【进阶技术】一篇文章搞掂:Spring Cloud Stream
本文总结自官方文档http://cloud.spring.io/spring-cloud-static/spring-cloud-stream/2.1.0.RC3/single/spring-cloud-stream.html
一、Spring的数据集成简史
二、一个最简单的实例
三、2.0版本的新特性
四、Spring Cloud Stream介绍
Spring Cloud Steam内容简介:
- 一个框架,用于构建消息驱动的微服务应用程序;
- 构建在SpringBoot之上;
- 使用Spring Integration提供与消息代理的连接;
- 提供了几个不同供应商的中间件的opinionated配置;
- 引入了持久发布-订阅语义、使用者组和分区的概念。
接收消息:
使用@EnableBinding注释,可以连接到消息代理服务器。
使用@StreamListener添加到方法中,可以接收用于流处理的事件。
下面的示例显示接收外部消息的接收器应用程序:
@SpringBootApplication
@EnableBinding(Sink.class)
public class VoteRecordingSinkApplication { public static void main(String[] args) {
SpringApplication.run(VoteRecordingSinkApplication.class, args);
} @StreamListener(Sink.INPUT)
public void processVote(Vote vote) {
votingService.recordVote(vote);
}
}
通道接口:
@EnableBinding注释将一个或多个接口作为参数(在本例中,参数是单个Sink接口)。
接口声明输入和输出通道。Spring Cloud Stream提供了Source、Sink和Processor接口。
您还可以定义自己的接口。
下面的清单显示了Sink接口的定义:
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
@Input注释标识了一个输入通道,用于接收消息,使消息能进入应用程序。
@Output注释标识了一个输出通道,通过它发布的消息可以离开应用程序。
@Input和@Output注释可以将通道名称作为参数。如果没有提供名称,则使用注释方法的方法名称。
Spring Cloud Stream为您创建了接口的实现。您可以通过自动装配来使用它,如下面的示例所示(来自测试用例):
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = VoteRecordingSinkApplication.class)
@WebAppConfiguration
@DirtiesContext
public class StreamApplicationTests { @Autowired
private Sink sink; @Test
public void contextLoads() {
assertNotNull(this.sink.input());
}
}
5、主要概念
Spring Cloud Stream通过一些术语和抽象来简化了消息驱动程序的编写。
5.1、程序模型
Spring Cloud Stream的核心与中间件实现无关。
Stream应用通过输入输出通道(channel)来与外界交互。
通道(channel)通过与外部中间件对应的绑定器(Binder)具体实现,来与外部的中间件产品进行通信。

5.2、绑定器(Binder)抽象
Spring Cloud Stream提供了kafka、RabbitMQ对应的Binder实现、也包含一个TestSupportBinder用于测试,也可以编写自己的Binder
Spring Cloud Stream使用Spring Boot配置以及Binder抽象,使之可以灵活地配置如何连接到一个消息中间件。例如,可以在部署时设置连接到哪种类型,或者哪个消息中间件。
这些配置可以通过外部设置或者任何Spring Boot支持的配置方式(如程序参数、环境变量、yml文件、properties文件)进行
Spring Cloud Stream会根据classpath下的依赖自动选择binder,你也可以包含多个binder,在运行时决定使用哪个,甚至根据不同的通道使用不同的binder
5.3、发布订阅的持久化支持
应用程序之间的通信遵循发布-订阅模型,其中数据通过共享主题广播。在下图中可以看到这一点,它显示了一组交互的Spring Cloud Stream应用程序的典型部署。
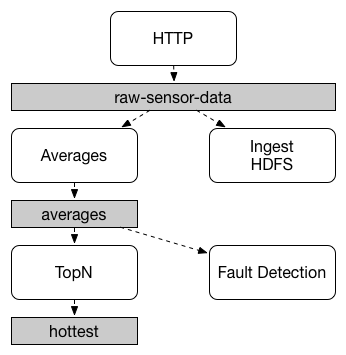
Spring Cloud Stream发布订阅模式
传感器的数据报告到一个HTTP端点,然后被送到一个共同的destination(目的地):raw-sensor-data。
从这个destination(目的地)开始,有2个微服务订阅了raw-sensor-data这个主题,一个负责计算窗口平均值,一个将原始数据导入HDFS(Hadoop Distributed File System)。
发布-订阅通信模型降低了生产者和使用者的复杂性,并允许在不中断现有流的情况下将新的应用程序添加到拓扑中。例如,在计算平均值的应用程序的下游,您可以添加计算显示和监视的最高温度值的应用程序。然后,您可以添加另一个应用程序来解释用于故障检测的相同平均值流。通过共享主题(而不是点对点队列)进行所有通信可以减少微服务之间的耦合。
虽然发布-订阅消息传递的概念并不新鲜,Spring Cloud Stream采取了额外的步骤,使其成为其应用程序模型的一个opinionated choice。通过使用本地中间件支持,Spring Cloud Stream还简化了跨不同平台的发布-订阅模型的使用。
5.4、消费者组
为了提升程序的处理能力,我们部署时会创建多个实例的应用程序;而此时,不同实例对于消息是互相竞争的关系,只需要有其中一个实例来对消息进行消费即可。
Spring Cloud Stream通过消费者组的概念对这种行为进行建模。(Spring Cloud Stream消费者组与卡夫卡消费者组相似并受到其启发。)
每个消费者binding都可以使用spring.cloud.stream.bindings.<channelName>.group属性指定组名。
对于如下图所示的使用者,此属性将设置为spring.cloud.stream.bindings.<channelName>.group=hdfsWrite或spring.cloud.stream.bindings.<channelName>.group=average.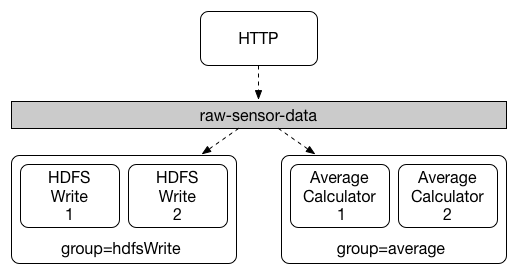
订阅给定目标的所有组都会收到已发布数据的副本,但每个组中只有一个成员从该目的地接收到给定的消息。
默认情况下,当未指定组时,Spring Cloud Stream会把应用程序放到一个匿名的、独立的、只有一个成员的消费者组中,然后和其它消费者组放在一起维护。
5.5、消费者类型
支持2种消费者类型:
- Message-driven (sometimes referred to as Asynchronous)
- Polled (sometimes referred to as Synchronous)
2.0前,只支持异步消费者;A message is delivered as soon as it is available and a thread is available to process it.
