java并发学习--第四章 JDK提供的线程原子性操作工具类
在了解JDK提供的线程原子性操作工具类之前,我们应该先知道什么是原子性:在多线程并发的条件下,对于变量的操作是线程安全的,不会受到其他线程的干扰。接下来我们就学习JDK中线程的原子性操作。
一、CAS原理
说道原子性,不得不提的就是CAS原理:
使用锁时,线程获取锁是一种悲观锁策略,即假设每一次执行临界区代码都会产生冲突,所以当前线程获取到锁的时候同时也会阻塞其他线程获取该锁。而CAS操作(又称为无锁操作)是一种乐观锁策略,它假设所有线程访问共享资源的时候不会出现冲突,既然不会出现冲突自然而然就不会阻塞其他线程的操作。因此,线程就不会出现阻塞停顿的状态。那么,如果出现冲突了怎么办?无锁操作是使用CAS(compare and swap)又叫做比较交换来鉴别线程是否出现冲突,出现冲突就重试当前操作直到没有冲突为止。
CAS既然和锁有关,那么它和Synchronized有什么区别呢:
元老级的Synchronized(未优化前)最主要的问题是:在存在线程竞争的情况下会出现线程阻塞和唤醒锁带来的性能问题,因为这是一种互斥同步(阻塞同步)。而CAS并不是武断的间线程挂起,当CAS操作失败后会进行一定的尝试,而非进行耗时的挂起唤醒的操作,因此也叫做非阻塞同步。这是两者主要的区别。
二、原子更新基本类型
在我们实际开发中,线程原子性问题是比较常见的地方,最简单的例子:i ++;i ++是我们开发中一定会用到的一段代码,但是你知道吗,i ++在多线程环境中是不安全的,我们接下来通过一个例子来说明为什么i ++不安全:
public class Demo2 implements Runnable {
//给线程方法传递一个参数
static int count=0;
/**
*线程任务,将count的值遍历到10000再输出
*/
public void run() {
System.out.println("当前线程获取count的值为:"+count);
for (int i = 0; i < 10000; i++) {
count++;
}
}
public static void main(String[] args) throws InterruptedException {
//创建多线程环境,这里创建了10个线程
Thread[] thread = new Thread[10];
//未创建的多线程中添加线程任务
for (int i = 0; i < 10; i++) {
thread[i] = new Thread(new Demo2());
}
//启动每个线程任务
for (int i = 0; i < 10; i++) {
thread[i].start();
}
//join方法的作用是阻塞主线程,防止还没有计算完成,就开始输出count的值了
for (int i = 0; i < 10; i++) {
thread[i].join();
}
System.out.println("count计算的结果是:"+count);
}
}
运行的结果是:
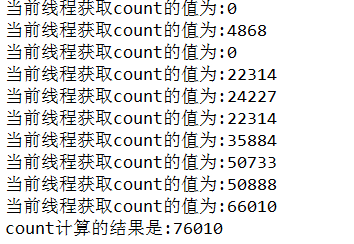
这里的 count++就是我们说的i ++;可以很明确的看到,count的值除了重复获取外, 执行count++操作时,也是有问题的,这个问题的原因是:count在执行++操作时,因为是多线程环境,假设count的值在第一个线程获取为0了但是还没有完成++操作,就有第二个线程抢到了CPU资源,此时count的值还是0,所以就出现了这个数据重复获取,导致count++操作不准确,因此count++是线程不安全的。
面对这样的问题,JDK为我们提供了原子基本类型来解决,一个有三个:
AtomicBoolean:原子更新布尔类型
AtomicInteger:原子更新整型
AtomicLong:原子更新长整型
这个三个类中的方法都一致,我们主要使用的是:
get():直接返回值
getAndIncrement():以原子方式将当前值加1,相当于线程安全的i++操作
incrementAndGet():以原子方式将当前值加1,相当于线程安全的++i操作
其他的方法可以参考AtomicInteger的API文档,因此我们改造上面的场景:
public class Demo2 implements Runnable {
//给线程方法传递一个参数
static AtomicInteger count=new AtomicInteger(0);
/**
*线程任务,将count的值遍历到10000再输出
*/
public void run() {
System.out.println("当前线程获取count的值为:"+count);
for (int i = 0; i < 10000; i++) {
count.incrementAndGet();
}
}
public static void main(String[] args) throws InterruptedException {
//创建多线程环境,这里创建了10个线程
Thread[] thread = new Thread[10];
//未创建的多线程中添加线程任务
for (int i = 0; i < 10; i++) {
thread[i] = new Thread(new Demo2());
}
//启动每个线程任务
for (int i = 0; i < 10; i++) {
thread[i].start();
}
//join方法的作用是阻塞主线程,防止还没有计算完成,就开始输出count的值了
for (int i = 0; i < 10; i++) {
thread[i].join();
}
System.out.println("count计算的结果是:"+count);
}
}
运行结果:

可以看到计算的结果是准确的,证明我们的count ++操作是线程安全的
三、原子更新数组类型
atomic包中更新数组类型的方式与更新基本类型类似,一共提供了三种方式:
AtomicIntegerArray:原子更新整型数组中的元素;
AtomicLongArray:原子更新长整型数组中的元素;
AtomicReferenceArray:原子更新引用类型数组中的元素
三个类的用法都很相似,我们以AtomicIntegerArray类来作为介绍,一共常用的有3个方法:
addAndGet(int i, int delta):以原子更新的方式将数组中索引为i的元素与输入值相加;
getAndIncrement(int i):以原子更新的方式将数组中索引为i的元素自增加1;
compareAndSet(int i, int expect, int update):将数组中索引为i的位置的元素进行更新(注意这个是非原子性操作)
我们就用这个几个方法写一个实例:
public class Demo2 implements Runnable{
