(转)Adaboost
基本原理
Adaboost算法基本原理就是将多个弱分类器(弱分类器一般选用单层决策树)进行合理的结合,使其成为一个强分类器。
Adaboost采用迭代的思想,每次迭代只训练一个弱分类器,训练好的弱分类器将参与下一次迭代的使用。也就是说,在第N次迭代中,一共就有N个弱分类器,其中N-1个是以前训练好的,其各种参数都不再改变,本次训练第N个分类器。其中弱分类器的关系是第N个弱分类器更可能分对前N-1个弱分类器没分对的数据,最终分类输出要看这N个分类器的综合效果。
弱分类器(单层决策树)
Adaboost一般使用单层决策树作为其弱分类器。单层决策树是决策树的最简化版本,只有一个决策点,也就是说,如果训练数据有多维特征,单层决策树也只能选择其中一维特征来做决策,并且还有一个关键点,决策的阈值也需要考虑。
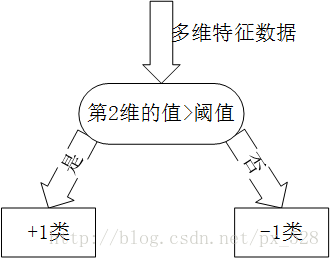
关于单层决策树的决策点,来看几个例子。比如特征只有一个维度时,可以以小于7的分为一类,标记为+1,大于(等于)7的分为另一类,标记为-1。当然也可以以13作为决策点,决策方向是大于13的分为+1类,小于(等于)13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
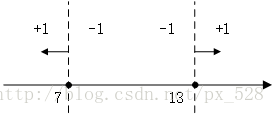
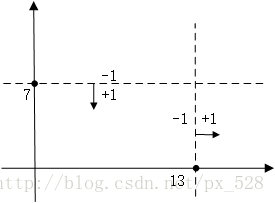
同样的道理,当特征有两个维度时,可以以纵坐标7作为决策点,决策方向是小于7分为+1类,大于(等于)7分类-1类。当然还可以以横坐标13作为决策点,决策方向是大于13的分为+1类,小于13的分为-1类。在单层决策树中,一共只有一个决策点,所以下图的两个决策点不能同时选取。
扩展到三维、四维、N维都是一样,在单层决策树中,一共只有一个决策点,所以只能在其中一个维度中选择一个合适的决策阈值作为决策点。
关于Adaboost的两种权重
Adaboost算法中有两种权重,一种是数据的权重,另一种是弱分类器的权重。其中,数据的权重主要用于弱分类器寻找其分类误差最小的决策点,找到之后用这个最小误差计算出该弱分类器的权重(发言权),分类器权重越大说明该弱分类器在最终决策时拥有更大的发言权。
Adaboost数据权重与弱分类器
刚刚已经介绍了单层决策树的原理,这里有一个问题,如果训练数据保持不变,那么单层决策树找到的最佳决策点每一次必然都是一样的,为什么呢?因为单层决策树是把所有可能的决策点都找了一遍然后选择了最好的,如果训练数据不变,那么每次找到的最好的点当然都是同一个点了。
所以,这里Adaboost数据权重就派上用场了,所谓“数据的权重主要用于弱分类器寻找其分类误差最小的点”,其实,在单层决策树计算误差时,Adaboost要求其乘上权重,即计算带权重的误差。
