python--------------常用模块之正则
一、认识模块
什么是模块:一个模块就是一个包含了python定义和声明的文件,文件名就是加上.py的后缀,但其实import加载的模块分为四个通用类别 :
1.使用python编写的代码(.py文件)
2.已被编译为共享库二和DLL的C或C++扩展
3.包好一组模块的包
4.使用C编写并连接到python解释器的内置模块
为何要使用莫模块?
如果你想退出python解释器然后重新进入,那么你之前定义的函数或变量都将丢失,因此我们通常将程序写到文件中以便永久保存下来,需要时,就通过python test.py 方式去执行,此时test.py被称为脚本script。
随着程序的发展,功能越来越多,为了方便管理,我们通常将文件分成一个个的文件,这样做程序的结构更清晰,方便管理。这时我们不仅仅可以吧这些文件当做脚本去执行,还可以把它们当做模块来导入到其他模块中,实现了功能的重复利用。
二、常见模块分类
常用模块一、
collocations 模块
时间模块
random模块
os模块
sys模块
序列化模块
re模块
常用模块二:这些模块和面向对象有关
hashlib模块
configparse模块
logging模块
三、正则表达式
像我们平常见的那些注册页面啥的,都需要我们输入手机号码吧,你想我们的电话号码也是有限定的吧(手机号码一共11位,并且只以13,14,15,17,18开头的数字这些特点)如果你的输入有误就会提示,那么实现这个程序的话你觉得用While循环so easy嘛,那么我们来看看实现的结果。
while True:
phone_number=input('请输入你的电话号码:')
if len(phone_number)==11 and phone_number.isdigit()\
and (phone_number.startswith('')\
or phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('') \
or phone_number.startswith('')):
print('是合法的手机号码')
else:
print('不是合法的手机号码')
判断手机号码是否合法
看到这个代码,虽说理解很容易,但是我还有更简单的方法。那我们一起来看看吧。
import re
phone_number=input('请输入你的电话号码:')
if re.match('^(13|14|15|17|18)[0-9]{9}$',phone_number):
'''^这个符号表示的是判断是不是以13|14|15|17|18开头的,
[0-9]: []表示一个字符组,可以表示0-9的任意字符
{9}:表示后面的数字重复九次
$:表示结束符
'''
print('是合法的手机号码')
else:
print('不是合法的手机号码')
判断手机号码输入是否合法
大家可能都觉的第一种方法更简单吧,但是如果我让你从整个文件中匹配出所有的手机号码,你能用python写出来吗?但是导入re模块和利用正则表达式就可以解决这一个问题了。
那么什么是正则呢?
首先你要知道的是,谈到正则,就只和字符串相关了。在线测试工具 http://tool.chinaz.com/regex/
比如你要用‘1’去匹配‘1’,或者用‘2’去匹配‘2’,直接就可以匹配上。
字符组:[字符组]
在同一位置可能出现的各种字符组成了一个字符组,在正则表达式中用[]表示
字符分为很多类,比如数字,字母,标点等登。
假如你现在要求一个位置‘只能出现一个数字’,那么这个位置上的字符只能是0、1、2、3.......9这是个数之一。
字符组:

字符:

量词:
