【SqlServer系列】聚合函数
1 概述
本篇文章简要回顾SQL Server 聚合函数,MAX,MIN,SUM,AVG,SUM,CHECKSUM_EGG,COUNT,STDEV,STDEVP,VAR,VARP。
2 具体内容
2.1 AVG (Transact-SQL)
返回组中值的平均值。空值被忽略。
2.1.1 定义
AVG ( [ ALL | DISTINCT ] expression )
OVER ( [ partition_by_clause ] order_by_clause )
2.1.2 参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定仅对值的每个唯一实例执行AVG,而不管该值发生多少次。
表达式
是位数据类型除外的精确数字或近似数值数据类型类别的表达式。不允许使用聚合函数和子查询。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。
2.1.3 返回类型
返回类型由表达式的评估结果的类型决定。

2.1.4 小结
a.If the data type of expression is an alias data type, the return type is also of the alias data type. However, if the base data type of the alias data type is promoted, for example from tinyint to int, the return value is of the promoted data type and not the alias data type.
译文:如果表达式的数据类型是别名数据类型,则返回类型也是别名数据类型。但是,如果别名数据类型的基本数据类型被提升,例如从tinyint到int,则返回值是升级数据类型,而不是别名数据类型。
b.AVG () computes the average of a set of values by dividing the sum of those values by the count of nonnull values. If the sum exceeds the maximum value for the data type of the return value an error will be returned.
译文:AVG()通过将这些值的总和除以非空值的计数来计算一组值的平均值。如果sum超过返回值的数据类型的最大值,则返回错误。
c.AVG is a deterministic function when used without the OVER and ORDER BY clauses. It is nondeterministic when specified with the OVER and ORDER BY clauses. For more information, see Deterministic and Nondeterministic Functions.
译文:当没有OVER和ORDER BY子句时,AVG是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.2 CHECKSUM_EGG
返回组中值的校验和。空值被忽略。可以跟随OVER子句。
2.2.1 定义
CHECKSUM_AGG ( [ ALL | DISTINCT ] expression )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定CHECKSUM_AGG返回唯一值的校验和。
expression
是一个整数表达式。不允许使用聚合函数和子查询。
返回类型
将所有表达式值的校验和返回为int。
2.2.2 小结
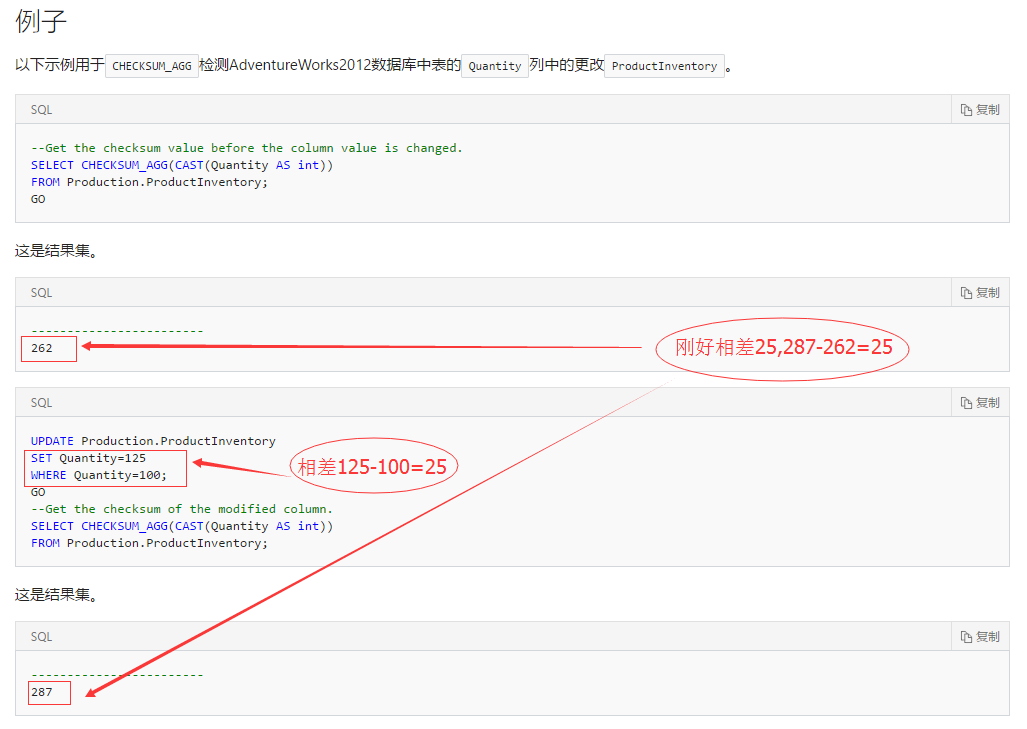
a.CHECKSUM_AGG可用于检测表中的更改。
b.表中行的顺序不影响CHECKSUM_AGG的结果。此外,CHECKSUM_AGG函数可以与DISTINCT关键字和GROUP BY子句一起使用。
b.如果表达式列表中的其中一个值更改,则列表的校验和也通常会更改。但是,校验和几乎不会改变。
d.CHECKSUM_AGG具有与其他聚合函数类似的功能。有关更多信息,请参阅聚合函数(Transact-SQL)。
2.2.3 例子
2.3 COUNT
返回组中的项目数。COUNT的作用类似于COUNT_BIG的功能。两个函数之间的唯一区别是它们的返回值。COUNT始终返回一个int数据类型值。COUNT_BIG总是返回一个bigint数据类型的值。
2.3.1 定义