如果想控制消息处理的速率,可以使用同步消费者;
持久化:
与Spring Cloud Stream程序模型一致,消费者组是持久化的。
Binder实现保证了组订阅是持久的,即使消息是在消费者都停止的状态下发送的,只要消费者组创建了一个订阅者,这个组就开始接收数据。
!!匿名订阅本质上是不持久的。对于某些绑定器实现(如RabbitMQ),有可能具有非持久的组订阅。
通常,在将应用程序绑定到给定目标时,最好始终使用消费者组。在扩展Spring Cloud Stream应用程序时,必须为每个输入绑定指定一个使用者组。这样做可以防止应用程序的实例接收重复的消息(除非需要这种行为,这是不寻常的)。
5.6、分区支持
Spring Cloud Stream支持在给定应用程序的多个实例之间划分数据。在分区场景中,物理通信介质(例如the broker topic)被视为被构造成多个分区。
一个或多个生产者应用实例向多个使用者应用实例发送数据,并确保由公共特征标识的数据由同一个使用者实例处理。
Spring Cloud Stream为统一实现分区处理提供了一个公共抽象。因此,无论代理本身是否是自然分区的(例如Kafka),都可以使用分区(例如RabbitMQ)。
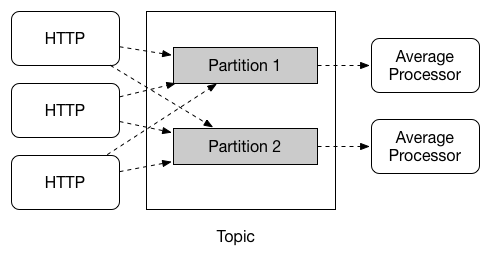
Spring Cloud Stream分区
分区是有状态处理中的一个关键概念,在这种情况下,确保所有相关数据一起处理是至关重要的(无论是出于性能还是一致性的原因)。
例如,在时间加窗的平均计算示例中,来自任何给定传感器的所有测量都由同一个应用实例处理是很重要的。
若要设置分区处理方案,必须同时配置数据生成端和数据消耗端。
六、编程模型
核心概念:
- Destination Binders:负责集成外部消息队列系统的组件。
- Destination Bindings:由绑定器创建的,连接外部消息队列系统和提供信息生产者或消费者的应用程序的桥梁。
- Message:生产者和消费者使用的规范数据结构,用于与Destination Binders(以及通过外部消息传递系统的其他应用程序)通信。

6.1、Destination Binders
Destination Binders是Spring Cloud Stream的扩展组件,为实现与外部消息系统集成,提供必要的配置和实现。这种集成负责消息与生产者和使用者之间的连接、委托和路由、数据类型转换、用户代码的调用等等。
Binders处理了很多重要的事情,但是有些地方需要人为帮助,通常是以配置的方式来实现,在本文其余部分会详细介绍这些选项。
6.2、Destination Bindings
如前所述,Destination Bindings在连接外部消息队列系统和提供信息生产者或消费者的应用程序的桥梁。
将@EnableBinding注释应用于应用程序的一个配置类,可以定义一个binding。@EnableBinding注释本身使用@Configuration进行元注释,并触发SpringCloudStream基础结构的配置。
下面的示例显示了一个完全配置和功能良好的Spring Cloud Stream应用程序,该应用程序以字符串类型从输入目标接收消息的有效负载(请参见第9章内容类型协商部分),将其记录到控制台,并在将其转换为大写后发送到输出目的地。
@SpringBootApplication
@EnableBinding(Processor.class)
public class MyApplication { public static void main(String[] args) {
SpringApplication.run(MyApplication.class, args);
} @StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public String handle(String value) {
System.out.println("Received: " + value);
return value.toUpperCase();
}
}
如您所见,@EnableBinding注释可以使用一个或多个接口类作为参数。这些参数称为绑定,它们包含表示可绑定组件的方法。这些组件通常是基于信道的绑定器(如Ribbit、Kafka和其他)的消息通道(参见Spring消息传递)。然而,其他类型的绑定可以提供对相应技术的本机特性的支持。例如,Kafka流绑定器(以前称为KStream)允许直接绑定到Kafka流(有关更多细节,请参见Kafka流)。
SpringCloudStream已经为典型的消息交换契约提供了绑定接口,其中包括:
- Sink:提供消息消费的目的地,是消息的消费者
- Source:提供消息发布的目的地,是消息的生产者
- Processor:即使消费者,也是生产者
public interface Sink {
String INPUT = "input";
@Input(Sink.INPUT)
SubscribableChannel input();
}
public interface Source {
String OUTPUT = "output";
@Output(Source.OUTPUT)
MessageChannel output();
}
public interface Processor extends Source, Sink {}
虽然前面的示例满足了大多数情况,但您也可以通过定义自己的绑定接口来定义自己的契约,并使用@Input和@Output注释来标识实际的可绑定组件。
public interface Barista {
@Input
SubscribableChannel orders();
@Output
MessageChannel hotDrinks();
@Output
MessageChannel coldDrinks();
}
使用前面示例中显示的接口作为@EnableBinding参数,将触发分别名为Orders、HotDrinks和ColdDrinks的三个绑定通道的创建。您可以根据需要为@EnableBinding注释提供任意数量的绑定接口,如下面的示例所示:
@EnableBinding(value = { Orders.class, Payment.class })
在SpringCloudStream中,可用的通道绑定组件包括:Spring Messaging的Message Channel(用于出站)及其扩展,Subscribable Channel(用于入站)。
Pollable Destination Binding
虽然前面描述的绑定支持基于事件的消息消耗,但有时需要更多的控制,例如消耗率。
从版本2.0开始,您现在可以绑定pollable consumer:
下面的示例演示如何绑定pollable consumer:
public interface PolledBarista {
@Input
PollableMessageSource orders();
. . .
}
在这种情况下,一个PollableMessageSource实现绑定到订单通道。See Section 6.3.5, “Using Polled Consumers” for more details.
自定义通道名称
通过使用@Input和@Output注释,可以为通道指定自定义的通道名称,如下面的示例所示:
public interface Barista {
@Input("inboundOrders")
SubscribableChannel orders();
}
Normally, you need not access individual channels or bindings directly (other then configuring them via @EnableBinding annotation). However there may be times, such as testing or other corner cases, when you do.
Aside from generating channels for each binding and registering them as Spring beans, for each bound interface, Spring Cloud Stream generates a bean that implements the interface. That means you can have access to the interfaces representing the bindings or individual channels by auto-wiring either in your application, as shown in the following two examples:
在这个示例中,创建的绑定通道被命名为inboundOrders。
通常,您不需要直接访问单个通道或绑定(然后通过@EnableBinding注释配置它们)。
然而,也有一些时候,例如测试或其他特殊情况,你可能需要这么做。
除了为每个绑定生成通道并将它们注册为Spring Bean之外,Spring Cloud Stream为每个绑定接口生成一个实现该接口的bean。这意味着您可以通过应用程序中的自动装配表示绑定或单个通道的接口,如以下两个示例所示:
自动装配Binding接口
@Autowire
private Source source public void sayHello(String name) {
source.output().send(MessageBuilder.withPayload(name).build());
}
自动装配一个通道
@Autowire
private MessageChannel output; public void sayHello(String name) {
output.send(MessageBuilder.withPayload(name).build());
}
您还可以使用标准Spring的@Qualifier注释,用于自定义信道名称或需要指定通道的多通道场景中的情况。
@Autowire
@Qualifier("myChannel")
private MessageChannel output;
6.3、生产和消费消息
2种使用方式:
- Spring Integration注解
- Spring Cloud注解
6.3.1、Spring Integration注解用法:
Spring Cloud Stream的基础:企业集成模式定义的概念和模式
Spring Cloud Stream的内部实现:依赖于Spring Integration框架
所以Stream支持Spring Integration已经建立的基础、语义和配置选项
例如:可以通过@InboundChannelAdapter注解获取到一个Source或MessageSource的输出通道:
@EnableBinding(Source.class)
public class TimerSource { @Bean
@InboundChannelAdapter(value = Source.OUTPUT, poller = @Poller(fixedDelay = "10", maxMessagesPerPoll = "1"))
public MessageSource<String> timerMessageSource() {
return () -> new GenericMessage<>("Hello Spring Cloud Stream");
}
}
类似:可以通过@Transformer或@ServiceActivator,提供一个对来自Processor binding的消息的处理实现:
@EnableBinding(Processor.class)
public class TransformProcessor {
@Transformer(inputChannel = Processor.INPUT, outputChannel = Processor.OUTPUT)
public Object transform(String message) {
return message.toUpperCase();
}
}
注意一点:
使用Spring Cloud Stream中的@StreamListener注释绑定同一个绑定时,使用的是发布订阅模型,所以每一个使用了@StreamListener注释的方法,都会接收到一份消息;
而使用Spring Integration中的注解 (such as @Aggregator, @Transformer, or @ServiceActivator)时,使用的是竞争模型,只会有一个消费者得到消息;而且,不会为每一个消费者创建单独的使用者组。
6.3.2、使用Spring Cloud Stream的注解@StreamListener
作为对Spring Integration框架的补充,SpringCloudStream提供了自己的@StreamListener注解,该注释借鉴了其他Spring消息注解(@Messagemap、@JmsListener、@RabbitListener等),并提供了方便性,如基于内容的路由等。
@EnableBinding(Sink.class)
public class VoteHandler { @Autowired
VotingService votingService; @StreamListener(Sink.INPUT)
public void handle(Vote vote) {
votingService.record(vote);
}
}
与其他Spring消息传递方法一样,方法参数可以使用@Payload、@Header和@Header进行注释。对于返回数据的方法,必须使用@SendTo注释为该方法返回的数据指定输出绑定目的地,如以下示例所示:
@EnableBinding(Processor.class)
public class TransformProcessor { @Autowired
VotingService votingService; @StreamListener(Processor.INPUT)
@SendTo(Processor.OUTPUT)
public VoteResult handle(Vote vote) {
return votingService.record(vote);
}
}
6.3.3、@StreamListener用于基于内容的路由
Spring Cloud Stream支持根据conditions向多个带有@StreamListener注释的处理程序方法分发消息。
为了支持条件分派,方法必须满足以下条件:
- 不能有返回值。
- 它必须是an individual message handling method(不支持reactive API methods)。
条件由注释的条件参数中的Spel表达式指定,并对每条消息进行计算。匹配条件的所有处理程序都是在同一个线程中调用的,不需要对调用的顺序作出任何假设。
在具有调度条件的@StreamListener的下面示例中,所有带有值bogey的header type的消息都被分派到RecveBogey方法,而带有值Bacall的header type的所有消息都被分派到ReceiveBacall方法。
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class TestPojoWithAnnotatedArguments { @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'")
public void receiveBogey(@Payload BogeyPojo bogeyPojo) {
// handle the message
} @StreamListener(target = Sink.INPUT, condition = "headers['type']=='bacall'")
public void receiveBacall(@Payload BacallPojo bacallPojo) {
// handle the message
}
}
Content Type Negotiation in the Context of condition
条件语境下的内容类型协商
It is important to understand some of the mechanics behind content-based routing using the condition argument of @StreamListener, especially in the context of the type of the message as a whole. It may also help if you familiarize yourself with the Chapter 9, Content Type Negotiation before you proceed.
