mongodb 3.0 WT 引擎性能测试(转载)
网上转载来的测试,仅供参考。原文地址:http://www.mongoing.com/benchmark_3_0
类机器。
- 测试均在单机器,单实例的情况下进行。
- 机器A(cache 12G,即内存>数据):
- 数据:{_id:默认,Name:"Edison",Num:随机数}
- 使用引擎:WiredTiger
- 索引:除了_id的索引外,Num字段也有索引。
OS:centos6.5 64
Cpu:8核 E5 2407 2.4GHZ
RAM:16G
Disk:300G SATA*2 RAID 1
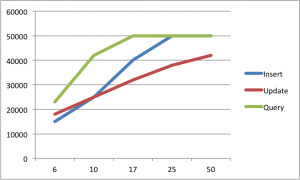
(点击查看大图)
- Insert:
同时连接数 op/s
6 15K
10 25K
17 40K
25 50K
50 50K
- Update(表2亿条数据):
同时连接数 op/s
6 18K
10 25K
17 32K
25 38K
50 42K
- Query(表2亿条数据):
同时连接数 op/s
6 23K
10 42K
17 50K
25 50K
50 50K
- TPS(表2亿条数据):
同时连接数 query/s insert/s
6 15K 15K
10 20K 20K
17 21K 21K
25 23K 23K
50 23K 23K
- 机器B(cache 12G,即内存>数据):
- 数据:{_id:默认,Name:"Edison",Num:随机数}
- 使用引擎:WiredTiger
- 索引:除了_id的索引外,Num字段也有索引。
OS:centos6.5 64
Cpu:24核 E5 2403 1.8GHZ
RAM:64G
Disk:300G SSD RAID 10
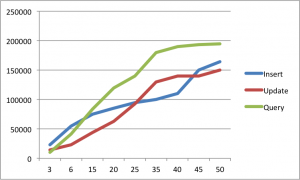
(点击查看大图)
- Insert:
同时连接数 op/s
3 23K
4 50K
6 55K
8 65K
14 75K
20 85K
30 95K
35 100K
40 110K
45 150K
50 164K
- Update(表2亿条数据):
同时连接数 op/s
3 14K
6 23K
15 44K
20 63K
25 93K
35 130K
40 140K
45 140K
50 150K
- Query(表2亿条数据):
同时连接数 op/s
3 10K
6 41K
15 84K
20 120K
25 140K
35 180K
40 190K
45 193K
50 195K
- TPS(表2亿条数据):
同时连接数 query/s insert/s
3 10K 10K
6 31K 31K
12 44K 44K
25 60K 60K
35 75K 75K
50 75K 75K
下面在机器B上测试内存不足装下所有数据(只能装下index/index都无法全部装下)的情况
内存装下所有数据:
- Query(表3亿条数据):
同时连接数 op/s
3 20K
5 40K
8 58K
12 80K
15 90K
22 130K
