Linux下Hadoop2.7.1集群环境的搭建(超详细版)

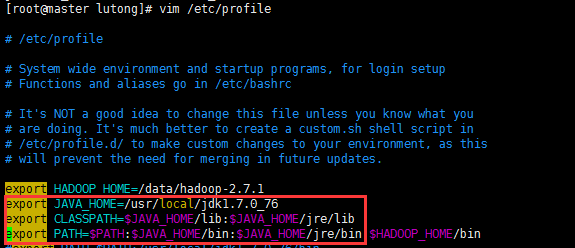

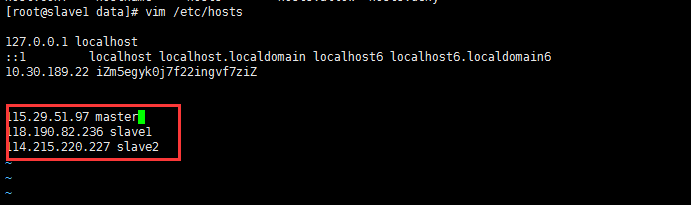
二、Host配置
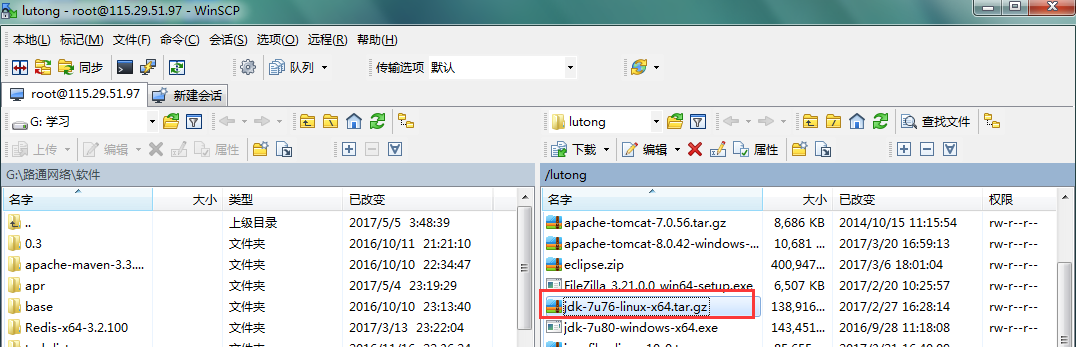
3.2 下载
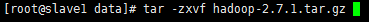
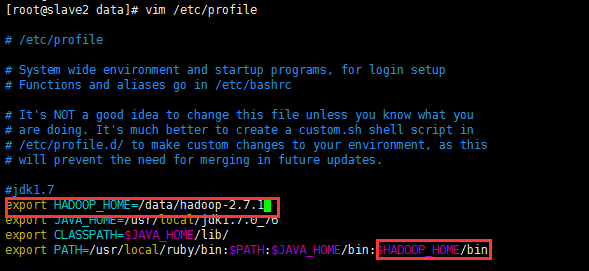





