Workout Wednesday Redux (2017 Week 3)
I had started a “52 Vis” initiative back in 2016 to encourage folks to get practice making visualizations since that’s the only way to get better at virtually anything. Life got crazy, 52 Vis fell to the wayside and now there are more visible alternatives such as Makeover Mondayand Workout Wednesday. They’re geared towards the “T” crowd (I’m not giving a closed source and locked-in-data product any more marketing than two links) but that doesn’t mean R, Python or other open-tool/open-data communities can’t join in for the ride and learning experience.
This week’s workout is a challenge to reproduce or improve upon a chart by Matt Stiles. You should go to both (give them the clicks and eyeballs they both deserve since they did great work). They both chose a line chart, but the whole point of these exercises is to try out new things to help you learn how to communicate better. I chose to use geom_segment() to make mini-column charts since that:
- eliminates the giant rose-coloured rectangles that end up everywhere
- helps show the differences a bit better (IMO), and
- also helps highlight some of the states that have had more difficulties than others
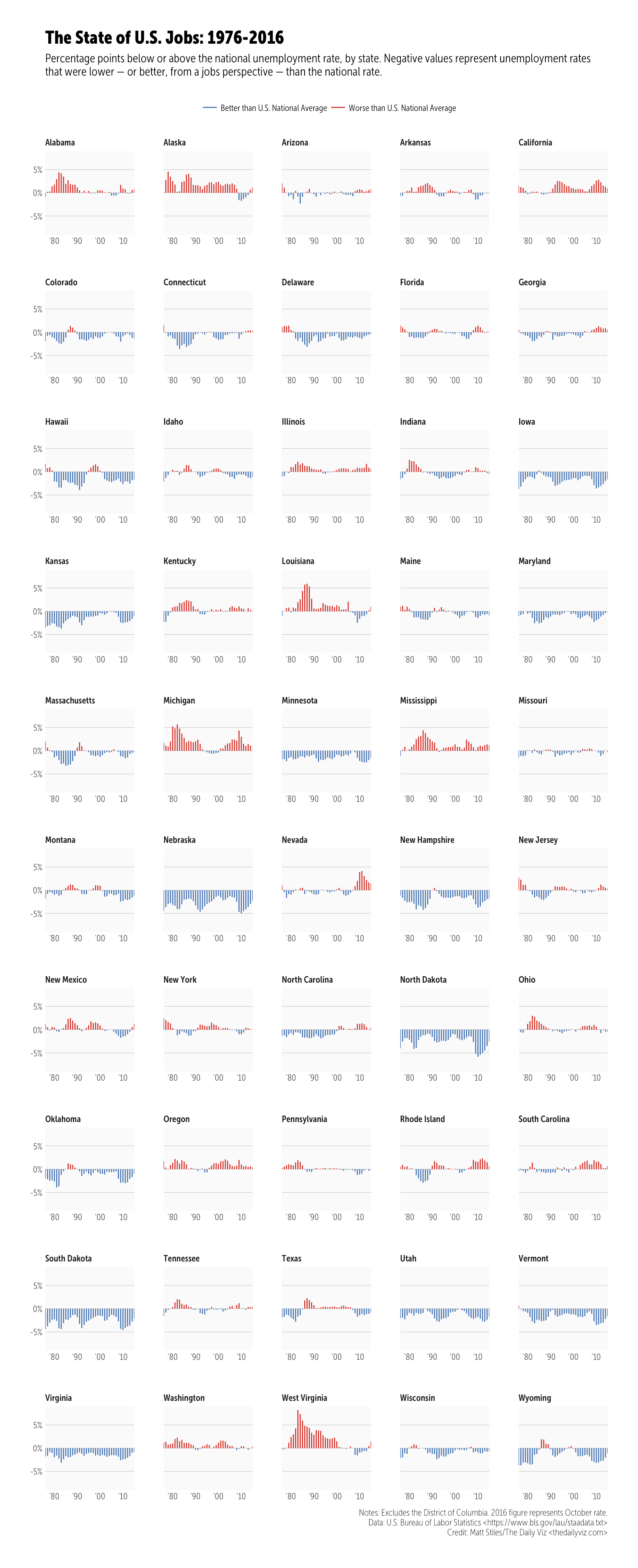
Click/tap to “embiggen”. I kept the same dimensions that Andy did but unlike Matt’s creation this is a plain ol’ PNG as I didn’t want to deal with web fonts (I’m on a Museo Sans Condensed kick at the moment but don’t have it in my TypeKit config yet). I went with official annual unemployment numbers as they may be calculated/adjusted differently (I didn’t check, but I knew that data source existed, so I used it).
