Python爬虫通过替换http request header来欺骗浏览器实现登录
以豆瓣为例,访问https://www.douban.com/contacts/list 来查看自己关注的人,要登录才能查看。
如果用requests.get()方法获取这个http,没登录只能抓取回一个登录界面,所以我们要用Python登录网站才能抓取想要的网页。
一个简便的方法就是自己在浏览器上登录好,然后通过下图方法(Chrome为例),找到自己的Cookie和User-Agent,然后发送request时用这复制来的header替换掉待发送的request以达到登录的目的,server端会凭这个认为你是已经登录的用户。
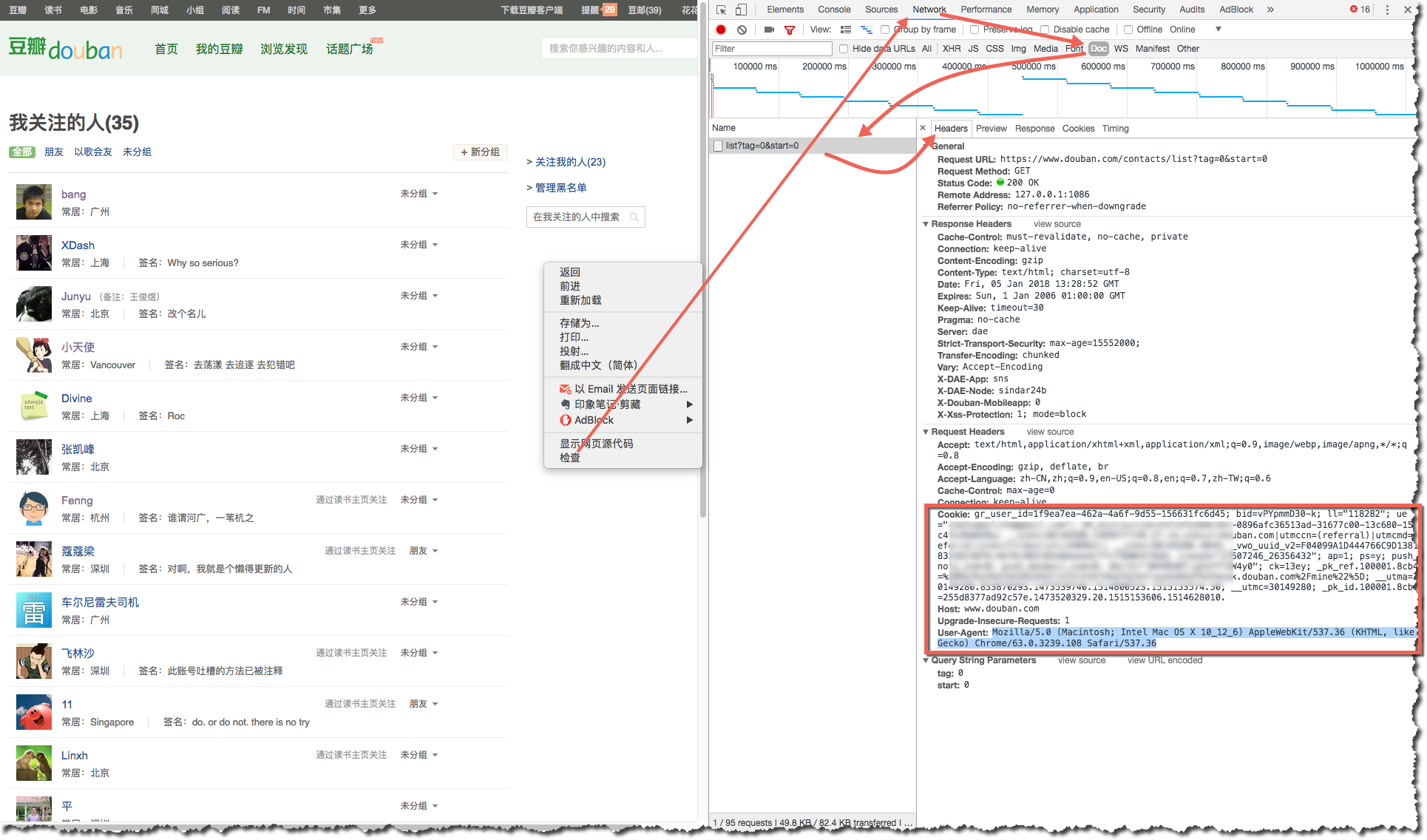
代码如下:
import requests
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.108 Safari/537.36',
'Cookie':'gr_user_id=1f9ea7ea-462a-4a6f-9d55-156631fc6d45; bid=vPYpmmD30-k; ll="118282"; ue="codin; __utmz=30149280.1499577720.27.14.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/doulist/240962/; __utmv=30149280.3049; _vwo_uuid_v2=F04099A9dd; viewed="27607246_26356432"; ap=1; ps=y; push_noty_num=0; push_doumail_num=0; dbcl2="30496987:gZxPfTZW4y0"; ck=13ey; _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1515153574%2C%22https%3A%2F%2Fbook.douban.com%2Fmine%22%5D; __utma=30149280.833870293.1473539740.1514800523.1515153574.50; __utmc=30149280; _pk_id.100001.8cb4=255d8377ad92c57e.1473520329.20.1515153606.1514628010.'
