从Trie树到双数组Trie树
Trie树
原理
又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,能在常数时间O(len)内实现插入和查询操作,是一种以空间换取时间的数据结构,广泛用于词频统计和输入统计领域。
来看看Trie树长什么样,我们从百度找一张图片:
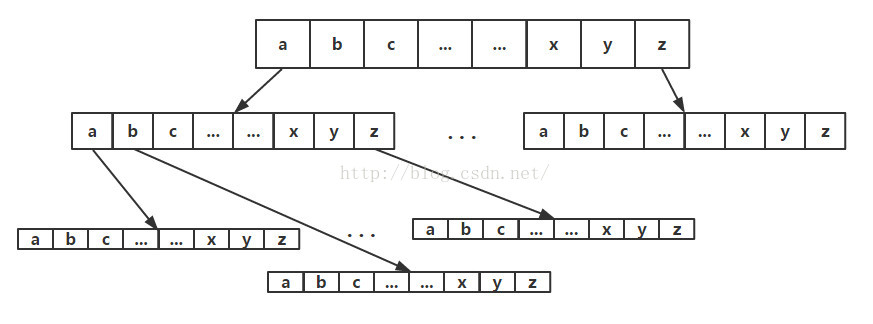
字典树在查找时,先看第一个字是否在字典树里,如果在继续往下,如果不在,则字典里不存在,因此,对于一个长度为len的字符串,可以在O(len)时间内完成查询。
实现trie树
怎么实现trie树呢,trie树的关键是一个节点要在O(1)时间跳转到下一级节点,因此链表方式不可取,最好用数组来存储下一级节点。问题就来了,如果是纯英文字母,长度26的数组就可以搞定,N个节点的数,就需要N个长度为26的数组。但是,如果包含中文等字符呢,就需要N个65535的数组,特别占用存储空间。当然,可以考虑使用map来存储下级节点。
定义一个Node,包含节点的Character word,以及下级节点nexts和节点可能附件的值values:
public static class Node<T> {
Character word;
List<T> values;
Map<Character, Node> nexts = new HashMap<>(24);
public Node() {
}
public Node(Character word) {
this.word = word;
}
public Character getWord() {
return word;
}
public void setWord(Character word) {
this.word = word;
}
public void addValue(T value){
if(values == null){
values = new ArrayList<>();
}
values.add(value);
}
public List<T> getValues() {
return values;
}
public Map<Character, Node> getNexts() {
return nexts;
}
/**
* @param node
*/
public void addNext(Node node) {
this.nexts.put(node.getWord(), node);
}
public Node getNext(Character word) {
return this.nexts.get(word);
}
}
来看如何构建字典树,首先定义一棵树,包含根节点即可
public static class Trie<T> {
Node<T> rootNode;
public Trie() {
this.rootNode = new Node<T>();
}
public Node<T> getRootNode() {
return rootNode;
}
}
构建树,拆分成单字,然后逐级构建树。
public static class TrieBuilder {
public static Trie<String> buildTrie(String... values){
Trie<String> trie = new Trie<String>();
for(String sentence : values){
// 根节点
Node<String> currentNode = trie.getRootNode();
for (int i = 0; i < sentence.length(); i++) {
Character character = sentence.charAt(i);
// 寻找首个节点
Node<String> node = currentNode.getNext(character);
if(node == null){
// 不存在,创建节点
node = new Node<String>(character);
currentNode.addNext(node);
}
currentNode = node;
}
// 添加数据
currentNode.addValue(sentence);
}
return trie;
}
Trie树应用
比如判断一个词是否在字典树里,非常简单,逐级匹配,末了判断最后的节点是否包含数据:
public boolean isContains(String word) {
if (word == null || word.length() == 0) {
return false;
}
Node<T> currentState = rootNode;
for (int i = 0; i < word.length(); i++) {
currentState = currentState.getNext(word.charAt(i));
if (currentState == null) {
return false;
}
}
return currentState.getValues()!=null;
}
测试代码:
public static void main(String[] args) {
Trie trie = TrieBuilder.buildTrie("刘德华","刘三姐","刘德刚","江姐");
System.out.println(trie.isContains("刘德华"));
System.out.println(trie.isContains("刘德"));
