Group By查询
1、概述
“Group By”从字面意义上理解就是根据“By”指定的规则对数据进行分组,所谓的分组就是将一个“数据集”划分成若干个“小区域”,然后针对若干个“小区域”进行数据处理。
2、原始表
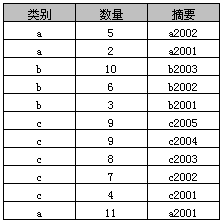
3、简单Group By
示例1
- select 类别, sum(数量) as 数量之和
- from A
- group by 类别
返回结果如下表,实际上就是分类汇总。

4、Group By 和 Order By
示例2
- select 类别, sum(数量) AS 数量之和
- from A
- group by 类别
- order by sum(数量) desc
返回结果如下表

在Access中不可以使用“order by 数量之和 desc”,但在SQL Server中则可以。
5、Group By中Select指定的字段限制
示例3
- select 类别, sum(数量) as 数量之和, 摘要
- from A
- group by 类别
- order by 类别 desc
示例3执行后会提示下错误,如下图。这就是需要注意的一点,在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。

6、Group By All
示例4
- select 类别, 摘要, sum(数量) as 数量之和
- from A
- group by all 类别, 摘要
示例4中则可以指定“摘要”字段,其原因在于“多列分组”中包含了“摘要字段”,其执行结果如下表

“多列分组”实际上就是就是按照多列(类别+摘要)合并后的值进行分组,示例4中可以看到“a, a2001, 13”为“a, a2001, 11”和“a, a2001, 2”两条记录的合并。
SQL Server中虽然支持“group by all”,但Microsoft SQL Server 的未来版本中将删除 GROUP BY ALL,避免在新的开发工作中使用 GROUP BY ALL。Access中是不支持“Group By All”的,但Access中同样支持多列分组,上述SQL Server中的SQL在Access可以写成
- select 类别, 摘要, sum(数量) AS 数量之和
- from A
- group by 类别, 摘要
7、Group By与聚合函数
在示例3中提到group by语句中select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中,常见的聚合函数如下表:
- 函数 作用 支持性
- sum(列名) 求和
- max(列名) 最大值
- min(列名) 最小值
- avg(列名) 平均值
- first(列名) 第一条记录 仅Access支持
- last(列名) 最后一条记录 仅Access支持
- count(列名) 统计记录数 注意和count(*)的区别
示例5:求各组平均值
- select 类别, avg(数量) AS 平均值 from A group by 类别;
示例6:求各组记录数目
- select 类别, count(*) AS 记录数 from A group by 类别;
示例7:求各组记录数目
8、Having与Where的区别
where 子句的作用是在对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,where条件中不能包含聚组函数,使用where条件过滤出特定的行。
having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,条件中经常包含聚组函数,使用having 条件过滤出特定的组,也可以使用多个分组标准进行分组。
示例8
- select 类别, sum(数量) as 数量之和 from A
- group by 类别
- having sum(数量) > 18
示例9:Having和Where的联合使用方法
- select 类别, SUM(数量)from A
- where 数量 gt;8
- group by 类别
- having SUM(数量) gt; 10
9、Compute 和 Compute By
- select * from A where 数量 > 8
执行结果:

示例10:Compute
- select *
- from A
- where 数量>8
- compute max(数量),min(数量),avg(数量)
执行结果如下:

compute子句能够观察“查询结果”的数据细节或统计各列数据(如例10中max、min和avg),返回结果由select列表和compute统计结果组成。
示例11:Compute By
- select *
- from A
- where 数量>8
- order by 类别
- compute max(数量),min(数量),avg(数量) by 类别
执行结果如下:

