用python爬取微博数据并生成词云
很早之前写过一篇怎么利用微博数据制作词云图片出来,之前的写得不完整,而且只能使用自己的数据,现在重新整理了一下,任何的微博数据都可以制作出来,放在今天应该比较应景。
一年一度的虐汪节,是继续蹲在角落默默吃狗粮还是主动出击告别单身汪加入散狗粮的行列就看你啦,七夕送什么才有心意,程序猿可以试试用一种特别的方式来表达你对女神的心意。有一个创意是把她过往发的微博整理后用词云展示出来。本文教你怎么用Python快速创建出有心意词云,即使是Python小白也能分分钟做出来。
准备工作
本环境基于Python3,理论上Python2.7也是可行的,先安装必要的第三方依赖包:
# requirement.txt
jieba==0.38
matplotlib==2.0.2
numpy==1.13.1
pyparsing==2.2.0
requests==2.18.4
scipy==0.19.1
wordcloud==1.3.1
requirement.txt文件中包含上面的几个依赖包,如果用pip方式安装失败,推荐使用Anaconda安装
pip install -r requirement.txt
第一步:分析网址
打开微博移动端网址 https://m.weibo.cn/searchs ,找到女神的微博ID,进入她的微博主页,分析浏览器发送请求的过程
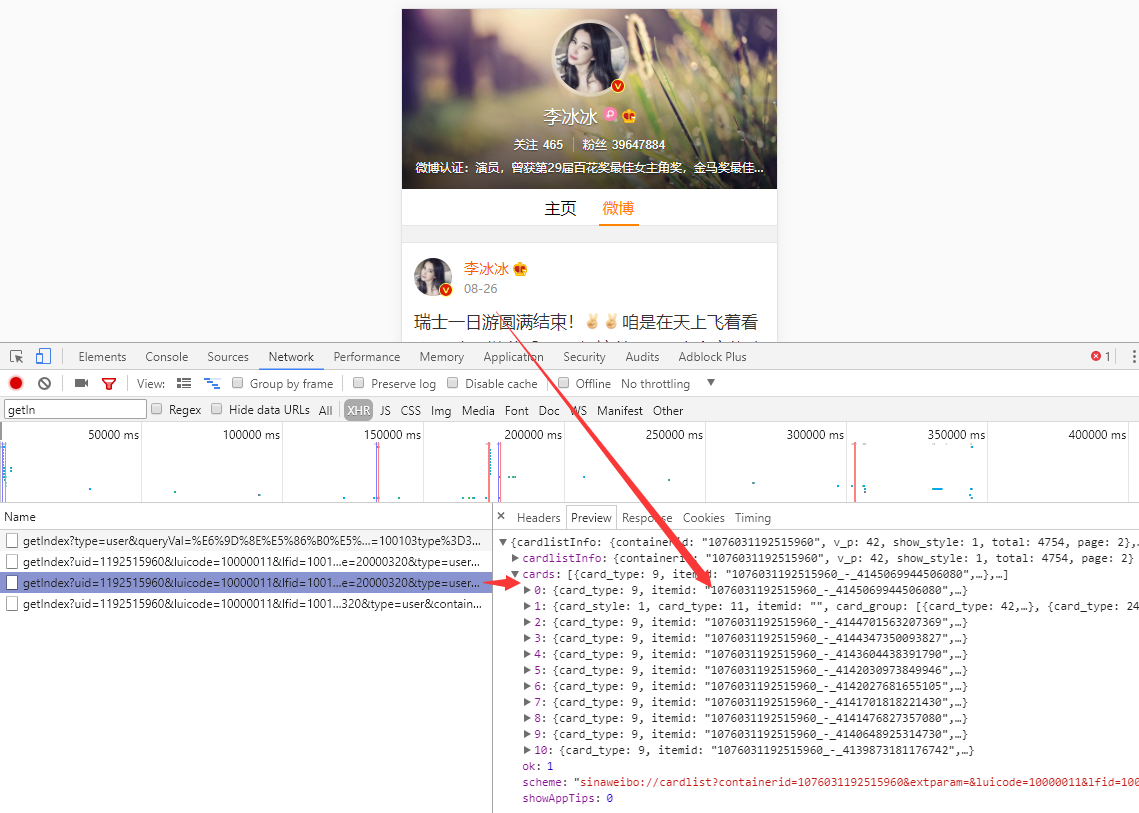
打开 Chrome 浏览器的调试功能,选择 Network 菜单,观察到获取微博数据的的接口是 https://m.weibo.cn/api/container/getIndex ,后面附带了一连串的参数,这里面有些参数是根据用户变化的,有些是固定的,先提取出来。
uid=1192515960&
luicode=10000011&
lfid=100103type%3D3%26q%3D%E6%9D%8E%E5%86%B0%E5%86%B0&
featurecode=20000320&
type=user&
containerid=1076031192515960
再来分析接口的返回结果,返回数据是一个JSON字典结构,total 是微博总条数,每一条具体的微博内容封装在 cards 数组中,具体内容字段是里面的 text 字段。很多干扰信息已隐去。
{
"cardlistInfo": {
"containerid": "1076031192515960",
"total": 4754,
"page": 2
},
"cards": [
{
"card_type": 9,
"mblog": {
"created_at": "08-26",
"idstr": "4145069944506080",