27 170K
35 180K
50 195K
内存仅装得下index:
- cache:data = 4:10
- Query(表3亿条数据):
同时连接数 op/s
3 8K
5 10K
8 16K
12 20K
15 25K
22 32K
27 40K
35 48K
50 57K
内存连index都无法全部放下:
- cache:data = 1:10
- Query(表3亿条数据):
同时连接数 op/s
3 3.4K
5 4.5K
8 9.3K
12 11K
15 14K
22 20K
27 24K
35 25K
50 34K
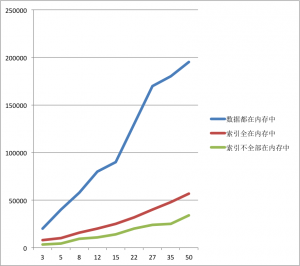
(点击查看大图)
索引全在内存中:
cache:data为4:10
索引不全在内存中
cache:data为1:10
- 内存足够大的情况下,CPU是瓶颈,CPU表现越好的机器,MongoDB性能越好。
mongodb官方的报告:
http://www.mongoing.com/archives/862
前言:
MongoDB 3.0的主要侧重点是提高性能,尤其是写性能和对硬件资源的利用率 。为了展示我们在3.0 中取得的成果和如何来应用这些新的改善,我们接下来将发布一系列博客来比较MongoDB 2.6和3.0的性能。
就像所有的基准测试一样,这些测试结果不一定适用于你的场景。 MongoDB的使用场景是多种多样的,采用那种能够反映你应用程序需求和你将要用来部署的硬件的性能测试是至关重要的。正因如此,目前并没有一个"标准的"测试程序可以告诉你哪个技术是最适合你的应用程序 。只有你的需求,你的数据,你的基础设施可以告诉你你所需要知道的。
为了帮助我们衡量性能,我们已经与社区合作采用了上百种不同的测试。这些测试反映了用户所开发的多种多样的应用程序,和用来部署这些应用的不断衍变的环境。
YCSB被一些机构用来作为对几个不同数据库的性能测试的一个工具。YCSB功能是相当有限的,并不一定能够告诉你所有你想了解的关于你应用程序性能方面的信息。当然,YCSB还是相当流行的,并且MongoDB和其他一些数据库系统的用户也对此比较熟悉。 在这篇文章内我们会比较MongoDB2.6和3.0的YCSB测试结果。
并发量:
在YCSB测试中,MongoDB3.0在多线程、批量插入场景下较之于MongoDB2.6有大约7倍的增长。我们应该期待这种测试场景有最大的改进,因为这是100%写操作,而WiredTiger的文档级 并发性控制对在多核处理器服务器上的多线程测试场景最有帮助 。
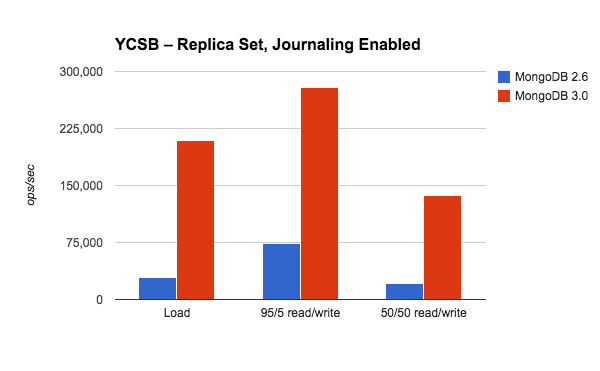
第二次测试比较了两个系统上 95%读取和5%更新的场景。这里我们看到WiredTiger 有4倍多的吞吐量。相比于刚才的纯插入场景,这次的性能提升没有那么显著,因为写操作只占所有操作的5%。在MongoDB2.6中,并发控制是在数据库级别,而且写会阻塞读操作,从而降低总体的并发量。通过这次测试,我们看到MongoDB 3.0更加细粒的并发性控制明显提高了总并发量。
