【原】 twemproxy ketama一致性hash分析
转贴请注明原帖位置:http://www.cnblogs.com/basecn/p/4288456.html
测试Twemproxy集群,双主双活
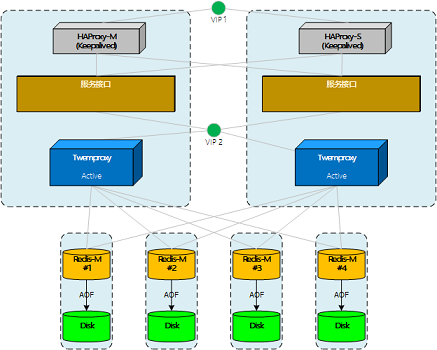
向twemproxy集群做写操作时,发现key的分布不太理想。在测试节点故障时,也发现一些和预想不太一样的地方。
1、Key的一致性Hash
当尝试以a001,a002这样有规律且的key值写入的时候,在4节点的集群环境中,key主要分布在其中的2台节点,另外两台分配极少。对于一些应用来说,key值可能根据一定规则生成,所以有被定向分配的可能。
解决办法在key中使用hash_key:{},hask_key使用8位随机数,测试结果分布的比较满意。
测试4节点中key的分布:
2: 10761
3: 8596
4: 14382
由于ketama的算法仍是使用了md5签名(具体后面说),又特意观察了比如有序数字生成的md5序列,结果并没有出现明显的有序或连序值。所以只能建议不使用连续的数据结尾key做一致性hash key。
2、ketama算法
twemproxy源码下载:https://github.com/twitter/twemproxy,命令:git clone https://github.com/twitter/twemproxy
关于ketama算法的代码在nc_ketama.c文件中,主要是四个方法:
- ketama_hash 计算某个主机,某个point的hash值
- ketama_item_cmp 比较两个连续区的值,用于在ketama_update 方法中排序
- ketama_update 更新server-pool的分配策略
- ketama_dispatch 找出给定hash值所在的连续区
2.1 连续区
说一下连续区(continuum),参考下图。想象所有md5的值构成下面完整的“环”(没有起点),那么所有md5结果值在环上都有一个固定的位置。
按ketama的算法,在这个环上创建服务器数*160个点,这些点把环分成了同等数量的段。
那么,被插入数据的md5值也一定会落到环的某个区间,以此来判断数据应被写入哪台服务器。
 参考:理想化的Redis集群
参考:理想化的Redis集群
2.2 如何生成ketama_hash
再来看服务器+点的hash值是如何生成的:
alignment的值固定是4,ketama_hash是对由server名+索引组成的md5签名,从第16位开始取值,再重组一个32位值。
static uint32_t
ketama_hash(const char *key, size_t key_length, uint32_t alignment)
{
unsigned char results[16]; md5_signature((unsigned char*)key, key_length, results); return ((uint32_t) (results[3 + alignment * 4] & 0xFF) << 24)
| ((uint32_t) (results[2 + alignment * 4] & 0xFF) << 16)
| ((uint32_t) (results[1 + alignment * 4] & 0xFF) << 8)
| (results[0 + alignment * 4] & 0xFF);
}
下面是调用ketama_hash的代码:
for (x = ; x < pointer_per_hash; x++) {
value = ketama_hash(host, hostlen, x);
pool->continuum[continuum_index].index = server_index;
pool->continuum[continuum_index++].value = value;
}
每个服务器被分成160个point点,由服务器名+索引组成host值,x值等于160/索引。
这样计算出的服务器各点的值并不是有序的,所以进行排序。
qsort(pool->continuum, pool->ncontinuum, sizeof(*pool->continuum), ketama_item_cmp);
排序后的点值是连续的,但同一服务器的点并不一定连续。这时,所有的值构成了用于一致性hash的环。
2.3、分配Key
由ketama_dispatch实现key值的分配。
可见方法中使用二分法找到一个值在环中的对应区域。
uint32_t
ketama_dispatch(struct continuum *continuum, uint32_t ncontinuum, uint32_t hash)
{
struct continuum *begin, *end, *left, *right, *middle; ASSERT(continuum != NULL);
ASSERT(ncontinuum != ); begin = left = continuum;
end = right = continuum + ncontinuum; while (left < right) {
middle = left + (right - left) / ;
if (middle->value < hash) {
left = middle + ;
} else {
right = middle;
}
}
if (right == end) {
right = begin;
}
return right->index;
}
3、服务器的故障处理
从集群中摘除节点时,ketama的算法不会重新计算"环"。当需要写入故障节点时,会抛出异常。
仔细想一下是合理的,因为摘除的节点持有一部分数据,一般来说是需要恢复的,这是一个前提。
我们假设twemproxy可以感知节点故障,并重新计算分配策略。那么,故障后又有新的数据写入。这时,一部分原本要写入故障节点的数据会被分配到其它节点上。
随后,故障节点恢复,twemproxy又重新调整了分配策略。那么,后写入的那部分数据就不会再被找到(这个有点像内存泄露)。
nc_ketama.c 完整代码
/*
* twemproxy - A fast and lightweight proxy for memcached protocol.
