Node.js爬虫-爬取慕课网课程信息
第一次学习Node.js爬虫,所以这时一个简单的爬虫,Node.js的好处就是可以并发的执行
这个爬虫主要就是获取慕课网的课程信息,并把获得的信息存储到一个文件中,其中要用到cheerio库,它可以让我们方便的操作HTML,就像是用jQ一样
开始前,记得
npm install cheerio
为了能够并发的进行爬取,用到了Promise对象
//接受一个url爬取整个网页,返回一个Promise对象
function getPageAsync(url){
return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = ''; res.on('data',function(data){
html += data;
}); res.on('end',function(){
resolve(html);
}); res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}
在慕课网中,每个课程都有一个ID,我们事先要把想要获取课程的ID写到一个数组中,而且每个课程的地址都是一个相同的地址加上ID,所以我们只要把地址和ID拼接起来就是课程的地址
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';
//获取课程的ID
const videosId = [773,371];
为了使获取每个课程内容时并发执行,要使用Promise中的all方法
Promise
//当所有网页的内容爬取完毕
.all(courseArray)
.then((pages)=>{
//所有页面需要的内容
let courseData = []; //遍历每个网页提取出所需要的内容
pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
}); //给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
} //对所需要的内容进行排序
courseData.sort((a,b)=>{
return a.number > b.number;
}); //在重新将爬取内容写入文件中前,清空文件
fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{
if(err){
console.log(err)
}
});
printfData(courseData);
});
在then方法中,pages是每个课程的HTML页面,我们还得从中提取出我们需要的信息,需要使用下面的函数
//接受一个爬取下来的网页内容,查找网页中需要的信息
function filterChapter(html){
const $ = cheerio.load(html); //所有章
const chapters = $('.chapter'); //课程的标题和学习人数
let title = $('.hd>h2').text();
let number = 0; //最后返回的数据
//每个网页需要的内容的结构
let courseData = {
'title':title,
'number':number,
'videos':[]
}; chapters.each(function(item){
let chapter = $(this);
//文章标题
let chapterTitle = Trim(chapter.find('strong').text(),'g'); //每个章节的结构
let chapterdata = {
'chapterTitle':chapterTitle,
'video':[]
}; //一个网页中的所有视频
let videos = chapter.find('.video').children('li');
videos.each(function(item){
//视频标题
let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');
//视频ID
let id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({
'title':videoTitle,
'id':id
})
}); courseData.videos.push(chapterdata); }); return courseData;
}
注意:在上面中将课程的学习人数设置为了0是因为学习课程人数是用Ajax动态获取,所以我在后面写了方法专门获取学习课程人数,其中用到的Trim()方法是去除文本中的空格
获取学习课程的人数:
//获取上课人数
function getNumber(url){ let datas = ''; http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
}); res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}
这样就将想获取课程的学习人数都添加到了courseMembers数组中,在最后将学习课程的人数在赋值给相对应的课程
//给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}
我们获取到了数据,就要把它按照一定的格式存到一个文件中
//写入文件
function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{
if(err){
console.log(err);
}
})
} //打印信息
function printfData(coursesData){ coursesData.forEach((courseData)=>{
// console.log(`${courseData.number}人学习过${courseData.title}\n`);
writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`); courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;
// console.log(chapterTitle + '\n');
writeFile(outputFile,`\n ${chapterTitle}\n`); item.video.forEach(function(item){
// console.log(' 【' + item.id + '】' + item.title + '\n');
writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
}); }); }
最后获取到的数据:
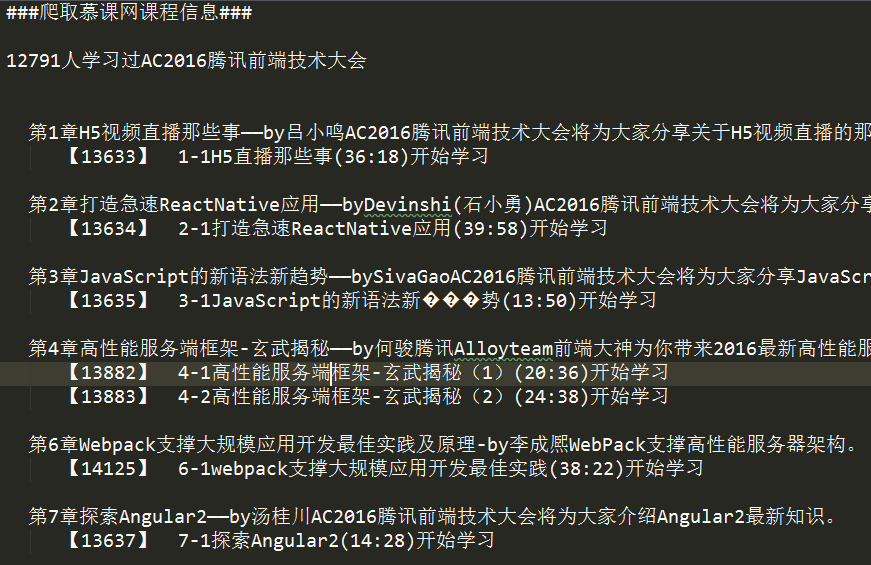
源码:
/**
* Created by hp-pc on 2017/6/7 0007.