最后,对于读写操作平衡的场景,我们看到 MongoDB3.0有6倍的并发率。这比我们刚才看到的95%读 的4倍提高要好一些,因为这里有更多的写操作。
响应延迟:
在性能测试中仅仅监测并发量是不够的,我们还要考虑操作的响应延迟 。对许多操作的响应延迟做一个平均得来的平均响应延迟值不是一个最好的度量指标。对于想要系统有持续良好、低延时体验的开发者来说,他们更关注在这个系统中效能最低的操作。 高延时查询通常用95th和99th百分位数来衡量 – 95th 百分位数表示这个数值(响应延迟)比95%的其他操作都要糟糕(慢)。(有人可能会觉得这种衡量不够准确: 因为很多网页请求会使用几百个数据库操作, 那么很可能绝大部分用户都会经历到这些99th百分位数的慢响应延迟 )
在读操作响应延迟上我们看到在MongoDB2.6和MongoDB3.0之间的差别是非常微小的,读操作响应延迟很稳定的保持在1ms或者更少的数值内。然而更新操作响应延迟则有相当大的区别 。
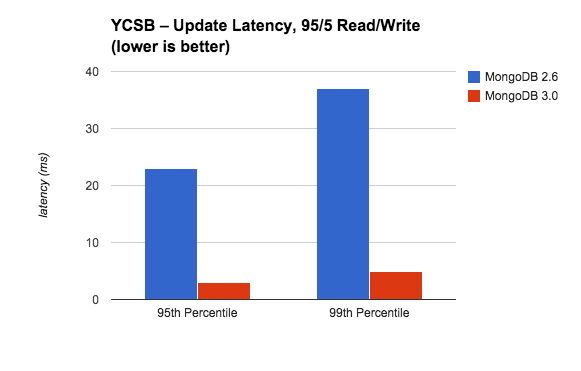
在这里我们通过读密集型的工作负荷来比较更新响应延迟的95th和99th百分位数 。在MongoDB3.0中更新延时显著改善了,在95th和99th百分位数中几乎减少了90%。这很重要,提高并发量不应该以更长的延时为代价,因为这将最终降低应用程序 的用户体验。
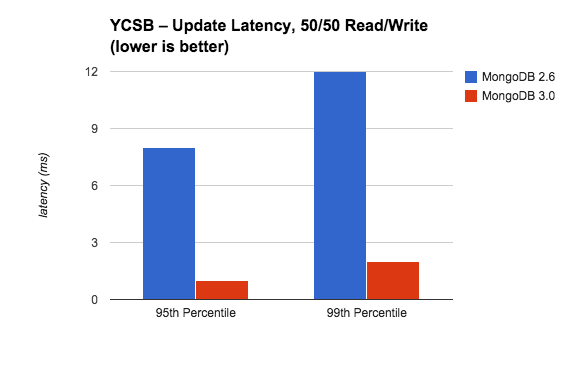
在平衡的工作负荷下,更新延迟仍然保持在较低的水平 。在95th百分位数,MongoDB3.0的更新延迟比MongoDB2.6几乎低90%,而99th百分位数则低80% 。这些改善可以给用户带来更好的使用体验,更加可预测的性能。
我们相信这些针对并发量和响应延迟的测试证明了MongoDB在写性能上有了显著的提高。
小改变产生大影响:
在接下来的博客中我们将描述可以对MongoDB性能产生大影响的一些小改变。作为一个预览,我们来看一个人们经常忽略的因素。
提供充足的客户端能力:
YCSB的默认配置只使用一个线程。使用一个单线程,无论是哪个数据库你的测试结果都会很可怜 。 不要使用单线程基准测试除非你的应用程序运行单线程。单线程测试仅仅测量响应时间,不能测试并发量,而容量规划对两个因素都要考虑到。
大多数数据库都是为多线程客户端设计的 。通过逐步增加线程数来找到最佳的数量 – 增加更多线程直到你发现并发率停止上升或者响应时间在增加。
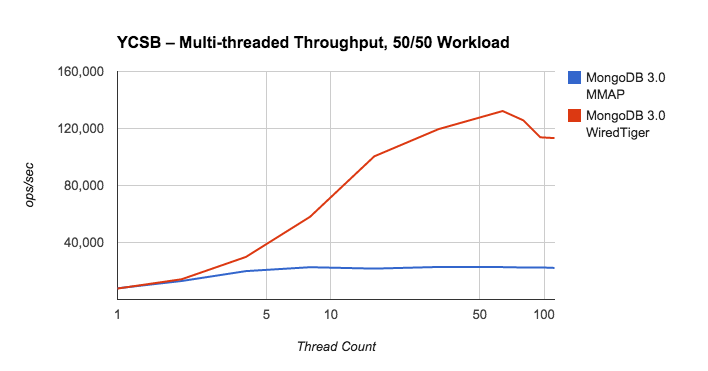
考虑为YCSB运行多个客户端服务器。一个单一客户端可能无法产生充足的压力来测试系统的容量。不幸的是,YCSB没有让使用多个客户端变的简单,你必须手动去协调多个客户端的开始和停止,而且你必须自己去综合各个客户端的测试结果。
当使用分片的时候,每1,2个分片使用一个mongos,并且每一个mongos要使用一个YCSB客户端。太多客户端进程可能会导致系统崩溃,开始会导致响应延迟增加,然而最终会导致CPU崩溃。有时候你需要去控制客户端的请求量。
