浅析SQL Server在可序列化隔离级别下,防止幻读的范围锁的锁定问题
本文出处:http://www.cnblogs.com/wy123/p/7501261.html
(保留出处并非什么原创作品权利,本人拙作还远远达不到,仅仅是为了链接到原文,因为后续对可能存在的一些错误进行修正或补充,无他)
数据库在处理并发事物的过程中,在不同的隔离级别下有不同的锁表现,在非可序列化隔离级别下,存在着脏读,不可重复读,丢失更新,幻读等情况。
本文不讨论脏读和不可重复读以及丢失更新的情形,仅讨论幻读,幻读是指在一个事物中,同一个条件,存在两次读到的数据行数不一致的情况。
最高隔离级别也即可序列化隔离级别消除了幻读,幻读的消除过程中会通过Range锁(也即范围锁)来实现事物隔离的。
那么,Range锁是如何产生的?产生Range锁时,锁定的范围又是如何确定的?不同的索引产生的Range锁范围有什么区别?
本文将对此进行一个粗浅的分析与推断。
查阅了很多资料,尚未得到一个非常清晰的答案,原因在于:
1,没有指明Range锁的范围,观察锁的时候看到Range锁产生之后就收场,并没有分析Range锁产生时,锁定的具体范围是什么,锁定已存在的值没问题,是否锁定未存在的值?
1,非唯一索引与唯一索引的情况下产生的范围锁,锁定的范围包不包括临界值 ?
2,对于查询表中不存在的key值(分两种,一种是介于表中最大与最小Key之间,一种是位于最大或者最小key值之外),锁定的范围到底是怎么样的?
测试中发现一个有意思的问题,对于唯一索引,当锁定目标是一个表中已存在的Key值的时候,表面上产生的是一个key锁,真的就仅仅锁定了当前的这一个Key(数据行)吗?
同时,对于那个经典的“并发情况下存在则更新,不存在的插入”的处理,其背后的原理,也可以用Range锁来解释。
说明一下本文测试的原则:
1,测试均在可序列化隔离级别下测试(set transaction isolation level serializable )。
2,测试的原则是,Session1中采用排它锁的方式加锁,利用共享锁与排它锁不兼容的特点,Session2中采用共享锁的方式来不断探测Session1中产生的锁的范围。
3,测试数据库是SQL Server 2014
1,测试环境构建
1.1 新建测试表并写入数据
create table TestLock
(
Id int,
Name varchar(100)
) create clustered index idx_id on TestLock(id) insert into TestLock values (10,'aaa')
insert into TestLock values (20,'bbb')
insert into TestLock values (30,'ccc')
insert into TestLock values (40,'ddd')
insert into TestLock values (50,'eee')
