R_Studio模拟学生成绩对数据简单分析
模拟产生学生名单,记录高数,英语,网站开发三科成绩,然后进行统计分析
假设有100名学生,起始学号为161304000,各科成绩取整
高数成绩为均匀分布随机函数,都在75分以上
英语成绩为正态分布,平均成绩80
网站开发成绩为正态分布,平均成绩83,标准差18,
正态分布中超过100分的成绩变成100分
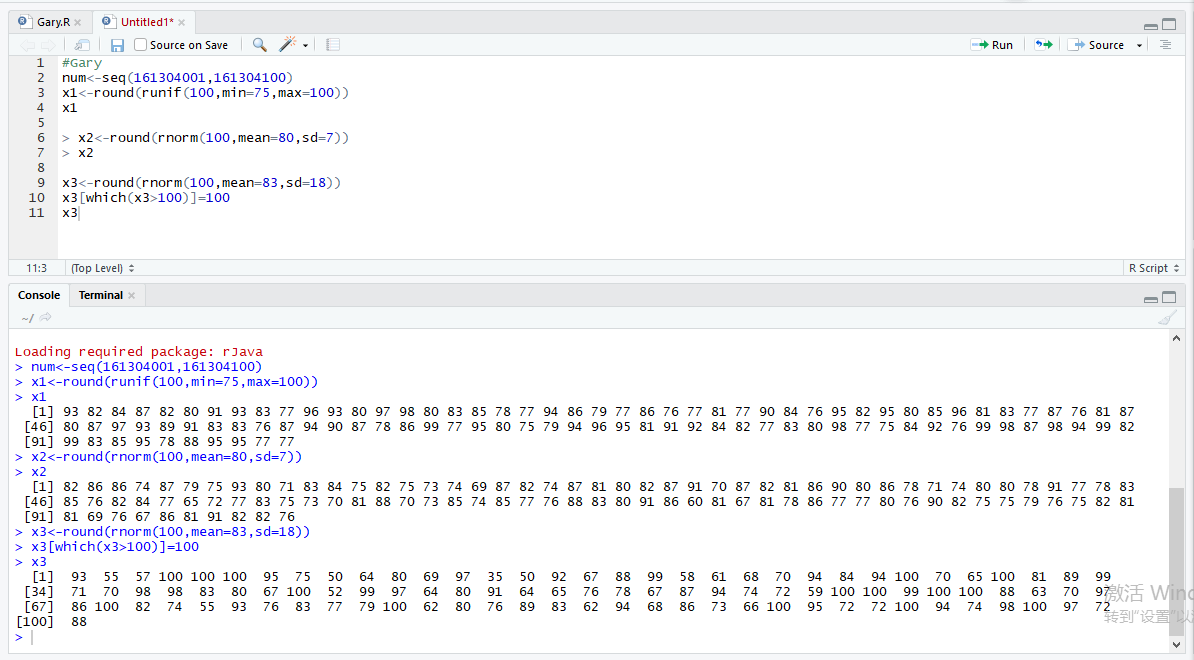
生成学号、三科成绩
生成学号
num<-seq(,)
生成高数成绩
高数成绩为均匀分布随机数,都在 75 分以上
均匀分布函数:runif(n,min=0,max=1) 其中,n 为产生随机值个数(长度),min 为最小值,max 为最大值。
x1<-round(runif(,min=,max=))
生成英语成绩
英语成绩为正态分布,平均成绩 80,标准差为 7
正态分布函数:rnorm(n, mean=0,sd= 1) 其中,n 为产生随机值个数(长度) ,mean 是平均数, sd 是标准差
x2<-round(rnorm(,mean=,sd=))
生成网站开发成绩
网站开发成绩为正态分布,平均成绩 83,标准差为 18。 其中大于 100 的都记为 100
x3<-round(rnorm(,mean=,sd=))
x3[which(x3>)]=
