Orleans的集群构建
Orleans的集群构建
这是Orleans系列文章中的一篇.首篇文章在此
听闻一周前,微软公布了.net core2.0,以及各种各样的其他core2.0.大家都很兴奋.微妈的诚意真是满满的.这次开源势头让我感觉到了微妈的技术实力之雄厚.我在这里祝福C#越来越好.细心的人似乎发现Orleans在github中是和net core分在一起的.Orleans的2.0何时发布呀…
现在我们面对的Orleans1.5(github上是1.6)已经是一个成熟的框架了.涉及到分布式的方方面面,我突然觉得我原来暂定的8篇文章都介绍不完全.我尽量介绍完整,至少让大家能入门,后边的修行就看大家自己的努力了.如果读者中有人能够和我分享,与我共同讨论我也是非常欢迎的.我的联系方式在第一篇文章中这里就不再复述了.
我现在利用<Orleans简单配置>文章中介绍的内容,配置一个可以分布式的silo,观察它们的行为.这里只介绍2种,其余的配置方式往读者自己研究.
我先说利用sql server数据库作为"服务自我发现"的服务
还是跟以前一样,我一步一步来.
基于SQL server的集群步骤
- 回顾之前的文章中在集群中客户端配置应该是这个模样:
<ClientConfiguration xmlns="urn:orleans">
<SystemStore SystemStoreType="SqlServer"
DeploymentId="target deployment ID"
DataConnectionString="SQL connection string"/>
</ClientConfiguration>
这里解释一下,还记得持久化中配置文件的主体是什么吗?对了是<StorageProviders>节.这个节的内容定义了Orleans在持久化时,要利用的存储中间件的各种参数.
而我们这里要利用的是<SystemStore>,它定义了与"系统"相关的变量应该存储在哪里.我只要定义好<SystemStore>后Orleans就会自动使用服务发现.
由于Orleans使用MembershipTable 来控制silo与silo的关系变化(谁加入了集群,谁离开了集群等等)如果配置好了<SystemStore>,这个MembershipTable就会存储在数据库中.所有的silo都要以数据库中的成员关系表为标准.这个表长成这个样子
其中有一个字段就是silo的地址.因此silo可以发现其他的silo,它们可以构成一个集群,而client可以发现集群内所有的silo.从而与集群互动.
- 按照以上讨论,我修改了一下配置文件.如下.
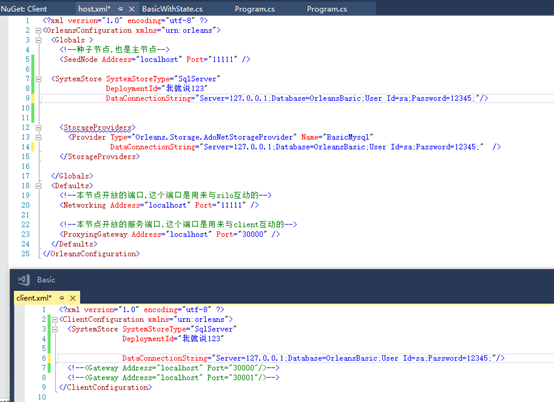
此处client也需要配置,因为client也需要读取成员关系表,以便知道所有silo的地址和状态.为了使client可以利用<SystemStore>必须在client里引用OrleansSQLUtils以及System.Data.SqlClient的包,
- 运行一下,就会有如下截图

- 再运行一个.找到host.exe,我们双击后再运行一个,会看到错误,这是因为silo配置文件中指明了一些端口,这些端口已经被第一个silo占用了,所以我修改一些host的配置文件,再次运行,会得到如下截图
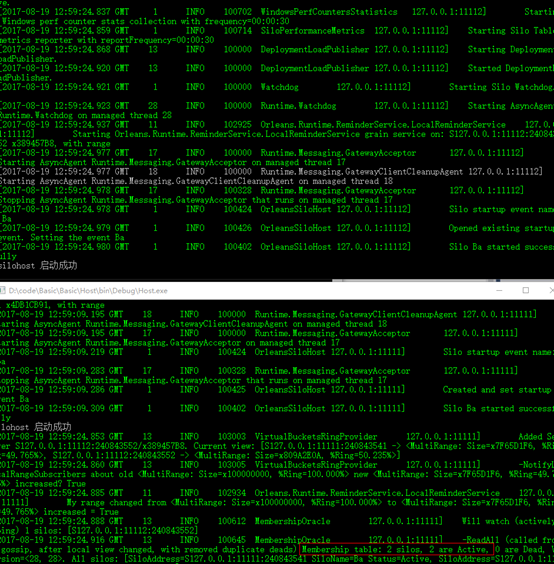
我们看到先启动的silo发现了新加入的silo.读者可以再次实验silo离开后的情况.