1.2 测试表中的数据行存储位置分析
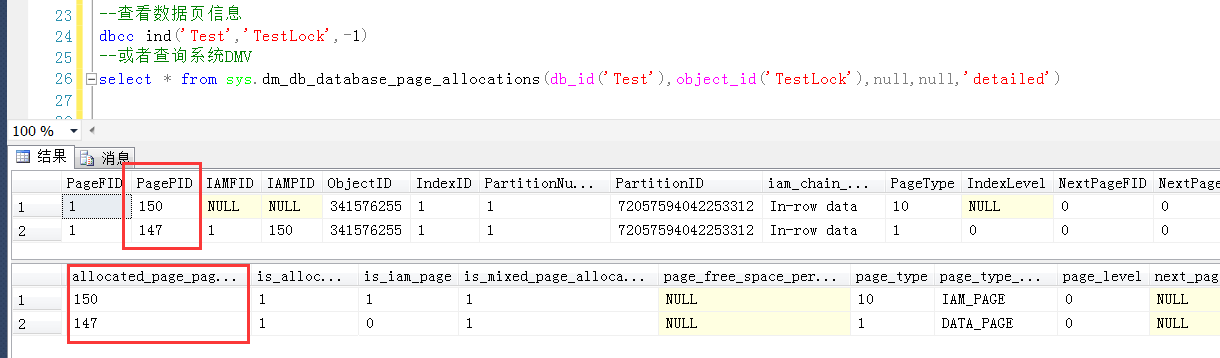
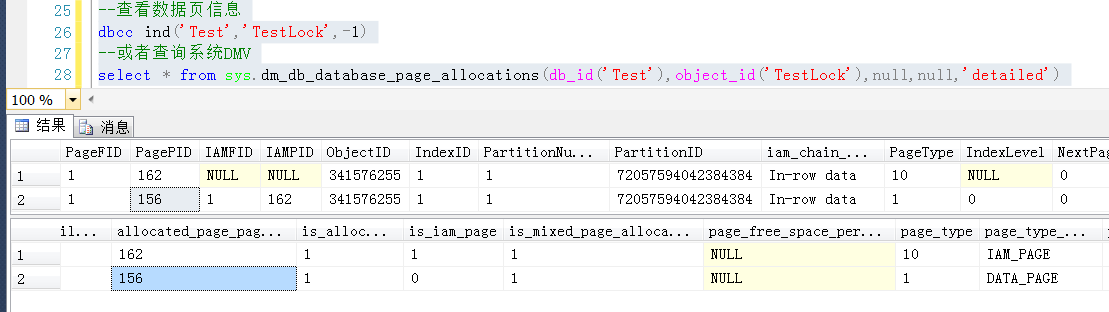
通过系统命令或者表查询测试表的page信息
--查看数据页信息
dbcc ind('Test','TestLock',-1)
--或者查询系统DMV
select * from sys.dm_db_database_page_allocations(db_id('Test'),object_id('TestLock'),null,null,'detailed')
表TestLock的数据页面为147
1.3 查询147号页面的数据行的KeyHashValue(可以认为是数据行的唯一标识)
DBCC TRACEON(3604)
DBCC PAGE(Test,1,147,3)
这里找到数据行对应的KeyHashValue如下图所示
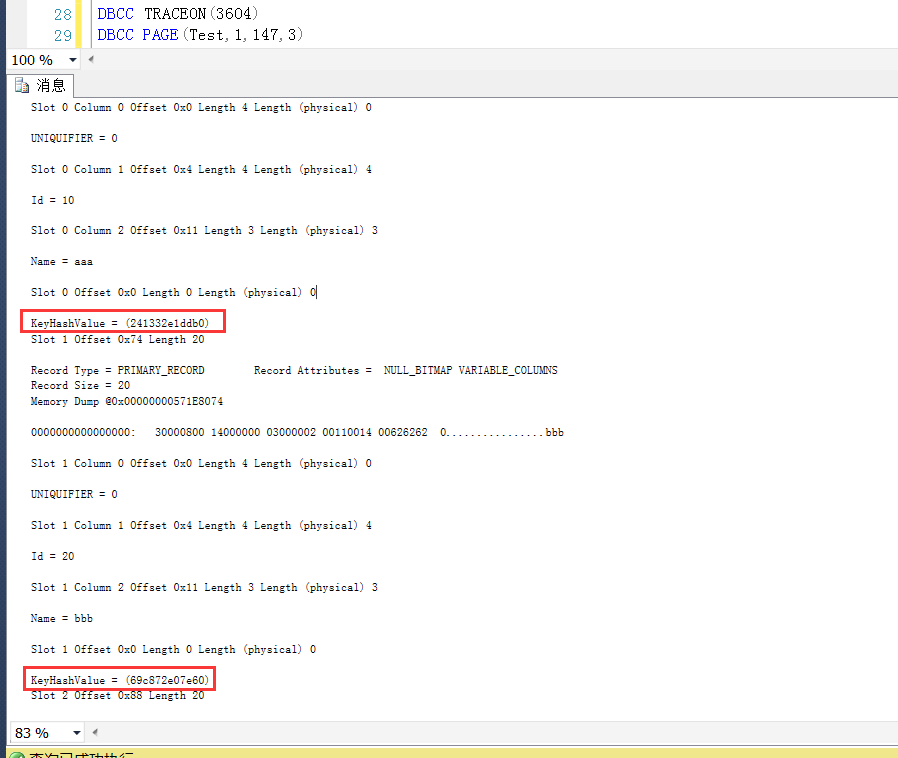
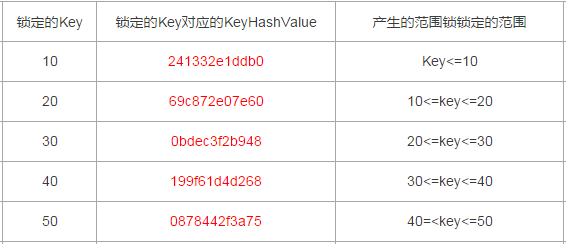
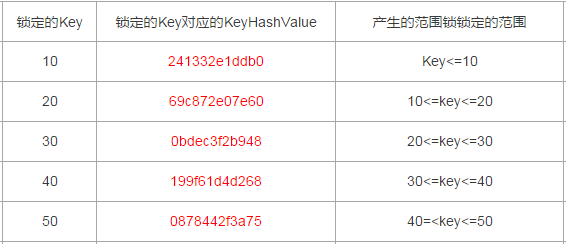
整理出来的数据行Id与其对应的KeyHashValue如下
10:241332e1ddb0
20:69c872e07e60
30:0bdec3f2b948
40:199f61d4d268
50:0878442f3a75
2,Range锁产生时,锁定的范围初步分析
2.1 Range锁产生的场景分析
在可序列化隔离级别下,测试一个Range锁产生的情况
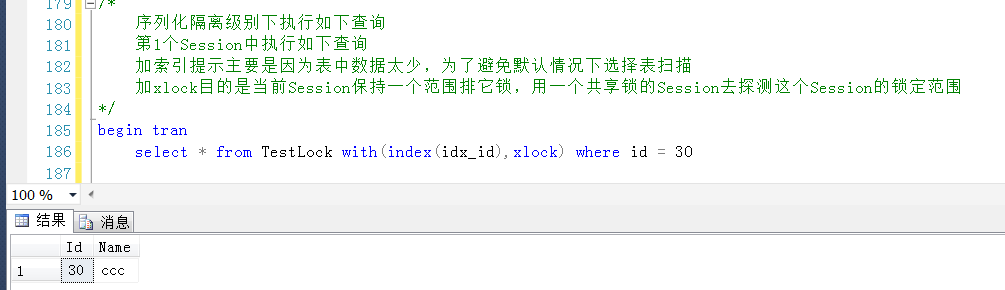
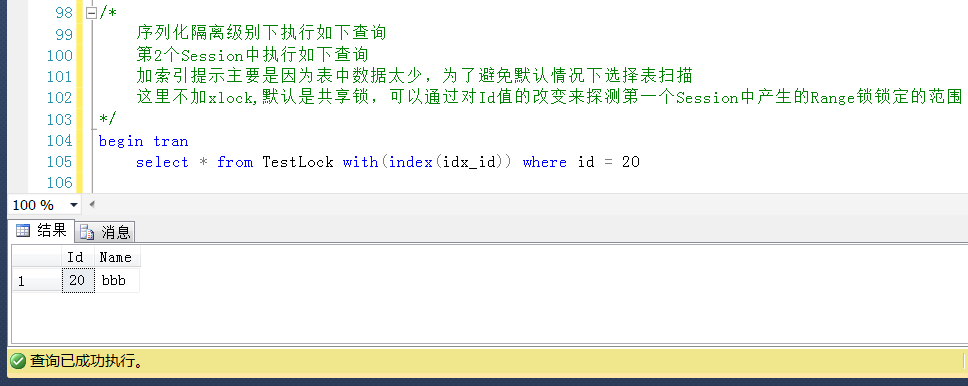
如代码中的备注所示,第一个Session中执行如下查询,暂不提交事物
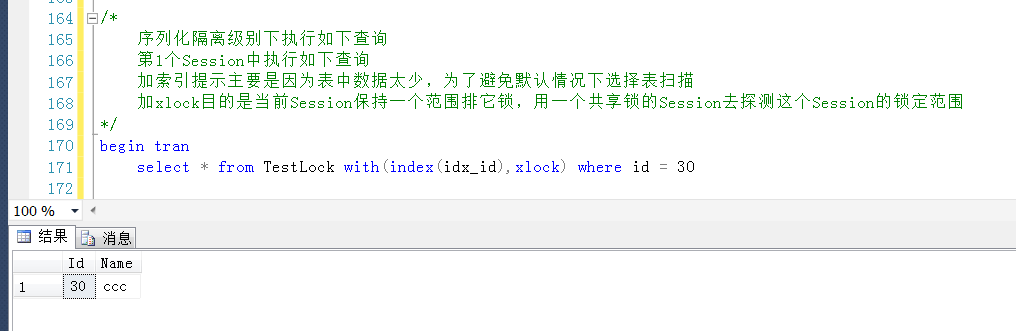
第一个Session中执行情况先保持(不提交也不回滚),另开一个查询窗口,也即第二个Session中查询产生的Range锁
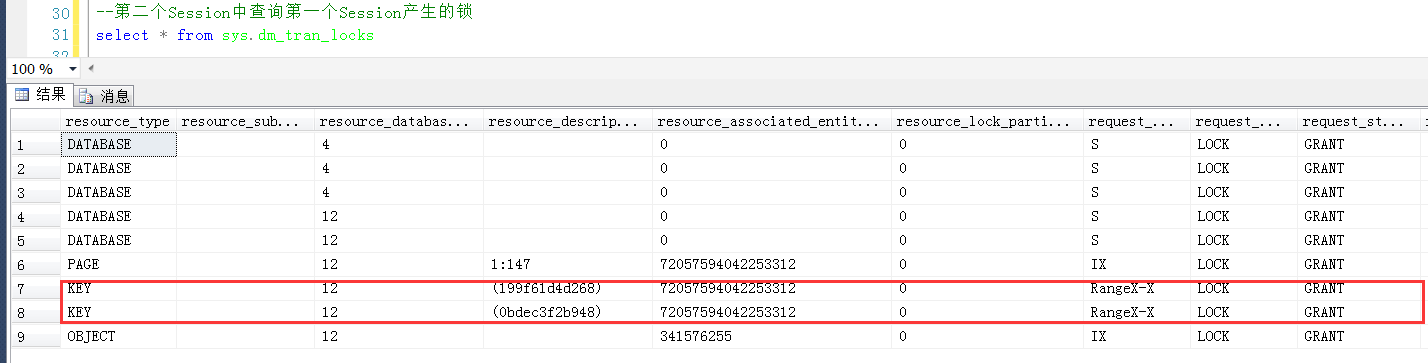
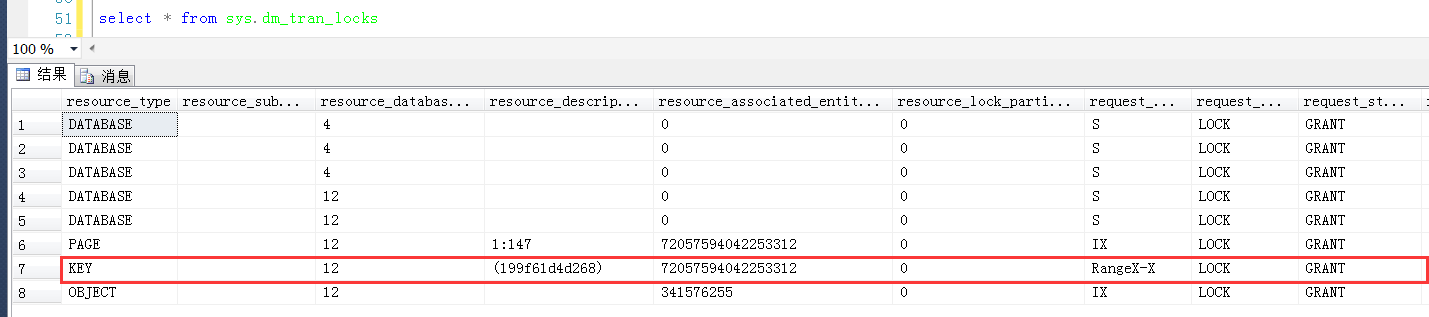
可以清楚地看到产生两个Range锁的resource_description分别是0bdec3f2b948和199f61d4d268
对照上面分析出来的数据行与KeyHashValue的关系,说明这个两个resource_description的值分别是30和40
最重要的问题就在这里,Range锁的resource_description是0bdec3f2b948和199f61d4d268,既然是RangeX-X,也就是范围锁,那么这两个Range锁定的范围是多大?