//给线程方法传递一个参数
static int[] arr = new int[]{0, 0};
//将创建的数组传递给AtomicIntegerArray,进行原子性操作
static AtomicIntegerArray count=new AtomicIntegerArray(arr);
/**
*线程任务,将count第一个元素的值赋值让其等于i的值,将第二个元素的值自增
*/
public void run() {
for (int i = 0; i < 10000; i++) {
//以原子更新的方式将数组中索引为i的元素与输入值相加
count.getAndSet(0, i);
//以原子更新的方式将数组中索引为i的元素自增加1
count.getAndIncrement(1);
}
}
public static void main(String[] args) throws InterruptedException {
//创建多线程环境,这里创建了10个线程
Thread[] thread = new Thread[10];
//未创建的多线程中添加线程任务
for (int i = 0; i < 10; i++) {
thread[i] = new Thread(new Demo2());
}
//启动每个线程任务
for (int i = 0; i < 10; i++) {
thread[i].start();
}
//join方法的作用是阻塞主线程,防止还没有计算完成,就开始输出count的值了
for (int i = 0; i < 10; i++) {
thread[i].join();
}
System.out.println("计算完成后count数组第一个元素的值为:"+count.get(0));
System.out.println("计算完成后count数组第二个元素的值为:"+count.get(1));
}
}
运行的结果:

可以看到,我们在线程任务中进行的自增和赋值操作都是原子性的
四、原子更新类
一共有三种方式
AtomicReference:原子更新引用类型
AtomicReferenceFieldUpdater:原子更新引用类型里的字段
AtomicMarkableReference:原子更新带有标记位的引用类型
主要使用的是get和set方法,我们来看一个实例:
public class Demo2 implements Runnable{
//创建一个原子更新引用,引用一个Bean对象
static AtomicReference<Bean> count=new AtomicReference();
/**
*线程任务,对bean对象的字段赋值
*/
public void run() {
for (int i = 0; i < 10000; i++) {
//以原子更新的方式将数组中索引为i的元素与输入值相加
Bean bean=new Bean();
bean.setName("一共有"+i+"次执行");
bean.setNum(i);
count.set(bean);
}
}
public static void main(String[] args) throws InterruptedException {
//创建多线程环境,这里创建了10个线程
Thread[] thread = new Thread[10];
//未创建的多线程中添加线程任务
for (int i = 0; i < 10; i++) {
thread[i] = new Thread(new Demo2());
}
//启动每个线程任务
for (int i = 0; i < 10; i++) {
thread[i].start();
}
//join方法的作用是阻塞主线程,防止还没有计算完成,就开始输出count的值了
for (int i = 0; i < 10; i++) {
thread[i].join();
}
System.out.println(count.get().getName());
System.out.println("赋值的结果是"+count.get().num);
}
}
其中bean对象的代码是:
public class Bean {
String name;
int num;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
运行的结果

五、原子更新字段
AtomicReference:原子更新引用类型;
AtomicReferenceFieldUpdater:原子更新引用类型里的字段;
AtomicMarkableReference:原子更新带有标记位的引用类型;
public class Demo2 implements Runnable{
static Bean bean=new Bean();
//创建一个原子更新字段对象,更新bean中的num属性
static AtomicIntegerFieldUpdater<Bean> count=AtomicIntegerFieldUpdater.newUpdater(Bean.class,"num");
/**
*线程任务,对bean对象的字段赋值
*/
public void run() {
for (int i = 0; i < 10000; i++) {
//以原子更新的方式将数组中索引为i的元素与输入值相加
bean.setNum(i);
count.getAndIncrement(bean);
}
}
public static void main(String[] args) throws InterruptedException {
//创建多线程环境,这里创建了10个线程
Thread[] thread = new Thread[10];
//未创建的多线程中添加线程任务
for (int i = 0; i < 10; i++) {
thread[i] = new Thread(new Demo2());
}
//启动每个线程任务
for (int i = 0; i < 10; i++) {
thread[i].start();
}
//join方法的作用是阻塞主线程,防止还没有计算完成,就开始输出count的值了
for (int i = 0; i < 10; i++) {
thread[i].join();
}
System.out.println("赋值的结果是"+count.get(bean));
}
}
java并发学习--第四章 JDK提供的线程原子性操作工具类的更多相关文章
- java并发学习--第七章 JDK提供的线程工具类
一.ThreadLocal ThreadLocal类用于隔离多线程中使用的对象,为ThreadLocal类中传递的泛型就是要隔离的对象,简单的来说:如果我们在主线程创建了一个对象,并且需要给下面的多线 ...