-- Syntax for SQL Server and Azure SQL Database
COUNT ( { [ [ ALL | DISTINCT ] expression ] | * } )
[ OVER (
[ partition_by_clause ]
[ order_by_clause ]
[ ROW_or_RANGE_clause ]
) ]
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定COUNT返回唯一非空值的数量。
expression
是除text,image或ntext之外的任何类型的表达式。不允许使用聚合函数和子查询。
*
指定应计算所有行以返回表中的总行数。COUNT(*)不带参数,不能与DISTINCT一起使用。COUNT(*)不需要表达式参数,因为根据定义,它不使用有关任何特定列的信息。COUNT(*)返回指定表中的行数,而不会摆脱重复。它分别计算每一行。这包括包含空值的行。
OVER ( [ partition_by_clause ] [ order_by_clause ] [ ROW_or_RANGE_clause ] )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
INT
2.3.2 小结
COUNT(*)返回组中的项目数。这包括NULL值和重复。
COUNT(ALL 表达式)计算组中每一行的表达式,并返回非空值的数量。
COUNT(DISTINCT 表达式)计算组中每一行的表达式,并返回唯一的非空值。
对于大于2 ^ 31-1的返回值,COUNT会产生错误。改用COUNT_BIG。
在没有OVER和ORDER BY子句的情况下使用COUNT是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.4 COUNT_BIGG
返回组中的项目数。COUNT_BIG的作用类似于COUNT功能。两个函数之间的唯一区别是它们的返回值。COUNT_BIG总是返回一个bigint数据类型的值。COUNT始终返回一个int数据类型值。
2.5 GROUPING
指示GROUP BY列表中指定的列表达式是否聚合。GROUPING返回1为聚合,0为未聚合的结果集。在指定GROUP BY时,GROUPING只能在SELECT <select>列表,HAVING和ORDER BY子句中使用。
2.5.1 定义
GROUPING ( <column_expression> )
参数
<column_expression>
是包含GROUP BY子句中的列的列或表达式。
返回类型
TINYINT
2.5.2 小结
GROUPING用于区分ROLLUP,CUBE或GROUPING SETS从标准空值返回的空值。作为ROLLUP,CUBE或GROUPING SETS操作的结果返回的NULL是NULL的特殊用途。这作为结果集中的列占位符,意味着全部。
2.6 GROUPING_ID
是计算分组级别的函数。当指定GROUP BY时,GROUPING_ID只能在SELECT <select>列表,HAVING或ORDER BY子句中使用。
2.6.1 定义
GROUPING_ID ( <column_expression>[ ,...n ] )
参数
<column_expression>
是一个column_expression在GROUP BY子句。
返回类型
INT
2.6.2 小结
GROUPING_ID <column_expression>必须与GROUP BY列表中的表达式完全匹配。例如,如果您按DATEPART(yyyy,< column name >)进行分组,请使用GROUPING_ID(DATEPART(yyyy,< column name >)); 或者如果您使用< column name > 进行分组,请使用GROUPING_ID(< column name >)。
2.7 MAX
2.7.1 定义
-- Syntax for SQL Server and Azure SQL Database MAX ( [ ALL | DISTINCT ] expression )
OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。DISTINCT对MAX无效,仅适用于ISO兼容性。
表达式
是常量,列名称或函数,以及算术,按位和字符串运算符的任意组合。MAX可以与数字,字符,唯一标识符和datetime列一起使用,但不能与位列一起使用。不允许使用聚合函数和子查询。
有关更多信息,请参阅表达式(Transact-SQL)。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
返回与表达式相同的值。
