数据结构与算法(C/C++版)【树与二叉树】
第六章《树与二叉树》
树结构是一种非线性存储结构,存储的是具有“一对多”关系的数据元素的集合。

结点: A、B、C等,结点不仅包含数据元素,而且包含指向子树的分支。例如,A结点不仅包含数据元素A,而且包含3个指向子树的指针。
结点的度: 结点拥有的子树个数或者分支的个数。例如,A结点有3棵子树,所以A结点的度为3。
树的度:树中各结点度的最大值。如例子中结点度最大为3(A、D结点),最小为O(F、G、I、J、K、L、M结点),所以树的度为3。
叶子结点:又叫作终端结点,指度为0的结点,如F、G、I、J、K、L、M结点都是叶子结点。
非终端结点: 又叫作分支结点,指度不为0的结点,如A、B、C、D、E、H结点都是非终端结点。除了根结点之外的非终端结点,也叫作内部结点,如B、c、D、E、H结点都是内部结点。
孩子:结点的子树的根,如A结点的孩子为B、C、D。
双亲:与孩子的定义对应,如B、C、D结点的双亲都是A。
兄弟:同一个双亲的孩子之间互为兄弟。如B、c、D互为兄弟,因为它们都是A结点的孩子。
祖先:从根到某结点的路径上的所有结点,都是这个结点的祖先。如K的祖先是A、B、E,因为从A到K的路径为A一B一E一K。
子孙: 以某结点为根的子树中的所有结点,都是该结点的子孙。如D的子孙为H、I、J、M。
层次:从根开始,根为第一层,根的孩子为第二层,根的孩子的孩子为第三层,以此类推。
树的深度和高度:树中结点的最大层次。如例子中的树共有4层,所以高度为4。
结点的深度和高度: 结点深度是从根结点算起的,根结点的深度为1;结点高度是从最底层的叶子结点算起的,最底层叶子结点的高度为1。
堂兄弟:双亲在同一层的结点互为堂兄弟。如G和H互为堂兄弟,因为G的双亲是C,H的双亲是D,C和D在同一层上。注意和兄弟的概念的区分。
有序树:树中结点的子树从左到右是有次序的,不能交换,这样的.树叫作有序树。
无序树: 树中结点的子树没有顺序,可以任意交换,这样的树叫作无序树。
丰满树:丰满树即理想一平衡树,要求除最底层外,其他层都是满的。
森林: 若干棵互不相交的树的集合。例子中如果把根A去掉,剩卜的3棵子树互不相交,它们组成一个森林。
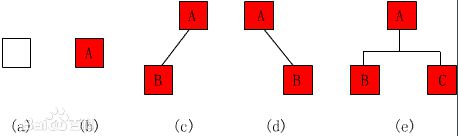
二叉树的5种基本形态
(1)空二叉树——如图(a);
(2)只有一个根结点的二叉树——如图(b);
(3)只有左子树——如图(c);
(4)只有右子树——如图(d);
(5)完全二叉树——如图(e)。
二叉树的性质:
①二叉树中,第 i 层最多有2i-1个结点。
②如果二叉树的深度为 K,那么此二叉树最多有2K-1个结点。