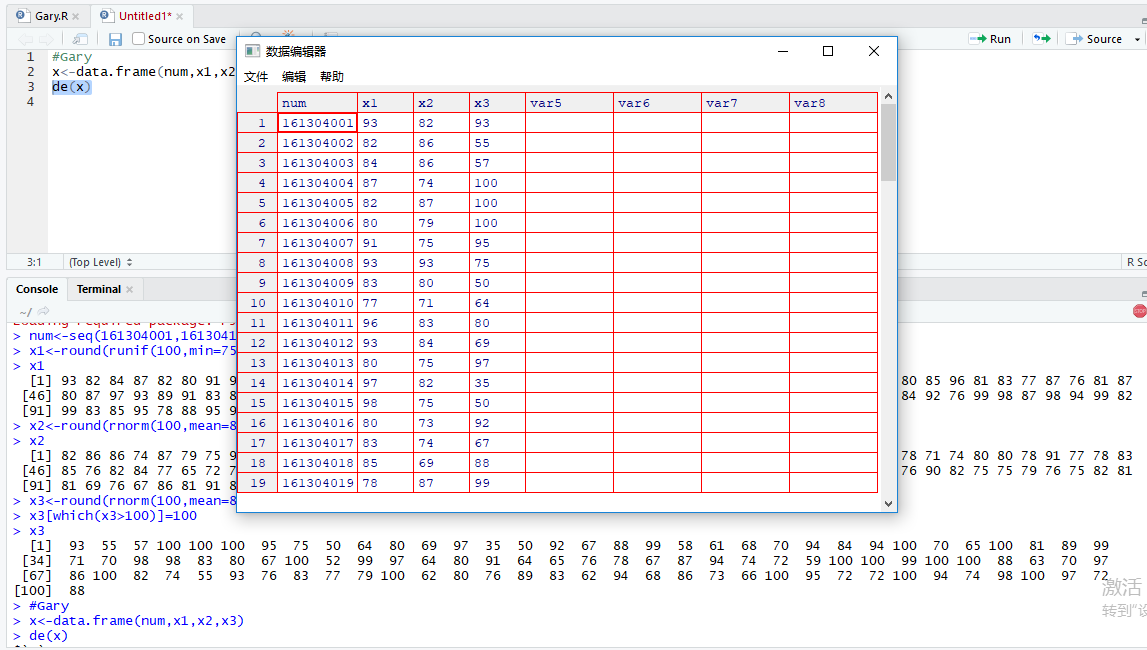
讲数据写入文本框
生成文本文件
x<-data.frame(num,x1,x2,x3)
打开数据框
de(x)
平均分
apply(x,,mean)
x4<-apply(x[c("x1","x2","x3")],,mean)
x$x4<round(x4)
x4
总分
apply(x,,sum)
x5<-apply(x[c("x1","x2","x3")],,sum)
x$x5<round(x5)
x5
最低分
apply(x,,min)
x6<-apply(x[c("x1","x2","x3")],,min)
x$x6<round(x6)
x5
最高分
apply(x,,max)
x7<-apply(x[c("x1","x2","x3")],,max)
x$x7<round(x7)
x7
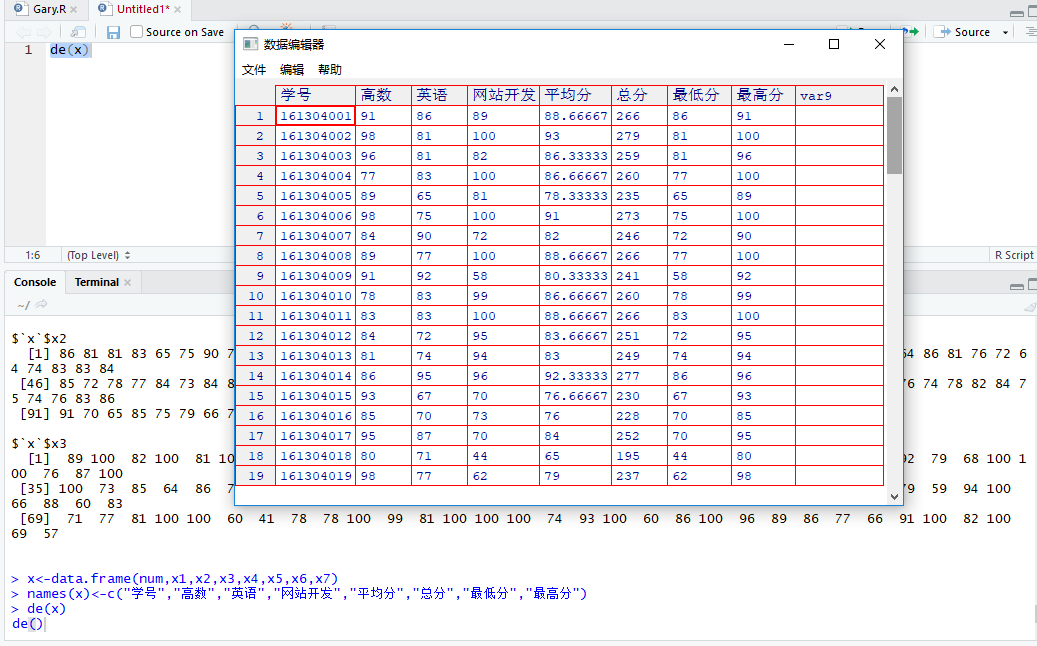
在数据框中命名变量
names(x)<-c("学号","高数","英语","网站开发","平均分","总分","最低分","最高分")
重新写入数据并命名
x<-data.frame(num,x1,x2,x3,x4,x5,x6,x7)
names(x)<-c("学号","高数","英语","网站开发","平均分","总分","最低分","最高分")