*/
const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';
//获取课程的ID
const videosId = [773,371];
//输出的文件
const outputFile = 'test.txt';
//记录学习课程的人数
let courseMembers = []; //去除字符串中的空格
function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");
if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}
return result;
} //接受一个url爬取整个网页,返回一个Promise对象
function getPageAsync(url){
return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = ''; res.on('data',function(data){
html += data;
}); res.on('end',function(){
resolve(html);
}); res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
} //接受一个爬取下来的网页内容,查找网页中需要的信息
function filterChapter(html){
const $ = cheerio.load(html); //所有章
const chapters = $('.chapter'); //课程的标题和学习人数
let title = $('.hd>h2').text();
let number = 0; //最后返回的数据
//每个网页需要的内容的结构
let courseData = {
'title':title,
'number':number,
'videos':[]
}; chapters.each(function(item){
let chapter = $(this);
//文章标题
let chapterTitle = Trim(chapter.find('strong').text(),'g'); //每个章节的结构
let chapterdata = {
'chapterTitle':chapterTitle,
'video':[]
}; //一个网页中的所有视频
let videos = chapter.find('.video').children('li');
videos.each(function(item){
//视频标题
let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');
//视频ID
let id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({
'title':videoTitle,
'id':id
})
}); courseData.videos.push(chapterdata); }); return courseData;
} //获取上课人数
function getNumber(url){ let datas = ''; http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
}); res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
} //写入文件
function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{
if(err){
console.log(err);
}
})
} //打印信息
function printfData(coursesData){ coursesData.forEach((courseData)=>{
// console.log(`${courseData.number}人学习过${courseData.title}\n`);
writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`); courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;
// console.log(chapterTitle + '\n');
writeFile(outputFile,`\n ${chapterTitle}\n`); item.video.forEach(function(item){
// console.log(' 【' + item.id + '】' + item.title + '\n');
writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
}); }); } //所有页面爬取完后返回的Promise数组
let courseArray = []; //循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容
videosId.forEach((id)=>{
//将爬取网页完毕后返回的Promise对象加入数组
courseArray.push(getPageAsync(baseUrl + id));
//获取学习的人数
getNumber(baseNuUrl + id);
}); Promise
//当所有网页的内容爬取完毕
.all(courseArray)
.then((pages)=>{
//所有页面需要的内容
let courseData = []; //遍历每个网页提取出所需要的内容
pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
}); //给每个courseMenners.number赋值
for(let i=0;i<videosId.length;i++){
for(let j=0;j<videosId.length;j++){
if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
} //对所需要的内容进行排序
courseData.sort((a,b)=>{
return a.number > b.number;
}); //在重新将爬取内容写入文件中前,清空文件
fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{
if(err){
console.log(err)
}
});
printfData(courseData);
});
Node.js爬虫-爬取慕课网课程信息的更多相关文章
- 养只爬虫当宠物(Node.js爬虫爬取58同城租房信息)
先上一个源代码吧. https://github.com/answershuto/Rental 欢迎指导交流. 效果图 搭建Node.js环境及启动服务 安装node以及npm,用express模块启 ...