这里先给出结论,当在产生key类型的Range锁的时候,
以上述测试case为例,每一个Range锁对应的范围如下(以下表格内容都包括临界值,临界值跟索引是否唯一也有关,下文会有说明)
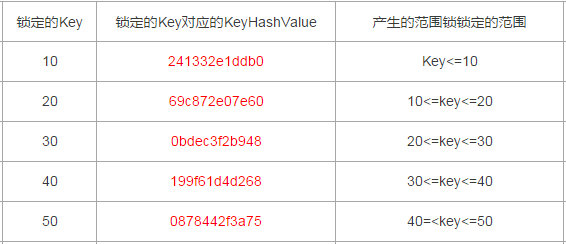
以上述测试为例,产生了两个RangeX-X类型的Key类型锁,分别是Id为30和40对应的RangeX-X,那么锁定的范围就是20~40,
既然是一个范围锁,就跟表中是区间的数据是否存在无关。
上面的话怎么理解?
如何证明锁定的范围就是20~40,看以下测试:
2.2查询被锁定区间的值,不管这个值是否已经存在于表中,都是会被被阻塞的
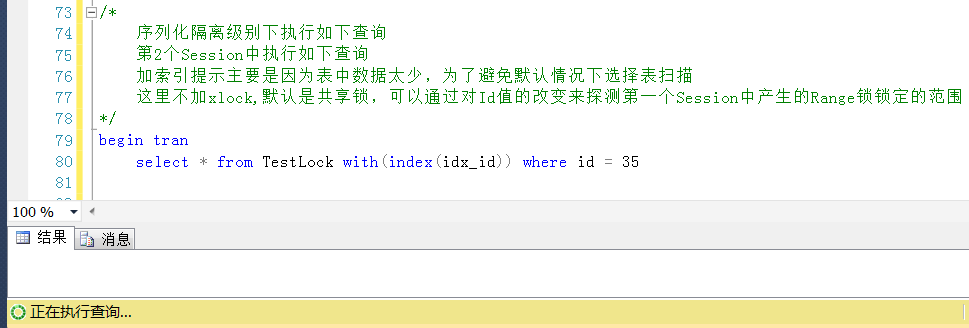
Session2中以序列化隔离级别执行如下代码,
查询Id = 35的Id值,虽然Id = 35是一个不存在的值,但是这个区间被锁定了,按道理,查询Id = 35的查询是会被阻塞的。
测试正如所预料的,因为这个区间被锁定了(排它锁),查询这个区间的任何一个值都被阻塞,而不管查询的Id值是否存在
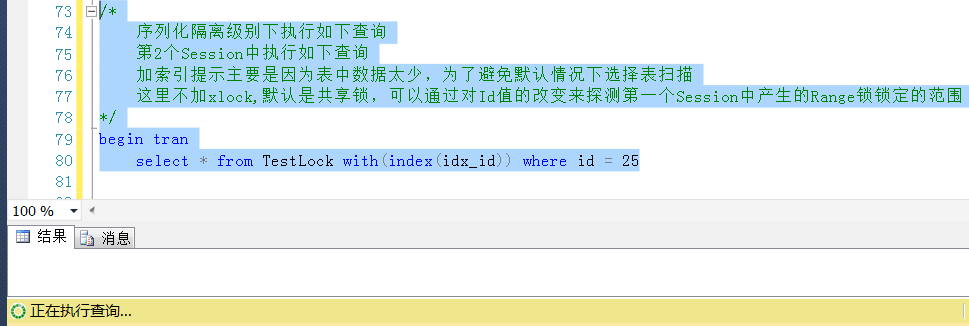
继续测试,回滚Session2中的查询,查询一个下限范围的Id,
同样的道理,虽然Id = 25是一个不存在的值,但是这个区间被锁定了,按道理,查询Id = 25的查询是会被阻塞的。
也是正如所预料的,因为这个区间被锁定了(排它锁),查询这个区间的任何一个值都被阻塞,而不管查询的Id值是否存在
2.3查询非锁定区间的值,不管这个值是否已经存在于表中,都是不会被被阻塞的
上面说了,锁定的范围就是20~40,那么查询一个非此区间的Id,是不会被锁定的。
继续测试,回滚Session2的查询,查询一个Id = 50的值,在非锁定范围之内(也即非20~40这个区间的Id),是可以正常查询的,也是预期的。
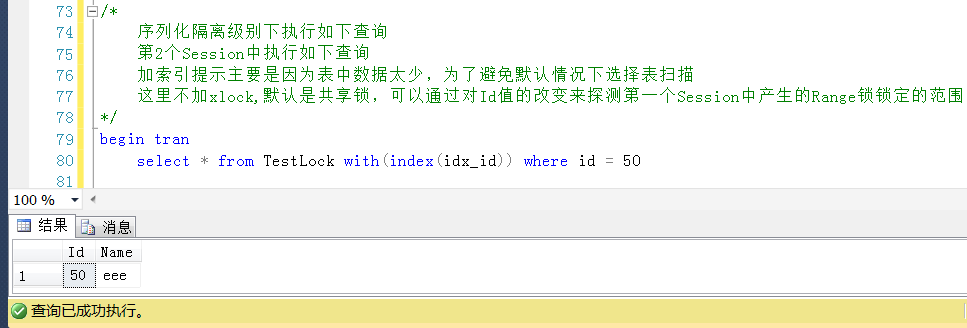
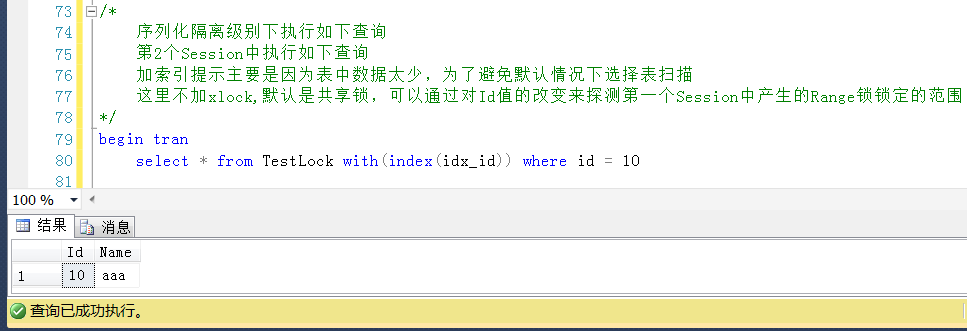
继续回滚Session2中的查询,查询一个小于20且存在的Id值,查询成功
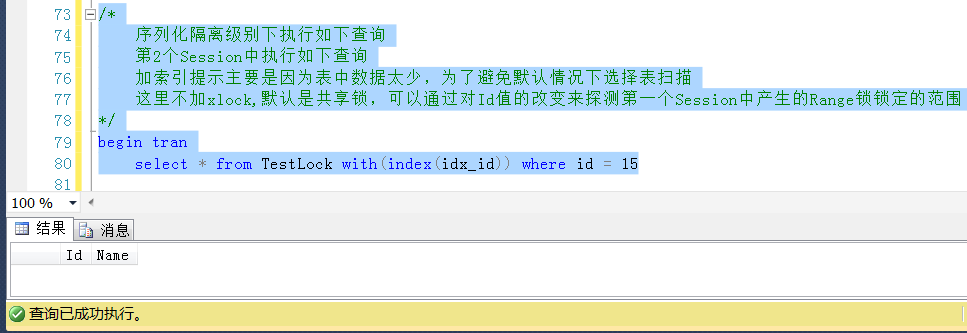
继续回滚Session2中的查询,查询一个小于20且不存在的Id值,这里使用Id = 15,查询成功
以上测试可以说明,一个Key类型的Range锁,都对应一个范围,加锁的时候锁定的是一个范围,对于锁定范区间的值,不管是否存在,都是会被阻塞的,而不仅仅是锁定已有数据行的作用。
3,非唯一索引情况下,范围锁锁定的范围分析
那么,一个Key类型的Range锁究竟锁定的范围是多大?