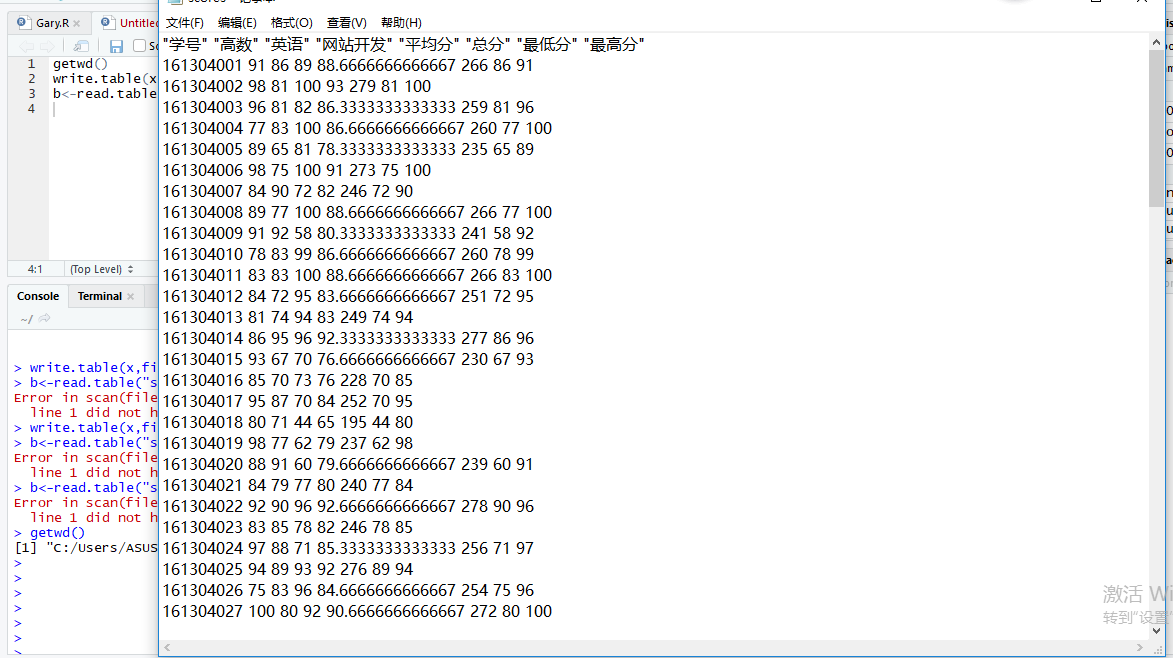
将生成的数据写入文本
write.table(x,file="scores.txt",col.names=T,row.name=F,sep=" ")
b<-read.table("scores.txt",head=T)
getwd() 可查找到文件所放置目录
单例输出
学生总成绩
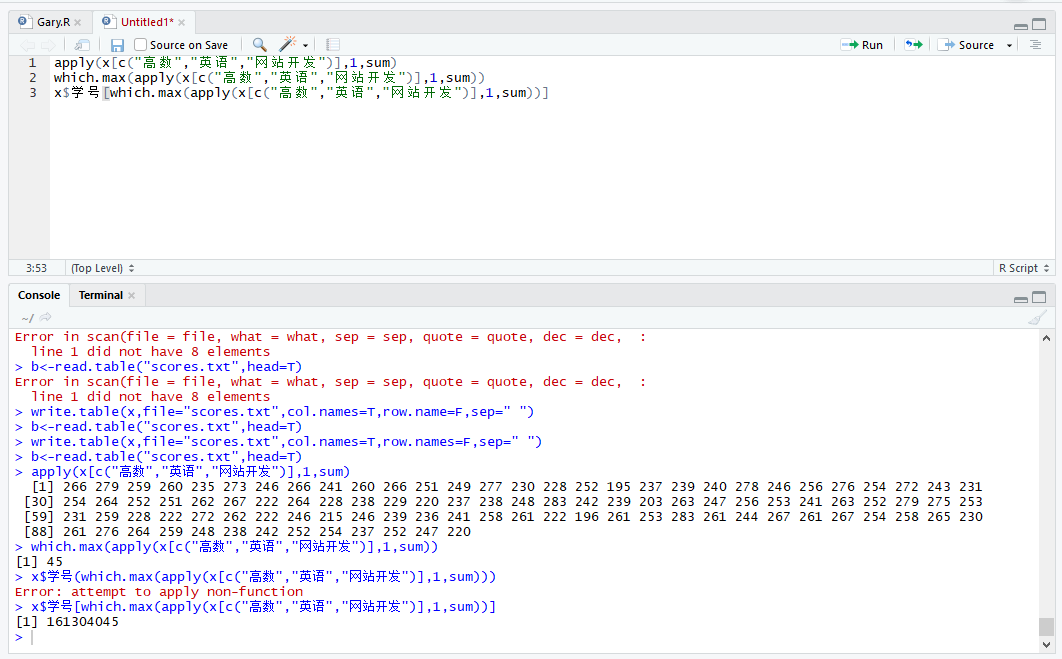
apply(x[c("高数","英语","网站开发")],,sum)
求成绩最高num
which.max(apply(x[c("高数","英语","网站开发")],,sum))
求成绩最高学号
x$学号[which.max(apply(x[c("高数","英语","网站开发")],,sum))]
绘图
hist(x[,],main="直方图")
plot(x[,],x[,],pch=,bg="green",main="散点图",xlab="学生学号",ylab="高数成绩")
barplot(x[,],main="网站开发成绩条形图")
pie(:,x[,],main="高数成绩饼状图")
boxplot(x[,],col=c("green","red","blue")) #箱尾图
R_Studio模拟学生成绩对数据简单分析的更多相关文章
- R_Studio(学生成绩)对数据缺失值md.pattern()、异常值分析(箱线图)
我们发现这张Gary.csv表格存在学生成绩不完全的(五十三名学生,三名学生存在成绩不完整.共四个不完整成绩) 79号大学语文.高等数学 96号中国近代史纲要 65号大学体育 (1)NA表示数据集中的 ...
- 基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
目录 1 准备工作 2 具体实施 1 准备工作 什么是Redis? Redis:一个高性能的key-value数据库.支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使 ...
- R_Studio(学生成绩)对数据进行属性构造处理
对“Gary.csv”中数据进行进行属性构造处理,增加“总成绩”属性 Gary.csv setwd('D:\\data') list.files() #数据读取 dat=read.csv(file=& ...
- 使用Java模拟一个简单的Dos学生成绩管理系统:
使用Java模拟学生成绩管理系统... ------------------- 学生成绩管理系统:需要实现的功能:1.录入学生的姓名和成绩2.显示列表.列表中包括学生姓名与成绩3.显示最高分.最低分的 ...