- Java并发程序设计(四)JDK并发包之同步控制
JDK并发包之同步控制 一.重入锁 重入锁使用java.util.concurrent.locks.ReentrantLock来实现.示例代码如下: public class TryReentrant ...
- java并发学习第五章--线程中的锁
一.公平锁与非公平锁 线程所谓的公平,就是指的是线程是否按照锁的申请顺序来获取锁,如果是遵守顺序来获取,这就是个公平锁,反之为非公平锁. 非公平锁的优点在于吞吐量大,但是由于其不是遵循申请锁的顺序来获 ...
- java并发学习--第六章 线程之间的通信
一.等待通知机制wait()与notify() 在线程中除了线程同步机制外,还有一个最重要的机制就是线程之间的协调任务.比如说最常见的生产者与消费者模式,很明显如果要实现这个模式,我们需要创建两个线程 ...
- java并发学习--第三章 线程安全问题
线程的安全问题一直是我们在开发过程中重要关注的地方,出现线程安全问题的必须满足两个条件:存在着两个或者两个以上的线程:多个线程共享着共同的一个资源, 而且操作资源的代码有多句.接下来我们来根据JDK自 ...
- “全栈2019”Java多线程第二十四章:等待唤醒机制详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- 《Java程序设计》第四章-认识对象
20145221<Java程序设计>第四章-认识对象 总结 教材学习内容总结 类与对象 定义:对象是Java语言中重要的组成部分,之前学过的C语言是面向过程的,而Java主要是面向对象的. ...
- “全栈2019”Java多线程第十四章:线程与堆栈详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java多 ...
- “全栈2019”Java异常第十四章:将异常输出到文本文件中
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java异 ...
随机推荐
- css内容过长显示省略号的几种解决方法
单行文本(方法一): 语法: text-overflow : clip | ellipsis 参数: clip : 不显示省略标记(...),而是简单的裁切 (clip这个参数是不常用的!) elli ...
- java的基本数据类型有
整型数据根据它所占内容大小的不同可分为4种类型. 数据类型 内存 byte 8位 short 16位 int 32位 long 64位 浮点类型 数据类型 内存 float 32位 double 64 ...
- 学习C#20天有感
自学C#有20多天了,期间出差去深圳一周,每天平均学习4小时左右,看书+视频,之前有点C语言基础(仅限于基础哈哈),计划30内把C#的基本语法和SQL的基本语法熟悉,把面向对象相对深入的理解一些,然后 ...
- mysql group by 去重 分类 求和
w SELECT COUNT(*) FROM ( SELECT COUNT(*) FROM listing_vary_asins GROUP BY asin, countrycode ) AS w; ...
- python修改文件
文档username.txt 将文件中密码123456改成67890: 方法一:(简单粗暴) 1.打开文件 2.读出数据 3.修改数据 4.清空原来文件,将新的内容写进去 f = open('user ...
- UI自动化之特殊处理四(获取元素属性\爬取页面源码\常用断言)
获取元素属性\爬取页面源码\常用断言,最终目的都是为了验证我们实际结果是否等于预期结果 目录 1.获取元素属性 2.爬取页面源码 3.常用断言 1.获取元素属性 获取title:driver.titl ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
- redis集群主从中断,报io过高 不错
问题原因:1.由于这个集群redis操作非常频繁,1分钟操作数据达到1-2G,所有自动aof非常频繁,主从复制打包rdb也非常频繁,之前配置已经无法满足要求报异常如下6943:M 19 Jul 20: ...
- js 一道题目引发的正则的学习
正则表达式中的特殊字符 字符 含意 \ 做为转意,即通常在"\"后面的字符不按原来意义解释,如/b/匹配字符"b",当b前面加了反斜杆后/\b/,转意为匹配一个 ...
- 如何理解ajax的同步和异步?
对于如下一段代码: var dataJson = {"ABC":'testABC'}; $.ajax({ url: "/MonkeyServ ...