寻找在响应延迟和并发量中正确的平衡点是任何性能调优的一个重要组成部分。通过监测延时和并发量,并且通过一系列测试增加线程量,你可以在延时和并发量两者之间确定明确的关系,并在一个给定工作负荷的情况下计算出最佳线程数。
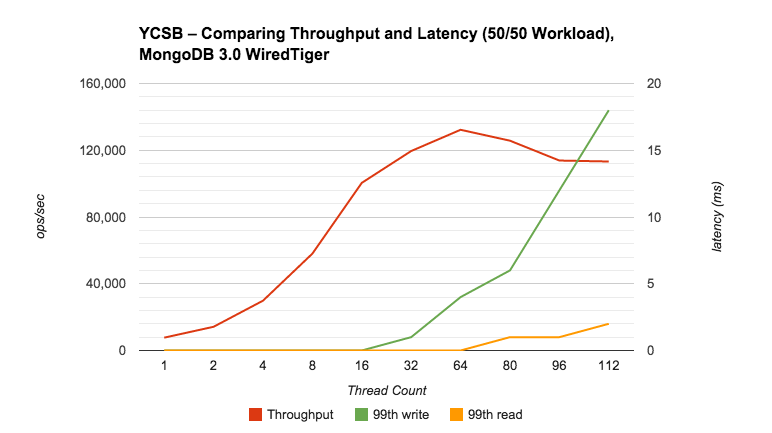
基于这些测试结果我们观察到以下两点:
1、 所有操作的99th百分位数直到16线程为止都少于1ms。当多于16线程,响应延迟开始增加。
2、 并发量从1增加到64线程时会不断增长。在64线程之后,增加线程数不再提高并发量,但是响应延迟却在增加。
基于这些,应用程序的最佳线程数在16和64之间,且取决于我们更希望降低延迟还是提高并发量。在64线程时,延时看起来依旧很好:99th百分位数的读取少于1ms, 99th百分位数的写少于4ms。与此同时,并发量高于13万/秒
YCSB测试配置
我们测试了许多不同的配置来确定并发量和响应延迟之间的最佳平衡点。
在这些测试中,我们使用了3千万的文档和3千万的操作。文档包含一个100字节的字段(总共151字节) 并选择Zipfian作为读操作选记录方式。 我们通过逐步增加线程量直到95th和99th百分位数延时开始增加而并发量停止增加的时候确定了最佳线程数,这里发布的结果就是基于这个最佳线程数的测试。
所有测试使用了复制集,开启了恢复日志(Journal),服务器环境参照了我们的最佳实践来配置。我们始终建议在生产环境要使用复制集。
YCSB客户端在一个专门的服务器上运行。每一个复制集成员也在一个专门的服务器上运行。所有服务器都是具有下列规格的Softlayer 裸机:
1、CPU: 2x Deca Core Xeon 2690 V2 – 3.00GHz (Ivy Bridge) – 2 x 25MB cache
2、 RAM: 128 GB Registered DDR3 1333
3、 Storage: 2x 960GB SSD drives, SATA Disk Controller
4、 Network: 10 Gbps
5、 Ubuntu 14.10 (64 bit)
6、 MongoDB Versions: MongoDB 2.6.7; MongoDB 3.0.1
mongodb 3.0 WT 引擎性能测试(转载)的更多相关文章
- (转)MongoDB 3.0 WT引擎参考配置文件
mongodb 3.0 改变很多,从2.6版本升级到3.0要关注的细节很多,如权限等等.3.0在数据存储引擎上更换成了wiredTiger,在数据压缩方面很有效,解决大数据量问题的情况下,磁盘不够用的 ...
- MongoDB 3.0 WT引擎参考配置文件
单实例: systemLog: destination: file ###日志存储位置 path: /data/mongodb/log/mongod.log logAppend: true stora ...
- mongodb三种存储引擎高并发更新性能专题测试
背景说明 近期北京理财频道反馈用来存放股市实时数据的MongoDB数据库写响应请求很慢,难以跟上业务写入速度水平.我们分析了线上现场的情况,发现去年升级到SSD磁盘后,数据持久化的磁盘IO开销已经不是 ...