Consider the following scenario:
理解使用@StreamListener的条件参数l来进行基于内容的路由背后的一些机制是很重要的,特别是在整个消息类型的上下文中。
如果您熟悉了第9章,内容类型协商,这也会有帮助。
考虑以下情况:
@EnableBinding(Sink.class)
@EnableAutoConfiguration
public static class CatsAndDogs { @StreamListener(target = Sink.INPUT, condition = "payload.class.simpleName=='Dog'")
public void bark(Dog dog) {
// handle the message
} @StreamListener(target = Sink.INPUT, condition = "payload.class.simpleName=='Cat'")
public void purr(Cat cat) {
// handle the message
}
}
上面的代码是完全有效的。它编译和部署没有任何问题,但它永远不会产生您期望的结果。
这是因为您正在测试一些尚未以您期望的状态存在的东西。
这是因为消息的有效负载尚未传输类型转换成所需类型。换句话说,它还没有经历第9章“内容类型协商”中描述的类型转换过程。
因此,除非您使用计算原始数据的Spel表达式(例如,字节数组中第一个字节的值),否则使用基于消息头的表达式(例如,condition = "headers['type']=='dog'")。
At the moment, dispatching through @StreamListener conditions is supported only for channel-based binders (not for reactive programming) support.
6.3.4 Spring Cloud Function support
自SpringCloudStreamv2.1以来,定义stream handlers and sources的另一个替代方法是使用对 Spring Cloud Function 的内置支持,其中可以将它们表示为beans of type java.util.function.[Supplier/Function/Consumer].
To specify which functional bean to bind to the external destination(s) exposed by the bindings, you must provide spring.cloud.stream.function.definitionproperty.
Here is the example of the Processor application exposing message handler as java.util.function.Function
@SpringBootApplication
@EnableBinding(Processor.class)
public class MyFunctionBootApp { public static void main(String[] args) {
SpringApplication.run(MyFunctionBootApp.class, "--spring.cloud.stream.function.definition=toUpperCase");
} @Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
In the above you we simply define a bean of type java.util.function.Function called toUpperCase and identify it as a bean to be used as message handler whose 'input' and 'output' must be bound to the external destinations exposed by the Processor binding.
Below are the examples of simple functional applications to support Source, Processor and Sink.
Here is the example of a Source application defined as java.util.function.Supplier
在上面,我们只定义一个java.util.Function.Function类型的bean,函数名称为toUpperCase,并将其标识为用作消息处理器,其“输入”和“输出”必须绑定到Processor binding暴露的外部目的地。
下面是支持Source、Processor和Sink的简单功能应用程序的示例。
下面是定义为java.util.Function.Supplier的Source应用程序的示例
@SpringBootApplication
@EnableBinding(Source.class)
public static class SourceFromSupplier {
public static void main(String[] args) {
SpringApplication.run(SourceFromSupplier.class, "--spring.cloud.stream.function.definition=date");
}
@Bean
public Supplier<Date> date() {
return () -> new Date(12345L);
}
}
Here is the example of a Processor application defined as java.util.function.Function
@SpringBootApplication
@EnableBinding(Processor.class)
public static class ProcessorFromFunction {
public static void main(String[] args) {
SpringApplication.run(ProcessorFromFunction.class, "--spring.cloud.stream.function.definition=toUpperCase");
}
@Bean
public Function<String, String> toUpperCase() {
return s -> s.toUpperCase();
}
}
Here is the example of a Sink application defined as java.util.function.Consumer
@EnableAutoConfiguration
@EnableBinding(Sink.class)
public static class SinkFromConsumer {
public static void main(String[] args) {
SpringApplication.run(SinkFromConsumer.class, "--spring.cloud.stream.function.definition=sink");
}
@Bean
public Consumer<String> sink() {
return System.out::println;
}
}
Functional Composition
使用此编程模型,您还可以从函数组合中受益,在这种情况下,您可以从一组简单的函数中动态地组合复杂的处理程序。作为一个示例,让我们将下面的函数bean添加到上面定义的应用程序中
@Bean
public Function<String, String> wrapInQuotes() {
return s -> "\"" + s + "\"";
}
and modify the spring.cloud.stream.function.definition property to reflect your intention to compose a new function from both ‘toUpperCase’ and ‘wrapInQuotes’. To do that Spring Cloud Function allows you to use | (pipe) symbol. So to finish our example our property will now look like this:
—spring.cloud.stream.function.definition=toUpperCase|wrapInQuotes
6.3.5 Using Polled Consumers
6.4 Error Handling
6.5 Reactive Programming Support
7. Binders
SpringCloudStream提供了一个Binder抽象,用于连接外部中间件。
本节提供有关BinderSPI背后的主要概念、其主要组件和具体实现细节的信息。
7.1 Producers and Consumers
下图显示生产者与消费者之间的一般关系:
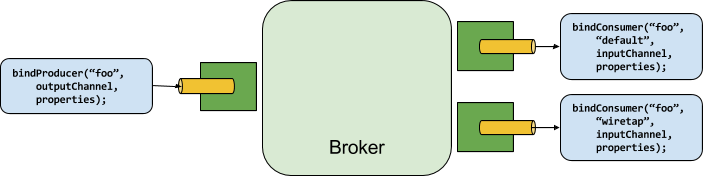
A producer is any component that sends messages to a channel. The channel can be bound to an external message broker with a Binder implementation for that broker. When invoking the bindProducer() method, the first parameter is the name of the destination within the broker, the second parameter is the local channel instance to which the producer sends messages, and the third parameter contains properties (such as a partition key expression) to be used within the adapter that is created for that channel.
生产者:是向channel发送消息的任何组件。
channel :使用一个对应消息代理的Binder实现绑定到一个外部消息代理。
当调用bindProducer()方法时,第一个参数是代理中destination 的名称,第二个参数是生产者发送消息的local channel instance,第三个参数包含要在为该通道创建的适配器中使用的属性(例如分区键表达式)。
A consumer is any component that receives messages from a channel. As with a producer, the consumer’s channel can be bound to an external message broker. When invoking the bindConsumer() method, the first parameter is the destination name, and a second parameter provides the name of a logical group of consumers. Each group that is represented by consumer bindings for a given destination receives a copy of each message that a producer sends to that destination (that is, it follows normal publish-subscribe semantics). If there are multiple consumer instances bound with the same group name, then messages are load-balanced across those consumer instances so that each message sent by a producer is consumed by only a single consumer instance within each group (that is, it follows normal queueing semantics).