* Copyright (C) 2011 Twitter, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ #include <stdio.h>
#include <stdlib.h>
#include <math.h> #include <nc_core.h>
#include <nc_server.h>
#include <nc_hashkit.h> #define KETAMA_CONTINUUM_ADDITION 10 /* # extra slots to build into continuum */
#define KETAMA_POINTS_PER_SERVER 160 /* 40 points per hash */
#define KETAMA_MAX_HOSTLEN 86 static uint32_t
ketama_hash(const char *key, size_t key_length, uint32_t alignment)
{
unsigned char results[]; md5_signature((unsigned char*)key, key_length, results); return ((uint32_t) (results[ + alignment * ] & 0xFF) << )
| ((uint32_t) (results[ + alignment * ] & 0xFF) << )
| ((uint32_t) (results[ + alignment * ] & 0xFF) << )
| (results[ + alignment * ] & 0xFF);
} static int
ketama_item_cmp(const void *t1, const void *t2)
{
const struct continuum *ct1 = t1, *ct2 = t2; if (ct1->value == ct2->value) {
return ;
} else if (ct1->value > ct2->value) {
return ;
} else {
return -;
}
} rstatus_t
ketama_update(struct server_pool *pool)
{
uint32_t nserver; /* # server - live and dead */
uint32_t nlive_server; /* # live server */
uint32_t pointer_per_server; /* pointers per server proportional to weight */
uint32_t pointer_per_hash; /* pointers per hash */
uint32_t pointer_counter; /* # pointers on continuum */
uint32_t pointer_index; /* pointer index */
uint32_t points_per_server; /* points per server */
uint32_t continuum_index; /* continuum index */
uint32_t continuum_addition; /* extra space in the continuum */
uint32_t server_index; /* server index */
uint32_t value; /* continuum value */
uint32_t total_weight; /* total live server weight */
int64_t now; /* current timestamp in usec */ ASSERT(array_n(&pool->server) > ); now = nc_usec_now();
if (now < ) {
return NC_ERROR;
} /*
* Count live servers and total weight, and also update the next time to
* rebuild the distribution
*/
nserver = array_n(&pool->server);
nlive_server = ;
total_weight = ;
pool->next_rebuild = 0LL;
for (server_index = ; server_index < nserver; server_index++) {
struct server *server = array_get(&pool->server, server_index); if (pool->auto_eject_hosts) {
if (server->next_retry <= now) {
server->next_retry = 0LL;
nlive_server++;
} else if (pool->next_rebuild == 0LL ||
server->next_retry < pool->next_rebuild) {
pool->next_rebuild = server->next_retry;
}
} else {
nlive_server++;
} ASSERT(server->weight > ); /* count weight only for live servers */
if (!pool->auto_eject_hosts || server->next_retry <= now) {
total_weight += server->weight;
}
} pool->nlive_server = nlive_server; if (nlive_server == ) {
log_debug(LOG_DEBUG, "no live servers for pool %"PRIu32" '%.*s'",
pool->idx, pool->name.len, pool->name.data); return NC_OK;
}
log_debug(LOG_DEBUG, "%"PRIu32" of %"PRIu32" servers are live for pool "
"%"PRIu32" '%.*s'", nlive_server, nserver, pool->idx,
pool->name.len, pool->name.data); continuum_addition = KETAMA_CONTINUUM_ADDITION;
points_per_server = KETAMA_POINTS_PER_SERVER;
/*
* Allocate the continuum for the pool, the first time, and every time we
* add a new server to the pool
*/
if (nlive_server > pool->nserver_continuum) {
struct continuum *continuum;
