Hive HQL学习
HQL学习
1.hive的数据类型

2.hive_DDL
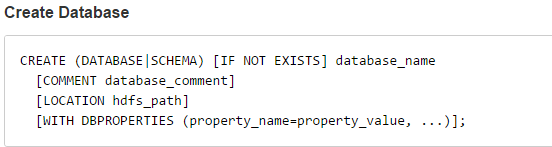


 Default数据库,默认的,优先级相对于其他数据库是最高的
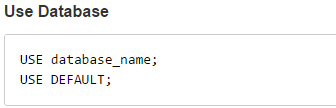
Default数据库,默认的,优先级相对于其他数据库是最高的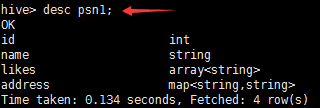
2.2重点:创建表_内部表_外部表
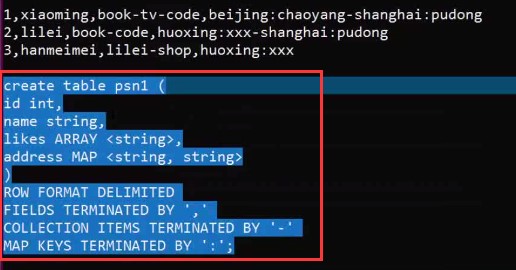
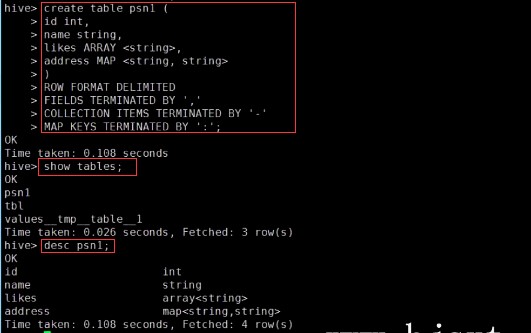
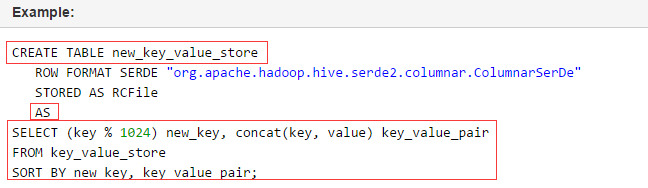
– create table person(– id int,– name string,– age int,– likes array<string>,– address map<string,string>–)– row format delimited– FIELDS TERMINATED BY ','– COLLECTION ITEMS TERMINATED BY '-'– MAP KEYS TERMINATED BY ':'– lines terminated by '\n';–Select address[‘city’] from person where name=‘zs’




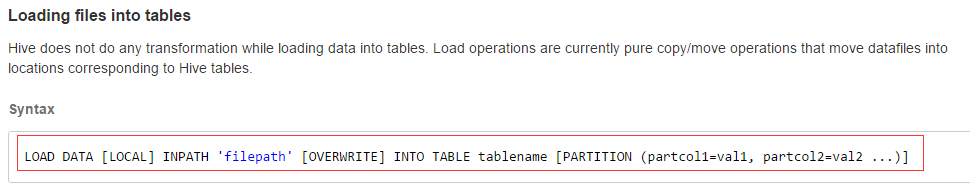
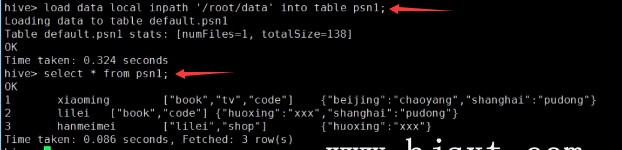
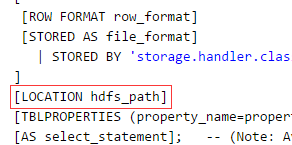
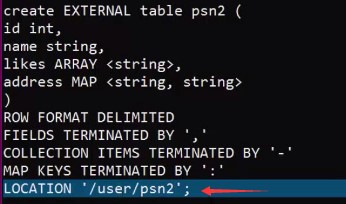


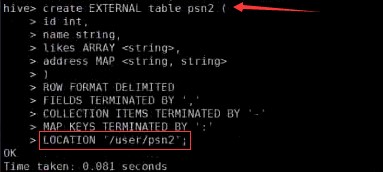
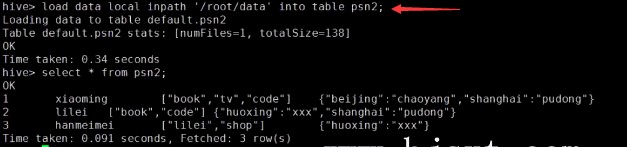