System.out.println(trie.isContains("刘大大"));
}
结果:
true
false
false
双数组Trie树
在Trie数实现过程中,我们发现了每个节点均需要 一个数组来存储next节点,非常占用存储空间,空间复杂度大,双数组Trie树正是解决这个问题的。双数组Trie树(DoubleArrayTrie)是一种空间复杂度低的Trie树,应用于字符区间大的语言(如中文、日文等)分词领域。
原理
双数组的原理是,将原来需要多个数组才能表示的Trie树,使用两个数据就可以存储下来,可以极大的减小空间复杂度。具体来说:
使用两个数组base和check来维护Trie树,base负责记录状态,check负责检查各个字符串是否是从同一个状态转移而来,当check[i]为负值时,表示此状态为字符串的结束。
上面的有点抽象,举个例子,假定两个单词ta,tb,base和check的值会满足下面的条件:
base[t] + a.code = base[ta]
base[t] + b.code = base[tb]
check[ta] = check[tb]
在每个节点插入的过程中会修改这两个数组,具体说来:
1、初始化root节点base[0] = 1; check[0] = 0;
2、对于每一群兄弟节点,寻找一个begin值使得check[begin + a1…an] == 0,也就是找到了n个空闲空间,a1…an是siblings中的n个节点对应的code。
3、然后将这群兄弟节点的check设为check[begin + a1…an] = begin
4、接着对每个兄弟节点,如果它没有孩子,令其base为负值;否则为该节点的子节点的插入位置(也就是begin值),同时插入子节点(迭代跳转到步骤2)。
码表:
胶 名 动 知 下 成 举 一 能 天 万
33014 21517 21160 30693 19979 25104 20030 19968 33021 22825 19975
DoubleArrayTrie{
char = × 一 万 × 举 × 动 × 下 名 × 知 × × 能 一 天 成 胶
i = 0 19970 19977 20032 20033 21162 21164 21519 21520 21522 30695 30699 33023 33024 33028 40001 44345 45137 66038
base = 1 2 6 -1 20032 -2 21162 -3 5 21519 -4 30695 -5 -6 33023 3 1540 4 33024
check= 0 1 1 20032 2 21162 3 21519 1540 4 30695 5 33023 33024 6 20032 21519 20032 33023
size=66039, allocSize=2097152, key=[一举, 一举一动, 一举成名, 一举成名天下知, 万能, 万能胶], keySize=6, progress=6, nextCheckPos=33024, error_=0}
首层:一[19968],万[ 19975]
base[一] = base[0]+19968-19968 = 1
base[万] = base[0]+19975-19968 =
实现
参考 双数组Trie树(DoubleArrayTrie)Java实现
开源项目:https://github.com/komiya-atsushi/darts-java
双数组Trie+AC自动机
参见:http://www.hankcs.com/program/algorithm/aho-corasick-double-array-trie.html
结合了AC自动机+双数组Trie树:
AC自动机能高速完成多模式匹配,然而具体实现聪明与否决定最终性能高低。大部分实现都是一个Map<Character, State>了事,无论是TreeMap的对数复杂度,还是HashMap的巨额空间复杂度与哈希函数的性能消耗,都会降低整体性能。
双数组Trie树能高速O(n)完成单串匹配,并且内存消耗可控,然而软肋在于多模式匹配,如果要匹配多个模式串,必须先实现前缀查询,然后频繁截取文本后缀才可多匹配,这样一份文本要回退扫描多遍,性能极低。
如果能用双数组Trie树表达AC自动机,就能集合两者的优点,得到一种近乎完美的数据结构。在我的Java实现中,我称其为AhoCorasickDoubleArrayTrie,支持泛型和持久化,自己非常喜爱。
作者:Jadepeng
出处:jqpeng的技术记事本--http://www.cnblogs.com/xiaoqi
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
从Trie树到双数组Trie树的更多相关文章
- python Trie树和双数组TRIE树的实现. 拥有3个功能:插入,删除,给前缀智能找到所有能匹配的单词
#coding=utf- #字典嵌套牛逼,别人写的,这样每一层非常多的东西,搜索就快了,树高26.所以整体搜索一个不关多大的单词表 #还是O(). ''' Python 字典 setdefault() ...
- 中文分词系列(一) 双数组Tire树(DART)详解
1 双数组Tire树简介 双数组Tire树是Tire树的升级版,Tire取自英文Retrieval中的一部分,即检索树,又称作字典树或者键树.下面简单介绍一下Tire树. 1.1 Tire树 Trie ...
- [转]双数组TRIE树原理
原文名称: An Efficient Digital Search Algorithm by Using a Double-Array Structure 作者: JUN-ICHI AOE 译文: 使 ...