One reason I’m doing this is a quote on the Workout Wednesday post:
This will be a very tedious exercise. To provide some context, this took me 2-3 hours to create. Don’t get discouraged and don’t feel like you have to do it all in one sitting. Basically, try to make yours look identical to mine.
This took me 10 minutes to create in R:
#' ---
#' output:
#' html_document:
#' keep_md: true
#' ---
#+ message=FALSE
library(ggplot2)
library(hrbrmisc)
library(readxl)
library(tidyverse)
# Use official BLS annual unemployment data vs manually calculating the average
# Source: https://data.bls.gov/timeseries/LNU04000000?years_option=all_years&periods_option=specific_periods&periods=Annual+Data
read_excel("~/Data/annual.xlsx", skip=10) %>%
mutate(Year=as.character(as.integer(Year)), Annual=Annual/100) -> annual_rate
# The data source Andy Kriebel curated for you/us: https://1drv.ms/x/s!AhZVJtXF2-tD1UVEK7gYn2vN5Hxn #ty Andy!
read_excel("~/Data/staadata.xlsx") %>%
left_join(annual_rate) %>%
filter(State != "District of Columbia") %>%
mutate(
year = as.Date(sprintf("%s-01-01", Year)),
pct = (Unemployed / `Civilian Labor Force Population`),
us_diff = -(Annual-pct),
col = ifelse(us_diff<0,
"Better than U.S. National Average",
"Worse than U.S. National Average")
) -> df
credits <- "Notes: Excludes the District of Columbia. 2016 figure represents October rate.\nData: U.S. Bureau of Labor Statistics <https://www.bls.gov/lau/staadata.txt>\nCredit: Matt Stiles/The Daily Viz <thedailyviz.com>"
#+ state_of_us, fig.height=21.5, fig.width=8.75, fig.retina=2
ggplot(df, aes(year, us_diff, group=State)) +
geom_segment(aes(xend=year, yend=0, color=col), size=0.5) +
scale_x_date(expand=c(0,0), date_labels="'%y") +
scale_y_continuous(expand=c(0,0), label=scales::percent, limit=c(-0.09, 0.09)) +
scale_color_manual(name=NULL, expand=c(0,0),
values=c(`Better than U.S. National Average`="#4575b4",
`Worse than U.S. National Average`="#d73027")) +
facet_wrap(~State, ncol=5, scales="free_x") +
labs(x=NULL, y=NULL, title="The State of U.S. Jobs: 1976-2016",
subtitle="Percentage points below or above the national unemployment rate, by state. Negative values represent unemployment rates\nthat were lower — or better, from a jobs perspective — than the national rate.",
caption=credits) +
theme_hrbrmstr_msc(grid="Y", strip_text_size=9) +
theme(panel.background=element_rect(color="#00000000", fill="#f0f0f055")) +
theme(panel.spacing=unit(0.5, "lines")) +
theme(plot.subtitle=element_text(family="MuseoSansCond-300")) +
theme(legend.position="top")Swap out ~/Data for where you stored the files.
The “weird” looking comments enable me to spin the script and is pretty much just the inverse markup for knitr R Markdown documents. As the comments say, you should really thank Andy for curating the BLS data for you/us.
If I really didn’t pine over aesthetics it would have taken me 5 minutes (most of that was waiting for re-rendering). Formatting the blog post took much longer. Plus, I can update the data source and re-run this in the future without clicking anything. This re-emphasizes a caution I tell my students: beware of dragon droppings (“drag-and-drop data science/visualization tools”).
Hopefully you presently follow or will start following Workout Wednesday and Makeover Monday and dedicate some time to hone your skills with those visualization katas.