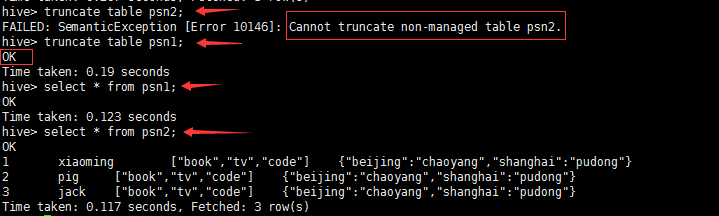
删除内部表和外部表的区别?
3.hive_分区
1.分区表什么时候会用?
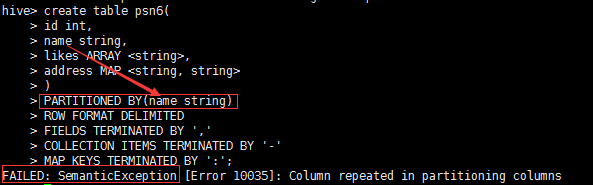
2.分区表的创建,添加数据,查看对应分区下的数据,修改分区、删除分区
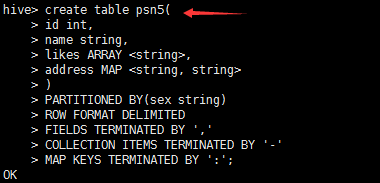