③二叉树中,终端结点数(叶子结点数)为 n0,度为 2 的结点数为 n2,则n0 = n2 + 1。
性质 3 的计算方法为:
对于一个二叉树来说,除了度为 0 的叶子结点和度为 2 的结点,剩下的就是度为 1 的结点(设为 n1),那么总结点n = n0 + n1 + n2。
同时,对于每一个结点来说都是由其父结点分支表示的,假设树中分枝数为 B,那么总结点数n = B + 1。而分枝数是可以通过 n1 和 n2 表示的:B = n1 + 2 * n2。
所以,n 用另外一种方式表示为:n=n1+2*n2+1。
两种方式得到的 n 值组成一个方程组,就可以得出n0 = n2 + 1。
完全二叉树特有的性质:
n 个结点的完全二叉树的深度为[log2n]+1。
[log2n]表示取小于log2n的最大整数。例如,[log24] = 2,而 [log25] 结果也是 2。
对于任意一个完全二叉树来说,将含有的结点按照层次从左到右依次标号,对于任意一个结点 i ,有以下几个结论:
当 i > 1时,父亲结点为结点 [i / 2] 。( i = 1时,表示的是根结点,无父亲结点)
如果 2*i > n ,则结点 i 肯定没有左孩子(为叶子结点);否则其左孩子是结点 2*i 。
如果 2*i +1 > n ,则结点 i 肯定没有右孩子;否则右孩子是结点 2*i +1 。
二叉树的存储结构
①顺序存储结构
借用数组将二叉树中的数据元素存储起来。此方式只适用于完全二叉树,如果想存储普通二叉树,需要将普通二叉树转化为完全二叉树。
使用数组存储完全二叉树时,从数组的起始地址开始,按层次顺序从左往右依次存储完全二叉树中的结点。当提取时,根据完全二叉树的第 2 条性质,可以将二叉树进行还原。
转化后的二叉树中,数据元素 0 表示此位置没有数据。将转化后的完全二叉树按照层次并从左到右的次序存储到数组中:

深度为 K 且只有 K 个结点的单支树(树中不存在度为 2 的结点),需要 2K-1 的数组空间,浪费存储空间。所以,顺序存储方式更适用于完全二叉树。
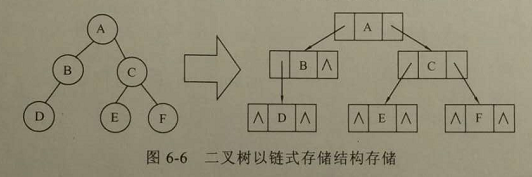
②链式存储

Lchild 代表指向左孩子的指针域;data 为数据域;Rchild 代表指向右孩子的指针域。使用此种结点构建的二叉树称为“二叉链表”
递归思想遍历二叉树
树是由根结点和子树部分构建的,对于每一棵树来说,都可以分为 3 部分:左子树、根结点和右子树。所以,可以采用递归的思想依次遍历每个结点。
根据访问结点的顺序,分为三种遍历方式:先序遍历、中序遍历、后序遍历