- php中CURL技术模拟登陆抓取数据实战,抓取某校教务处学生成绩。
这两天有基友要php中curl抓取教务处成绩的源码,用于微信公众平台的开发.下面笔者只好忍痛割爱了.php中CURL技术模拟登陆抓取数据实战,抓取沈阳工学院教务处学生成绩. 首先,教务处登录需要验证码 ...
- python实现人人网用户数据爬取及简单分析
这是之前做的一个小项目.这几天刚好整理了一些相关资料,顺便就在这里做一个梳理啦~ 简单来说这个项目实现了,登录人人网并爬取用户数据.并对用户数据进行分析挖掘,终于效果例如以下:1.存储人人网用户数据( ...
- 题目1018:统计同成绩学生人数(hash简单应用)
问题来源 http://ac.jobdu.com/problem.php?pid=1018 问题描述 给你n位同学的成绩,问获得某一成绩的学生有多少位. 问题分析 初见此题,有人会想到先将所有成绩存入 ...
- 通过excel表格分析学生成绩
题目要求: 分析文件’课程成绩.xlsx’,至少要完成内容:分析1)每年不同班级平均成绩情况.2)不同年份总体平均成绩情况.3)不同性别学生成绩情况,并分别用合适的图表展示出三个内容的分析结果. 废话 ...
- R_Studio(学生成绩)使用cbind()函数对多个学期成绩进行集成
“Gary1.csv”.“Gary2.csv”.“Gary3.csv”中保存了一个班级学生三个学期的成绩 对三个学期中的成绩数据进行集成并重新计算综合成绩和排名,并按排名顺序排布(学号9位数11130 ...
随机推荐
- python-day10(正式学习)
目录 字符编码 计算机基础 文本编辑器存取文件的原理 python解释器执行py文件的原理 python解释器与文本编辑的异同 字符编码介绍 字符编码的分类 乱码分析 总结 文件操作 三种基本操作 文 ...
- tomcat启动报ClassNotFound
排除本来就缺少该类的原因,经过自己经验和网上查的资料,解决方式如下: jar包冲突(关闭其他项目) eclipse的java版本不对,点击项目,右键properties在project facets, ...
- spring + dubbo 学习
新启动的项目中可能会使用到dubbo,因为之前并没有接触过,所以先小试一下 示例运行环境准备:OS X 10.10.5 + java version "1.8.0_40" zook ...
- 本人亲测-Setup Factory打包教程(整理并优化)
Setup Factory 9 总结 一:安装完毕立刻启动 result = Shell.Execute(SessionVar.Expand("%AppFolder%\\消息助手.exe&q ...
- JS常用自定义函数总结
JS常用自定义函数总结 1.原生JavaScript实现字符串长度截取 2.原生JavaScript获取域名主机 3.原生JavaScript清除空格 4.原生JavaScript替换全部 5.原 ...
- 第96:SVM简介与简单应用
详细推到见:https://blog.csdn.net/v_july_v/article/details/7624837 python实现方式:
- centos7安装jdk和tomcat
1,先卸载掉openjdk rpm -qa | grep java 卸载 sudo rpm -e --nodeps 加 需要卸载的 或者直接 rpm -e `rpm -qa | grep java` ...
- MySQL select之后再update
1.先查询页面 而后再根据查询的结果来更改数据库,可以使用SELECT …… FOR UPDATE 来实现,具体的代码如下 SELECT * FROM chat //查询的表 //查询的条件 FOR ...
- RAID原理详解
RAID 0(stripe,条带化存储):在RAID级别中最高的存储性能. 原理:是把连续的数据分散到多个磁盘上存取,系统有数据请求就可以被多个磁盘并行的执行,每个磁盘执行属于他自己的那部分数据请求. ...
- 线程池ThreadPool
在面向对象编程中,经常会面对创建对象和销毁对象的情况,如果不正确处理的话,在短时间内创建大量对象然后执行简单处理之后又要销毁这些刚刚建立的对象,这是一个非常消耗性能的低效行为,所以很多面向对象语言中在 ...