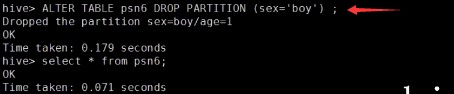
---分区_指定两个分区字段create table psn5(id int,name string,likes ARRAY <string>,address MAP <string, string>)PARTITIONED BY(sex string,age int)ROW FORMAT DELIMITEDFIELDS TERMINATED BY ','COLLECTION ITEMS TERMINATED BY '-'MAP KEYS TERMINATED BY ':';---创建分区后,再进行插入数据,就需要指定分区字段load data local inpath '/root/data' into table psn5 partition (sex='boy',age=1);
4.hive_DML
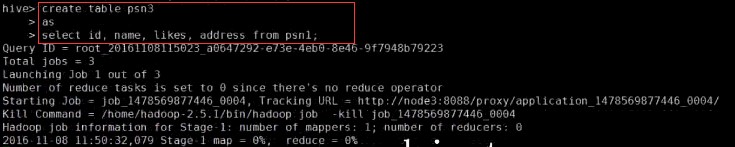
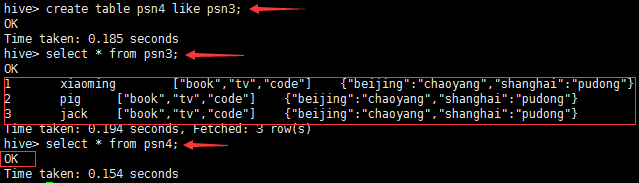
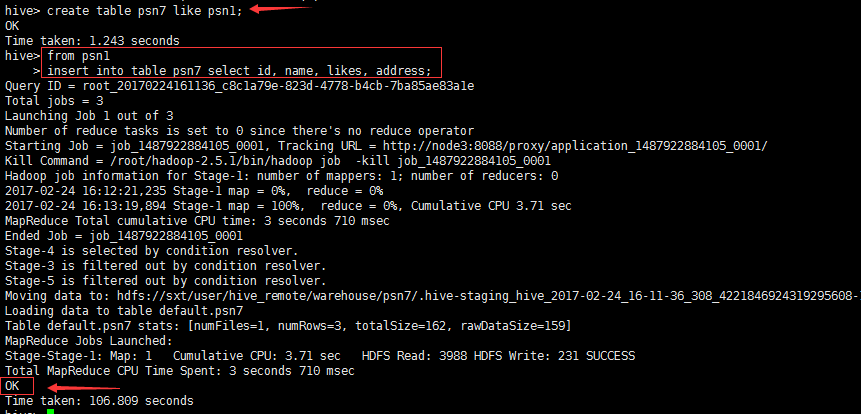
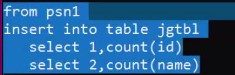
create table psn7 like psn1;from psn1insert into table psn7 select id, name, likes, address
思考一:hive其实就是写sql来分析hdfs上的数据,那么问题来了,以上这种方式做什么用?
思考二:为什么要将from放在上面呢?
附件列表
Hive HQL学习的更多相关文章
- Hive入门学习随笔(一)
Hive入门学习随笔(一) ===什么是Hive? 它可以来保存我们的数据,Hive的数据仓库与传统意义上的数据仓库还有区别. Hive跟传统方式是不一样的,Hive是建立在Hadoop HDFS基础 ...
- hive的学习入门(飞进数据仓库的小蜜蜂)
前言 hive是构建在Hadoop上的数据仓库平台,其设计目标是:使Hadoop上的数据操作与传统的SQL结合,让熟悉sql的开发人员能够轻松的像Hadoop平台迁移. Hive是Facebook的信 ...
- Hive入门学习
Hive学习之路 (一)Hive初识 目录 Hive 简介 什么是Hive 为什么使用 Hive Hive 特点 Hive 和 RDBMS 的对比 Hive的架构 1.用户接口: shell/CLI, ...
- Hive深入学习--应用场景及架构原理
Hive背景介绍 Hive最初是Facebook为了满足对海量社交网络数据的管理和机器学习的需求而产生和发展的.互联网现在进入了大数据时代,大数据是现在互联网的趋势,而hadoop就是大数据时代里的核 ...
- Hive 体系学习
Hive简介 Hive是一个基于Hadoop的数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并使用HQL作为查询接口.HDFS作为存储底层.MapReduce作为执行层,将HQL语句转换成M ...
- 60分钟内从零起步驾驭Hive实战学习笔记
本博文的主要内容是: 1. Hive本质解析 2. Hive安装实战 3. 使用Hive操作搜索引擎数据实战 SparkSQL前身是Shark,Shark强烈依赖于Hive.Spark原来没有做SQL ...
- Hive基础学习
Hive 学习记录Hive介绍:Hive 是起源于Facebook,使得Hadoop进行SQL查询成为可能,进而使得非程序员也可以进进行对其使用:它是一种数据仓库工具,将结构化的数据文件 映射为一张数 ...
- Hive入门学习--HIve简介
现在想要应聘大数据分析或者数据挖掘岗位,很多都需要会使用Hive,Mapreduce,Hadoop等这些大数据分析技术.为了充实自己就先从简单的Hive开始吧.接下来的几篇文章是记录我如何入门学习Hi ...
- hive入门学习线路指导
hive被大多数企业使用,学习它,利于自己掌握企业所使用的技术,这里从安装使用到概念.原理及如何使用遇到的问题,来讲解hive,希望对大家有所帮助.此篇内容较多:看完之后需要达到的目标1.hive是什 ...
随机推荐
- mybatis源码分析(一)
mybatis源码分析(sqlSessionFactory生成过程) 1. mybatis框架在现在各个IT公司的使用不用多说,这几天看了mybatis的一些源码,赶紧做个笔记. 2. 看源码从一个d ...
- npm lodash
在数据操作时,Lodash 就是我的弹药库,不管遇到多复杂的数据结构都能用一些函数轻松拆解. ES6 中也新增了诸多新的对象函数,一些简单的项目中 ES6 就足够使用了,但还是会有例外的情况引用了少数 ...
- input选择框样式修改与自定义
html自带的选择框样式不好看,并且在ios设备上丑的罚款.所以一般都是自定义样式: 原理:将原来默认的input选择框隐藏,然后控制label的:before与:after,配合矢量图标或者图片来实 ...
- dJango前言之 socketserver源码
socketserver源码分析: ftpserver=socketserver.ThreadingTCPServer(('127.0.0.1',8080),FtpServer) ftpserver. ...
- 【精选】Nginx模块Lua-Nginx-Module学习笔记(二)Lua指令详解(Directives)
源码地址:https://github.com/Tinywan/Lua-Nginx-Redis Nginx与Lua编写脚本的基本构建块是指令. 指令用于指定何时运行用户Lua代码以及如何使用结果. 下 ...
- iOS微信运动 刷分
修改 iOS微信运动的数据 很简单,这里记录下实现步骤. 首先要安装Theos,具体安装步骤就不说了.网上很多. 大体安装步骤: sudo brew install dpkg sudo brew i ...
- 初读"Thinking in Java"读书笔记之第二章 --- 一切都是对象
用引用操纵对象 Java里一切都被视为对象,通过操纵对象的一个"引用"来操纵对象. 例如, 可以将遥控器视为引用,电视机视为对象. 创建一个引用,不一定需要有一个对象与之关联,但此 ...
- linux下centos6.8相关配置,以及音频相关配置
一:安装上传下载命令 1:cd /tmp 2:wget http://www.ohse.de/uwe/releases/lrzsz-0.12.20.tar.gz 3:tar zxvf lrzsz-0. ...
- 解决CentOS7安装Tomcat不能被外部访问的问题
在CentOS7安装了Tomcat,在服务器内部使用火狐浏览器通过localhost:8080是可以访问的,但是不能被外部访问,主要原因是因为防火墙的存在,导致端口不能被访问.CentOS是使用fir ...
- eslint 的基本配置介绍
eslint 这个代码规则,是在用webpack +vue-cli这个脚手架时候接触的,默认的规则可能不太习惯我们日常平时的代码开发,需要对这个规则稍加改造. 下面的是 eslintrc.js的基本规 ...