三种方式唯一的不同就是访问结点时机的不同,给出一个二叉树,首先需要搞清楚三种遍历方式下访问结点的顺序。
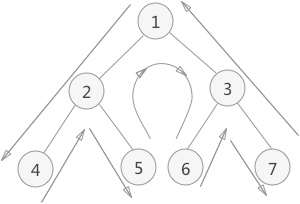
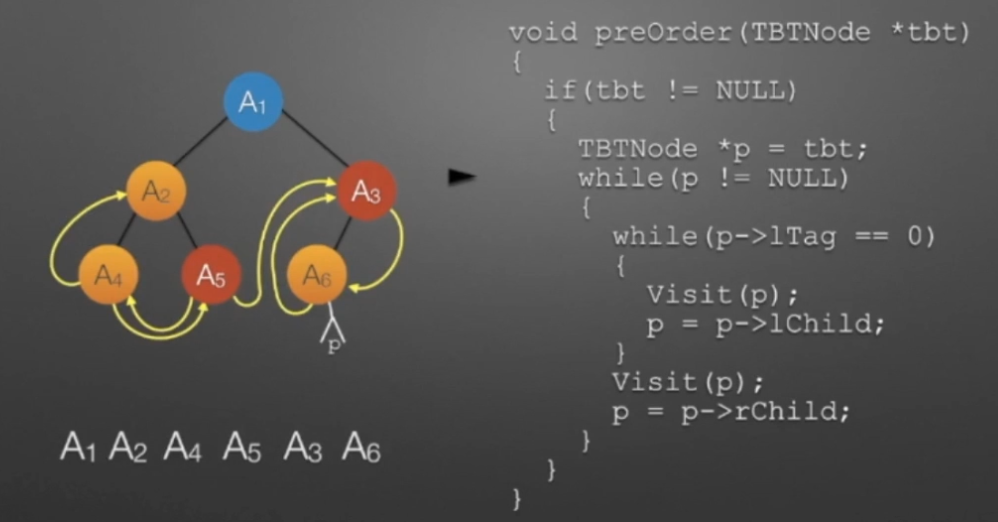
①先访问根结点,再遍历左右子树,称为“先序遍历”;
先序遍历是只要线条走到该结点的左方位置时,就操作该结点。所以操作结点的顺序为:1 2 4 5 3 6 7
//先序遍历
void preorder(BTNode *p)
{
if (p!=NULL)
{
Visit(p); //假设访问函数Visit()已经定义,其中包含了对结点p的各种访问操作,如可以打印出p对应的数值
preorder(p->lchild); //遍历左子树
preorder(p->rchild); //遍历右子树
}
}
②遍历左子树,之后访问根结点,然后遍历右子树,称为“中序遍历”;
中序遍历是当线条越过结点的左子树,到达该结点的正下方时,才操作该结点。所以操作结点的顺序为:4 2 5 1 6 3 7
//中序遍历
void inorder(BTNode *p)
{
if (p!=NULL)
{
inorder(p->lchild);
Visit(p);
inorder(p->rchild);
}
}
③遍历完左右子树,再访问根结点,称为“后序遍历”。
后序遍历是线条完全走过结点的左右子树,到达该结点的右方范围时,就开始操作该结点。所以操作结点的顺序为:4 5 2 6 7 3 1
//后序遍历
void potorder(BTNode *p)
{
if (p!=NULL)
{
potorder(p->lchild);
potorder(p->rchild);
Visit(p);
}
}
层次遍历

//层次遍历
void level (BTNode *p)
{
int front,rear;
BTNode *que[maxSize]; //①定义一个循环队列,用来记录将要访问的层次上的结点
front=rear=;
BTNode *q;
if(p=!NULL)
{
rear=(rear+)%maxSize;
que[rear]=p; //②跟结点入队
while(front!=rear) //③当队列不空的时候进行循环
{
front=(front+)%maxSize;
q=que[front]; //④队头结点出队
Visit(q); //⑤访问队头结点
if(q->lchild!=NULL) //⑥如果左子树不空,则左子树的跟结点入队
{
rear=(rear+)%maxSize;
que[rear]=q->lchild;
}