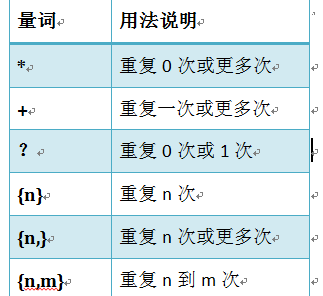
.^$

*+?{}

注意:前面的*,+,?等都是贪婪匹配,也就是尽可能多的匹配,后面加?就变成了非贪婪匹配,也就是惰性匹配。
贪婪匹配:

几个常用的配贪婪匹配
*?;重复任意次,但尽可能少重复
+?:重复一次或更多次,但尽可能少重复
??:重复0次或1次,但尽可能少重复
{n,m}:重复n到m次,但尽可能少重复
{n,}: 重复n次以上,但尽可能少重复
.*?的用法:
.是任意字符
*是取0到无限长度
?是非贪婪模式
和在一起就是取尽量少的任意字符,一般不会这么单独写,大多用在:
.*?x
意思就是取前面任意长度的字符,直到一个x出现
字符集:
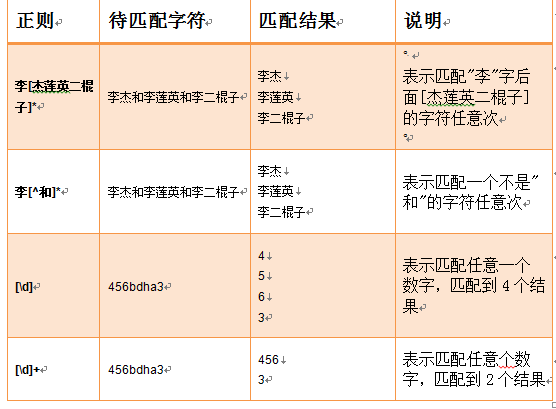
分组()与或|[^]:
(1)^[1-9]\d{13,16}[0-9x]$ #^以数字0-9开始,
\d{13,16}重复13次到16次
$结束标志
上面的表达式可以匹配一个正确的身份证号码
(2)^[1-9]\d{14}(\d{2}[0-9x])?$
#?重复0次或者1次,当是0次的时候是15位,是1的时候是18位
(3)^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
#表示先匹配[1-9]\d{16}[0-9x]如果没有匹配上就匹配[1-9]\d{14}
举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的。因此,如果想获取页面标题(xxx),充其量只能写一个类似于这样的表达式:<title>.*</title>,而这样写匹配出来的是完整的<title>xxx</title>标签,并不是单纯的页面标题xxx。
想解决以上问题,就要用到断言知识。
在讲断言之前,读者应该先了解分组,这有助于理解断言。
分组在正则中用()表示,根据小菜理解,分组的作用有两个:
n 将某些规律看成是一组,然后进行组级别的重复,可以得到意想不到的效果。
n 分组之后,可以通过后向引用简化表达式。
先来看第一个作用,对于IP地址的匹配,简单的可以写为如下形式:
\d{1,3}.\d{1,3}.\d{1,3}.\d{1,3}
但仔细观察,我们可以发现一定的规律,可以把.\d{1,3}看成一个整体,也就是把他们看成一组,再把这个组重复3次即可。表达式如下:
\d{1,3}(.\d{1,3}){3}
这样一看,就比较简洁了。
再来看第二个作用,就拿匹配<title>xxx</title>标签来说,简单的正则可以这样写:
<title>.*</title>
可以看出,上边表达式中有两个title,完全一样,其实可以通过分组简写。表达式如下:
<(title)>.*</\1>
这个例子实际上就是反向引用的实际应用。对于分组而言,整个表达式永远算作第0组,在本例中,第0组是<(title)>.*</\1>,然后从左到右,依次为分组编号,因此,(title)是第1组。
用\1这种语法,可以引用某组的文本内容,\1当然就是引用第1组的文本内容了,这样一来,就可以简化正则表达式,只写一次title,把它放在组里,然后在后边引用即可。
以此为启发,我们可不可以简化刚刚的IP地址正则表达式呢?原来的表达式为\d{1,3}(.\d{1,3}){3},里边的\d{1,3}重复了两次,如果利用后向引用简化,表达式如下:
(\d{1,3})(.\1){3}
简单的解释下,把\d{1,3}放在一组里,表示为(\d{1,3}),它是第1组,(.\1)是第2组,在第2组里通过\1语法,后向引用了第1组的文本内容。
经过实际测试,会发现这样写是错误的,为什么呢?
小菜一直在强调,后向引用,引用的仅仅是文本内容,而不是正则表达式!