使用者是从通道接收消息的任何组件。
与生产者一样,使用者的通道可以绑定到外部消息代理。
当调用bindConsumer()方法时,第一个参数是destination 名称,第二个参数提供使用者组的逻辑名称。由给定目标的使用者绑定表示的每个组接收生产者发送到该目标的每个消息的副本(也就是说,它遵循正常的发布-订阅语义)。如果有多个以同一个组名绑定的使用者实例,那么这些使用者实例之间的消息是负载均衡的,这样由生产者发送的每条消息只被每个组中的单个使用者实例所使用(也就是说,它遵循正常的排队语义)。
7.2 Binder SPI
BinderSPI由许多接口、开箱即用的实用工具类和提供连接到外部中间件的可插拔机制的发现策略组成。
SPI的关键点是Binder接口,它是一种将输入和输出连接到外部中间件的策略。
下面的清单显示了Binder接口的定义:
public interface Binder<T, C extends ConsumerProperties, P extends ProducerProperties> {
Binding<T> bindConsumer(String name, String group, T inboundBindTarget, C consumerProperties);
Binding<T> bindProducer(String name, T outboundBindTarget, P producerProperties);
}
The interface is parameterized, offering a number of extension points:
- Input and output bind targets. As of version 1.0, only
MessageChannelis supported, but this is intended to be used as an extension point in the future. - Extended consumer and producer properties, allowing specific Binder implementations to add supplemental properties that can be supported in a type-safe manner.
A typical binder implementation consists of the following:
- A class that implements the
Binderinterface; - A Spring
@Configurationclass that creates a bean of typeBinderalong with the middleware connection infrastructure. A
META-INF/spring.bindersfile found on the classpath containing one or more binder definitions, as shown in the following example:
接口是参数化的,提供了许多扩展点:
- 输入和输出绑定目标。从1.0版开始,只支持MessageChannel,但这将在将来用作扩展点。
- 扩展使用者和生产者属性,允许特定的Binder实现,去添加类型安全的补充属性。
典型的绑定器实现包括以下内容:
- 实现Binder接口的类;
- 创建Binder类型bean的Spring@Configuration类以及中间件连接基础设施。
- 在类路径上找到一个meta-INF/Spring.binders文件,其中包含一个或多个绑定器定义,如下面的示例所示:
kafka:\
org.springframework.cloud.stream.binder.kafka.config.KafkaBinderConfiguration
7.3 Binder Detection
SpringCloudStream依赖于BinderSPI的实现来执行将channels 连接到消息代理的任务。每个Binder实现通常连接到一种类型的消息传递系统。
7.3.1 Classpath Detection
默认情况下,SpringCloudStream依赖SpringBoot的自动配置来配置绑定过程。如果在类路径上找到单个Binder实现,SpringCloudStream将自动使用它。例如,旨在绑定到RabbitMQ的SpringCloudStream项目可以添加以下依赖项:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
有关其他绑定器依赖项的特定Maven坐标,请参见该绑定器实现的文档。
7.4 Multiple Binders on the Classpath
当类路径上存在多个绑定器时,应用程序必须指示要为每个通道绑定使用哪个绑定器。每个绑定器配置都包含一个meta-INF/Spring.binders文件,它是一个简单的属性文件,如下面的示例所示:
rabbit:\
org.springframework.cloud.stream.binder.rabbit.config.RabbitServiceAutoConfiguration
Similar files exist for the other provided binder implementations (such as Kafka), and custom binder implementations are expected to provide them as well. The key represents an identifying name for the binder implementation, whereas the value is a comma-separated list of configuration classes that each contain one and only one bean definition of type org.springframework.cloud.stream.binder.Binder.
Binder selection can either be performed globally, using the spring.cloud.stream.defaultBinder property (for example, spring.cloud.stream.defaultBinder=rabbit) or individually, by configuring the binder on each channel binding. For instance, a processor application (that has channels named input and output for read and write respectively) that reads from Kafka and writes to RabbitMQ can specify the following configuration:
spring.cloud.stream.bindings.input.binder=kafka
spring.cloud.stream.bindings.output.binder=rabbit
7.5 Connecting to Multiple Systems
7.6 Binding visualization and control
绑定可视化和控制,可以通过端点来查看,或者暂停通道
7.7 Binder Configuration Properties
当自定义绑定器配置时,下列属性可用。这些通过org.springframework.cloud.stream.config.BinderProperties公开的属性必须以spring.cloud.stream.binders.<configurationName>.作为前缀
- type
-
The binder type. It typically references one of the binders found on the classpath — in particular, a key in a
META-INF/spring.bindersfile.By default, it has the same value as the configuration name.
- inheritEnvironment
-
Whether the configuration inherits the environment of the application itself.
Default:
true. - environment
-
Root for a set of properties that can be used to customize the environment of the binder. When this property is set, the context in which the binder is being created is not a child of the application context. This setting allows for complete separation between the binder components and the application components.
Default:
empty. - defaultCandidate
-
Whether the binder configuration is a candidate for being considered a default binder or can be used only when explicitly referenced. This setting allows adding binder configurations without interfering with the default processing.
Default:
true.
8. Configuration Options
一些binders有额外的binding 属性支持特定中间件的特性。
可以通过SpringBoot支持的任何机制向SpringCloudStream应用程序提供配置选项。
这包括应用程序参数、环境变量和YAML或.properties文件。
8.1 Binding Service Properties
These properties are exposed via org.springframework.cloud.stream.config.BindingServiceProperties
- spring.cloud.stream.instanceCount
-
The number of deployed instances of an application. Must be set for partitioning on the producer side. Must be set on the consumer side when using RabbitMQ and with Kafka if
autoRebalanceEnabled=false.Default:
1. - spring.cloud.stream.instanceIndex
- The instance index of the application: A number from
0toinstanceCount - 1. Used for partitioning with RabbitMQ and with Kafka ifautoRebalanceEnabled=false. Automatically set in Cloud Foundry to match the application’s instance index. - spring.cloud.stream.dynamicDestinations
-
A list of destinations that can be bound dynamically (for example, in a dynamic routing scenario). If set, only listed destinations can be bound.
Default: empty (letting any destination be bound).
- spring.cloud.stream.defaultBinder
-
The default binder to use, if multiple binders are configured. See Multiple Binders on the Classpath.
Default: empty.
- spring.cloud.stream.overrideCloudConnectors
-
This property is only applicable when the
cloudprofile is active and Spring Cloud Connectors are provided with the application. If the property isfalse(the default), the binder detects a suitable bound service (for example, a RabbitMQ service bound in Cloud Foundry for the RabbitMQ binder) and uses it for creating connections (usually through Spring Cloud Connectors). When set totrue, this property instructs binders to completely ignore the bound services and rely on Spring Boot properties (for example, relying on thespring.rabbitmq.*properties provided in the environment for the RabbitMQ binder). The typical usage of this property is to be nested in a customized environment when connecting to multiple systems.Default:
false. - spring.cloud.stream.bindingRetryInterval
-
The interval (in seconds) between retrying binding creation when, for example, the binder does not support late binding and the broker (for example, Apache Kafka) is down. Set it to zero to treat such conditions as fatal, preventing the application from starting.
Default:
30
8.2 Binding Properties
Binding properties are supplied by using the format of spring.cloud.stream.bindings.<channelName>.<property>=<value>. The <channelName> represents the name of the channel being configured (for example, output for a Source).
To avoid repetition, Spring Cloud Stream supports setting values for all channels, in the format of spring.cloud.stream.default.<property>=<value>.
When it comes to avoiding repetitions for extended binding properties, this format should be used - spring.cloud.stream.<binder-type>.default.<producer|consumer>.<property>=<value>.
In what follows, we indicate where we have omitted the spring.cloud.stream.bindings.<channelName>. prefix and focus just on the property name, with the understanding that the prefix ise included at runtime.
8.2.1 Common Binding Properties
These properties are exposed via org.springframework.cloud.stream.config.BindingProperties
The following binding properties are available for both input and output bindings and must be prefixed with spring.cloud.stream.bindings.<channelName>. (for example, spring.cloud.stream.bindings.input.destination=ticktock).
Default values can be set by using the spring.cloud.stream.default prefix (for example`spring.cloud.stream.default.contentType=application/json`).
- destination
- The target destination of a channel on the bound middleware (for example, the RabbitMQ exchange or Kafka topic). If the channel is bound as a consumer, it could be bound to multiple destinations, and the destination names can be specified as comma-separated
Stringvalues. If not set, the channel name is used instead. The default value of this property cannot be overridden. - group
-
The consumer group of the channel. Applies only to inbound bindings. See Consumer Groups.
Default:
null(indicating an anonymous consumer). - contentType
-
The content type of the channel. See “Chapter 9, Content Type Negotiation”.
Default:
application/json. - binder
-
The binder used by this binding. See “Section 7.4, “Multiple Binders on the Classpath”” for details.
Default:
null(the default binder is used, if it exists).