if(q->rchild!=NULL) //⑦如果右子树不空,则右子树的跟结点入队
{
rear=(rear+)%maxSize;
que[rear]=q->rchild;
}
}
}
}
非递归思想遍历二叉树
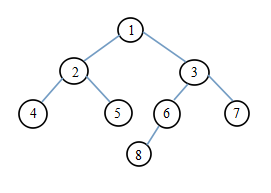
//1.先序遍历
//遍历顺序:1,2,4,5,3,6,8,7
void preorderNonrecursion(BTNode *bt)
{
if(bt!=NULL)
{
BTNode *Stack[maxSize]; //定义一个栈
int top=-; //初始化栈
BTNode *p; //定义一个遍历指针
Stack[++top]=bt; //根结点入栈
while(top!=top) //循环遍历结点
{
p=Stack[top--]; //出栈并输出栈顶结点
Visit(p); //访问p的函数
if(p->rchild!=NULL) //栈顶的右孩子存在,则右孩子入栈
Stack[++top]=p->rchild;
if(p->lchild!=NULL) //栈顶的左孩子存在,则左孩子入栈
Stack[++top]=p->lchild;
}
}
}
//2.中序遍历
//遍历顺序:4,2,5,1,8,6,3,7
void inorderNonrecursion(BTNode *bt)
{
if(bt!=NULL)
{
BTNode *Stack[maxSize];
int top=-;
BTNode *p;
p=bt; while(top!=- || p!=NULL)
{
while (p!=NULL) //左孩子存在,则左孩子入栈
{
Stack[++top]=p;
p=p->lchild;
}
if(top!=-) //在栈不空的情况下出栈并输出出栈结点
{
p=Stack[top--];
Visit(p);
p=p->rchild;
}
}
}
}
//3.后序遍历
//遍历顺序: 先序(根、左、右):1,2,4,5,3,6,8,7
// 后序(左、右、根):4,5,2,8,6,7,3,1
// 中序(根、右、左):1,3,7,6,8,2,5,4
void postorderNonrecursion(BTNode *bt)
{
if(bt!=NULL)
{
BTNode *Stack1[maxSize]; //定义辅助遍历的栈
BTNode *Stack2[maxSize]; //定义将结果逆序的栈
int top1=-;
int top2=-;
BTNode *p=NULL;
Stack1[++top1]=bt;
while(top!=-)