这也是一个非常有意思的问题,这里同样先给出结论,分为以下几种情况:
3.1 如果锁定的目标Id的值存在与表中,且大于表中的最大值,小于表中的最小值,那么锁定的区间就是小于锁定目标的第一个最大值,大于锁定目标的第一个最小值这个区间。
上述测试已经说明了这个锁的区间
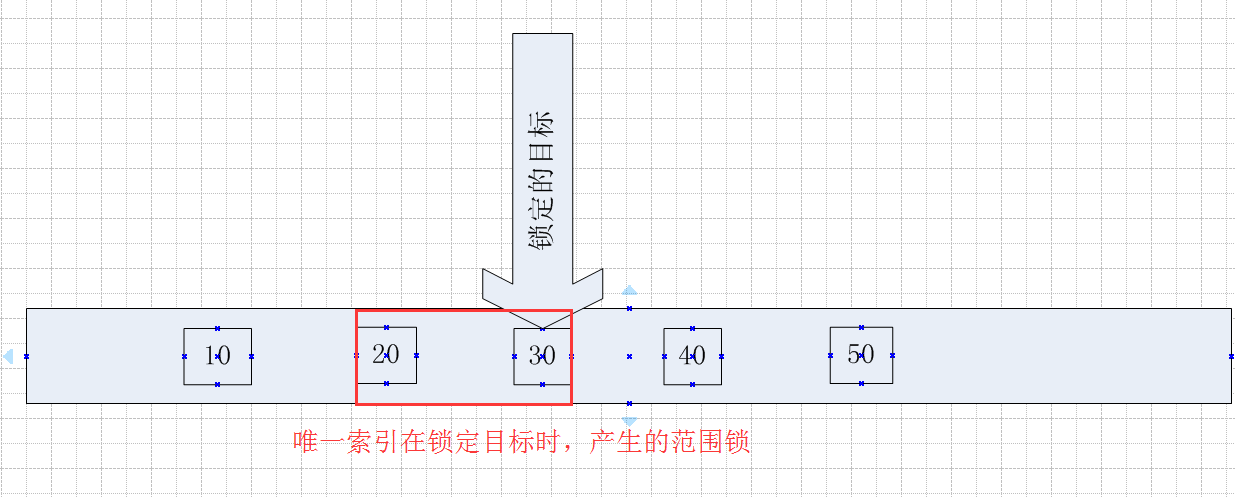
比如上述测试锁定的目标值,在Session1中以xlock的方式锁定Id =30,产生的范围锁,锁定的范围是下限值是20(小于30的最大值),上限值是40(大于30的最小值)
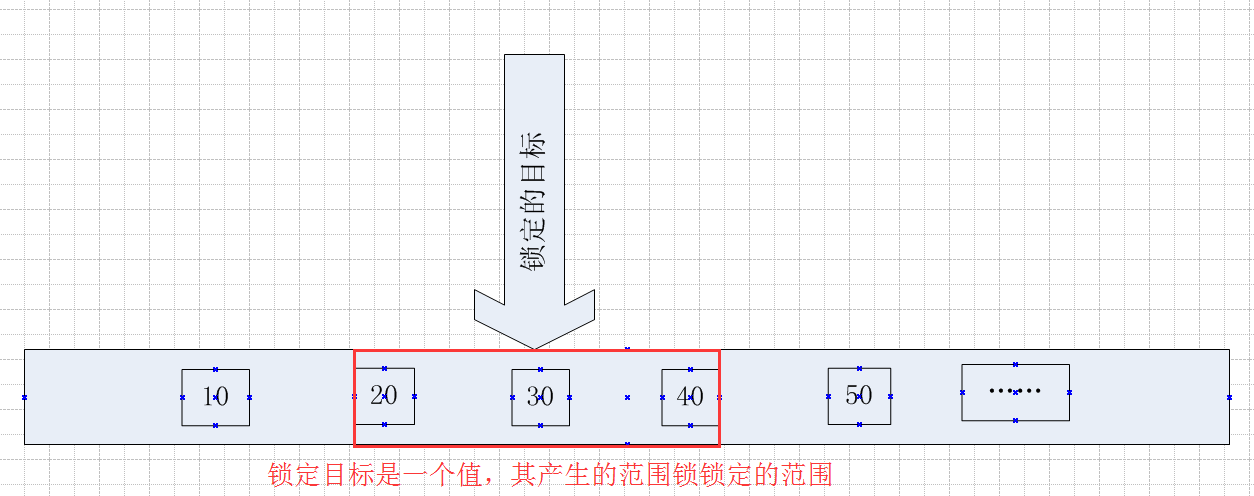
文字说起来有点绕,画个图看起来就直观了,如下
锁定的目标是30,因为在锁定30的时候会产生范围锁,这个范围锁锁定的区间是20~40
3.2 如果锁定的目标Id的值不存在与表中,且大于表中的最大值,小于表中的最小值,那么锁定的区间就是小于锁定目标的第一个最大值,大于锁定目标的第一个最小值这个区间。
重新开始测试,Session1和Session2中都回滚之前的测试
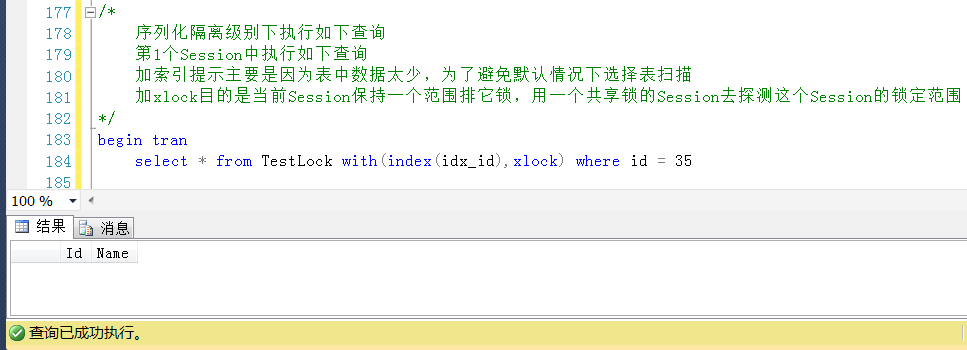
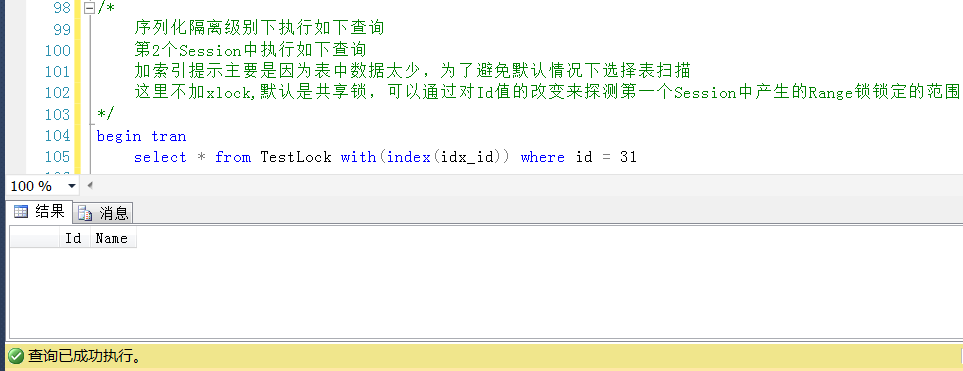
在Session1中执行一个Id = 35的查询,这个查询是添加了排它锁的方式执行的,这个Id是不存在的。
在Session2中观察产生的锁,会发现有一个resource_description是199f61d4d268的范围锁 。
KeyHashValue为199f61d4d268的Id是40,结合上述列表,40这个Id对应的锁的范围是30~40
那么究竟锁定的范围是不是30~40,同样可以在Session2中用共享锁查询的方式来探测Session1中锁定的范围