- 此时我让client运行,就会得到如下截图

可以看到client发送的消息均衡负载地再两个silo内执行.
至此一个基于sql server的简单silo集群就搭建完毕…这个集群虽然简单,但是满足所有高级的特性,扩展性和稳定性双优.是居家旅行的良好解决方案.只要有一个silo存活,这个集群就不会倒..
基于consul的集群
下文将介绍一下,另一个轻量级的集群实现.这个实现的步骤来自于官方教程.我再刚开始学习Orleans的时候,曾经使用这个步骤构建过集群.因为这个步骤是官方教程里一个最为详细的步骤,所以我就照做了.
1. 创建一个文件夹用来放置consul 比如 c:\consul.
2. 创建一个子文件夹放置数据 比如 c:\consul\data(consul不会自己创建.)
3. 下载并解压consul到c:\consul
4. 打开cmd,转至 c:\consul
5. 运行 Consul.exe agent -server -bootstrap -data-dir "C:\Consul\Data" -client=0.0.0.0
agent 指示consul新运行承载服务的代理进程,如果缺少这个参数 consul进程就尝试使用RPC来配置一个正在运行的代理进程
-server 指明这个代理进程是服务而不是client(一个consul client承载着所有的服务和数据,但是它没有权利投票,也没有可能成为consul集群领导)
-bootstrap consul集群中的第一个节点必须是有这个参数,它同时也是consul集群的领导.(单实例consule,,无所谓了)
-data-dir [path] 指明数据存储地址
-client=0.0.0.0 指明consule的服务地址
还有很多其他的consule参数.它们可以用json文件来配置,阅读consul文章来详细了解
确保consul已经运行了,请在浏览器里输入以下网址http://localhost:8500/v1/catalog/services 看看
6. 配置服务器
<OrleansConfiguration xmlns="urn:orleans">
<Globals>
<SystemStore SystemStoreType="None" DataConnectionString="http://localhost:8500" DeploymentId="MyOrleansDeployment" />
</Globals>
<Defaults>
<Networking Address="localhost" Port="22222" />
<ProxyingGateway Address="localhost" Port="30000" />
</Defaults>
</OrleansConfiguration>
并在host项目中的program.cs中,手动增加以下内容
silohost.Config.Globals.LivenessType = GlobalConfiguration.LivenessProviderType.Custom;
silohost.Config.Globals.MembershipTableAssembly = "OrleansConsulUtils";
silohost.Config.Globals.ReminderServiceType = GlobalConfiguration.ReminderServiceProviderType.Disabled;
silohost.InitializeOrleansSilo();
官方解释说: Consul的xml配置文件,Orleans在解析的时候有点小bug所以要在代码中控制一下.我在搭配的时候就采用了这个,但是我并没有验证此bug是否依然存在(官方教程是1.2的,我写的时候已经是1.5了).
好了这样一个基于consul的集群就构建好了.
经过以上的文章介绍,Orleans主要方面都或多或少的涉及到了,我写这系列文章的目的也快要达到了.除去一个方面,那就是eventSourcing.由于EventSourcinig是个复杂的事情,我需要组织语言,而且最近家里私事很多.也许下一篇文章放出的时候会很晚.因为接下来我没有太多时间.
Orleans的集群构建的更多相关文章
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
- RabbitMQ从零到集群高可用(.NetCore5.0) -高可用集群构建落地
系列文章: RabbitMQ从零到集群高可用(.NetCore5.0) - RabbitMQ简介和六种工作模式详解 RabbitMQ从零到集群高可用(.NetCore5.0) - 死信队列,延时队列 ...
- [k8s]jenkins配合kubernetes插件实现k8s集群构建的持续集成
另一个结合harbor自动构建镜像的思路: 即code+baseimage一体的方案 - 程序员将代码提交到代码仓库gitlab - 钩子触发jenkins master启动一次构建 - jenkin ...