- 双数组Trie树 (Double-array Trie) 及其应用
双数组Trie树(Double-array Trie, DAT)是由三个日本人提出的一种Trie树的高效实现 [1],兼顾了查询效率与空间存储.Ansj便是用DAT(虽然作者宣称是三数组Trie树,但 ...
- Ansj分词双数组Trie树实现与arrays.dic词典格式
http://www.hankcs.com/nlp/ansj-word-pairs-array-tire-tree-achieved-with-arrays-dic-dictionary-format ...
- 双数组trie树的基本构造及简单优化
一 基本构造 Trie树是搜索树的一种,来自英文单词"Retrieval"的简写,可以建立有效的数据检索组织结构,是中文匹配分词算法中词典的一种常见实现.它本质上是一个确定的有限状 ...
- 双数组Trie树(DoubleArrayTrie)Java实现
http://www.hankcs.com/program/java/%E5%8F%8C%E6%95%B0%E7%BB%84trie%E6%A0%91doublearraytriejava%E5%AE ...
- 双数组字典树(Double Array Trie)
参考文献 1.双数组字典树(DATrie)详解及实现 2.小白详解Trie树 3.论文<基于双数组Trie树算法的字典改进和实现> DAT的基本内容介绍这里就不展开说了,从Trie过来的同 ...
- 双数组Trie树中叶子结点check[t]=t的证明
双数组Trie树,其实就是用两个一维数组来表示Trie树这种数据结构. 一个数组称为BASE,另一个数组为CHECK.转移条件如下: 对于状态s,接收字符c,转移到状态t BASE[s]+c=t CH ...
随机推荐
- C#实现DirectShow技术开发准备
DirectShow组件在“C:\WINDOWS\system32”目录下的Quartz.dll动态库中,要使C#代码引用COM对象和接口,必须将COM类型库转换为.NET框架元数据,从而有效地创建一 ...
- Error parsing HTTP request header Note: further occurrences of HTTP header parsing errors...java.lang.IllegalArgumentException: Invalid character found in the request target. The valid characters are
先将异常信息贴出: 该问题是tomcat进行http request解析的时候报的错,网上的解决办法主要是修改Tomcat的server.xml,在<Connector port="8 ...
- MarkdownPad2使用高亮插件
MarkdownPad 2有插入代码块的功能,但样式却不尽人意,但又不想换个编辑器,找了挺多相关资料,最后在MarkdownPad 2集成prettify高亮插件. 如下相关资料: [HTML] Pr ...
- Android Oreo 8.0 新特性实战 Autosizing TextView --自动缩放TextView
Android Oreo 8.0 新特性实战 Autosizing TextView --自动缩放TextView 8.0出来很久了,这个新特性已经用了很久了,但是一直没有亲自去试试.这几天新的需求来 ...
- robotframework自动化系列:删除操作流程以及总结
之前已经完成了登录.新增和修改的操作流程,这一节主要说明删除操作流程以及自动化的过程中出现的问题,算是对这个项目自动化的一个总结. 删除操作流程 对于系统账号管理中删除功能,删除的测试点主要如图所示 ...
- Adobe阅读器漏洞(adobe_cooltype_sing)学习研究
实验环境:Kali 2.0+Windows XP sp3+Adobe Reader 9.0.0 类别:缓冲区溢出 描述:这个漏洞针对Adobe阅读器9.3.4之前的版本,一个名为SING表对象中一个名 ...
- SpringMVC 快速入门
SpringMVC 快速入门 SpringMVC 简介 SpringMVC是 Spring为展示层提供的基于Web MVC设计模式的请求驱动类型的轻量级Web框架,它的功能和Struts2一样.但比S ...
- unity3d开发环境配置
1. 首先先下载软件包:http://pan.baidu.com/s/1imYVv 4.2版本2.下载完后,解压会看到两个文件(运行第二个安装包) 3.准备安装,这里直接上图了. 这里全选,里面包括 ...
- 手动编译 Nginx 并安装 VeryNginx
VeryNginx 是个非常有意思且便捷的 Nginx 扩展程序.最近新开了台 VPS,便想体验一下它带来的快感. VeryNginx 有个不超过 5 行的安装方法,但作为强迫症我更喜欢使用自己编译的 ...
- uva 1418 - WonderTeam
题意:你n支球队进行比赛,每两支队伍之间进行2场比赛,胜得3分,平得1分,输得0分,比赛后挑选出一个梦之队,要求进球总数最多,胜利场数最多,失球总数最少,并且三种都不能与其它对比列第一.问说梦之队的最 ...