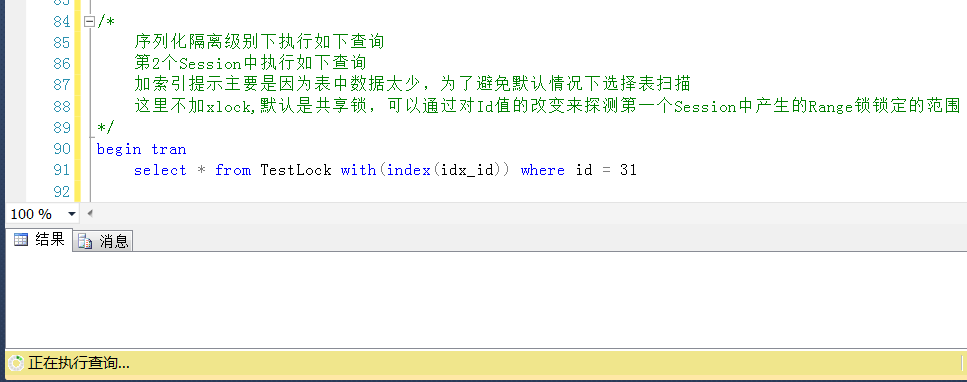
测试1,查询Id = 31的值,被锁定
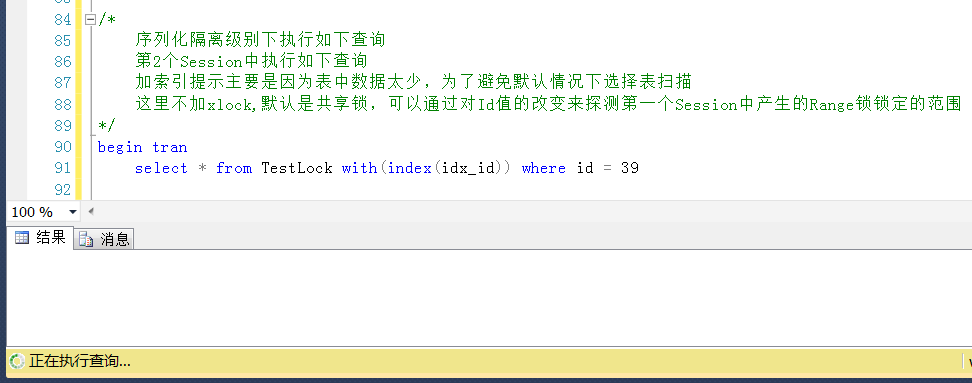
测试2,查询Id=39的值,被锁定
测试3,查询Id = 29得值,位于锁定区间之外,查询成功,尽管这是一个不存在的值,但是在锁定区间之外,可以查询成功。
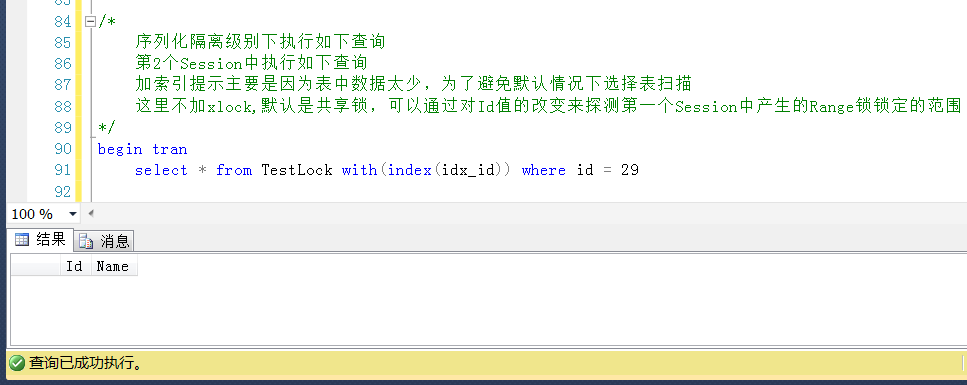
测试4,查询Id = 50的值,位于锁定区间之外,查询成功,这是一个存在的Id值
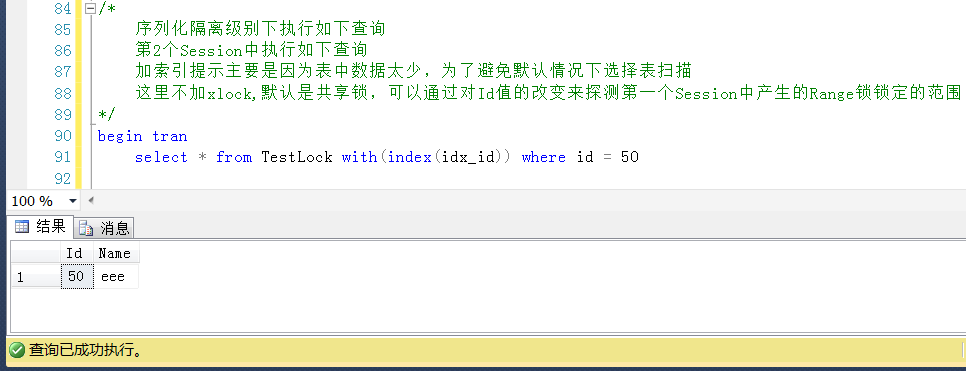
当锁定的目标在表中不存在的时候,且锁定目标大于表中已存在的最小Id值,小于最大Id值,
那么锁定的区间就是小于锁定目标的第一个最大值,大于锁定目标的第一个最小值这个区间。
同理,当产生范围锁的时候,锁定的是一个区间,而不管这个区间是否存在值,或者存在多少个值。
同样用一个图来表示,看起来更直观一点
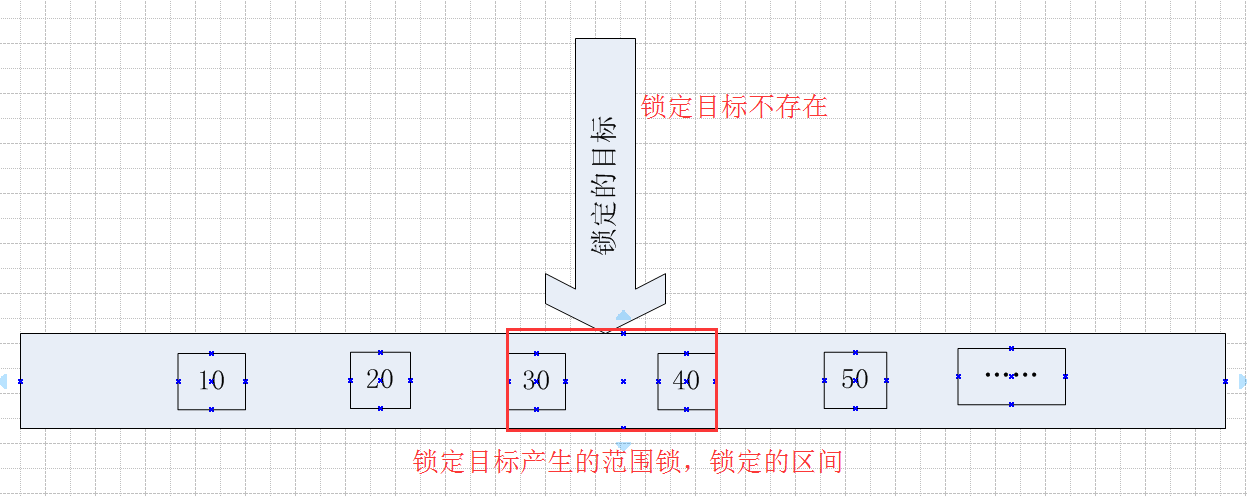
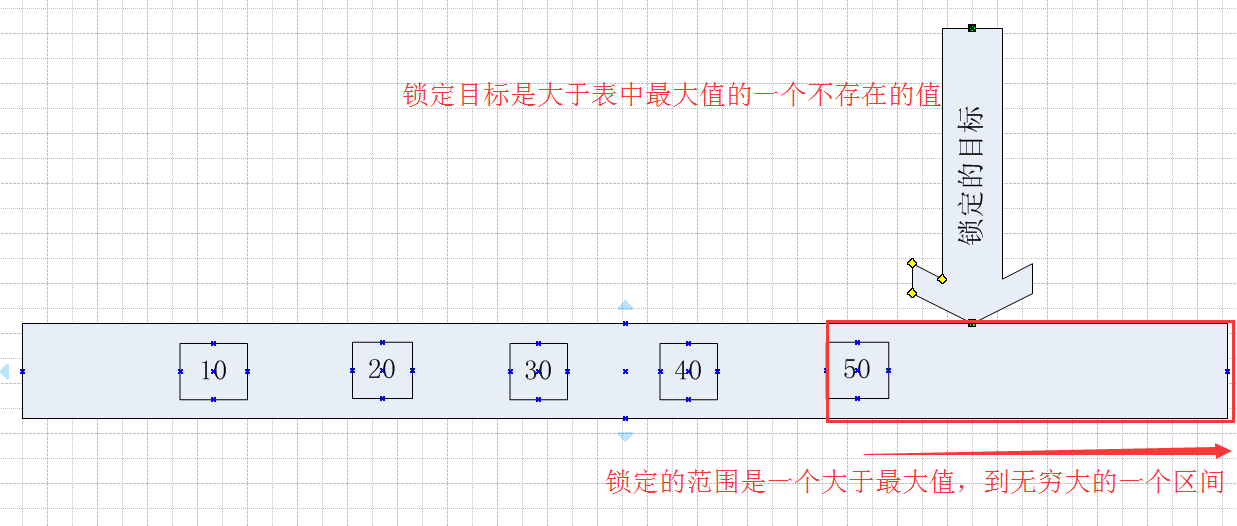
3.3 如果锁定的目标Id的值不存在与表中,且大于表中的最大值 ,锁定的范围是一个表中最大值到无穷大的一个范围
重新开始测试,Session1和Session2中都回滚之前的测试
在Session1中执行一个Id = 60的查询,这个查询是添加了排它锁的方式执行的,这个Id是不存在的

在Session2中观察产生的范围锁,这一次发现resource_description是一个(ffffffffffff),可以认为(ffffffffffff)这个KeyHashValue是一个无穷大的值
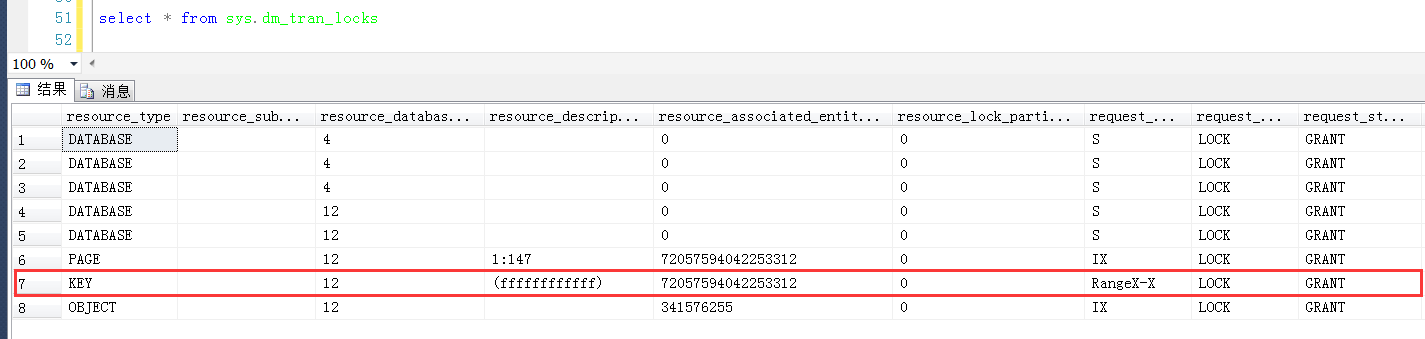