{
p=Stack1[top1--];
Stack2[++top2]=p; if(p->lchild!=NULL) //栈顶的左孩子存在,则左孩子入栈
Stack[++top1]=p->lchild;
if(p->rchild!=NULL) //栈顶的右孩子存在,则右孩子入栈
Stack[++top1]=p->rchild;
}
while (top2!=-) //左孩子存在,则左孩子入栈
{
p=Stack2[top2--];
Visit(p);
}
}
}
线索二叉树
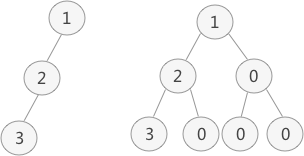
通过考察各种二叉链表,不管二叉树的形态如何,空链域的个数总是多过非空链域的个数。准确的说,n各结点的二叉链表共有2n个链域,非空链域为n-1个,但其中的空链域却有n+1个。如下图所示。
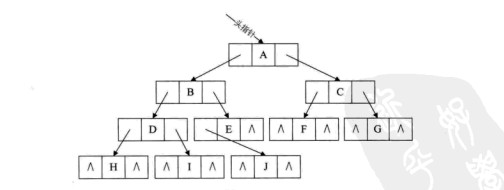
因此,提出了一种方法,利用原来的空链域存放指针,指向树中其他结点。这种指针称为线索。
记ptr指向二叉链表中的一个结点,以下是建立线索的规则:
(1)如果ptr->lchild为空,则存放指向中序遍历序列中该结点的前驱结点。这个结点称为ptr的中序前驱;
(2)如果ptr->rchild为空,则存放指向中序遍历序列中该结点的后继结点。这个结点称为ptr的中序后继;
显然,在决定lchild是指向左孩子还是前驱,rchild是指向右孩子还是后继,需要一个区分标志的。因此,我们在每个结点再增设两个标志域ltag和rtag,注意ltag和rtag只是区分0或1数字的布尔型变量,其占用内存空间要小于像lchild和rchild的指针变量。结点结构如下所示。

LTag 和 RTag 为标志域。实际上就是两个布尔类型的变量:
LTag 值为 0 时,表示 lchild 指针域指向的是该结点的左孩子;为 1 时,表示指向的是该结点的直接前趋结点;
RTag 值为 0 时,表示 rchild 指针域指向的是该结点的右孩子;为 1 时,表示指向的是该结点的直接后继结点。
所以,对于上图的二叉链表图可以修改为下图的样子。

//结构定义
typedef struct TBTNode{
char data; //数据域(结点的数据)
int Ltag,Rtag; //标志域,枚举类型
struct BiThrNode *lchild; //左孩子指针域
struct BiThrNode *rchild;
}TBTNode;
线索化的实质就是将二叉链表中的空指针改为指向前驱或后继的线索。由于前驱和后继信息只有在遍历该二叉树时才能得到,所以,线索化的过程就是在遍历的过程中修改空指针的过程。