- spark集群构建
一.spark启动有standalong.yarn.cluster,具体的他们之间的区别这里不在赘述,请参考官网.本文采用的是standalong模式进行搭建及将接使用. 1.首先去官网下载需要的sp ...
- solr集群构建的基本流程介绍
先从第一台solr服务器说起:1. 它首先启动一个嵌入式的Zookeeper服务器,作为集群状态信息的管理者,2. 将自己这个节点注册到/node_states/目录下3. 同时将自己注册到/live ...
- RabbitMQ基础使用之集群构建
简介 RabbitMQ是基于Erlang开发的一种消息队列服务,本篇文章主要部署三台机器用来实现集群的普通模式与镜像模式!欢迎大家吐槽交流学习! 特点 集群节点包括内存节点和磁盘节点,有了磁盘节点就支 ...
- NATS_11:NATS集群构建与验证
NATS服务集群化 NATS支持每一个服务按照集群模式方式运行.你可以将这些服务组织在一起形成一个集群来提高服务器的容量的消息传递系统,并可以提升整个系统的弹性话和高可用性. 注意,NATS集群服务器 ...
- 分布式FastDfs+nginx缓存高可用集群构建
介绍: FastDFS:开源的高性能分布式文件系统:主要功能包括:文件存储,文件同步和文件访问,以及高容量和负载平衡 FastDFS:角色:跟踪服务器(Tracker Server).存储服务器(St ...
- activitmq+keepalived+nfs 非zk的高可用集群构建
nfs 192.168.10.32 maast 192.168.10.4 savel 192.168.10.31 应对这个需求既要高可用又要消息延迟,只能使用变态方式实现 nfs部署 #yum ins ...
随机推荐
- iOS多线程开发之NSOperation - 快上车,没时间解释了!
一.什么是NSOperation? NSOperation是苹果提供的一套多线程解决方案.实际上NSOperation是基于GCD更高一层的封装,但是比GCD更加的面向对象.代码可读性更高.可控性更强 ...
- 使用boost/property_tree进行XML操作
之前一直用tinyxml来进行XML文件操作,刚刚接触的一个测试项目是使用boost操作的,虽然不清楚这两者的差异,但boost使用起来还挺方便的,所以简单整理一些关于boost解析和创建XML文件的 ...
- Hadoop的配置过程(虚拟机中的伪分布模式)
1引言 hadoop如今已经成为大数据处理中不可缺少的关键技术,在如今大数据爆炸的时代,hadoop给我们处理海量数据提供了强有力的技术支撑.因此,了解hadoop的原理与应用方法是必要的技术知识. ...
- Centos7 安装keepalived实现高可用
场景:尝试安装keepalived实现高可用,进而在suse环境中部署. 测试过程需要配合Nginx的相关知识:Centos7 Nginx安装 1 安装过程 问题 !!! OpenSSL is not ...
- (转)Spring boot——logback.xml 配置详解(四)<filter>
文章转载自:http://aub.iteye.com/blog/1101260,在此对作者的辛苦表示感谢! 1 filter的使用 <filter>: Logback的过滤器基于三值逻辑( ...
- 【D3】cluster layout
一. 和其他D3类一样,layout 可以链式传递,使用简明的申明添加多种自定义设置. 二.API # d3.layout.cluster() Creates a new cluster layout ...
- JStorm与Storm源码分析(三)--Scheduler,调度器
Scheduler作为Storm的调度器,负责为Topology分配可用资源. Storm提供了IScheduler接口,用户可以通过实现该接口来自定义Scheduler. 其定义如下: public ...
- ES6中的迭代器(Iterator)和生成器(Generator)
前面的话 用循环语句迭代数据时,必须要初始化一个变量来记录每一次迭代在数据集合中的位置,而在许多编程语言中,已经开始通过程序化的方式用迭代器对象返回迭代过程中集合的每一个元素 迭代器的使用可以极大地简 ...
- 初学者:浅谈web前端就业的学习路线
初级前端 主要学习三个部分:HTML,CSS,JavaScript 一.html + css部分: 这部分特别简单,到网上搜资料,书籍视频非常多.css中盒子模型,流动,block,inline,层叠 ...
- centos7启动过程及systemd祥细说明
开机启过程 POST->BOOT SEQUENCE-> BOOTLOADER->KERNEL + INITRAMFS(INITRD)->ROOTFS->/sbin/ini ...