5.1 格式化NameNode
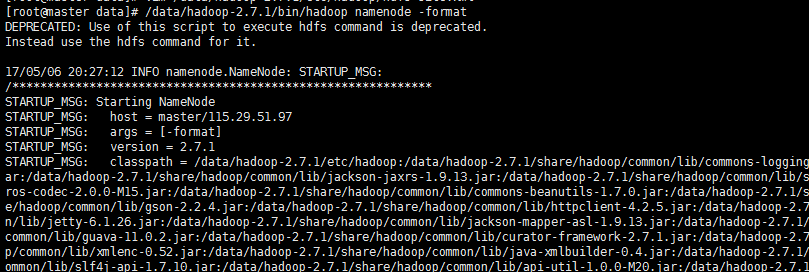
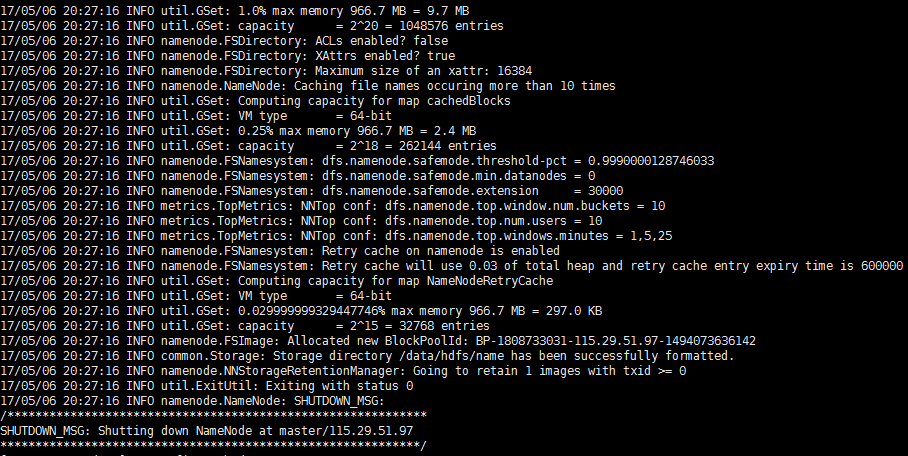
最后的执行结果如下图:
5.2 启动NameNode


在Master上执行jps命令,得到如下结果:


master

slave1

slave2

说明ResourceManager运行正常。

6.1 测试HDFS
最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:

6.2 测试YARN
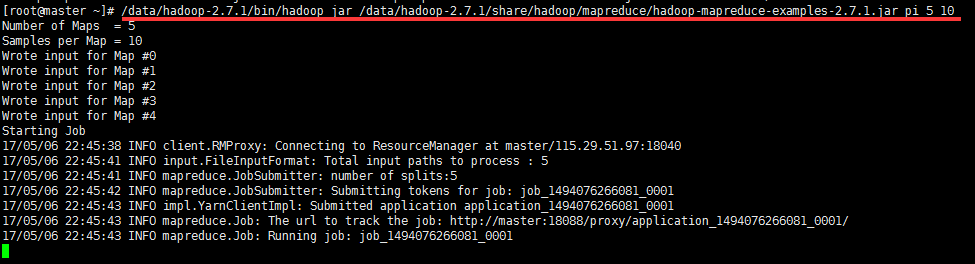
6.3 测试mapreduce
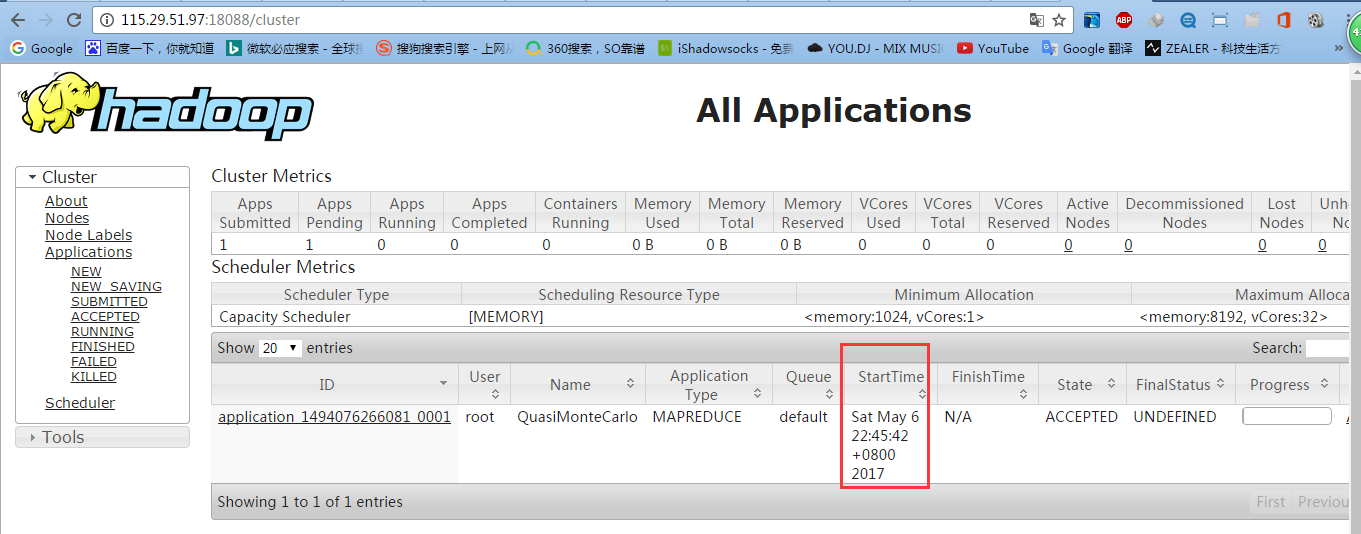
七、配置运行Hadoop中遇见的问题