①线索二叉树(中序)
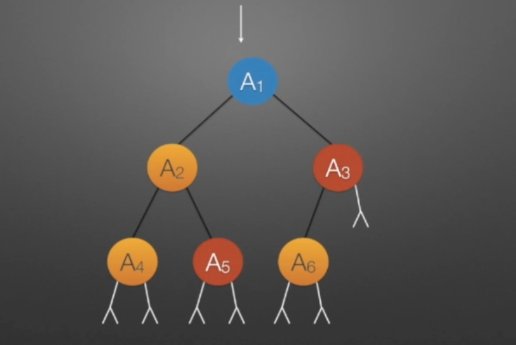
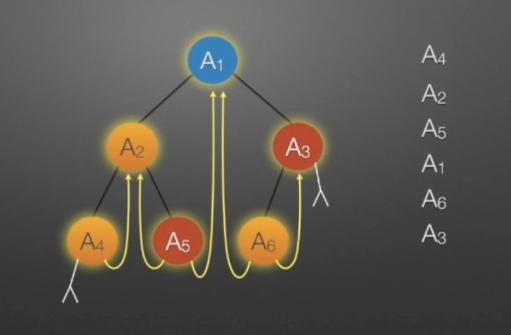
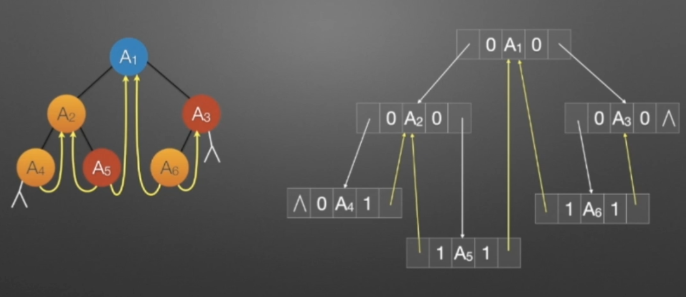
//中序遍历进行线索化
//遍历顺序:A4,A2,A5,A1,A6,A3
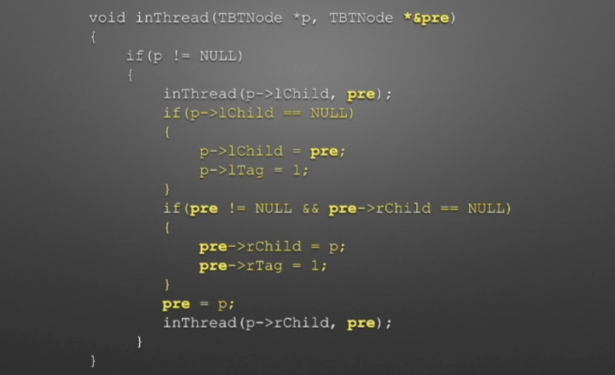
void InThread(TBTNode *p,TBTNode *&pre)
{
if(p!=NULL)
{
InThread(p->lchild,pre); //*递归,左子树线索化
if(p->lchild==NULL) //没有左孩子
{ //*建立当前结点的前驱线索
p->lchild = pre; //左孩子指针指向前驱
p->ltag = ; //前驱线索
}
if(pre->rchild==NULL && pre!=NULL) //没有右孩子
{ //*建立前驱结点的后继线索
pre->rchild = p; //前驱右孩子指针指向后继(当前结点p)
pre->rtag = ; //后继线索
}
pre = p; //pre指向当前的p,作为p将要指向的下一个结点的前驱结点指示指针
p=p->rchild; //p指向一个新结点,此时pre和p分别指向的结点形成了一个前驱后继对,为下一次线索的连接做准备
InThreading(p,pre); //递归,右子树线索化
}
}
②线索二叉树(前序)
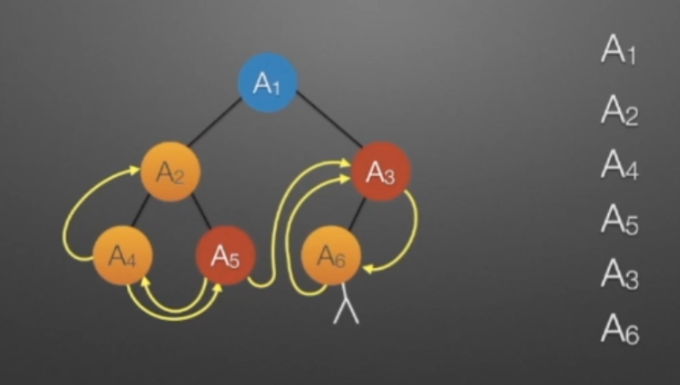
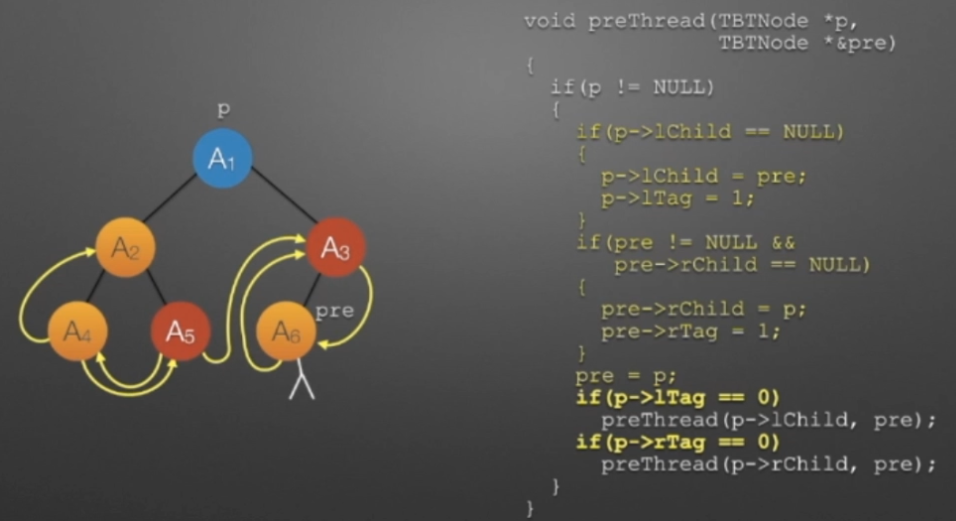
//前序遍历进行线索化
//遍历顺序:A1,A2,A4,A5,A3,A6
void preThread(TBTNode *p,TBTNode *&pre)
{
if(p!=NULL)
{
if(p->lchild==NULL) //没有左孩子
{ //*建立当前结点的前驱线索
p->lchild = pre; //左孩子指针指向前驱
p->ltag = ; //前驱线索
}
if(pre->rchild==NULL && pre!=NULL) //没有右孩子
{ //*建立前驱结点的后继线索
pre->rchild = p; //前驱右孩子指针指向后继(当前结点p)
pre->rtag = ; //后继线索
}
if(p->ltag=)
preThread(p->lchild,pre);