也就是说,组中的内容一旦匹配成功,后向引用,引用的就是匹配成功后的内容,引用的是结果,而不是表达式。
因此,(\d{1,3})(.\1){3}这个表达式实际上匹配的是四个数都相同的IP地址,比如:123.123.123.123。
至此,读者已经掌握了传说中的后向引用,就这么简单。
对于分组的理解
分组命名:语法(?p<name>)注意先命名,后正则
import re
import re
ret=re.search('<(\w+)>\w+<(/\w+)>','<h1>hello</h1>')
print(ret.group())
# 给分组起个名字。就用下面的分组命名,上面的方法和下面的分组命名是一样的,只不过就是给命了个名字
ret=re.search('<(?P<tag_name>\w+)>\w+</(?P=tag_name)>','<h1>hello</h1>') #(?P=tag_name)就代表的是(\w+)
print(ret.group()) # 了解(和上面的是一样的,是上面方式的那种简写)
ret=re.search(r'<(\w+)>\w+</\1>','<h1>hello</h1>')
print(ret.group(1))
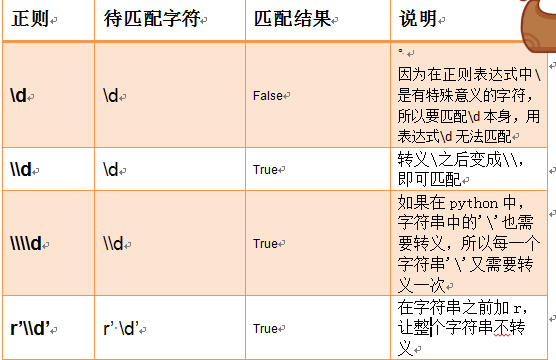
转义符:
四、re模块
# 1.re模块下的常用方法
# 1.findall方法
import re
ret = re.findall('a','eva ang egons')
# #返回所有满足匹配条件的结果,放在列表里
print(ret) # 2.search方法
# 函数会在字符串中查找模式匹配,只会找到第一个匹配然后返回
# 一个包含匹配信息的对象,该对象通过调用group()方法得到匹配的
# 字符串,如果字符串没有匹配,则报错
ret = re.search('s','eva ang egons')#找第一个
print(ret.group()) # 3.match方法
print(re.match('a','abc').group())
#同search,只从字符串开始匹配,并且guoup才能找到 # 4.split方法
print(re.split('[ab]','abcd'))
#先按'a'分割得到''和'bcd',在对''和'bcd'分别按'b'分割 # 5.sub方法
print(re.sub('\d','H','eva3sdf4ahi4asd45',1))
# 将数字替换成'H',参数1表示只替换一个 # 6.subn方法
print(re.subn('\d','H','eva3sdf4ahi4asd45'))
#将数字替换成’H‘,返回元组(替换的结果,替换了多少次) # 7.compile方法
obj = re.compile('\d{3}')#将正则表达式编译成一个正则表达式对象,规则要匹配的是三个数字
print(obj)
ret = obj.search('abc12345eeeee')#正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #.group一下就显示出结果了 # 8.finditer方法
ret = re.finditer('\d','dsf546sfsc')#finditer返回的是一个存放匹配结果的迭代器
# print(ret)#<callable_iterator object at 0x00000000021E9E80>
print(next(ret).group())#查看第一个结果
print(next(ret).group())#查看第二个结果
print([i.group() for i in ret] )#查看剩余的左右结果
re模块相关的方法
import re
ret = re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret) #结果是['oldboy']这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret = re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret) #['www.oldboy.com']
findall的优先级查询
ret = re.split('\d+','eva123dasda9dg')#按数字分割开了
print(ret) #输出结果:['eva', 'dasda', 'dg']
ret = re.split('(\d+)','eva123dasda9dg')
print(ret) #输出结果:['eva', '123', 'dasda', '9', 'dg']
#
# 在匹配部分加上()之后和不加括号切出的结果是不同的,
# 没有括号的没有保留所匹配的项,但是有括号的却能够保留了
# 匹配的项,这个在某些需要保留匹配部分的使用过程是非常重要的
split的优先级查询
五、re模块和正则表达式的关系
re模块和正则表达式没有一点毛线关系。re模块和正则表达式的关系类似于time模块和时间的关系,你没有学习python之前,也不知道有一个time模块,但是你已经认识时间了呀,12:30就表示中午十二点半。时间有自己的格式,年月日时分秒,已成为一种规则。你早就牢记于心了,time模块只不过是python提供给我们的可以方便我们操作时间的一个工具而已。
六、collections模块
在内置数据类型(dict,list,set,tuple)的基础上,collections 模块还提供了几个额外的数据类型:
1.namedtuple:生成可以使用名字来访问元素内容的tuple