2.7.2 小结
MAX忽略任何空值。
对于字符列,MAX找到整理顺序中的最高值。
使用时,MAX不是OVER和ORDER BY子句的确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.8 MIN
返回表达式中的最小值。可能之后是OVER子句。
2.8.1定义:
-- Syntax for SQL Server and Azure SQL Database MIN ( [ ALL | DISTINCT ] expression )
OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将聚合函数应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。DISTINCT对MIN无效,仅适用于ISO兼容性。
表达式
是常量,列名称或函数,以及算术,按位和字符串运算符的任意组合。MIN可以与numeric,char,varchar,uniqueidentifier或datetime列一起使用,但不能与位列一起使用。不允许使用聚合函数和子查询。
有关更多信息,请参阅表达式(Transact-SQL)。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
返回与表达式相同的值。
2.8.2 小结
MIN忽略任何空值。
使用字符数据列,MIN找到排序顺序中最低的值。
在不使用OVER和ORDER BY子句的情况下,MIN是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.9 STDEV
返回指定表达式中所有值的统计标准偏差。
2.9.1 定义
-- Syntax for SQL Server and Azure SQL Database STDEV ( [ ALL | DISTINCT ] expression )
OVER ( [ partition_by_clause ] order_by_clause )
参数
ALL
将该功能应用于所有值。ALL是默认值。
DISTINCT
指定每个唯一值被考虑。
expression
是一个数字表达式。不允许使用聚合函数和子查询。表达式是精确的数字或近似数字数据类型类别的表达式,除了位数据类型。
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause将FROM子句生成的结果集划分为应用该函数的分区。如果未指定,则该函数将查询结果集的所有行视为单个组。order_by_clause确定执行操作的逻辑顺序。order_by_clause是必需的。有关更多信息,请参阅OVER子句(Transact-SQL)。
返回类型
浮点
2.9.2 小结
如果STDEV用于SELECT语句中的所有项目,则结果集中的每个值都包含在计算中。STDEV只能用于数字列。空值被忽略。
当没有OVER和ORDER BY子句时,STDEV是一个确定性函数。当用OVER和ORDER BY子句指定时,它是非确定性的。有关更多信息,请参阅确定性和非确定性函数。
2.10 STDEP
返回指定表达式中所有值的总体统计标准偏差。
2.11 SUM
求和
2.12 VAR
返回指定表达式中所有值的统计方差。可能之后是OVER子句。
2.13 VARP
返回指定表达式中所有值的总体统计方差。
3 参考文献
【01】https://msdn.microsoft.com/zh-cn/library
【02】https://docs.microsoft.com/zh-cn/sql/t-sql/functions/functions
4 版权
- 感谢您的阅读,若有不足之处,欢迎指教,共同学习、共同进步。
- 博主网址:http://www.cnblogs.com/wangjiming/。
- 极少部分文章利用读书、参考、引用、抄袭、复制和粘贴等多种方式整合而成的,大部分为原创。
- 如您喜欢,麻烦推荐一下;如您有新想法,欢迎提出,邮箱:2016177728@qq.com。
- 可以转载该博客,但必须著名博客来源。
【SqlServer系列】聚合函数的更多相关文章
- SQLServer 之 聚合函数
一.聚合函数介绍 1.聚合函数最常用的: (1) COUNT:求个数 count函数用于计算满足条件的数据项数,返回int数据类型的值. [1] 语法结构:COUNT( {[[ all | disti ...
- sqlserver的over开窗函数(与排名函数或聚合函数一起使用)
首先初始化表和数据 create table t_student( Id INT, Name varchar(), Score int, ClassId INT ); insert i ...