那么问题就来了,锁定范围的上限是一个无穷大的值,那么下限在哪里?
同样,可以在Session2中采用共享锁探测的方式来观察Session1锁定的范围
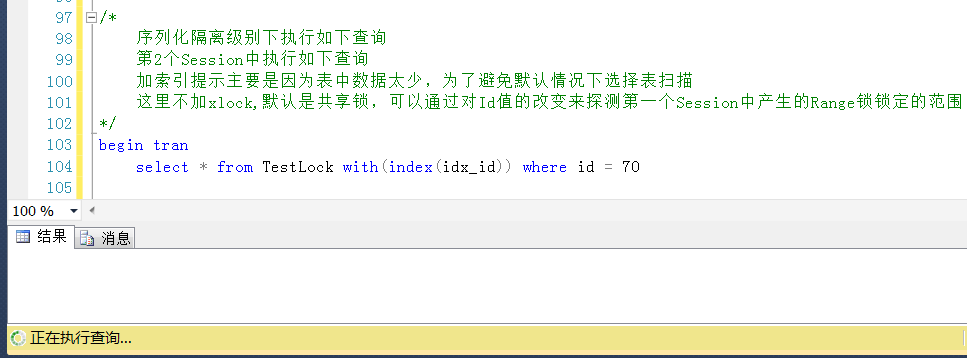
测试1,在Session2中查询Id = 70的值,Id = 70是大于表中的一个最大值,被锁定(锁定范围上限为无穷大,同理更大值也能被锁定)
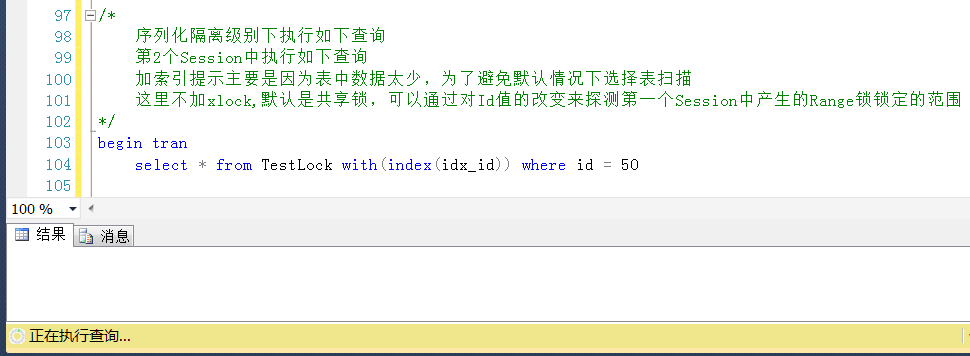
测试1,在Session2中查询Id = 50的值,Id = 50是表中的一个最大值,被锁定
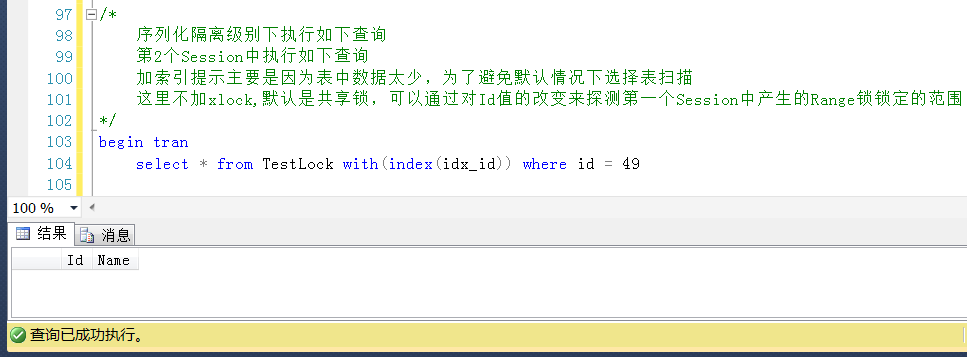
测试3,在Session2中查询Id = 49的值,Id = 49是小于表中的一个最大值,未被锁定,尽管这个值不存在
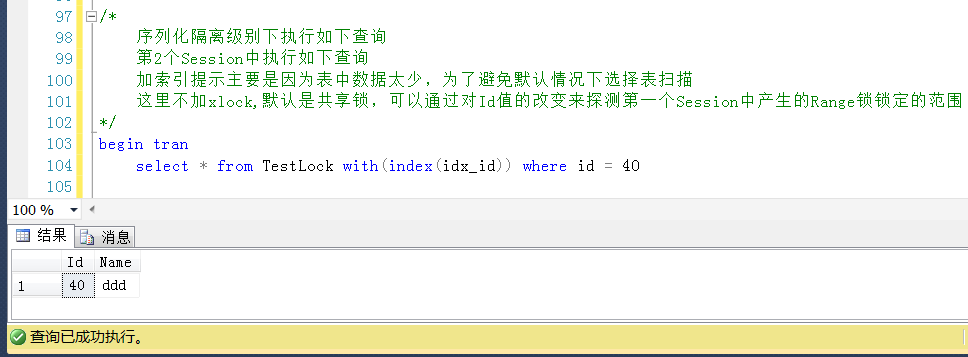
测试4,在Session2中查询Id = 40的值,Id = 40是小于表中的一个最大值且存在的值,未被锁定
当锁定的目标在表中不存在的时候,且锁定目标大于表中已存在的最大Id值,那么锁定的区间就是从表中最大值开始到无穷大的一个区间。
同样用一个图来表示,看起来更直观一点
4,关于索引是否唯一与锁定期间临界值的关系
上文测试过程中,给出的Key与其对应的范围锁的锁定关系中如下,锁定范围是包含了临界值的(双闭区间),但是一直没有刻意测试临界值。
没有刻意测试临界值是因为临界值是否被锁定,是跟索引的唯一性有关,如果索引时非唯一的,对应的范围锁在锁定的时候就包含临界值,如果索引唯一,情况是不一样的。
下文中会有说明。
对于唯一索引,分为以下几种情况:
4.1 唯一索引情况下,锁定目标为已存在的Id值,且Id值大于表中的最小Id,小于表中的最大Id
在索引唯一的情况下,锁定目标是一个表中已存在的Id值,那么究竟是不是范围锁?