"text": "瑞士一日游圆满结束...",
}
}]
}
第二步:构建请求头和查询参数
分析完网页后,我们开始用 requests 模拟浏览器构造爬虫获取数据,因为这里获取用户的数据无需登录微博,所以我们不需要构造 cookie信息,只需要基本的请求头即可,具体需要哪些头信息也可以从浏览器中获取,首先构造必须要的请求参数,包括请求头和查询参数。
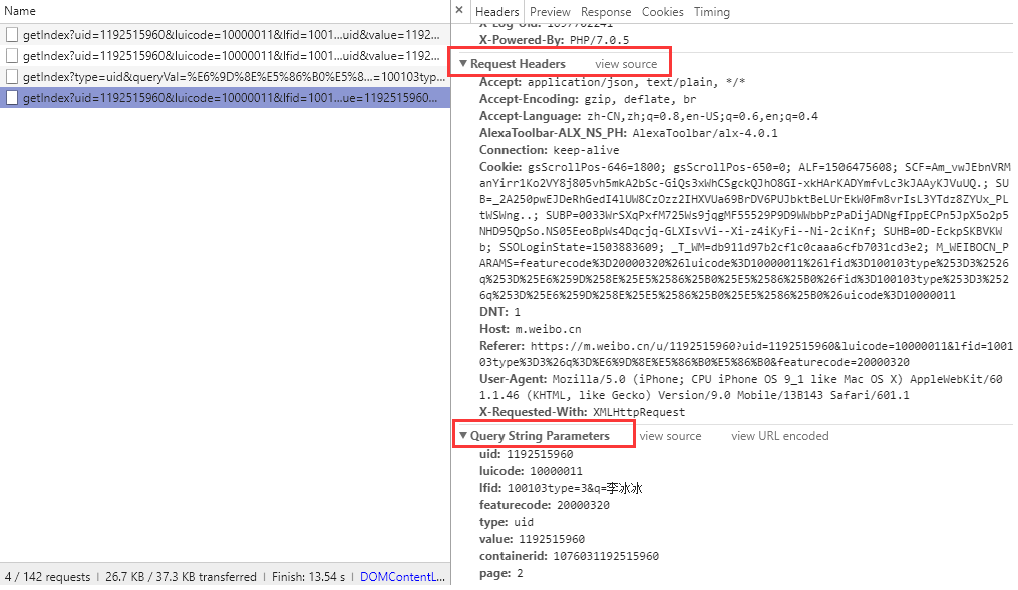
headers = {
"Host": "m.weibo.cn",
"Referer": "https://m.weibo.cn/u/1705822647",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) "
"Version/9.0 Mobile/13B143 Safari/601.1",
}
params = {"uid": "{uid}",
"luicode": "20000174",
"featurecode": "20000320",
"type": "uid",
"value": "1705822647",
"containerid": "{containerid}",
"page": "{page}"}
- uid是微博用户的id
- containerid虽然不什么意思,但也是和具体某个用户相关的参数
- page 分页参数
第三步:构造简单爬虫
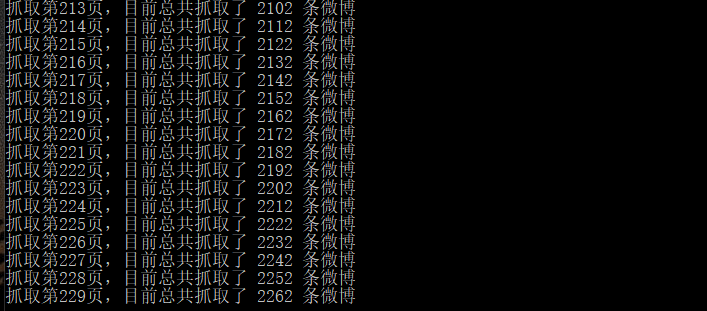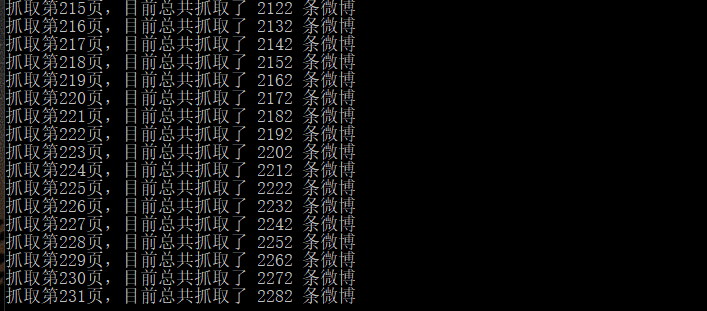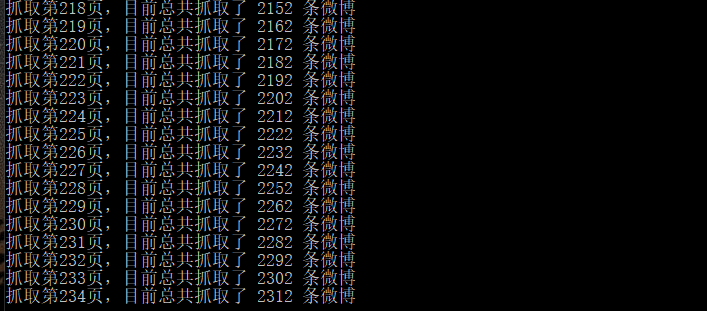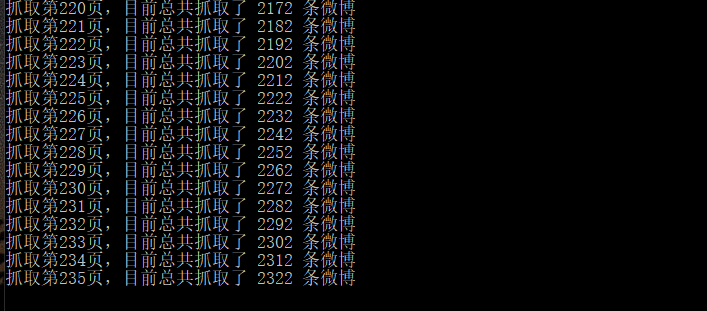
通过返回的数据能查询到总微博条数 total,爬取数据直接利用 requests 提供的方法把 json 数据转换成 Python 字典对象,从中提取出所有的 text 字段的值并放到 blogs 列表中,提取文本之前进行简单过滤,去掉无用信息。顺便把数据写入文件,方便下次转换时不再重复爬取。
def fetch_data(uid=None, container_id=None):
"""
抓取数据,并保存到CSV文件中
:return:
"""
page = 0
total = 4754
blogs = []
for i in range(0, total // 10):
params['uid'] = uid
params['page'] = str(page)
params['containerid'] = container_id
res = requests.get(url, params=params, headers=HEADERS)