- 微软BI 之SSAS 系列 - 多维数据集中度量值设计时的聚合函数 (累加性_半累加性和非累加性)
在 SSAS 系列 - 实现第一个 Cube 以及角色扮演维度,度量值格式化和计算成员的创建 中主要是通过已存在的维度和事实数据创建了一个多维数据集,并同时解释了 Role-Playing Dimen ...
- SQL Server温故系列(4):SQL 查询之集合运算 & 聚合函数
1.集合运算 1.1.并集运算 UNION 1.2.差集运算 EXCEPT 1.3.交集运算 INTERSECT 1.4.集合运算小结 2.聚合函数 2.1.求行数函数 COUNT 2.2.求和函数 ...
- Spark 系列(十一)—— Spark SQL 聚合函数 Aggregations
一.简单聚合 1.1 数据准备 // 需要导入 spark sql 内置的函数包 import org.apache.spark.sql.functions._ val spark = SparkSe ...
- 【T-SQL系列】常用函数—聚合函数
聚合函数平均值AVG.标准偏差STDEV.方差VAR.最大值MAX.最小值MIN.合计SUM.次数COUNT.极差值MAX-MIN.变异系数STDEV/AVG*100 什么是统计统计 就是通过样本特性 ...
- sqlserver中的聚合函数
聚合函数:就是按照一定的规则将多行(Row)数据汇总成一行的函数,对数据进行汇总前,还可以按特定的列(coloumn)将数据进行分组(group by)再汇总,然后按照再次给定的条件进行筛选 一:Co ...
- Sqlserver 系列(一):常用函数
(1)聚合函数 sum,max,min,avg,count (2)日期函数 datediff ,dateadd, datepart,getdate,month,day (3)字符串函数 ltrim,r ...
- SqlServer聚合函数
聚合函数对一组值计算后返回单个值.除了count(统计项数)函数以外,其他的聚合函数在计算式都会忽略空值(null).所有的聚合函数均为确定性函数.即任何时候使用一组相同的输入值调用聚合函数执行后的返 ...
随机推荐
- PHP面试随笔
1.常见的HTTP状态码: 1xx系列:代表请求已被接受,需要继续处理 2xx系列:代表请求已成功被服务器接收.理解并接受 200:表示请求已成功,请求所希望的响应头或数据体将随此响应返回 201:表 ...
- Scrum Meeting Alpha - 1 (团队任务分解)
团队任务分解 Alpha阶段项目目标 实现一个博客园班级博客的Android 客户端: 实现班级博客的常用功能(不包括投票.公告.校区) 有一个较为简洁美观.操作方便的界面 添加消息提醒功能. 任务拆 ...
- Spring Boot单元测试(Mock)
Spring Boot单元测试(Mock) Java个人学习心得 2017-08-12 16:07 Mock 单元测试的重要性就不多说了,我这边的工程一般都是Spring Boot+Mybatis(详 ...
- mac下selenium+python环境搭建
selenium2+python的环境搭建主要需要python和selenium 1.python mac下自带了python,可以查看版本.当然可以选择安装其它版本的python. 2.seleni ...
- 《天书夜读:从汇编语言到windows内核编程》一 汇编指令与C语言
1. Debug模式下,VC++6.0下断点运行,按CTRL+F11可查看汇编代码:另外可以用cl /c /FAs YourCppFile.cpp命令行在同目录生成YourCppFile.asm汇编文 ...
- django之第二天
今天学习目标: 一,路由系统 1,默认处理函数 2,动态URL 3,分级匹配 4,反射实现动态路由 二.中间件 三.Model(重点) 1,创建表 2,操作表数据 四.Form (重点) 1,用户提交 ...
- JS中JSON对象的定义和取值
1.JSON(JavaScript Object Notation)一种简单的数据格式,比xml更轻巧.JSON是JavaScript原生格式,这意味着在JavaScript中处理JSON数据不需要任 ...
- SSM框架开发web项目系列(一) 环境搭建篇
前言 开发环境:Eclipse Mars + Maven + JDK 1.7 + Tomcat 7 + MySQL 主要框架:Spring + Spring MVC + Mybatis 目的:快速上手 ...
- C语言之二分猜数字游戏
#include <stdio.h>#include <windows.h>#include<string.h>int main() { int oldprice, ...
- 【原创】用python写的一个监测本地进程CPU占用的程序
#coding=utf-8import psutilimport sysimport timetry:#输入需要监测的进程PID PID = raw_input('ProcessPID: ') def ...