- MongoDB 4.0 事务实现解析
MongoDB 4.0 引入的事务功能,支持多文档ACID特性,例如使用 mongo shell 进行事务操作 > s = db.getMongo().startSession() sessio ...
- CentOS7 安装MongoDB 3.0服务器
1,下载&安装 MongoDB 3.0 正式版本发布!这标志着 MongoDB 数据库进入了一个全新的发展阶段,提供强大.灵活而且易于管理的数据库管理系统.MongoDB宣称,3.0新版本不只 ...
- MongoDB 3.0 新特性【转】
本文来自:http://www.open-open.com/lib/view/open1427078982824.html#_label3 更多信息见官网: http://docs.mongodb.o ...
- MongoDB 3.0(1):CentOS7 安装MongoDB 3.0服务
目录(?)[-] 1下载安装 2MongoDB CRUD 1创建数据 2更新数据 3删除 4查询 5更多方法 3MongoDB可视化工具 4总结 本文原文连接: http://blog.csdn. ...
- CentOS7 安装MongoDB 3.0服务
1,下载&安装 MongoDB 3.0 正式版本发布!这标志着 MongoDB 数据库进入了一个全新的发展阶段,提供强大.灵活而且易于管理的数据库管理系统.MongoDB宣称,3.0新版本不只 ...
- MongoDB 3.0新增特性一览
转自:http://blog.sina.com.cn/s/blog_48c95a190102vedr.html 引言 在历经版本号修改(2.8版本直接跳到3.0版本)和11个rc版本之后,MongoD ...
随机推荐
- three中的着色器示例
其实在3D引擎/库的帮助下,我们做webgl开发的难度已经很大大地降低了,熟悉相关API的话,开发一个简单的3D程序可以说是很轻松的事情. 在我看来,webgl的核心就是着色器(顶点着色器.片元着色器 ...
- charles获取抓包数据
charles获取抓包数据 第一步:确保手机和电脑处于同一个局域网之下 第二步:进入 charles 的代理设定选项(主导航栏Proxy-----Proxy Setting......)中,允许代理, ...
- MSSQL字符串取相应的第几个数组值
create function Get_StrArrayStrOfIndex( @str varchar(5000), --要分割的字符串 @split varchar(10), --分隔符号 @in ...
- 【AMAD】itsdangerous -- 用安全的方式把可信赖的数据传入不可信赖的环境,或者相反
动机 简介 内部原理 个人评分 动机 有时,你不得不把数据发送给一些不信赖的环境. 但是怎么安全地做这件事呢?答案就是使用签名. 简介 使用签名,首先设定一个只有你知道的key,你可以使用它来为你的数 ...
- spring5源码分析系列(二)——spring核心容器体系结构
首先我们来认识下IOC和DI: IOC(Inversion of Control)控制反转:控制反转,就是把原先代码里面需要实现的对象创建.依赖的代码,反转给容器来帮忙实现.所以需要创建一个容器,并且 ...
- HTML页面左上角图标
显示网页左上角标志图标 <link rel="shortcut icon"type="image/x-icon"href="images/fav ...
- 与C++开启新路途
1.我与C的过去 学习C语言大概是从18年8月开始,一直到19年3月.我完成了对C的基本认识和学习,也顺利通过了二级C计算机的考试.不过当你开始深入于C的世界时,你会发现学习的基础好像略有浅薄.宏的世 ...
- C++练习 | 最长公共字符串(DP)
HDU 1159.Common Subsequence #include<iostream> #include<stdio.h> #include<string> ...
- Smarty内置函数之config_load
config_load的作用是: 用于从配置文件中加载变量,属性file引入配置文件名,另外若配置文件包含多个部分,可以使用属性section指定从那部分取得变量(若不指定,将会引入失败). 实例: ...
- Hive 教程(五)-参数配置
配置基本操作 hive> set; 查看所有配置hive> set key: 查看某个配置hive> set key value: 设置某个配置 我们可以看到一些 hadoop 的配 ...