- Node.js 爬虫爬取电影信息
Node.js 爬虫爬取电影信息 我的CSDN地址:https://blog.csdn.net/weixin_45580251/article/details/107669713 爬取的是1905电影 ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- 手把手教你用Node.js爬虫爬取网站数据
个人网站 https://iiter.cn 程序员导航站 开业啦,欢迎各位观众姥爷赏脸参观,如有意见或建议希望能够不吝赐教! 开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请自行百度 ...
- node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Androi ...
- node js 爬虫爬取静态页面,
先打一个简单的通用框子 //根据爬取网页的协议 引入对应的协议, http||https var http = require('https'); //引入cheerio 简单点讲就是node中的jq ...
- node:爬虫爬取网页图片
代码地址如下:http://www.demodashi.com/demo/13845.html 前言 周末自己在家闲着没事,刷着微信,玩着手机,发现自己的微信头像该换了,就去网上找了一下头像,看着图片 ...
- Python爬虫项目--爬取自如网房源信息
本次爬取自如网房源信息所用到的知识点: 1. requests get请求 2. lxml解析html 3. Xpath 4. MongoDB存储 正文 1.分析目标站点 1. url: http:/ ...
随机推荐
- Linux学习(一)
Linux系统 1.组成部分 1.1内核负责的功能 1.1.1:系统内存管理 内存管理即管理物理内存和虚拟内存 (通过硬盘实现的,即swap space),长时间为被访问的内存块会被放到虚拟内存中,当 ...
- 2017年4月 TIOBE 编程语言排名
2017年4月 TIOBE 编程语言排名 Hack是Facebook 在三年推出的PHP方言,在2017年4月首次进入TIOBE编程语言排行榜前50位. Hack原是Facebook的内部项目,与20 ...
- 【uwp】浅谈China Daily中数据同步到One Drive的实现
新版China Daily与旧版相比新增了数据同步的功能,那这个功能具体是如何实现的呢,现在让我们来一起看看. 1.注册应用 开发者中心的应用注册就不用多说了(https://developer.mi ...
- Java使用POI为Excel打水印,调整列宽并设置Excel只读(用户不可编辑)
本文介绍在Java语言环境下,使用POI为Excel打水印的解决方案,具体的代码编写以及相关的注意事项. 需求描述: 要求通过系统下载的Excel都带上公司的水印,列宽调整为合适的宽度,并且设置为不可 ...
- 03(1) Gaussians,GMMs基础
1.单成分单变量高斯模型 2.单成分多变量高斯模型 若协方差矩阵为对角矩阵且对角线上值相等,两变量高斯分布的等值线为圆形 若协方差矩阵为对角矩阵且对角线上值不等,两变量高斯分布的等值线为椭圆形, 长轴 ...
- C语言学习第八章
今天开始学习字符串,学完以后最低要做到了解什么是字符串,以及字符串的一些应用方法,毕竟字符串还是很常见的. 简单的字符串"helloworld",这个字符串大家应该都很眼熟,学编程 ...
- java8 Lambda表达式的新手上车指南(1)
背景 java9的一再推迟发布,似乎让我们恍然想起离发布java8已经过去了三年之久,java8应该算的上java语言在历代版本中变化最大的一个版本了,最大的新特性应该算得上是增加了lambda表达式 ...
- 在C#中使用类golang信道编程(一)
BusterWood.Channels是一个在C#上实现的信道的开源库.通过使用这个类库,我们可以在C#语言中实现类似golang和goroutine的信道编程方式.在这里我们介绍3个简单的信道的例子 ...
- javascript 六种数据类型(一)
js的数据类型和常见隐式转化逻辑. 一.六种数据类型 原始类型(基本类型):按值访问,可以操作保存在变量中实际的值.原始类型汇总中null和undefined比较特殊. 引用类型:引用类型的值是保存在 ...
- 关于BSTR和SysStringLen方法的简单研究
英文的我编不下去了,所以还是先写个中文的吧, 之前遇到了SysStringLen求Bstr长度不正确的问题,试验了几次都不行的情况下我觉得可能是这个方法的bug,所以就没管. 大概的情况是这样: in ...