uint32_t nserver_continuum = nlive_server + continuum_addition;
uint32_t ncontinuum = nserver_continuum * points_per_server; continuum = nc_realloc(pool->continuum, sizeof(*continuum) * ncontinuum);
if (continuum == NULL) {
return NC_ENOMEM;
} pool->continuum = continuum;
pool->nserver_continuum = nserver_continuum;
/* pool->ncontinuum is initialized later as it could be <= ncontinuum */
} /*
* Build a continuum with the servers that are live and points from
* these servers that are proportial to their weight
*/
continuum_index = ;
pointer_counter = ;
for (server_index = ; server_index < nserver; server_index++) {
struct server *server;
float pct; server = array_get(&pool->server, server_index); if (pool->auto_eject_hosts && server->next_retry > now) {
continue;
} pct = (float)server->weight / (float)total_weight;
pointer_per_server = (uint32_t) ((floorf((float) (pct * KETAMA_POINTS_PER_SERVER / * (float)nlive_server + 0.0000000001))) * );
pointer_per_hash = ; log_debug(LOG_VERB, "%.*s:%"PRIu16" weight %"PRIu32" of %"PRIu32" "
"pct %0.5f points per server %"PRIu32"",
server->name.len, server->name.data, server->port,
server->weight, total_weight, pct, pointer_per_server); for (pointer_index = ;
pointer_index <= pointer_per_server / pointer_per_hash;
pointer_index++) { char host[KETAMA_MAX_HOSTLEN]= "";
size_t hostlen;
uint32_t x; hostlen = snprintf(host, KETAMA_MAX_HOSTLEN, "%.*s-%u",
server->name.len, server->name.data,
pointer_index - ); for (x = ; x < pointer_per_hash; x++) {
value = ketama_hash(host, hostlen, x);
pool->continuum[continuum_index].index = server_index;
pool->continuum[continuum_index++].value = value;
}
}
pointer_counter += pointer_per_server;
} pool->ncontinuum = pointer_counter;
qsort(pool->continuum, pool->ncontinuum, sizeof(*pool->continuum),
ketama_item_cmp); for (pointer_index = ;
pointer_index < ((nlive_server * KETAMA_POINTS_PER_SERVER) - );
pointer_index++) {
if (pointer_index + >= pointer_counter) {
break;
}
ASSERT(pool->continuum[pointer_index].value <=
pool->continuum[pointer_index + ].value);
} log_debug(LOG_VERB, "updated pool %"PRIu32" '%.*s' with %"PRIu32" of "
"%"PRIu32" servers live in %"PRIu32" slots and %"PRIu32" "
"active points in %"PRIu32" slots", pool->idx,
pool->name.len, pool->name.data, nlive_server, nserver,
pool->nserver_continuum, pool->ncontinuum,
(pool->nserver_continuum + continuum_addition) * points_per_server); return NC_OK;
} uint32_t
ketama_dispatch(struct continuum *continuum, uint32_t ncontinuum, uint32_t hash)
{
struct continuum *begin, *end, *left, *right, *middle; ASSERT(continuum != NULL);
ASSERT(ncontinuum != ); begin = left = continuum;
end = right = continuum + ncontinuum; while (left < right) {
middle = left + (right - left) / ;
if (middle->value < hash) {
left = middle + ;
} else {
right = middle;
}
} if (right == end) {
right = begin;
} return right->index;
}
【原】 twemproxy ketama一致性hash分析的更多相关文章
- [转] twemproxy ketama一致性hash分析
评注:提到HAProxy业务层proxy, twemproxy存储的proxy. 其中还提到了ketama算法的实现源码 转自:http://www.cnblogs.com/basecn/p/4288 ...
- 一致性Hash 分析和实现
一致性Hash 分析和实现 ---title: 1.一致性Hashdate: 2018-02-05 12:03:22categories:- 一致性Hash--- 一下分析来源于网络总结:算法参照自己 ...