很多人认为如果锁定目标是已存在的唯一索引,没有产生Range锁的时候就没有“范围锁”的概念了,其实是不对的。
继续测试,回滚Session1,Session2,删除表中一开始创建的非唯一索引,Id上创建成一个唯一的聚集索引。

测试在观察数据的索引页,发生了变化(重建了聚集索引,数据页发生了变化,想一想为什么?)
用同样的方式得到数据的KeyHashValue与数据行的对应关系如下
10:d08358b1108f
20:286fc18d83ea
30:8034b699f2c9
40:d8b6f3f4a521
50:f84b73ce9e8d
同理在Session1中查询一个已存在的Id值,作为锁定目标
在Session2中观察产生的锁,锁定的行是很明显是Id = 30的数据行,但是是一个X锁,而非范围锁(RangeX-X)。
那么此时,仅仅是会锁定当前行吗?
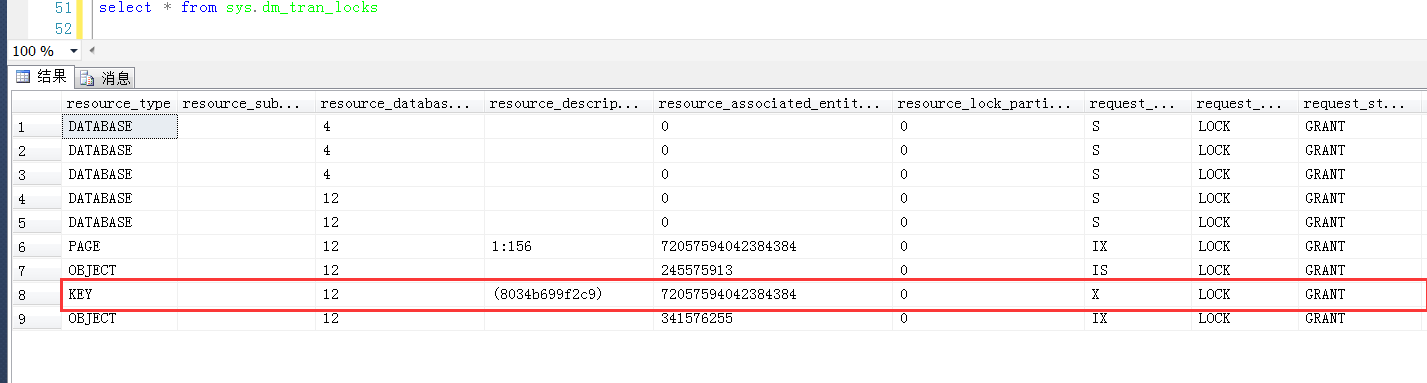
测试1,在Session2中查询一个小于输定目标(但是大于20,因为20是小于锁定目标的已存在的最大值)的值,发现依旧是被锁定,
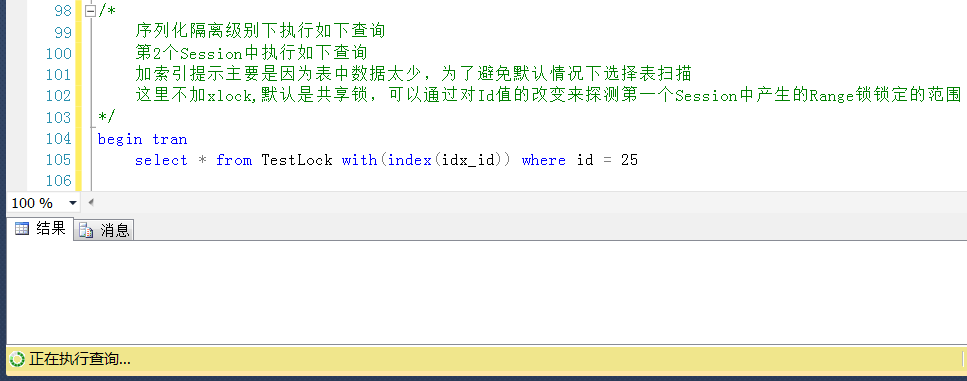
测试2,再测一个Id =29的值,一样是被锁定的
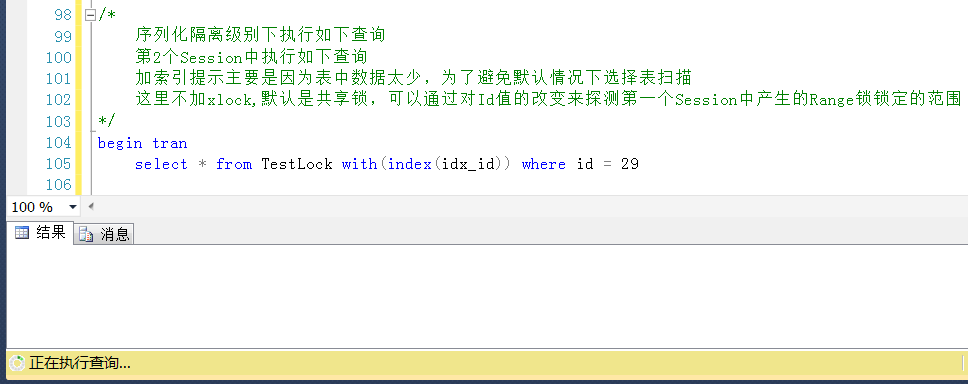
这里捎带看一下Session2(Sess_id = 55)被Session1(Session_id = 54)的阻塞情况
这里的wait_type为LCK_M_RS_S,LCK_M_RS_S是啥锁?LCK_M_RS_S:等待获取当前键值上的共享锁以及当前键和上一个键之间的共享范围锁
依旧是是“当前键和上一个键之间的共享范围锁”啊,依旧是范围锁啊,因此说,锁定已存在与表中的唯一索引的时候,虽然没有变现出来范围锁(sys.dm_tran_locks),但是本质上仍然是范围锁。
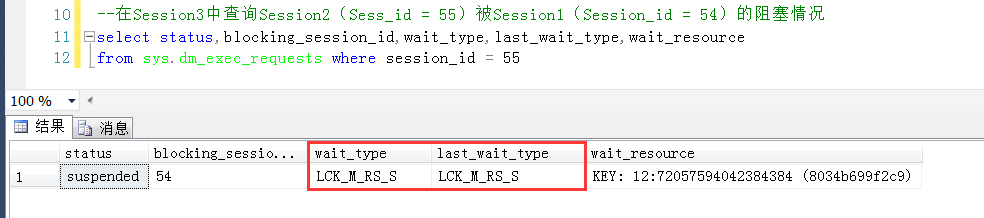
测试3,测试一个小于锁定目标,且存在与表中的最大值(也就是20),发现未被锁定(这就是唯一索引与非唯一索引在临界值上的锁定区别,如果是非唯一索引,这个20的临界值将会被锁定)
测试4,测试一个大于锁定区间的值,也即如下的Id = 31,查询是成功的,即便是Id= 31不存在的。
从中可以发现,在唯一索引的情况下,
如果锁定的目标Id的值存在与表中,且大于表中的最大值,小于表中的最小值,那么锁定的区间就是当前值到小于锁定目标的第一个最大值
具实际例子来说就是,锁定目标是30的情况下,锁定的区间值是(20,30]
4.2 唯一索引情况下,锁定目标为不存在的Id值,且Id值大于表中的最小Id,小于表中的最大Id
这种情况就不一一截图了,结论如同非唯一索引,比如锁定目标为Id = 35的情况下,锁的范围是(30,40],也即左开(区间)右闭(区间)
4.3 唯一索引情况下,锁定目标为不存在的Id值,且Id值大于表中的最大Id
这种情况也就不一一截图了,结论如同非唯一索引,比如锁定目标为Id = 60的情况下,锁的范围是(50,+∞),也即左开(区间)
5,关于查询条件是一个区间值的情况
因为知道了单个值查询的锁的区间,对于范围查询的情况,无非就是将查询范围进行分解,分解出单个值锁定的范围,然后将这个区间进行合并得到一个区间的并集。
有兴趣的可以自行测试。
6,关于查询条件是一个非聚集索引的情况
上述都是以聚集索引为查询条件进行测试的,如果是非聚集索引情况雷同,只不过是多了非聚集索引一级的锁,有时间再测试。
总结:
序列化隔离级别下会阻止幻读的产生,幻读的产生是通过范围锁锁定的是一个范围来实现的,
Range 锁最主要的是锁定一个范围,锁定的不仅仅是表中已有的数据,而是一个区间,而不管这个范围之内是否存在数据,
任何Session试图操作被其他Session范围锁锁定的数据,不管在表中是否存在,都将被阻塞,直到产生范围锁的Session事物提交。
此时也不难理解,对于那个最经典的问题:并发情况下,存在则更新,不存在则插入,不管采用什么写法,
比如并发插入,任何一个Session执行之前,都先锁定一个范围,即便是这个值不存在,
等到相同的值进来的时候,同样需要锁定一个范围,那么此时是会被阻塞的,因此可以实现并发存在则更新,不存在则插入的效果
了解了Range锁的锁定原理,也不会纠结不同写法的区别了,目的都是加Range锁,锁定范围,防止并发情况下的幻读出现。
以上纯属个人测试和简单的推断,难免存在错误的地方,如有兴趣,欢迎探讨指正,谢谢。
最后
其实楼主是看了MySQL的gap锁、next-key锁之后回头来看SQL Server中的Range锁的,
最终发现,除了一些细节,锁的实现在套路上都是一样的,比如对待幻读的处理上,可谓是在“道”的层面上都是一个原则。
一个叫做Range范围锁,一个叫做gap锁、next-key锁,不同的表现形式只是“术”上的问题罢了。
太累了,眼睛脖子都受不鸟了。
参考资料,各种翻书,各种上网查。

浅析SQL Server在可序列化隔离级别下,防止幻读的范围锁的锁定问题的更多相关文章
- InnoDB在MySQL默认隔离级别下解决幻读
1.结论 在RR的隔离级别下,Innodb使用MVVC和next-key locks解决幻读,MVVC解决的是普通读(快照读)的幻读,next-key locks解决的是当前读情况下的幻读. 2.幻读 ...