cards = res.json().get("cards") for card in cards:
# 每条微博的正文内容
if card.get("card_type") == 9:
text = card.get("mblog").get("text")
text = clean_html(text)
blogs.append(text)
page += 1
print("抓取第{page}页,目前总共抓取了 {count} 条微博".format(page=page, count=len(blogs)))
with codecs.open('weibo1.txt', 'w', encoding='utf-8') as f:
f.write("\n".join(blogs))
第四步:分词处理并构建词云
爬虫了所有数据之后,先进行分词,这里用的是结巴分词,按照中文语境将句子进行分词处理,分词过程中过滤掉停止词,处理完之后找一张参照图,然后根据参照图通过词语拼装成图。
def generate_image():
data = []
jieba.analyse.set_stop_words("./stopwords.txt") with codecs.open("weibo1.txt", 'r', encoding="utf-8") as f:
for text in f.readlines():
data.extend(jieba.analyse.extract_tags(text, topK=20))
data = " ".join(data)
mask_img = imread('./52f90c9a5131c.jpg', flatten=True)
wordcloud = WordCloud(
font_path='msyh.ttc',
background_color='white',
mask=mask_img
).generate(data)
plt.imshow(wordcloud.recolor(color_func=grey_color_func, random_state=3),
interpolation="bilinear")
plt.axis('off')
plt.savefig('./heart2.jpg', dpi=1600)
最终效果图:

完整代码可以在公众号(Python之禅)回复“qixi”获取
用python爬取微博数据并生成词云的更多相关文章
- 【python3】爬取简书评论生成词云
一.起因: 昨天在简书上看到这么一篇文章<中国的父母,大都有毛病>,看完之后个人是比较认同作者的观点. 不过,翻了下评论,发现评论区争议颇大,基本两极化.好奇,想看看整体的评论是个什么样, ...