- 一致性Hash算法(KetamaHash)的c#实现
Consistent Hashing最大限度地抑制了hash键的重新分布.另外要取得比较好的负载均衡的效果,往往在服务器数量比较少的时候需要增加虚拟节点来保证服务器能均匀的分布在圆环上.因为使用一般的 ...
- SOFA 源码分析 — 负载均衡和一致性 Hash
前言 SOFA 内置负载均衡,支持 5 种负载均衡算法,随机(默认算法),本地优先,轮询算法,一致性 hash,按权重负载轮询(不推荐,已被标注废弃). 一起看看他们的实现(重点还是一致性 hash) ...
- OpenStack_Swift源代码分析——Ring基本原理及一致性Hash算法
1.Ring的基本概念 Ring是swfit中最重要的组件.用于记录存储对象与物理位置之间的映射关系,当用户须要对Account.Container.Object操作时,就须要查询相应的Ring文件( ...
- 分布式缓存技术memcached学习(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到“分布式一致性hash算法”这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前,我们先来了解一下这几 ...
- memcache的一致性hash算法使用
一.概述 1.我们的memcache客户端(这里我看的spymemcache的源码),使用了一致性hash算法ketama进行数据存储节点的选择.与常规的hash算法思路不同,只是对我们要存储数据的k ...
- 一致性Hash算法在Redis分布式中的使用
由于redis是单点,但是项目中不可避免的会使用多台Redis缓存服务器,那么怎么把缓存的Key均匀的映射到多台Redis服务器上,且随着缓存服务器的增加或减少时做到最小化的减少缓存Key的命中率呢? ...
- 分布式缓存技术memcached学习系列(四)—— 一致性hash算法原理
分布式一致性hash算法简介 当你看到"分布式一致性hash算法"这个词时,第一时间可能会问,什么是分布式,什么是一致性,hash又是什么.在分析分布式一致性hash算法原理之前, ...
随机推荐
- UI:MVC设计模式
不是因为有些事情难以做到,我们才失去自信:而是因为我们失去了自信,有些事情才显得难以做到.自信的第一步就是去尝试.不是因为有希望才坚持,而是因为坚持才有了希望.坚持尝试,就有可能成功.加油! Xcod ...
- Vagrant 快速入门
1. Vagrant功能: Vagrant uses Oracle’s VirtualBox to build configurable, lightweight, and portable virt ...
- 开发过程中常用的Linux命令
做Java开发好几年了,部署JavaWeb到服务器上,一般都选择Linux,Linux作为服务器真是不二之选,高性能,只要熟悉Linux,操作快捷,效率很高. 总结一下工作中常用的Linux命令备忘: ...
- C#的WinForm中制作饼状图和柱状图
using System; using System.IO;//用于文件存取 using System.Data;//用于数据访问 using System.Drawing;//提供画GDI+图形的基 ...
- Ubuntu 改动bash
ubuntu下/bin/sh的指向 ubuntu 下 /bin/sh 默认是dash,用ll /bin/sh就能够看出来sh是指向dash的链接.有时候会导致使用bash脚本的时候出问题. 假 ...
- FluorineFx 播放FLV 时堆棧溢出解决 FluorineFx NetStream.play 并发时,无法全部连接成功的解决办法
http://25swf.blogbus.com/tag/FluorineFx/ http://www.doc88.com/p-7002019966618.html 基于Red5的视频监控系统的研究 ...
- Python基础教程之第2章 列表和元组
D:\>python Python 2.7.5 (default, May 15 2013, 22:43:36) [MSC v.1500 32 bit (Intel)] on win32 Typ ...
- 【UML】具体解释六种关系
UML中包括六中关系.各自是:关联(Association).聚合(Aggregation).组合(Composition).泛化(Generalization).依赖(Dependency).实现( ...
- IOS触摸事件和手势识别
IOS触摸事件和手势识别 目录 概述 触摸事件 手势识别 概述 为了实现一些新的需求,我们常常需要给IOS添加触摸事件和手势识别 触摸事件 触摸事件的四种方法 -(void)touchesBegan: ...
- IPC——信号量
Linux进程间通信——使用信号量 这篇文章将讲述别一种进程间通信的机制——信号量.注意请不要把它与之前所说的信号混淆起来,信号与信号量是不同的两种事物.有关信号的更多内容,可以阅读我的另一篇文章:L ...