- SQL Server 之 事务与隔离级别实例讲解
SQL Server 之 事务与隔离级别实例讲解 SQL Server 实现了6个隔离级别来防止并发情况下,类似企图并发的访问或修改同一数据时问题的发生.本文将带你体验全部6个隔离级别.正如你接下来将 ...
- 【转修正】sql server行版本控制的隔离级别
在SQL Server标准的已提交读(READ COMMITTED)隔离级别下,一个读操作会和一个写操作相互阻塞.未提交读(READ UNCOMMITTED)虽然不会有这种阻塞,但是读操作可能会读到脏 ...
- 查看SQL Server当前会话的隔离级别
查看SQL Server当前会话的隔离级别 DBCC USEROPTIONS
- Sql Server中的事务隔离级别
数据库中的事物有ACID(原子性,一致性,隔离性,持久性)四个特性.其中隔离性是用来处理并发执行的事务之间的数据访问控制.SqlServer中提供了几种不同级别的隔离类型. 概念 Read UnCom ...
- Innodb 中 RR 隔离级别能否防止幻读?
问题引出 我之前的一篇博客 数据库并发不一致分析 有提到过事务隔离级别以及相应加锁方式.能够解决的并发问题. 标准情况下,在 RR(Repeatable Read) 隔离级别下能解决不可重复读(当行修 ...
- MYSQL事件隔离级别以及复读,幻读,脏读的理解
一.mysql事件隔离级别 1未提交读(READUNCOMMITTED) 另一个事务修改了数据,但尚未提交,而本事务中的SELECT会读到这些未被提交的数据(脏读)( 隔离级别最低,并发性能高 ) 2 ...
- SQL Server 的 6 种隔离级别
背景知识: 高并发一直以来是数据的所追求的目标,然,一般事物是有两面性的.不多说了,等下变邪教了.下面直接看 并发性最高的隔离级别 read uncommitted 1. read uncommitt ...
- sqlserver默认隔离级别下并发批量update同一张表引起的死锁
提到死锁,最最常规的场景之一是Session1 以排它锁的方式锁定A表,请求B表,session2以排它锁的方式锁定B表,请求A表之类的,访问顺序不一致导致死锁的情况本文通过简化,测试这样一种稍显特殊 ...
随机推荐
- 使用VMware安装CentOS
使用VMware安装CentOS 第1步:首先安装VMware Workstation,只需点下一步即可,安装过程略 第2步:文件 → 新建虚拟机 或 直接点击 创建新的虚拟机 图标 第3步:选择 典 ...
- 【原创】-- C# 点滴积累 -- String
一.string.Format() 将[数字字符串]转为两位小数显示的字符串: dt = dtResult.Select(it => new CommodityPriceLimitEntity ...
- 如何在github制作一个网页
1.首先得先注册一个github账号,官网:https://github.com/ 2.注册完,登录账号进入首页,点右上角的 ‘+’ 创建新的仓库 3. 点击setting,选择一个主题, 4. 选完 ...
- R语言成功加载rJava方法
加载rJava的同时,要下载JAVA的JRE并且配置环境变量JAVA_HOME,因为rJava的调用需要java运行环境. 1.下载JRE 64位版本的JRE官网下载:http://www.java. ...
- Samba服务部署
Samba,是种用来让UNIX系列的操作系统与微软Windows操作系统的SMB/CIFS(Server Message Block/Common Internet File System)网络协议做 ...
- 表达式求值(二叉树方法/C++语言描述)(三)
二叉树方法求值对运算数处理的方法与栈方法求值不太相同,除了将字符串中的运算数转换为浮点类型外,还需要生成新的节点: void Calculator::dealWithNumber(char *& ...
- mk-js,一个基于react、nodejs的全栈框架
前言 在这个前端技术爆炸的时代,不自己写套开源框架出门都不好意思跟别人说自己搞前端.去年年初接触的react,16年7月份在github开源了一套针对react.redux探索的项目,近期和伙伴们一起 ...
- java_弹球小游戏
弹球游戏实现原理: 隔一定时间(小于1秒)重新绘制图像,因为Graphics类是一个抽象类,创建子类的时候需要把所有涉及的方法都得重写,所以这里使用的是创建Canvas的子类,只需要重写它的paint ...
- Cordova + idea 环境搭建
1.安装前期工作 1).安装Node.js http://nodejs.cn/download/ 里面内置了npm,可以用来安装 Cordova,把该路径添加到环境变量,这样就可以在 cmd 里面任何 ...
- [Scoi2014]方伯伯的玉米田 二维树状数组+动态规划
考试最后半个小时才做这道题.十分钟写了个暴力还写挂了..最后默默输出n.菜鸡一只. 这道题比较好看出来是动规.首先我们要明确一点.因为能拔高长度任意的一段区域,所以如果从i开始拔高,那么一直拔高到n比 ...