8.2.2 Consumer Properties
These properties are exposed via org.springframework.cloud.stream.binder.ConsumerProperties
The following binding properties are available for input bindings only and must be prefixed with spring.cloud.stream.bindings.<channelName>.consumer. (for example, spring.cloud.stream.bindings.input.consumer.concurrency=3).
Default values can be set by using the spring.cloud.stream.default.consumer prefix (for example, spring.cloud.stream.default.consumer.headerMode=none).
- concurrency
-
The concurrency of the inbound consumer.
Default:
1. - partitioned
-
Whether the consumer receives data from a partitioned producer.
Default:
false. - headerMode
-
When set to
none, disables header parsing on input. Effective only for messaging middleware that does not support message headers natively and requires header embedding. This option is useful when consuming data from non-Spring Cloud Stream applications when native headers are not supported. When set toheaders, it uses the middleware’s native header mechanism. When set toembeddedHeaders, it embeds headers into the message payload.Default: depends on the binder implementation.
- maxAttempts
-
If processing fails, the number of attempts to process the message (including the first). Set to
1to disable retry.Default:
3. - backOffInitialInterval
-
The backoff initial interval on retry.
Default:
1000. - backOffMaxInterval
-
The maximum backoff interval.
Default:
10000. - backOffMultiplier
-
The backoff multiplier.
Default:
2.0. - defaultRetryable
-
Whether exceptions thrown by the listener that are not listed in the
retryableExceptionsare retryable.Default:
true. - instanceIndex
-
When set to a value greater than equal to zero, it allows customizing the instance index of this consumer (if different from
spring.cloud.stream.instanceIndex). When set to a negative value, it defaults tospring.cloud.stream.instanceIndex. See “Section 11.2, “Instance Index and Instance Count”” for more information.Default:
-1. - instanceCount
-
When set to a value greater than equal to zero, it allows customizing the instance count of this consumer (if different from
spring.cloud.stream.instanceCount). When set to a negative value, it defaults tospring.cloud.stream.instanceCount. See “Section 11.2, “Instance Index and Instance Count”” for more information.Default:
-1. - retryableExceptions
-
A map of Throwable class names in the key and a boolean in the value. Specify those exceptions (and subclasses) that will or won’t be retried. Also see
defaultRetriable. Example:spring.cloud.stream.bindings.input.consumer.retryable-exceptions.java.lang.IllegalStateException=false.Default: empty.
- useNativeDecoding
-
When set to
true, the inbound message is deserialized directly by the client library, which must be configured correspondingly (for example, setting an appropriate Kafka producer value deserializer). When this configuration is being used, the inbound message unmarshalling is not based on thecontentTypeof the binding. When native decoding is used, it is the responsibility of the producer to use an appropriate encoder (for example, the Kafka producer value serializer) to serialize the outbound message. Also, when native encoding and decoding is used, theheaderMode=embeddedHeadersproperty is ignored and headers are not embedded in the message. See the producer propertyuseNativeEncoding.Default:
false.
8.2.3 Producer Properties
These properties are exposed via org.springframework.cloud.stream.binder.ProducerProperties
The following binding properties are available for output bindings only and must be prefixed with spring.cloud.stream.bindings.<channelName>.producer. (for example, spring.cloud.stream.bindings.input.producer.partitionKeyExpression=payload.id).
Default values can be set by using the prefix spring.cloud.stream.default.producer (for example, spring.cloud.stream.default.producer.partitionKeyExpression=payload.id).
- partitionKeyExpression
-
A SpEL expression that determines how to partition outbound data. If set, or if
partitionKeyExtractorClassis set, outbound data on this channel is partitioned.partitionCountmust be set to a value greater than 1 to be effective. Mutually exclusive withpartitionKeyExtractorClass. See “Section 5.6, “Partitioning Support””.Default: null.
- partitionKeyExtractorClass
-
A
PartitionKeyExtractorStrategyimplementation. If set, or ifpartitionKeyExpressionis set, outbound data on this channel is partitioned.partitionCountmust be set to a value greater than 1 to be effective. Mutually exclusive withpartitionKeyExpression. See “Section 5.6, “Partitioning Support””.Default:
null. - partitionSelectorClass
-
A
PartitionSelectorStrategyimplementation. Mutually exclusive withpartitionSelectorExpression. If neither is set, the partition is selected as thehashCode(key) % partitionCount, wherekeyis computed through eitherpartitionKeyExpressionorpartitionKeyExtractorClass.Default:
null. - partitionSelectorExpression
-
A SpEL expression for customizing partition selection. Mutually exclusive with
partitionSelectorClass. If neither is set, the partition is selected as thehashCode(key) % partitionCount, wherekeyis computed through eitherpartitionKeyExpressionorpartitionKeyExtractorClass.Default:
null. - partitionCount
-
The number of target partitions for the data, if partitioning is enabled. Must be set to a value greater than 1 if the producer is partitioned. On Kafka, it is interpreted as a hint. The larger of this and the partition count of the target topic is used instead.
Default:
1. - requiredGroups
- A comma-separated list of groups to which the producer must ensure message delivery even if they start after it has been created (for example, by pre-creating durable queues in RabbitMQ).
- headerMode
-
When set to
none, it disables header embedding on output. It is effective only for messaging middleware that does not support message headers natively and requires header embedding. This option is useful when producing data for non-Spring Cloud Stream applications when native headers are not supported. When set toheaders, it uses the middleware’s native header mechanism. When set toembeddedHeaders, it embeds headers into the message payload.Default: Depends on the binder implementation.
- useNativeEncoding
-
When set to
true, the outbound message is serialized directly by the client library, which must be configured correspondingly (for example, setting an appropriate Kafka producer value serializer). When this configuration is being used, the outbound message marshalling is not based on thecontentTypeof the binding. When native encoding is used, it is the responsibility of the consumer to use an appropriate decoder (for example, the Kafka consumer value de-serializer) to deserialize the inbound message. Also, when native encoding and decoding is used, theheaderMode=embeddedHeadersproperty is ignored and headers are not embedded in the message. See the consumer propertyuseNativeDecoding.Default:
false. - errorChannelEnabled
-
When set to
true, if the binder supports asynchroous send results, send failures are sent to an error channel for the destination. SeeSection 6.4, “Error Handling”for more information.Default:
false.
8.3 Using Dynamically Bound Destinations
9. Content Type Negotiation
10. Schema Evolution Support
11. Inter-Application Communication
12. Testing
13. Health Indicator
14. Metrics Emitter
15. Samples
Spring Cloud Stream 中 RabbitMQ Binder实现
1、使用
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-stream-binder-rabbit</artifactId>
</dependency>
或者
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
2. RabbitMQ Binder Overview
下图展示了RabbitMQ绑定器(Binder)实现的操作方式
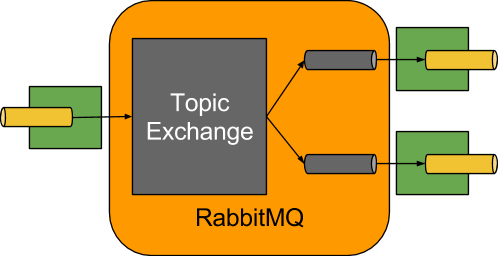
默认情况下,RabbitMQ Binder实现将每个destination映射到Topic交换器(Exchange)。
对于每个consumer group,一个Queue 绑定到这个TopicExchange。
每个consumer 实例都有相应的RabbitMQ consumer 实例连接到该consumer group对应的队列(queue)。
为了分区生产者和使用者,队列以分区索引作为后缀,并使用分区索引作为路由键(routing key)。
对于匿名consumer (那些没有组属性的用户),使用自动删除队列(具有随机唯一名称)。
通过使用可选的autoBindDlq选项,您可以配置binder来创建和配置死信队列(DLQs)(以及死信交换器DLX以及路由基础设施)。
默认情况下,死信队列的名称为destination.dlq。
如果启用了重试(maxAttempt>1),则在重试结束后,失败的消息将传递给DLQ。
如果禁用重试(maxAttempt=1),则应将requeueRejected设置为false(默认值),那么失败的消息会路由到DLQ,而不是重新排队。
此外,republishToDlq会导致binder 将失败的消息发布到DLQ(而不是拒绝它)。
此特性允许将附加信息(例如在header中的x-exception-stacktrace的堆栈跟踪信息)添加到报头中的消息中。
有关截断堆栈跟踪的信息,请参阅FrameMaxHeadRoom属性。
此选项不需要启用重试。只需重试一次,就可以重新发布失败的消息。从版本1.2开始,您可以配置重新发布消息的传递模式。请参见rePublishDeliveryMode属性。
如果流监听器抛出一个ImmediateAcKnowamqpException,则会绕过DLQ并简单地丢弃消息。从Version 2.1开始,不管rePublishToDlq的设置如何,都会这样执行;以前,则只有在rePublishToDlq为false时才是如此。
重要:!!!!!!!!!!!