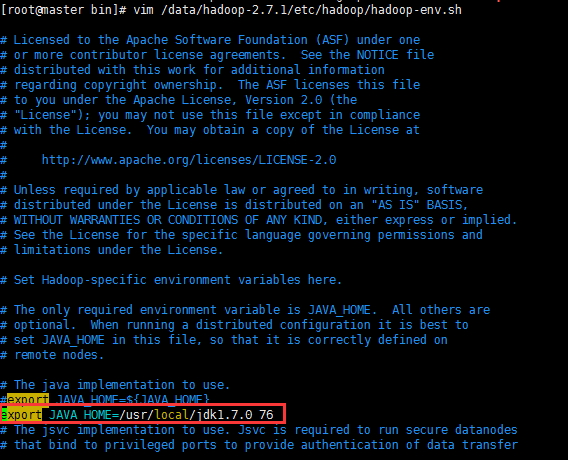
则需要/data/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路径
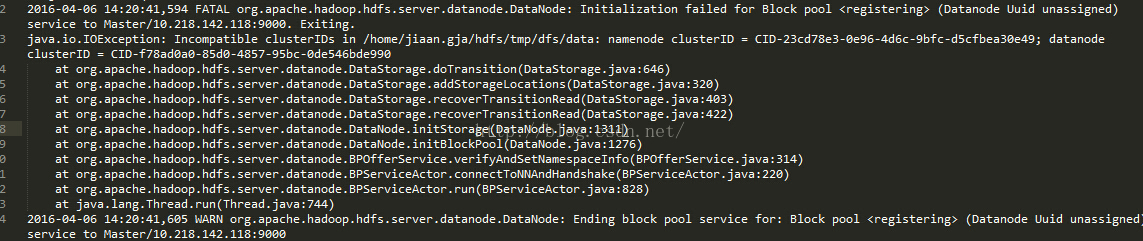
7.2 ncompatible clusterIDs
由于配置Hadoop集群不是一蹴而就的,所以往往伴随着配置——>运行——>。。。——>配置——>运行的过程,所以DataNode启动不了时,往往会在查看日志后,发现以下问题:
7.3 NativeCodeLoader的警告
在测试Hadoop时,细心的人可能看到截图中的警告信息:

Linux下Hadoop2.7.1集群环境的搭建(超详细版)的更多相关文章
- Linux下Hadoop2.7.3集群环境的搭建
Linux下Hadoop2.7.3集群环境的搭建 本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安 ...
- Linux下Hadoop2.6.0集群环境的搭建
本文旨在提供最基本的,可以用于在生产环境进行Hadoop.HDFS分布式环境的搭建,对自己是个总结和整理,也能方便新人学习使用. 基础环境 JDK的安装与配置 现在直接到Oracle官网(http:/ ...
- 基于原生态Hadoop2.6 HA集群环境的搭建
hadoop2.6 HA平台搭建 一.条件准备 软件条件: Ubuntu14.04 64位操作系统, jdk1.7 64位,Hadoop 2.6.0, zookeeper 3.4.6 硬件条件 ...
- (2)虚拟机下hadoop1.1.2集群环境搭建
hadoop集群环境的搭建和单机版的搭建差点儿相同,就是多了一些文件的配置操作. 一.3台主机的hostname改动和IP地址绑定 注意:以下的操作我都是使用root权限进行! (1)3太主机的基本网 ...
- centos6.5环境下zookeeper-3.4.6集群环境部署及单机部署详解
centos6.5环境下Zookeeper-3.4.6集群环境部署 [系统]Centos 6.5 集群部署 [软件]准备好jdk环境,此次我们的环境是open_jdk1.8.0_101 zookeep ...
- Linux下MySQL/MariaDB Galera集群搭建过程【转】
MariaDB介绍 MariaDB是开源社区维护的一个MySQL分支,由MySQL的创始人Michael Widenius主导开发,采用GPL授权许可证. MariaDB的目的是完全兼容MySQL,包 ...
- hadoop集群环境的搭建
hadoop集群环境的搭建 今天终于把hadoop集群环境给搭建起来了,能够运行单词统计的示例程序了. 集群信息如下: 主机名 Hadoop角色 Hadoop jps命令结果 Hadoop用户 Had ...
- Nacos集群环境的搭建与配置
Nacos集群环境的搭建与配置 集群搭建 一.环境: 服务器环境:CENTOS-7.4-64位 三台服务器IP:192.168.102.57:8848,192.168.102.59:8848,192. ...
- redis集群环境的搭建和错误分析
redis集群环境的搭建和错误分析 redis集群时,出现的几个异常问题 09 redis集群的搭建 以及遇到的问题
随机推荐
- 实用 .htaccess 用法大全
这里收集的是各种实用的 .htaccess 代码片段,你能想到的用法几乎全在这里. 免责声明: 虽然将这些代码片段直接拷贝到你的 .htaccess 文件里,绝大多数情况下都是好用的,但也有极个别情况 ...
- iOS开发之文件(分段)下载
1.HTTP HEAD方法 NSMutableURLRequest *request = [NSMutableURLRequest requestWithURL:url cachePolicy:0 t ...
- iOS开发之数据存储之SQLite3(包括FMDB)
1.概述 SQLite3是一款开源的嵌入式关系型数据库,可移植性好.易使用.内存开销小. SQLite3是无类型的,意味着你可以保存任何类型的数据到任意表的任意字段中.比如下列的创表语句是合法的: c ...
- 自动部署Nginx和nfs并架设Nginx集群脚本
本人经过多次尝试,简单完成了自动部署Nginx和nfs脚本,并且能够自动部署web反向代理集群,下面详细的阐述一下本人的思路.(以下脚本本人处于初学阶段,写的并不是很完善,所以需要后期进行整理和修正, ...
- Office 365开发环境概览
本文于2017年3月26日首发于LinkedIn,原文链接请参考这里 本系列文章已经按照既定计划在每周更新,此前的几篇文章如下 Office 365 开发概览系列文章和教程 Office 365开发概 ...
- EventBus通信小能手
1.EventBus简介 EventBus 是由 greenrobot 组织开发的一个 Android 事件发布/订阅轻量级框架,特点:代码简洁,是一种发布订阅设计模式(观察者设计模式). Even ...
- node.js平台下,利用cookie实现记住密码登陆(Express+Ejs+Mysql)
本博文需有node.js+express+mysql入门基础,若基础薄弱,可参考博主的其他几篇node.就是博文: 1.下载Mysql数据库,安装并配置 创建用户表供登录使用: 2.node.js平台 ...
- 光环国际的PRINCE2培训时间
一.光环国际的PRINCE2课程安排培训方式: 小班授课,50人为限; 全国网址直播课程,覆盖各个地区学员 精读原理配合独家开发大量实际案例研讨; 从商业战略角度解析PRINCE ...
- Eric的第一天
我叫刘志扬(ERIC),今天第一次来博客园,我是一个爱编程的小子,我使用开发工具Androidstudio(AS)我要把今后的问题记录在博客园里,欢迎大家点评,吐槽.
- 前端总结·基础篇·JS(四)异步请求及跨域方案
前端总结系列 前端总结·基础篇·CSS(一)布局 前端总结·基础篇·CSS(二)视觉 前端总结·基础篇·CSS(三)补充 前端总结·基础篇·JS(一)原型.原型链.构造函数和字符串(String) 前 ...