if(p->rtag=)
preThread(p->rchild,pre);
}
}
③线索二叉树(后序)
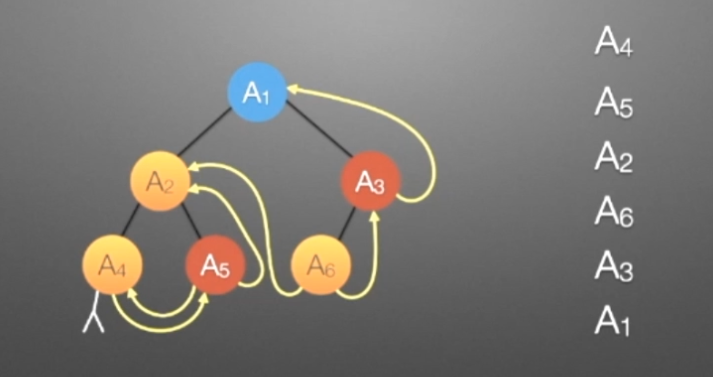
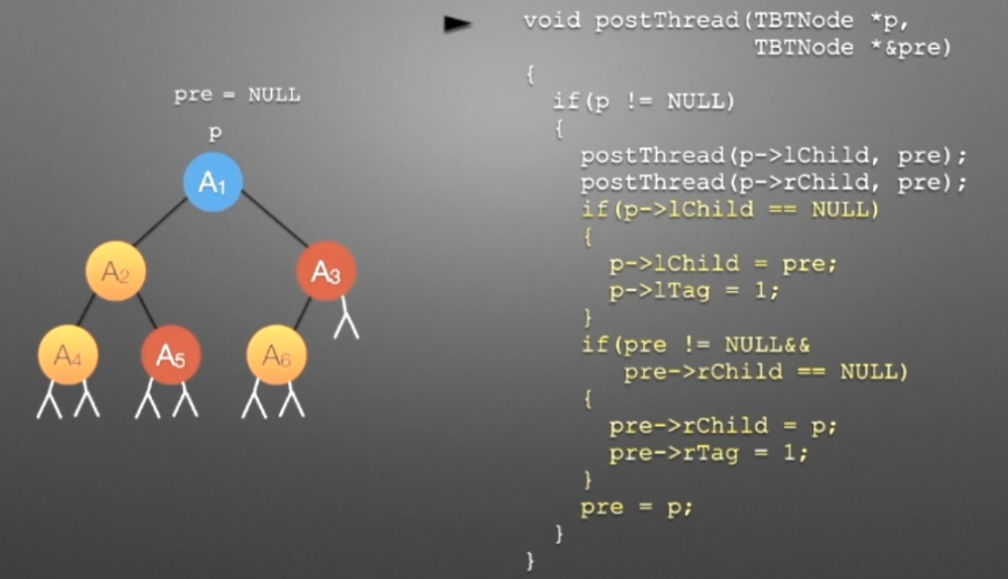
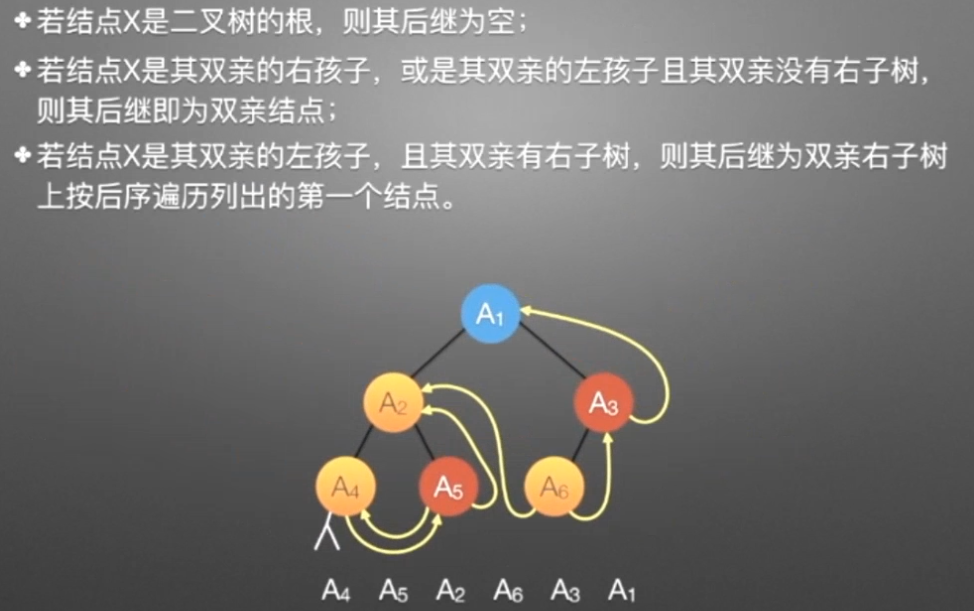
//后序遍历进行线索化
//遍历顺序:A4,A5,A2,A6,A3,A1
void postThread(TBTNode *p,TBTNode *&pre)
{
if(p!=NULL)
{
preThread(p->lchild,pre);
preThread(p->rchild,pre);
if(p->lchild==NULL) //没有左孩子
{ //*建立当前结点的前驱线索
p->lchild = pre; //左孩子指针指向前驱
p->ltag = ; //前驱线索
}
if(pre->rchild==NULL && pre!=NULL) //没有右孩子
{ //*建立前驱结点的后继线索
pre->rchild = p; //前驱右孩子指针指向后继(当前结点p)
pre->rtag = ; //后继线索
}
pre=p;
}
}

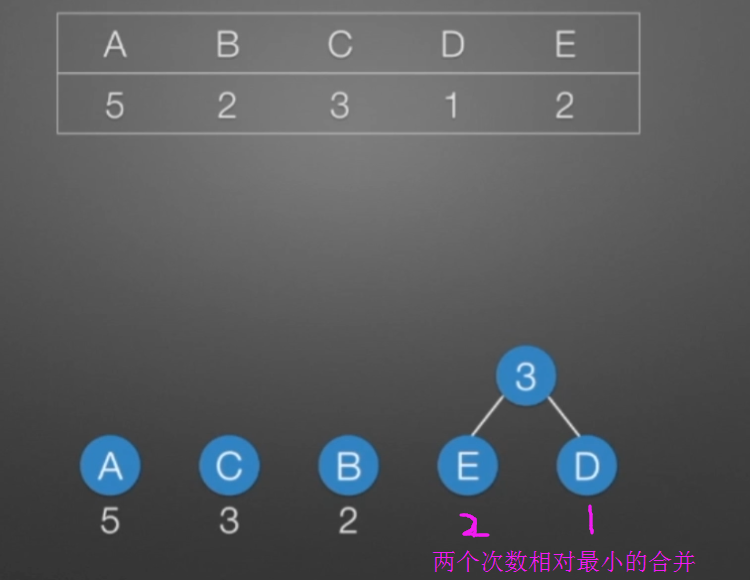
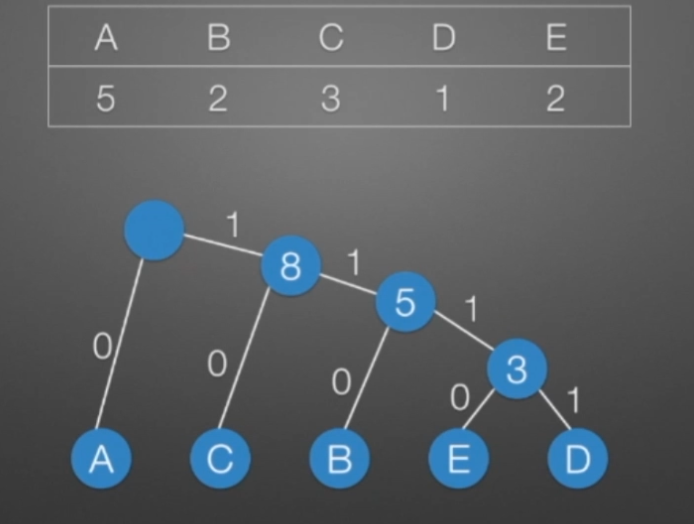
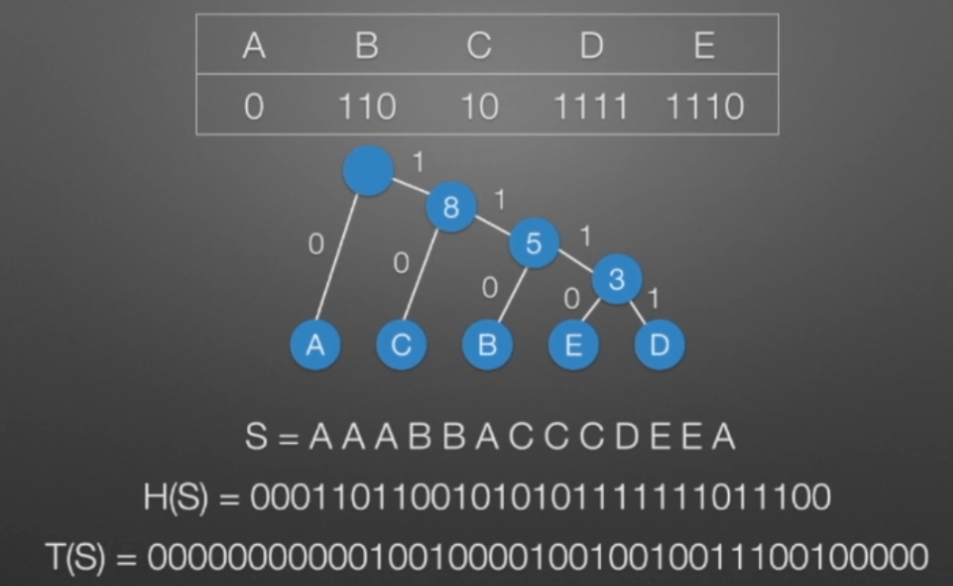
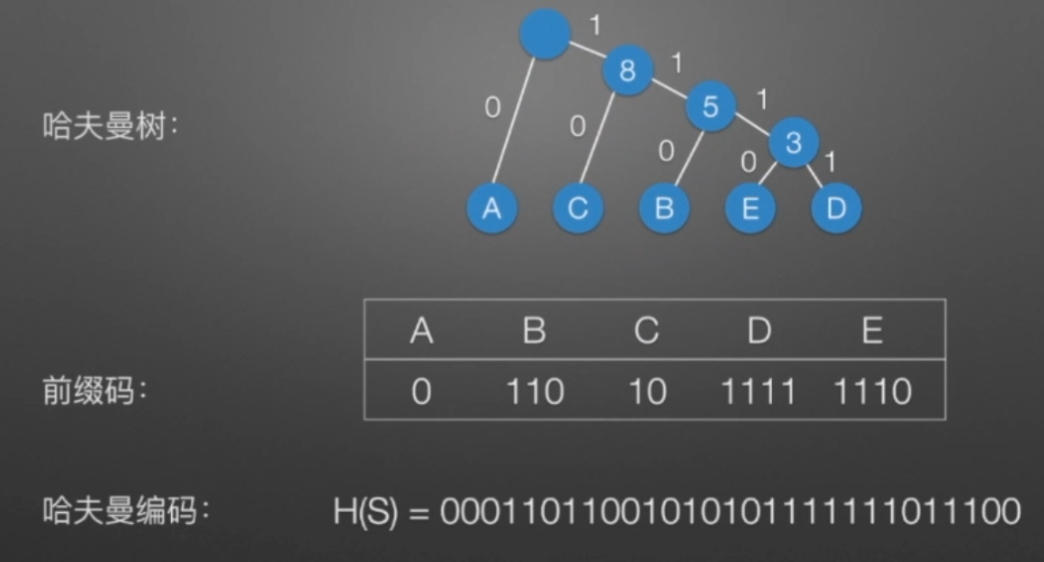
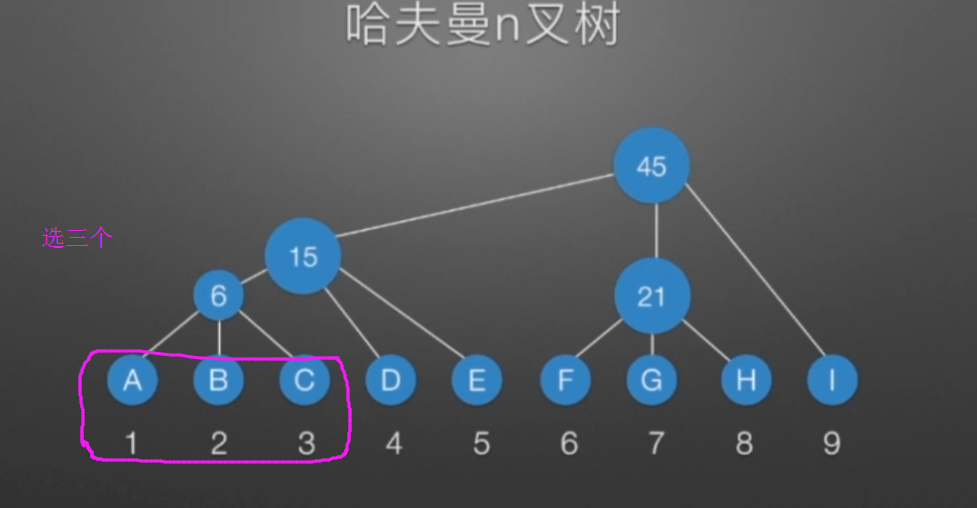
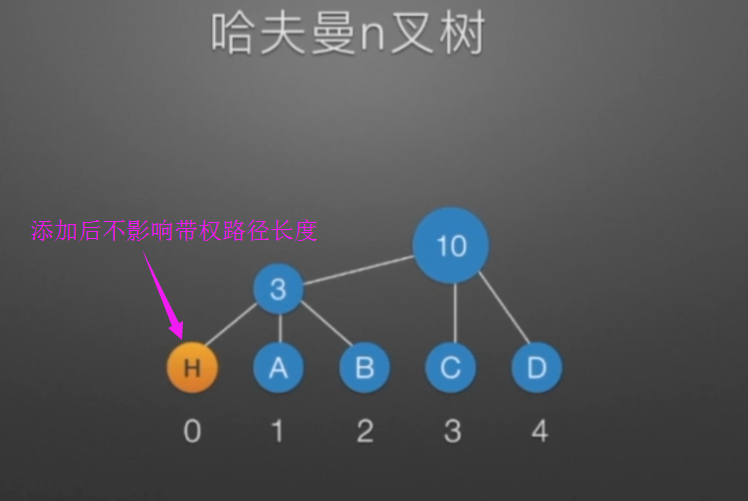
哈弗曼树和编码




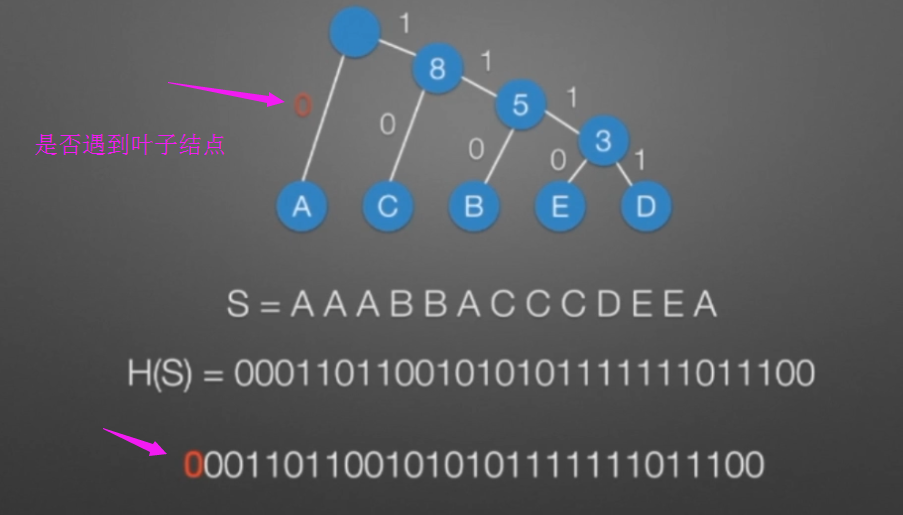
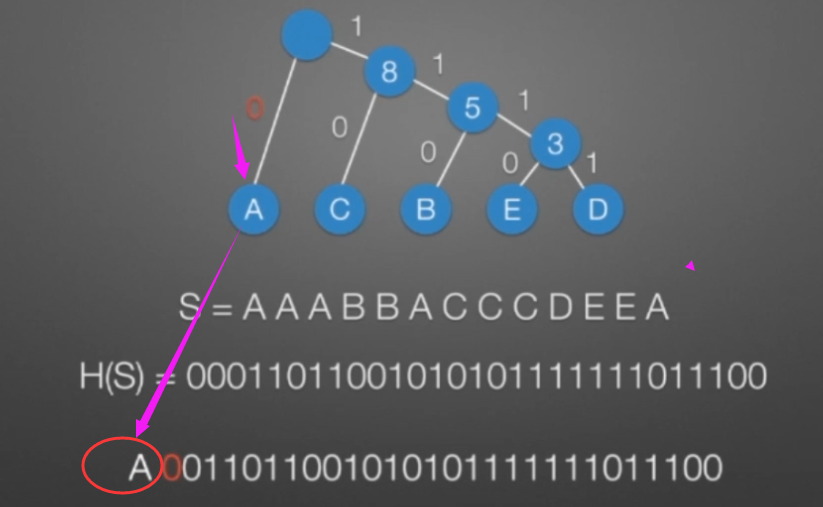
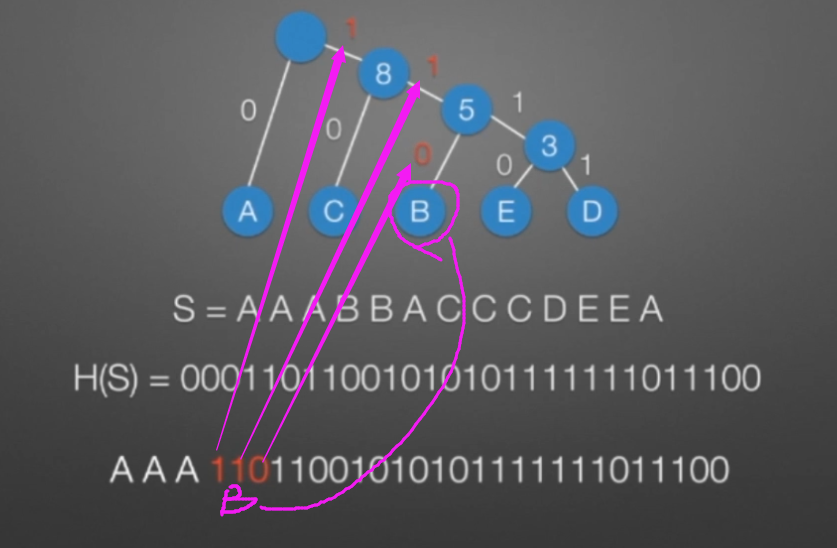
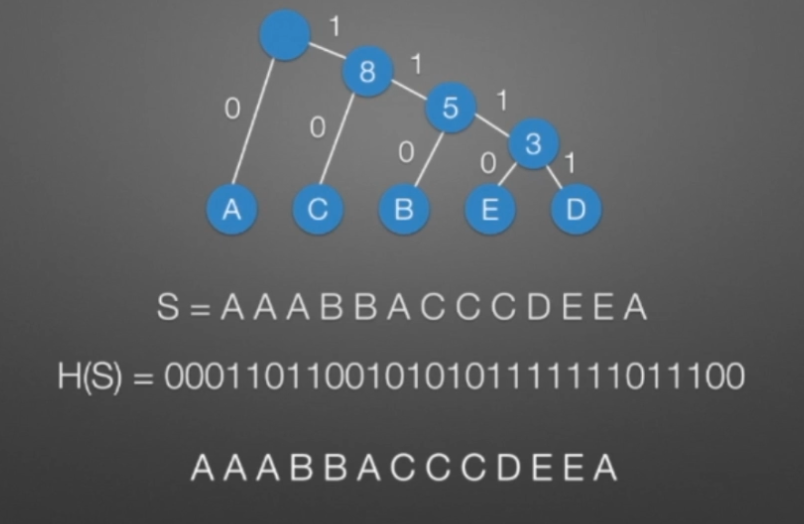


数据结构与算法(C/C++版)【树与二叉树】的更多相关文章
- 数据结构与算法系列研究五——树、二叉树、三叉树、平衡排序二叉树AVL
树.二叉树.三叉树.平衡排序二叉树AVL 一.树的定义 树是计算机算法最重要的非线性结构.树中每个数据元素至多有一个直接前驱,但可以有多个直接后继.树是一种以分支关系定义的层次结构. a.树是n ...