将requeueRejected设置为true(二设置rePublishToDlq=false)将导致消息被重新排队并不断地重新传递,除非故障的原因是短暂的,否则通常不是您想要的。
通常,您应该在绑定器中启用重试,方法是将maxAttempt设置为大于1,或者将rePublishToDlq设置为true。
有关这些属性的更多信息,请参见3.1节“RabbitMQ绑定器属性”。
该框架没有提供任何标准机制来使用死信消息(或将它们重新路由回主队列)。一些选项将在第6章“死信队列处理”中描述.
当在SpringCloudStream应用程序中使用多个RabbitMQ Binder时,一定要禁用“RabbitAutoConfiguration”,以避免将RabbitAutoConfiguration中相同的配置应用到这几个Binder中。你可以使用@SpringBootApplication注释来排除掉这个类。
从版本2.0开始,RabbitMessageChannelBinder将RabbitTemplate.userPublisherConnection属性设置为true,避免非事务producers对consumers造成死锁,如果由于代理上的内存警报而阻塞缓存连接,则可能发生死锁。
目前,只有消息驱动的消费 才支持多工使用者(一个侦听多个队列的使用者)polled consumers只能从单个队列中检索消息。
3. Configuration Options
本节包含特定于RabbitMQ绑定程序和绑定通道的设置
对于通用的设置,请参考Spring Cloud Stream Core的文档
3.1 RabbitMQ Binder Properties
默认情况下,RabbitMQ Binder使用SpringBoot的ConnectionFactory。因此,它支持所有SpringBoot配置选项(有关参考,请参阅SpringBoot文档)。RabbitMQ配置选项使用Spring.rabbitmq前缀。
除了SpringBoot选项之外,RabbitMQ绑定程序还支持以下属性:
spring.cloud.stream.rabbit.binder.adminAddresses
一个以逗号分隔的RabbitMQ管理插件URL列表.仅当节点包含多个条目时才使用。此列表中的每个条目必须在Spring.rabbitmq.Address中有相应的条目。
Only needed if you use a RabbitMQ cluster and wish to consume from the node that hosts the queue. See Queue Affinity and the LocalizedQueueConnectionFactory for more information.
默认值:空。
spring.cloud.stream.rabbit.binder.nodes
以逗号分隔的RabbitMQ节点名称列表。当有多个条目时,用于定位队列所在的服务器地址。此列表中的每个条目必须在Spring.rabbitmq.Address中有相应的条目。
Only needed if you use a RabbitMQ cluster and wish to consume from the node that hosts the queue. See Queue Affinity and the LocalizedQueueConnectionFactory for more information.
默认值:空。
spring.cloud.stream.rabbit.binder.compressionLevel
压缩绑定的压缩级别。参见java.util.zip.Deflater。
Default: 1 (BEST_LEVEL).
spring.cloud.stream.binder.connection-name-prefix
A connection name prefix used to name the connection(s) created by this binder. The name is this prefix followed by #n, where n increments each time a new connection is opened.
一个连接名前缀,用于命名binder创建的连接。名称后跟着#n,每次创建新连接,n都会递增。
Default: none (Spring AMQP default).
3.2 RabbitMQ Consumer Properties
以下属性仅适用于 Rabbit consumers,必须以spring.cloud.stream.rabbit.bindings.<channelName>.consumer..作为前缀
- acknowledgeMode
-
确认模式。
Default:
AUTO. - autoBindDlq
-
是否自动声明DLQ并将其绑定到绑定器DLX。
Default:
false. - bindingRoutingKey
-
The routing key with which to bind the queue to the exchange (if
bindQueueistrue). For partitioned destinations,-<instanceIndex>is appended.将queue 绑定到Exchange使用的路由键(如果bindQueue为true)。为了给destinations分区,附加-<instanceIndex>。
Default:
#. - bindQueue
-
是否声明queue 并将其绑定到目标exchange。如果您已经设置了自己的基础结构,并且已经创建并绑定了队列,则将其设置为false。
Default:
true. - consumerTagPrefix
-
用于创建consumer 标记;将由#n追加,每创建一个consumer 则自增1。
示例:${spring.application.name}-${spring.cloud.stream.bindings.input.group}-${spring.cloud.stream.instance-index}.
默认值:无-代理将生成随机的使用者标记。
- deadLetterQueueName
-
The name of the DLQ
Default:
prefix+destination.dlq - deadLetterExchange
-
A DLX to assign to the queue. Relevant only if
autoBindDlqistrue.Default: 'prefix+DLX'
- deadLetterExchangeType
-
The type of the DLX to assign to the queue. Relevant only if
autoBindDlqistrue.Default: 'direct'
- deadLetterRoutingKey
-
A dead letter routing key to assign to the queue. Relevant only if
autoBindDlqistrue.Default:
destination - declareDlx
-
Whether to declare the dead letter exchange for the destination. Relevant only if
autoBindDlqistrue. Set tofalseif you have a pre-configured DLX.是否为destination创建死信exchange。只有当autoBindDlq为true时才考虑设置。如果您有预先配置的DLX,则设置为false。
Default:
true. - declareExchange
-
Whether to declare the exchange for the destination.
Default:
true. - delayedExchange
-
Whether to declare the exchange as a
Delayed Message Exchange. Requires the delayed message exchange plugin on the broker. Thex-delayed-typeargument is set to theexchangeType.是否将exchange 定义为Delayed Message Exchange。Requires the delayed message exchange plugin on the broker. The
x-delayed-typeargument is set to theexchangeType.Default:
false. - dlqDeadLetterExchange
-
如果声明了DLQ,则向该队列分配DLX。
Default:
none - dlqDeadLetterRoutingKey
-
如果声明了DLQ,则向该队列分配一个死信路由键。
Default:
none - dlqExpires
-
删除未使用的死信队列的时间(以毫秒为单位)。
Default:
no expiration - dlqLazy
-
Declare the dead letter queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue.使用
x-queue-mode=lazy参数声明死信队列。See “Lazy Queues”. 考虑使用策略而不是此设置,因为使用策略可以在不删除队列的情况下更改设置。Default:
false. - dlqMaxLength
-
Maximum number of messages in the dead letter queue.
Default:
no limit - dlqMaxLengthBytes
-
Maximum number of total bytes in the dead letter queue from all messages.
Default:
no limit - dlqMaxPriority
-
Maximum priority of messages in the dead letter queue (0-255).
死信队列(0-255)中消息的最大优先级。
Default:
none - dlqOverflowBehavior
-
Action to take when
dlqMaxLengthordlqMaxLengthBytesis exceeded; currentlydrop-headorreject-publishbut refer to the RabbitMQ documentation.当超过dlqMaxLength或dlqMaxLengthBytes时要采取的操作;当前是
drop-headorreject-publish,但请参考RabbitMQ文档。Default:
none - dlqTtl
-
Default time to live to apply to the dead letter queue when declared (in milliseconds).
声明一个死信队列时,引用的默认存货时间(以毫秒为单位)
Default:
no limit - durableSubscription
-
Whether the subscription should be durable. Only effective if
groupis also set.订阅是否应该持久化。只有在也设置
group的情况下才有效。Default:
true. - exchangeAutoDelete
-
If
declareExchangeis true, whether the exchange should be auto-deleted (that is, removed after the last queue is removed).如果declareExchange为true,这里设置是否应自动删除exchange (最后一个队列被删除后,这个exchange会别删除)。
Default:
true. - exchangeDurable
-
If
declareExchangeis true, whether the exchange should be durable (that is, it survives broker restart).如果declareExchange为true,则该exchange 是否应是持久的(也就是说,几时重启代理,他仍然存在)。
Default:
true. - exchangeType
-
The exchange type:
direct,fanoutortopicfor non-partitioned destinations anddirectortopicfor partitioned destinations.Default:
topic. - exclusive
-
Whether to create an exclusive consumer. Concurrency should be 1 when this is
true. Often used when strict ordering is required but enabling a hot standby instance to take over after a failure. SeerecoveryInterval, which controls how often a standby instance attempts to consume.是否创建独占消费者。如果为true,那么并发性应该是1。 Often used when strict ordering is required but enabling a hot standby instance to take over after a failure. See
recoveryInterval, which controls how often a standby instance attempts to consume.Default:
false. - expires
-
How long before an unused queue is deleted (in milliseconds).