- 如何使用Python爬取基金数据,并可视化显示
本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理 以下文章来源于Will的大食堂,作者打饭大叔 前言 美国疫情越来越严峻,大选也进入 ...
- 毕设之Python爬取天气数据及可视化分析
写在前面的一些P话:(https://jq.qq.com/?_wv=1027&k=RFkfeU8j) 天气预报我们每天都会关注,我们可以根据未来的天气增减衣物.安排出行,每天的气温.风速风向. ...
- Python爬取房产数据,在地图上展现!
小伙伴,我又来了,这次我们写的是用python爬虫爬取乌鲁木齐的房产数据并展示在地图上,地图工具我用的是 BDP个人版-免费在线数据分析软件,数据可视化软件 ,这个可以导入csv或者excel数据. ...
- 【网络爬虫】【java】微博爬虫(一):小试牛刀——网易微博爬虫(自定义关键字爬取微博数据)(附软件源码)
一.写在前面 (本专栏分为"java版微博爬虫"和"python版网络爬虫"两个项目,系列里所有文章将基于这两个项目讲解,项目完整源码已经整理到我的Github ...
- python爬取拉勾网数据并进行数据可视化
爬取拉勾网关于python职位相关的数据信息,并将爬取的数据已csv各式存入文件,然后对csv文件相关字段的数据进行清洗,并对数据可视化展示,包括柱状图展示.直方图展示.词云展示等并根据可视化的数据做 ...
- python爬取网站数据
开学前接了一个任务,内容是从网上爬取特定属性的数据.正好之前学了python,练练手. 编码问题 因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了. 问题要从文字的编码讲 ...
- python爬取网站数据保存使用的方法
这篇文章主要介绍了使用Python从网上爬取特定属性数据保存的方法,其中解决了编码问题和如何使用正则匹配数据的方法,详情看下文 编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这 ...
- 用Python爬取股票数据,绘制K线和均线并用机器学习预测股价(来自我出的书)
最近我出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中用股票范例讲述Pyth ...
随机推荐
- Spring写第一个应用程序
ref:http://www.importnew.com/13246.html 让我们用Spring来写第一个应用程序吧. 完成这一章要求: 熟悉Java语言 设置好Spring的环境 熟悉简单的Ec ...
- StringBuffer的添加与删除功能
StringBuffer的添加功能A* public StringBuffer append(String str): * 可以把任意类型数据添加到字符串缓冲区里面,并返回字符串缓冲区本身 B* pu ...
- 框架基础:ajax设计方案(六)--- 全局配置、请求格式拓展和优化、请求二进制类型、浏览器错误搜集以及npm打包发布
距离上一次博客大概好多好多时间了,感觉再不搞点东西出来,感觉就废了的感觉.这段时间回老家学习驾照,修养,然后7月底来上海求职(面了4家,拿了3家office),然后入职同程旅游,项目赶进度等等一系列的 ...
- [js高手之路] html5 canvas系列教程 - arc绘制曲线图形(曲线,弧线,圆形)
绘制曲线,经常会用到路径的知识,如果你对路径有疑问,可以参考我的这篇文章[js高手之路] html5 canvas系列教程 - 开始路径beginPath与关闭路径closePath详解. arc:画 ...
- Mysql查询优化小结
转自http://www.cnblogs.com/112ba/p/6220650.html 数据类型 简单原则:更小更好,简单就好,避免NULL1)整型如int(10)括号中的值与存储大小无关2)实数 ...
- xcode7.3 iTunes Store operation failed解决
使用apploader上传程序 提示:如果您安装了XCode开发环境.在/Applications/XCode.app/Contents/Applications目录中可以找到Application ...
- C++移动构造函数以及move语句简单介绍
C++移动构造函数以及move语句简单介绍 首先看一个小例子: #include <iostream> #include <cstring> #include <cstd ...
- Minutes和TotalMinutes的区别
今天测试提了一个BUG,说是消息提醒的时机不对,设置的提前2小时,还没到就提醒了. 看了下代码 (m.ExpectReceiveTime - DateTime.Now).Minutes < (p ...
- JAVA HashMap 解析
1.简介(其实是HashMap注释的大致翻译) 本文基于JDK1.8,与JDK1.7中的HashMap有一些区别,看官注意区别. HashMap实现了Map接口,提供了高效的Key-Value访问.H ...
- BGP协议
BGP属于自治系统间路由协议.BGP的主要目标是为处于不同AS中的路由器之间进行路由信息通信提供保障.BGP既不是纯粹的矢量距离协议,也不是纯粹的链路状态协议,通常被称为通路向量路由协议.这是因为BG ...