- Java数据结构和算法(一)树
Java数据结构和算法(一)树 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 前面讲到的链表.栈和队列都是一对一的线性结构, ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第4章 栈
定场诗 金山竹影几千秋,云索高飞水自流: 万里长江飘玉带,一轮银月滚金球. 远自湖北三千里,近到江南十六州: 美景一时观不透,天缘有分画中游. 前言 本章是重读<学习JavaScript数据结构 ...
- 重读《学习JavaScript数据结构与算法-第三版》- 第5章 队列
定场诗 马瘦毛长蹄子肥,儿子偷爹不算贼,瞎大爷娶个瞎大奶奶,老两口过了多半辈,谁也没看见谁! 前言 本章为重读<学习JavaScript数据结构与算法-第三版>的系列文章,主要讲述队列数据 ...
- Java数据结构和算法 - 什么是2-3-4树
Q1: 什么是2-3-4树? A1: 在介绍2-3-4树之前,我们先说明二叉树和多叉树的概念. 二叉树:每个节点有一个数据项,最多有两个子节点. 多叉树:(multiway tree)允许每个节点有更 ...
- java数据结构和算法07(2-3-4树)
上一篇我们大概了解了红黑树到底是个什么鬼,这篇我们可以看看另外一种树-----2-3-4树,看这个树的名字就觉得很奇怪.... 我们首先要知道这里的2.3.4指的是任意一个节点拥有的子节点个数,所以我 ...
- 数据结构与算法(九):AVL树详细讲解
数据结构与算法(一):基础简介 数据结构与算法(二):基于数组的实现ArrayList源码彻底分析 数据结构与算法(三):基于链表的实现LinkedList源码彻底分析 数据结构与算法(四):基于哈希 ...
- Java数据结构和算法(二)树的基本操作
Java数据结构和算法(二)树的基本操作 数据结构与算法目录(https://www.cnblogs.com/binarylei/p/10115867.html) 一.树的遍历 二叉树遍历分为:前序遍 ...
- 数据结构1:数据结构与算法C语言版分析概述
本节开始将带领大家系统地学习数据结构,作为一门计算机专业大二学生的必修课程,该课程面对的目标人群为初步具备基本编程能力和编程思想的程序员(大一接触了 C 语言或者 C++).通过系统地学习数据结构,可 ...
- 重读《学习JavaScript数据结构与算法-第三版》-第2章 ECMAScript与TypeScript概述
定场诗 八月中秋白露,路上行人凄凉: 小桥流水桂花香,日夜千思万想. 心中不得宁静,清早览罢文章, 十年寒苦在书房,方显才高志广. 前言 洛伊安妮·格罗纳女士所著的<学习JavaScript数据 ...
随机推荐
- 手工搭建ABP框架(1) - Web项目
为了防止不提供原网址的转载,特在这里加上原文链接: http://www.cnblogs.com/skabyy/p/7295533.html ABP是 ASP.NET Boilerplate Proj ...
- MySQL服务相关
1.管理员身份运行cmd方法: 在C:\Windows\System32\cmd.exe右键以管理员身份运行 2.查看MySQL服务选项(路径:任务管理器-服务tab-选中任一服务点击打开服务-进入服 ...
- 【机器学习实战】第13章 利用 PCA 来简化数据
第13章 利用 PCA 来简化数据 降维技术 场景 我们正通过电视观看体育比赛,在电视的显示器上有一个球. 显示器大概包含了100万像素点,而球则可能是由较少的像素点组成,例如说一千个像素点. 人们实 ...
- 《Google SRE》读后感
注:这是去年国庆时的一篇读书笔记,最近线上故障频繁,重新读了下这篇读书笔记,觉得<Google SRE>非常棒,遂从简书再搬家到博客园,希望大家受益.我的简书地址:daoqidelv 国庆 ...
- c#鼠标点击TextBox控件后清空默认字体
方案(一) 脚本: <script type="text/javascript" language="javascript"> //得 ...
- Java build path && Deployment assembly && 编译路径 && 发布路径
java build path java源文件,编译后,输出的路径,默认值为: *此时的源码文件夹在 /src deployment assembly 系统发布路径设置,将完成(或未完成)的项目对应的 ...
- cgg之数据类型
所有例子都在64为操作系统 Linux 2.6.30 x86_64 x86_64 x86_64 GNU/Linux 1.1整数 在stdint.h中定义一些看上去更明确的整数类型 #ifndef __ ...
- Altera FIFO IP核时序说明
ALTERA在LPM(library of parameterized mudules)库中提供了参数可配置的单时钟FIFO(SCFIFO)和双时钟FIFO(DCFIFO).FIFO主要应用在需要数据 ...
- Cache类缓存
此处主要总结System.Web.Caching.Cache类 该类是用于存储常用信息的类,HttpRuntime.Cache以及HttpContext.Current.Cache都是该类的实例. 该 ...
- [转]the service mysql57 failed the most recent status[/br]mysql57 was not found解决办法
转自:http://forums.mysql.com/read.php?169,622722,622877#msg-622877 安装完mysql5.7.12后想要stop或者restart都会出现以 ...