删除未使用队列的时间(以毫秒为单位)。
Default:
no expiration - failedDeclarationRetryInterval
-
The interval (in milliseconds) between attempts to consume from a queue if it is missing.
如果队列丢失,尝试从队列中消耗的间隔(以毫秒为单位)。
Default: 5000
- frameMaxHeadroom
-
The number of bytes to reserve for other headers when adding the stack trace to a DLQ message header. All headers must fit within the
frame_maxsize configured on the broker. Stack traces can be large; if the size plus this property exceedsframe_maxthen the stack trace will be truncated. A WARN log will be written; consider increasing theframe_maxor reducing the stack trace by catching the exception and throwing one with a smaller stack trace.将堆栈跟踪添加到DLQ消息头时为其他标头保留的字节数。所有标头必须符合代理上配置的框架_max大小。堆栈跟踪可以很大;如果大小加上此属性超过Framemax,则堆栈跟踪将被截断。将写入一个警告日志;考虑通过捕获异常并抛出一个具有较小堆栈跟踪的异常来增加Framemax或减少堆栈跟踪。
Default: 20000
- headerPatterns
-
Patterns for headers to be mapped from inbound messages.
从入站消息映射标题的模式。
Default:
['*'](all headers). - lazy
-
Declare the queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue.使用x-queue-mode=lazy参数声明队列。 See “Lazy Queues”. ”。考虑使用策略而不是此设置,因为使用策略可以在不删除队列的情况下更改设置。
Default:
false. - maxConcurrency
-
The maximum number of consumers.
最大数量的消费者。
Default:
1. - maxLength
-
The maximum number of messages in the queue.
队列中的最大消息数。
Default:
no limit - maxLengthBytes
-
The maximum number of total bytes in the queue from all messages.
队列中来自所有消息的最大字节数。
Default:
no limit - maxPriority
-
The maximum priority of messages in the queue (0-255).
队列中消息的最大优先级(0-255)。
Default:
none - missingQueuesFatal
-
When the queue cannot be found, whether to treat the condition as fatal and stop the listener container. Defaults to
falseso that the container keeps trying to consume from the queue — for example, when using a cluster and the node hosting a non-HA queue is down.当找不到队列时,是否将此情况视为致命状态并停止侦听器容器。默认为false,这样容器就一直试图从队列中消费-例如,当使用集群和承载非HA队列的节点时。
Default:
false - overflowBehavior
-
Action to take when
maxLengthormaxLengthBytesis exceeded; currentlydrop-headorreject-publishbut refer to the RabbitMQ documentation.当maxLength或maxLengthBytes被超过时要采取的操作;当前是
drop-headorreject-publish,但请参考RabbitMQ文档。Default:
none - prefetch
-
Prefetch count.
Default:
1. - prefix
-
A prefix to be added to the name of the
destinationand queues.Default: "".
- queueDeclarationRetries
-
The number of times to retry consuming from a queue if it is missing. Relevant only when
missingQueuesFatalistrue. Otherwise, the container keeps retrying indefinitely.如果缺少队列,则重试从队列中消耗的次数。只有在错误答案时才有关联。否则,容器将无限期地重试。
Default:
3 - queueNameGroupOnly
-
When true, consume from a queue with a name equal to the
group. Otherwise the queue name isdestination.group. This is useful, for example, when using Spring Cloud Stream to consume from an existing RabbitMQ queue.连接恢复尝试之间的间隔,以毫秒为单位。
Default: false.
- recoveryInterval
-
The interval between connection recovery attempts, in milliseconds.
连接恢复尝试之间的间隔,以毫秒为单位。
Default:
5000. - requeueRejected
-
Whether delivery failures should be re-queued when retry is disabled or
republishToDlqisfalse.当Retry被禁用时,是否应该重新排队传递失败,还是REREREDDlq是假的。
Default:
false.
- republishDeliveryMode
-
When
republishToDlqistrue, specifies the delivery mode of the republished message.当rePublishToDlq为true时,指定重新发布消息的传递模式。
Default:
DeliveryMode.PERSISTENT - republishToDlq
-
By default, messages that fail after retries are exhausted are rejected. If a dead-letter queue (DLQ) is configured, RabbitMQ routes the failed message (unchanged) to the DLQ. If set to
true, the binder republishs failed messages to the DLQ with additional headers, including the exception message and stack trace from the cause of the final failure. Also see the frameMaxHeadroom property.默认情况下,在重试结束后失败的消息将被拒绝。如果配置了死信队列(DLQ),RabbitMQ将失败消息(未更改)路由到DLQ。如果设置为true,则绑定器会将失败消息重新发布到DLQ,其中包含来自最终故障原因的异常消息和堆栈跟踪。还请参阅FrameMaxHeadRoom属性。
Default: false
- transacted
-
Whether to use transacted channels.
是否使用交易通道。
Default:
false. - ttl
-
Default time to live to apply to the queue when declared (in milliseconds).
声明时应用于队列的默认存活时间(以毫秒为单位)。
Default:
no limit - txSize
-
The number of deliveries between acks.
接送的数量。
Default:
1.
3.3 Advanced Listener Container Configuration
To set listener container properties that are not exposed as binder or binding properties, add a single bean of type ListenerContainerCustomizer to the application context. The binder and binding properties will be set and then the customizer will be called. The customizer (configure() method) is provided with the queue name as well as the consumer group as arguments.
若要设置未公开为绑定或绑定属性的侦听器容器属性,请将ListenerContainerCustomizer类型的单个bean添加到应用程序上下文中。将设置绑定器和绑定属性,然后调用自定义程序。定制器(配置()方法)提供了队列名和使用者组作为参数。
3.4 Rabbit Producer Properties
以下属性仅适用于Rabbit producers,必须以spring.cloud.stream.rabbit.bindings.<channelName>.producer..作为前缀
- autoBindDlq
-
Whether to automatically declare the DLQ and bind it to the binder DLX.
Default:
false. - batchingEnabled
-
Whether to enable message batching by producers. Messages are batched into one message according to the following properties (described in the next three entries in this list): 'batchSize',
batchBufferLimit, andbatchTimeout. See Batching for more information.Default:
false. - batchSize
-
The number of messages to buffer when batching is enabled.
Default:
100. - batchBufferLimit
-
The maximum buffer size when batching is enabled.
Default:
10000. - batchTimeout
-
The batch timeout when batching is enabled.
Default:
5000. - bindingRoutingKey
-
The routing key with which to bind the queue to the exchange (if
bindQueueistrue). Only applies to non-partitioned destinations. Only applies ifrequiredGroupsare provided and then only to those groups.Default:
#. - bindQueue
-
Whether to declare the queue and bind it to the destination exchange. Set it to
falseif you have set up your own infrastructure and have previously created and bound the queue. Only applies ifrequiredGroupsare provided and then only to those groups.Default:
true. - compress
-
Whether data should be compressed when sent.
Default:
false. - confirmAckChannel
-
When
errorChannelEnabledis true, a channel to which to send positive delivery acknowledgments (aka publisher confirms). If the channel does not exist, aDirectChannelis registered with this name. The connection factory must be configured to enable publisher confirms.Default:
nullChannel(acks are discarded). - deadLetterQueueName
-
The name of the DLQ Only applies if
requiredGroupsare provided and then only to those groups.Default:
prefix+destination.dlq - deadLetterExchange
-
A DLX to assign to the queue. Relevant only when
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: 'prefix+DLX'
- deadLetterExchangeType
-
The type of the DLX to assign to the queue. Relevant only if
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: 'direct'
- deadLetterRoutingKey
-
A dead letter routing key to assign to the queue. Relevant only when
autoBindDlqistrue. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
destination - declareDlx
-
Whether to declare the dead letter exchange for the destination. Relevant only if
autoBindDlqistrue. Set tofalseif you have a pre-configured DLX. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
true. - declareExchange
-
Whether to declare the exchange for the destination.