转自:https://rud.is/b/2017/01/18/workout-wednesday-redux-2017-week-3/
Workout Wednesday Redux (2017 Week 3)的更多相关文章
- January 25 2017 Week 4 Wednesday
In every triumph, there's a lot of try. 每个胜利背后都有许多尝试. There's a lot of try behind every success, and ...
- November 15th, 2017 Week 46th Wednesday
Of all the tribulations in this world, boredom is the one most hard to bear. 所有的苦难中,无聊是最难以忍受的. When ...
- November 08th, 2017 Week 45th Wednesday
Keep your face to the sunshine and you cannot see the shadow. 始终面朝阳光,我们就不会看到黑暗. I love sunshine, but ...
- November 01st, 2017 Week 44th Wednesday
People always want to lead an active life, and is not it? 人们总要乐观生活,不是吗? Be active, and walk towards ...
- October 25th, 2017 Week 43rd Wednesday
Perseverance is not a long race; it is many short races one after another. 坚持不是一个长跑,她是很多一个接一个的短跑. To ...
- October 18th 2017 Week 42nd Wednesday
Only someone who is well-prepared has the opportunity to improvise. 只有准备充分的人才能够尽兴表演. From the first ...
- October 11th 2017 Week 41st Wednesday
If you don't know where you are going, you might not get there. 如果你不知道自己要去哪里,你可能永远到不了那里. The reward ...
- October 04th 2017 Week 40th Wednesday
We teach people how to remember, we never teach them how to grow. 我们教会人们如何记忆,却从来不教他们如何成长. Without pr ...
- September 27th 2017 Week 39th Wednesday
We both look up at the same stars, yet we see such different things. 我们仰望同一片星空,却看见了不同的事物. Looking up ...
随机推荐
- linux里的那么点东西(持续更新)
作为一个程序猿的确是应该上的了windows,下的了linux的.但是由于没有对linux产生一些刚性的需求,所以使用的次数还是略少,对一些基本的concept和command还是有一些生疏.借着最近 ...
- net.sz.framework 框架 登录服务器架构 单服2 万 TPS(QPS)
前言 无论我们做什么系统,95%的系统都离不开注册,登录: 而游戏更加关键,频繁登录,并发登录,导量登录:如果登录承载不起来,那么游戏做的再好,都是徒然,进不去啊: 序言 登录所需要的承载,包含程序和 ...
- lua 变量
lua 变量 类型 全局变量 lua 变量默认均为全局变量 打印一个未定义的变量输出为 nil 示例代码 a = 1 print(a, b) 局部变量 lua 变量默认均为全局变量, 除非变量前显式声 ...
- Linux--谈父子进程执行过程
fork函数用于从已存在进程中创建一个新进程,新进程成为子进程,原进程成为父进程.这两个进程分别返回他们各自的返回值, 其中父进程的返回值是子进程的进程号,子进程则返回0,因此返回值大于0标识父进程, ...
- Linux - 进程调度算法
进程调度: 无论是在批处理系统还是分时系统中,用户进程数一般都多于处理机数.这将导致它们互相争夺处理机.另外,系统进程也同样需要使用处理机. 这就要求进程调度程序按一定的策略,动态地把处理机分配给处于 ...
- Ajax (AppServ服务器练习)
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- Js 网页版扫雷游戏代码实现
这个游戏是自己在大约一年前联系js熟练度时做的,用的都是基础的东西,最近比较忙没时间整理.直接发给大家,有兴趣的可以看一下.欢迎大家提出建议.如果你有什么新的想法也可以提出来,或者你并不擅长编程.你想 ...
- 微信公众号、H5、APP三者各有什么优势?
昨天给大家分享了一个现在很热的H5,众所周知,当下H5手机网站.微信公众号.APP这三种载体都越来越火了,而且三者都有各自的一些优势和劣势. HTML5(H5) H5之所以能引发如此广泛的效应,根本在 ...
- 【算法系列学习】[kuangbin带你飞]专题十二 基础DP1 E - Super Jumping! Jumping! Jumping!
https://vjudge.net/contest/68966#problem/E http://blog.csdn.net/to_be_better/article/details/5056334 ...
- 蓝桥杯-组素数-java
/* (程序头部注释开始) * 程序的版权和版本声明部分 * Copyright (c) 2016, 广州科技贸易职业学院信息工程系学生 * All rights reserved. * 文件名称: ...