} #替换成自己的cookie
r = requests.get('https://www.douban.com/contacts/list', headers = headers)
print(r.text)
Python爬虫通过替换http request header来欺骗浏览器实现登录的更多相关文章
- python爬虫入门01:教你在 Chrome 浏览器轻松抓包
通过 python爬虫入门:什么是爬虫,怎么玩爬虫? 我们知道了什么是爬虫 也知道了爬虫的具体流程 那么在我们要对某个网站进行爬取的时候 要对其数据进行分析 就要知道应该怎么请求 就要知道获取的数据是 ...
- Python爬虫 【requests】request for humans
安装 pip install requests 源码 git clone git://github.com/kennethreitz/requests.git 导入 import requests 发 ...
- Python 爬虫js加密破解(四) 360云盘登录password加密
登录链接:https://yunpan.360.cn/mindex/login 这是一个md5 加密算法,直接使用 md5加密即可实现 本文讲解的是如何抠出js,运行代码 第一部:抓包 如图 第二步: ...
- python爬虫04 | 长江后浪推前浪,Reuqests库把urllib库拍在沙滩上
最近 有些朋友 看完小帅b的文章之后 把小帅b的表情包都偷了 还在我的微信 疯狂发表情包嘚瑟 我就呵呵了 只能说一句 盘他 还有一些朋友 看完文章不点好看 还来催更 小帅b也只能说一句 继续盘他 ...
- Python爬虫教程-06-爬虫实现百度翻译(requests)
使用python爬虫实现百度翻译(requests) python爬虫 上一篇介绍了怎么使用浏览器的[开发者工具]获取请求的[地址.状态.参数]以及使用python爬虫实现百度翻译功能[urllib] ...
- python爬虫入门02:教你通过 Fiddler 进行手机抓包
哟~哟~哟~ hi起来 everybody 今天要说说怎么在我们的手机抓包 通过 python爬虫入门01:教你在Chrome浏览器轻松抓包 我们知道了 HTTP 的请求方式 以及在 Chrome 中 ...
- python爬虫10 | 网站维护人员:真的求求你们了,不要再来爬取了!!
今天 小帅b想给大家讲一个小明的小故事 ... 话说 在很久很久以前 小明不小心发现了一个叫做 学习python的正确姿势 的公众号 从此一发不可收拾 看到什么网站都想爬取 有一天 小明发现了一个小黄 ...
- python爬虫如何POST request payload形式的请求
python爬虫如何POST request payload形式的请求1. 背景最近在爬取某个站点时,发现在POST数据时,使用的数据格式是request payload,有别于之前常见的 POST数 ...
- (转)python爬虫----(scrapy框架提高(1),自定义Request爬取)
摘要 之前一直使用默认的parse入口,以及SgmlLinkExtractor自动抓取url.但是一般使用的时候都是需要自己写具体的url抓取函数的. python 爬虫 scrapy scrapy提 ...
随机推荐
- 利用python web框架django实现py-faster-rcnn demo实例
操作系统.编程环境及其他: window7 cpu python2.7 pycharm5.0 django1.8x 说明:本blog是上一篇blog(http://www.cnblogs.co ...
- Windos系统git提交
一.$ git status //查看当前项目下所有文的状态,如果第一次,你会发现都红颜色的,因为它还没有交给git/github管理. 二.$ git add . //(.)点表示当前目录下 ...
- ACM HDU 1081 To The Max
To The Max Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) To ...
- 深入理解javascript函数进阶系列第二篇——函数柯里化
前面的话 函数柯里化currying的概念最早由俄国数学家Moses Schönfinkel发明,而后由著名的数理逻辑学家Haskell Curry将其丰富和发展,currying由此得名.本文将详细 ...
- HDU 1908 Double Queue(set)
Problem Description The new founded Balkan Investment Group Bank (BIG-Bank) opened a new office in B ...
- Oracle442个应用场景-----------角色管理
--------------------------------角色管理------------------------------------ 一.角色的概念和特性 1.什么是角色? 角色就是相关权 ...
- [UWP]本地化入门
1. 前言 上一篇文章介绍了各种WPF本地化的入门知识,这篇文章介绍UWP本地化的入门知识. 2. 使用resw资源文件实现本地化 在以前的XAML平台,resx资源文件是一种很方便的本地化方案,但在 ...
- 后台返回json可能会出现的异常解析:java.lang.IllegalStateException: WRITER
在使用filter做权限管理限制访问时,经常是在数据可以正确返回时,在后台日志中却有这个异常抛出,这个现象让人不禁想去一探究竟. 我要做的是在一个filter中拦截所有的请求,并且根据拿到的请求中的参 ...
- Asynchronous vs synchronous client applications(MQTT)
来自我的CSDN博客 想查看英文原文的请点击原文网址.在上两篇翻译中,Homejim我给大家分别翻译了同步客户端应用程序和异步客户端应用程序.本人对这两个的区别也有困惑,因此将paho下的这个比较 ...
- 「mysql优化专题」主从复制面试宝典!面试官都没你懂得多!(11)
内容较多,可先收藏,目录如下: 一.什么是主从复制 二.主从复制的作用(重点) 三.主从复制的原理(重中之重) 四.三步轻松构建主从 五.必问面试题干货分析(最最重要的点) 一.什么是主从复制(技术文 ...