Default:
true. - delayExpression
-
A SpEL expression to evaluate the delay to apply to the message (
x-delayheader). It has no effect if the exchange is not a delayed message exchange.Default: No
x-delayheader is set. - delayedExchange
-
Whether to declare the exchange as a
Delayed Message Exchange. Requires the delayed message exchange plugin on the broker. Thex-delayed-typeargument is set to theexchangeType.Default:
false. - deliveryMode
-
The delivery mode.
Default:
PERSISTENT. - dlqDeadLetterExchange
-
When a DLQ is declared, a DLX to assign to that queue. Applies only if
requiredGroupsare provided and then only to those groups.Default:
none - dlqDeadLetterRoutingKey
-
When a DLQ is declared, a dead letter routing key to assign to that queue. Applies only when
requiredGroupsare provided and then only to those groups.Default:
none - dlqExpires
-
How long (in milliseconds) before an unused dead letter queue is deleted. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no expiration - dlqLazy
- Declare the dead letter queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue. Applies only whenrequiredGroupsare provided and then only to those groups. - dlqMaxLength
-
Maximum number of messages in the dead letter queue. Applies only if
requiredGroupsare provided and then only to those groups.Default:
no limit - dlqMaxLengthBytes
-
Maximum number of total bytes in the dead letter queue from all messages. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - dlqMaxPriority
-
Maximum priority of messages in the dead letter queue (0-255) Applies only when
requiredGroupsare provided and then only to those groups.Default:
none - dlqTtl
-
Default time (in milliseconds) to live to apply to the dead letter queue when declared. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - exchangeAutoDelete
-
If
declareExchangeistrue, whether the exchange should be auto-delete (it is removed after the last queue is removed).Default:
true. - exchangeDurable
-
If
declareExchangeistrue, whether the exchange should be durable (survives broker restart).Default:
true. - exchangeType
-
The exchange type:
direct,fanoutortopicfor non-partitioned destinations anddirectortopicfor partitioned destinations.Default:
topic. - expires
-
How long (in milliseconds) before an unused queue is deleted. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no expiration - headerPatterns
-
Patterns for headers to be mapped to outbound messages.
Default:
['*'](all headers). - lazy
-
Declare the queue with the
x-queue-mode=lazyargument. See “Lazy Queues”. Consider using a policy instead of this setting, because using a policy allows changing the setting without deleting the queue. Applies only whenrequiredGroupsare provided and then only to those groups.Default:
false. - maxLength
-
Maximum number of messages in the queue. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit - maxLengthBytes
-
Maximum number of total bytes in the queue from all messages. Only applies if
requiredGroupsare provided and then only to those groups.Default:
no limit - maxPriority
-
Maximum priority of messages in the queue (0-255). Only applies if
requiredGroupsare provided and then only to those groups.Default:
none - prefix
-
A prefix to be added to the name of the
destinationexchange.Default: "".
- queueNameGroupOnly
-
When
true, consume from a queue with a name equal to thegroup. Otherwise the queue name isdestination.group. This is useful, for example, when using Spring Cloud Stream to consume from an existing RabbitMQ queue. Applies only whenrequiredGroupsare provided and then only to those groups.Default: false.
- routingKeyExpression
-
A SpEL expression to determine the routing key to use when publishing messages. For a fixed routing key, use a literal expression, such as
routingKeyExpression='my.routingKey'in a properties file orroutingKeyExpression: '''my.routingKey'''in a YAML file.Default:
destinationordestination-<partition>for partitioned destinations. - transacted
-
Whether to use transacted channels.
Default:
false. - ttl
-
Default time (in milliseconds) to live to apply to the queue when declared. Applies only when
requiredGroupsare provided and then only to those groups.Default:
no limit
 |
|
In the case of RabbitMQ, content type headers can be set by external applications. Spring Cloud Stream supports them as part of an extended internal protocol used for any type of transport — including transports, such as Kafka (prior to 0.11), that do not natively support headers. |
4. Retry With the RabbitMQ Binder
5. Error Channels
6. Dead-Letter Queue Processing
7. Partitioning with the RabbitMQ Binder
【进阶技术】一篇文章搞掂:Spring Cloud Stream的更多相关文章
- 这事没完,继续聊spring cloud stream和kafka的这些小事
上一篇文章讲了如何用spring cloud stream集成kafka,并且跑起来一个demo,如果这一次宣传spring cloud stream的文章,其实到这里就可以啦.但实际上,工程永远不是 ...
- 一起来学spring Cloud | 第一章:spring Cloud 与Spring Boot
目前大家都在说微服务,其实微服务不是一个名字,是一个架构的概念,大家现在使用的基于RPC框架(dubbo.thrift等)架构其实也能算作一种微服务架构. 目前越来越多的公司开始使用微服务架构,所以在 ...
- Spring Cloud Stream消费失败后的处理策略(二):自定义错误处理逻辑
应用场景 上一篇<Spring Cloud Stream消费失败后的处理策略(一):自动重试>介绍了默认就会生效的消息重试功能.对于一些因环境原因.网络抖动等不稳定因素引发的问题可以起到比 ...
- 消息驱动式微服务:Spring Cloud Stream & RabbitMQ
1. 概述 在本文中,我们将向您介绍Spring Cloud Stream,这是一个用于构建消息驱动的微服务应用程序的框架,这些应用程序由一个常见的消息传递代理(如RabbitMQ.Apache Ka ...
- spring cloud 2.x版本 Spring Cloud Stream消息驱动组件基础教程(kafaka篇)
本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka-ri ...
- 官方文档中文版!Spring Cloud Stream 快速入门
本文内容翻译自官方文档,spring-cloud-stream docs,对 Spring Cloud Stream的应用入门介绍. 一.Spring Cloud Stream 简介 官方定义 Spr ...
- Spring Cloud Stream同一通道根据消息内容分发不同的消费逻辑
应用场景 有的时候,我们对于同一通道中的消息处理,会通过判断头信息或者消息内容来做一些差异化处理,比如:可能在消息头信息中带入消息版本号,然后通过if判断来执行不同的处理逻辑,其代码结构可能是这样的: ...
- Spring Cloud Stream消费失败后的处理策略(四):重新入队(RabbitMQ)
应用场景 之前我们已经通过<Spring Cloud Stream消费失败后的处理策略(一):自动重试>一文介绍了Spring Cloud Stream默认的消息重试功能.本文将介绍Rab ...
- Spring Cloud Stream消费失败后的处理策略(三):使用DLQ队列(RabbitMQ)
应用场景 前两天我们已经介绍了两种Spring Cloud Stream对消息失败的处理策略: 自动重试:对于一些因环境原因(如:网络抖动等不稳定因素)引发的问题可以起到比较好的作用,提高消息处理的成 ...
随机推荐
- pandas 入门(2)
from pandas import Series, DataFrame, Index import numpy as np from numpy import nan as NA obj = Ser ...
- 多线程06-Lock
; i < ; i++) { c.Increment(); c.Decrement(); ...
- Java判断一个日期是否在下周日期区间
Java实现判断一个日期是否在下周日期区间的方法 /** * 判断输入的日期是否在下周区间 * @return * @author nemowang */ public static boolean ...
- [2019杭电多校第五场][hdu6625]three arrays(01字典树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6625 大意为给你两个数组a和b,对应位置异或得到c数组,现在可以将a,b数组从新排序求c数组,使得字典 ...
- Delphi Unicode学习
String.AnsiString及Tbytes之间的转换一.string转为AnsiString1.直接赋值 (有警告)2.AnsiString()类型强制转换.(无警告) 二.AnsiString ...
- Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介)
原文:Elasticsearch7.X 入门学习第四课笔记---- Search API之(Request Body Search 和DSL简介) 版权声明:本文为博主原创文章,遵循CC 4.0 BY ...
- 29、前端知识点--session\cookie\token
Java Token的原理和生成使用机制 https://yq.aliyun.com/articles/594217 Cookies Session Token 三者区别及应用场景 https://w ...
- hash和history
location.hash="aaa" history.pushState({},'', "home") history.replaceState() hist ...
- .net 项目中应用Web Services(vs2012)
一.在asp.net项目中添加Web services1.新建一个asp.net项目(目前尚未验证是否可以在MVC项目中添加)2.在项目名上右击,选择添加→新建项→Web服务,输好名称后确定即可 二. ...
- js 一个不得不注意的浏览器兼容性问题 进制转换
写几行JS代码 var num = '022'; alert(num+' '+parseInt(num)+' '+parseInt(num,10)); 不同的浏览器将会得到不同的结果在谷歌浏览器下的结 ...