2.deque:双向队列(两头都可进可出,但是不能取中间的值),可以快速的从另外一侧追加和推出对象
3.Counter:计数器,主要用来计数
4.OrderedDict:有序字典
5.defaultdict:带有默认值的字典
namedtuple:
我们知道tuple可以表示不变集合,例如,一个点的二维坐标就可以表示成:p=(1,2)
但是,看到(1,2),很难看出这个tuple是用来表示坐标的。
那么,我们的namedtuple就能用上了。
namedtuple('名称',‘属性list’)
from collections import namedtuple
point = namedtuple('point',['x','y'])
p = point(1,2)
print(p.x,p.y)、
Circle = namedtuple('Circle', ['x', 'y', 'r'])#用坐标和半径表示一个圆
deque
单向队列
# import queue #队列模块
# q = queue.Queue()
# q.put(10)
# q.put(20)
# q.put(30)
# # 10 20 30
# print(q.get())
# print(q.get())
# print(q.get())
# print(q.get())
deque是为了高效实现插入和删除操作的双向队列,适用于队列和栈
from collections import deque
q = deque(['a','b','c'])
q.append('ee')#添加元素
q.append('ff')
q.append('qq')
print(q)
q.appendleft('www')#从左边添加
print(q) q.pop() #删除元素
q.popleft() #从左边删除元素
print(q)
OrderedDict
使用字典时,key是无序的。在对字典做迭代时,我们无法确定key的顺序。如果要保持key的顺序,可以用OrderedDict
from collections import OrderedDict
d = {'z':'qww','x':'asd','y':'asd','name':'alex'}
print(d.keys()) #key是无序的
od = OrderedDict([('a', 1), ('b', 2), ('c', 3)]) print(od)# OrderedDict的Key是有序的
OrderedDict([('a', 1), ('b', 2), ('c', 3)])
OrderedDict的Key会按照插入的顺序排列,不是Key本身排序:od = OderedDict ()
od['z']=1
od['y']=2
od['x']=3
print(od.keys()) #按照插入额key的顺序返回
defaultdict
d = {'z':'qww','x':'asd','y':'asd','name':'alex'}
print(d.keys())
from collections import defaultdict
values = [11,22,33,44,55,66,77,88,99]
my_dict = defaultdict(list)
for v in values:
if v>66:
my_dict['k1'].append(v)
else:
my_dict['k2'].append(v)
print(my_dict)
找大于66和小于66的
from collections import defaultdict
dd = defaultdict(lambda: 'N/A')
dd['key1'] = 'abc'
print(dd['key1']) # key1存在 print(dd['key2']) # key2不存在,返回默认值
defaultdict
Counter
Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。计数值可以是任意的Interger(包括0和负数)。Counter类和其他语言的bags或multisets很相似。
from collections import Counter
c = Counter('abcdeabcdabcaba')
print(c)
# 输出:Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
其他详细内容 http://www.cnblogs.com/Eva-J/articles/7291842.html
python--------------常用模块之正则的更多相关文章
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- python——re模块(正则表达)
python——re模块(正则表达) 两个比较不错的正则帖子: http://blog.csdn.net/riba2534/article/details/54288552 http://blog.c ...
- python常用模块 以及第三方导入
python常用模块 1模块的分类 标准模块(内置模块)( 标准库 )300 第三方模块 18万 pip install 直接通过pip安装 软件一般会被自动安装你python安装目录的这个子目录里 ...
- Python常用模块之sys
Python常用模块之sys sys模块提供了一系列有关Python运行环境的变量和函数. 常见用法 sys.argv 可以用sys.argv获取当前正在执行的命令行参数的参数列表(list). 变量 ...
