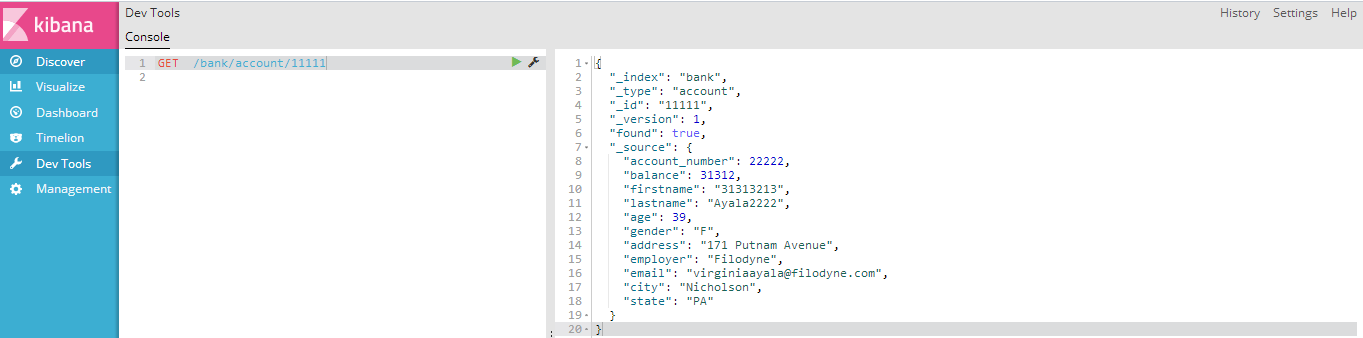
PUT:

DELETE:

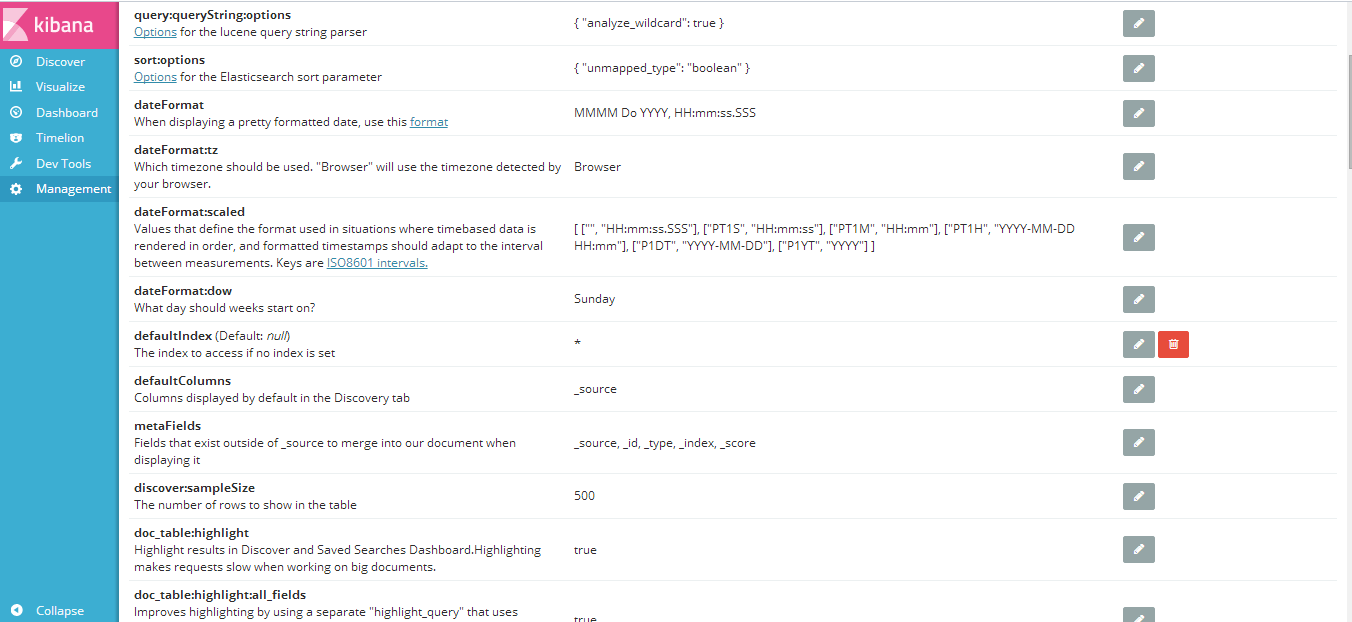
6、Management:管理Index Pattern,Object (创建保存的图像),系统的一些配置文件可以进行编辑,略过(暂时还没有细细研究)。
到这里,EK的安装和使用的基本介绍就完了。
注意:
我们在DB中创建数据库的时候是先配置schema在填写数据库的名字然后保存,这样一个数据库就建好了,这里在创建Mapping的时候其中就包含index的命名。其中Json参数包含type也就是表名,以及字段的定义。
Kibana主要做可视化展示,需要将可视化的组件多熟悉,了解过滤条件和聚合函数如此才能和业务结合。
[大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<2>的更多相关文章
- [大数据]-Elasticsearch5.3.1+Kibana5.3.1从单机到分布式的安装与使用<1>
一.Elasticsearch,Kibana简介: Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎.无论在开源还是专有领域, Lucene可以被认为是迄今为止最先 ...