示例11与示例10相比多了“order by 类别”和“... by 类别”,示例10的执行结果实际是按照分组(a、b、c)进行了显示,每组都是由改组数据列表和改组数统计结果组成,另外:
compute子句必须与order by子句用一起使用
compute...by与group by相比,group by 只能得到各组数据的统计结果,而不能看到各组数据
在实际开发中compute与compute by的作用并不是很大,SQL Server支持compute和compute by,而Access并不支持
(转自:https://www.cnblogs.com/jerrypro/p/6691670.html)
Group By查询的更多相关文章
- C# List集合Group by查询
C# List集合Group by查询 //根据企业ID.类型.配置ID进行分组: var groupList = chRCheckConfirmList .GroupBy(x => new { ...
- C# Datatable group by 查询
操作Datatable group by 查询 //获取统计图形数据 var dicleft = new Dictionary<string, DataTable>(); ].AsEn ...
- group by 查询分组后 组的条数
比如select gid from table group by gid 查询时使用下面的方法查询条数 select count(distinct gid) from table 使用select c ...
- mongodb 对内嵌文档(数组) group分页查询,并设置查询条件
文档示例Account的其中一条记录: // collection: Account { "_id" : ObjectId("5843e38e535f3708f759b2 ...
- PostgreSql之在group by查询下拼接列字符串
首先创建group_concat聚集函数: CREATE AGGREGATE group_concat(anyelement) ( sfunc = array_append, -- 每行的操作函数,将 ...
- mysql的group by查询
下面是多种写法,针对使用group by后得到最新记录的测试及结果: 说明:我在测试的时候,因为我的表数据在增加,得到最新的数据可能不同 -- 1.得到每个分组中id最小的那条记录 select * ...
- group by查询每组时间最新的一条记录
最近需要查询每组时间最新的记录 表如下:
- 数据库内连接GROUP BY查询外键表数据行的总数
最近看了看SQL,刚好遇到这个问题. INNER JOIN [外键表] ON [主键表] 内链接,用 GROUP BY 分组外键数据,COUNT(*)计算该外键数据总行数,最后用 ORDER BY 排 ...
- mysql 通过使用联全索引优化Group by查询
/*SELECT count(*) FROM (*/ EXPLAIN SELECT st.id,st.Stu_name,tmpgt.time,tmpgt.goutong FROM jingjie_st ...
- SQL group 分组查询
1.使用group by进行分组查询 在使用group by关键字时,在select列表中可以指定的项目是有限制的,select语句中仅许以下几项: 被分组的列 为每个分组返回一个值得表达式,例如 ...
随机推荐
- stm32 development
1.www.st.com st官网 2.www.stmcu.com.cn st中文网 3.www.stmcu.org.cn st中文社区
- C与汇编混合编程
C中调用汇编,要把汇编定义为全局的,加.global C内嵌汇编 __asm__( :汇编语句部分 :输出部分 :输入部分 :破坏描述部分 ); 用C内嵌汇编的方式:实现LED的点亮 //#defin ...
- GeoJson格式与转换(shapefile)Geotools
转自:https://blog.csdn.net/cobramonkey/article/details/71124888 作为大数据分析的重要工具,Hadoop在这一领域发挥着不可或缺的作用.有些人 ...
- Go语言标准库之fmt.Print
Go语言fmt.Printf使用指南 本文整理了Go语言的标准输出流(fmt.Printf)在打印到屏幕时的格式化输出操作. 在这里按照占位符将被替换的变量类型划分,更方便查询和记忆. General ...
- maven中配置jboss仓库
有两种方式,一种是在项目的pom.xml中<repositories>中添加,这是配置是针对具体的某一个项目,更多时候,我们想把jboss仓库作为所有项目的仓库,这就需要在maven的se ...
- 如何在某些情况下禁止提交Select下拉框中的默认值或者第一个值(默认选中的就是第一个值啦……)
群里有个帅哥问了这么个问题,他的下拉框刚进页面时是隐藏起来的,但是是有值的,为啥呢?因为下拉框默认选中了第一个值呗,,, 所以提交数据的时候就尴尬啦,明明没有选,但是还是有值滴.怎么办呢? 一开始看到 ...
- linux学习:【第1篇】之安装vmware+Centos 6.9
vmware+CentOs 6.9的安装步骤 一.安装步骤 linux分区 登录用户名和密码 登录用户名和密码后安装成功 二.远程控制Xshell的安装
- Golang闭包和匿名函数
1. 匿名函数 匿名函数就是没有函数名的函数,如下所示. func test() int { max := func(a, b int) int { if a > b { return a } ...
- 解决 sublime输入一个字符后后面一个字符就会自动删除的问题
A:在你的键盘上找到 insert 按键 当出现你所说情况的时候 就按一下这个按键因为insert按键 是控制覆盖原文输入功能的 因为你打字的时候不小心 碰到 才会出现你所说的情况.
- border-box与content-box的区别
㈠box-sizing 属性 ⑴box-sizing 属性允许您以特定的方式定义匹配某个区域的特定元素. ⑵语法:box-sizing: content-box|border-box|inherit; ...