- Python常用模块中常用内置函数的具体介绍
Python作为计算机语言中常用的语言,它具有十分强大的功能,但是你知道Python常用模块I的内置模块中常用内置函数都包括哪些具体的函数吗?以下的文章就是对Python常用模块I的内置模块的常用内置 ...
- python——常用模块2
python--常用模块2 1 logging模块 1.1 函数式简单配置 import logging logging.debug("debug message") loggin ...
- python——常用模块
python--常用模块 1 什么是模块: 模块就是py文件 2 import time #导入时间模块 在Python中,通常有这三种方式来表示时间:时间戳.元组(struct_time).格式化的 ...
- Python常用模块——目录
Python常用模块学习 Python模块和包 Python常用模块time & datetime &random 模块 Python常用模块os & sys & sh ...
- python 常用模块之random,os,sys 模块
python 常用模块random,os,sys 模块 python全栈开发OS模块,Random模块,sys模块 OS模块 os模块是与操作系统交互的一个接口,常见的函数以及用法见一下代码: #OS ...
- python常用模块之时间模块
python常用模块之时间模块 python全栈开发时间模块 上次的博客link:http://futuretechx.com/python-collections/ 接着上次的继续学习: 时间模块 ...
随机推荐
- SharePoint 2013 安装
步骤 1:打开提升的 SharePoint 2013 命令行管理程序 选择与您的服务器操作系统对应的过程. 在 Windows Server 2008 R2 中 单击“开始”>“所有程序”> ...
- Tween 若干年后我尽然还要学数学 曲线到底是什么鬼啊
var Tween = { linear: function (t, b, c, d){ //匀速 return c*t/d + b; }, easeIn: function(t, b, c, d){ ...
- jpg、jpeg、png... 的区别
对于做设计这一行的人来说,这几个图片格式是最常用的,也是最常见的,几乎每一天都要与他们打交道. 刚刚入门的新人通常不知道在什么地方如何使用他们或者说如何更有效的使用他们. 那他们到底是有什么区别?(一 ...
- Java自学手记——接口
抽象类 1.当类和对象被abstract修饰符修饰的时候,就变成抽象类或者抽象方法.抽象方法一定要在抽象类中,抽象类不能被创建对象,如果需要使用抽象类中的抽象方法,需要由子类重写抽象类中的方法,然后创 ...
- Selenium webdriver定位iframe里面元素两种方法
以东方财富网登录页面为例: 在查找元素过程中,直接通过id或者xpath等找不到元素,查看页面源代码发现元素是属于iframe里,例如: <div class="wrap_login& ...
- 【菜鸟入门】安装配置eclipse 并编写运行第一个Java程序
不得不吐槽一下,安装配置这eclipse真是太费劲了...下面总结一下,以便下次再安装 本人 win10系统,64位机 一.在官网下载eclipse安装包 文件名:eclipse-inst-win64 ...
- 基于jenkins搭建一个持续集成服务器
1 引言 1.1 编写目的 指导质量管理部,业务测试组同事进行Jenkins环境部署,通过Jenkins解决测试环境不可控,开发测试环境不一致等问题. 1.2 使用对象 质量管理部.基础研发部,集成部 ...
- Selenium自动化初级/中级网络授课班招生
近期学习selenium和appium的测试人员越来越多,应广大刚接触UI自动化以及对selenium想要更深入了解的测试人员的要求,特请一位资深测试架构师为我们开课讲解selenium,以及如何设计 ...
- 快速搞定selenium grid分布式
写这篇文章,似乎有点重复造轮子的嫌疑.当看了几篇相关文章后,我还是决定把半年前的半成品给完成了. 以传统的方式部署分布式Selenium Grid集群需要耗费大量时间和机器成本来准备测试环境. Sna ...
- (转)PLSQL Developer导入Excel数据
场景:近来在做加班记录的统计,主要是统计Excel表格中的时间,因为我对于Excel表格的操作不是很熟悉,所以就想到把表格中的数据导入到数据库中,通过脚本语言来统计,就很方便了!但是目前来看,我还没有 ...