- [大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置
--题外话:最近发现了一些问题,一些高搜索量的东西相当一部分没有价值.发现大部分是一些问题的错误日志.而我是个比较爱贴图的.搜索引擎的检索会将我们的博文文本分词.所以图片内容一般是检索不到的,也就是说 ...
- 大数据学习系列之二 ----- HBase环境搭建(单机)
引言 在上一篇中搭建了Hadoop的单机环境,这一篇则搭建HBase的单机环境 环境准备 1,服务器选择 阿里云服务器:入门型(按量付费) 操作系统:linux CentOS 6.8 Cpu:1核 内 ...
- [大数据]-Logstash-5.3.1的安装导入数据到Elasticsearch5.3.1并配置同义词过滤
阅读此文请先阅读上文:[大数据]-Elasticsearch5.3.1 IK分词,同义词/联想搜索设置,前面介绍了ES,Kibana5.3.1的安装配置,以及IK分词的安装和同义词设置,这里主要记录L ...
- HP PCS 云监控大数据解决方案
——把数据从分散统一集中到数据中心 基于HP分布式并行计算/存储技术构建的云监控系统即是通过“云高清摄像机”及IaaS和PaaS监控系统平台,根据用户所需(SaaS)将多路监控数据流传送给“云端”,除 ...
- 王家林的81门一站式云计算分布式大数据&移动互联网解决方案课程第14门课程:Android软硬整合设计与框架揭秘: HAL&Framework &Native Service &App&HTML5架构设计与实战开发
掌握Android从底层开发到框架整合技术到上层App开发及HTML5的全部技术: 一次彻底的Android架构.思想和实战技术的洗礼: 彻底掌握Andorid HAL.Android Runtime ...
- 王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上
王家林 Spark公开课大讲坛第一期:Spark把云计算大数据速度提高100倍以上 http://edu.51cto.com/lesson/id-30815.html Spark实战高手之路 系列书籍 ...
- 一站式Hadoop&Spark云计算分布式大数据和Android&HTML5移动互联网解决方案课程(Hadoop、Spark、Android、HTML5)V2的第一门课程
Hadoop是云计算的事实标准软件框架,是云计算理念.机制和商业化的具体实现,是整个云计算技术学习中公认的核心和最具有价值内容. 如何从企业级开发实战的角度开始,在实际企业级动手操作中深入浅出并循序渐 ...
- 大数据时代的杀手锏----Tachyon
一.Tachyon系统的简介 Tachyon是一个分布式内存文件系统,可以在集群里以访问内存的速度来访问存在tachyon里的文件.把 Tachyon是架构在最底层的分布式文件存储和上层的各种计算框架 ...
随机推荐
- 老司机带路——15个Android撸代码常见的坑
老司机为何能够成为老司机,不是因为开车开得多,而是撸多了… 0x00 使用 startActivityForResult 后在 onActivityResult 中没有正确回调到 Activity.R ...
- phpcms2008常用函数小结
{$head[title]} 页面标题,用法: <title>{$head[title]}-{$PHPCMS[sitename]}</title> {$PHPCMS[siten ...
- iOS 历史浏览网页的定向跳转
在实际的开发过程中,涉及到交互的问题,原生和H5的网页相互嵌套,直接造成跳转的混乱,混乱就应该指定的历史记录中,就需要网页的一些相关的一些属性问题 需要在webview里面的代理方法中执行相对应的操作 ...
- 【转】AS3操作XML,增加、删除、修改
var i:Number=0;//用于下面循环 var webcontent:String="Sontin's Blog <b>Welcome to 终吾一生</b> ...
- Dubbo的配置及使用
1. Dubbo是什么? Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案.简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需 ...
- 老李分享: 并行计算基础&编程模型与工具
在当前计算机应用中,对高速并行计算的需求是广泛的,归纳起来,主要有三种类型的应用需求: 计算密集(Computer-Intensive)型应用,如大型科学工程计算与数值模拟: 数据密集(Data-In ...
- C# Task 源代码阅读(1)
平时我们开发中,经常使用Task,后续的.net版本种很多都和Task有关,比如asyn,await有了Task 我们很少就去关注Thread 了.Task 给我们带来了很多的便利之处.是我们更少的去 ...
- python selenium2示例 - 生成 HTMLTestRunner 测试报告
前言 在python selenium2自动化测试过程中,一个合适的报告是必须的,而HTMLTestRunner模块为我们提供了一个很好的报告生成功能. 什么是HTMLTestRunner HTMLT ...
- 整合第二次(SSM第一次)------------>spring+struts2+mybatis
今天我们来讲解一下SSM整合,感觉整合这个比上一篇整合更费时,原因在于自己不太熟悉MyBatis了,下午的时候恶补了一下,看了一下相关的文档和PDF电子书,知识真的是你不用就会忘记的,以后还是不能懈怠 ...
- activiti 一个流程的运转步骤 以请假流程为例
---为了加深对activiti的理解记忆,对自己做的一个流程进行自述.加强记忆 请假实例 一.设计请假的流程图以及流程文件,完善对应数据项,比如用户信息,请假单信息 --请假单 --流程图 --流程 ...