举个例子,在以前没有权重时(其实是平局权重时),一共10个点时,对应每个点的权重都是0.1,分错1个,错误率就加0.1;分错3个,错误率就是0.3。现在,每个点的权重不一样了,还是10个点,权重依次是[0.01,0.01,0.01,0.01,0.01,0.01, 0.01,0.01,0.01,0.91],如果分错了第1一个点,那么错误率是0.01,如果分错了第3个点,那么错误率是0.01,要是分错了最后一个点,那么错误率就是0.91。这样,在选择决策点的时候自然是要尽量把权重大的点(本例中是最后一个点)分对才能降低误差率。由此可见,权重分布影响着单层决策树决策点的选择,权重大的点得到更多的关注,权重小的点得到更少的关注。
在Adaboost算法中,每训练完一个弱分类器都就会调整权重,上一轮训练中被误分类的点的权重会增加,在本轮训练中,由于权重影响,本轮的弱分类器将更有可能把上一轮的误分类点分对,如果还是没有分对,那么分错的点的权重将继续增加,下一个弱分类器将更加关注这个点,尽量将其分对。
这样,达到“你分不对的我来分”,下一个分类器主要关注上一个分类器没分对的点,每个分类器都各有侧重。
Adaboost分类器的权重
由于Adaboost中若干个分类器的关系是第N个分类器更可能分对第N-1个分类器没分对的数据,而不能保证以前分对的数据也能同时分对。所以在Adaboost中,每个弱分类器都有各自最关注的点,每个弱分类器都只关注整个数据集的中一部分数据,所以它们必然是共同组合在一起才能发挥出作用。所以最终投票表决时,需要根据弱分类器的权重来进行加权投票,权重大小是根据弱分类器的分类错误率计算得出的,总的规律就是弱分类器错误率越低,其权重就越高。
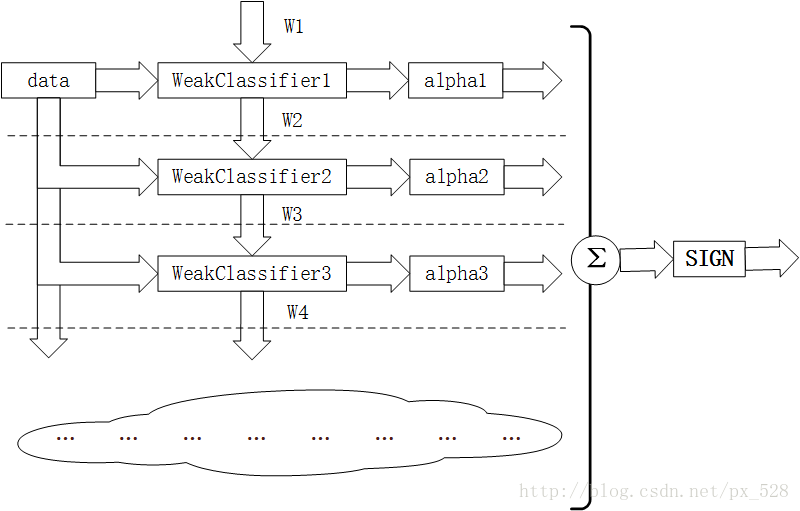
图解Adaboost分类器结构
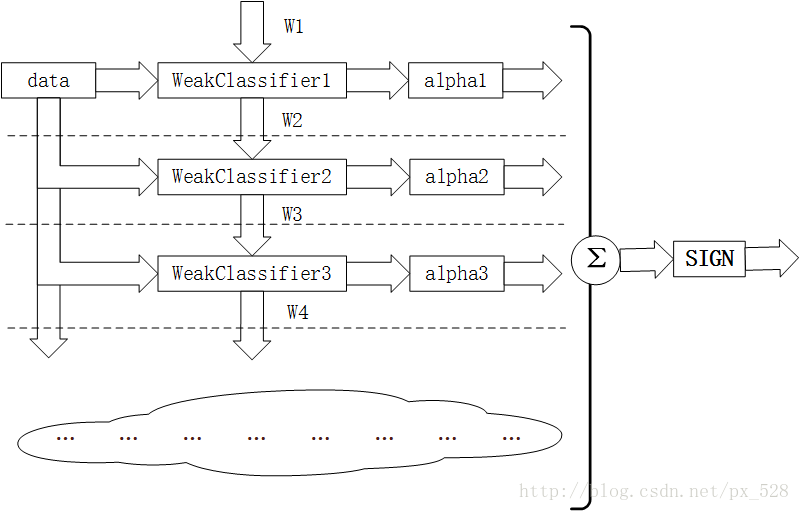
如图所示为Adaboost分类器的整体结构。从右到左,可见最终的求和与符号函数,再看到左边求和之前,图中的虚线表示不同轮次的迭代效果,第1次迭代时,只有第1行的结构,第2次迭代时,包括第1行与第2行的结构,每次迭代增加一行结构,图下方的“云”表示不断迭代结构的省略。
第i轮迭代要做这么几件事:
1. 新增弱分类器WeakClassifier(i)与弱分类器权重alpha(i)
2. 通过数据集data与数据权重W(i)训练弱分类器WeakClassifier(i),并得出其分类错误率,以此计算出其弱分类器权重alpha(i)
3. 通过加权投票表决的方法,让所有弱分类器进行加权投票表决的方法得到最终预测输出,计算最终分类错误率,如果最终错误率低于设定阈值(比如5%),那么迭代结束;如果最终错误率高于设定阈值,那么更新数据权重得到W(i+1)
图解Adaboost加权表决结果
关于最终的加权投票表决,举几个例子:
比如在一维特征时,经过3次迭代,并且知道每次迭代后的弱分类器的决策点与发言权,看看如何实现加权投票表决的。
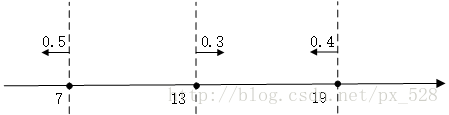
如图所示,3次迭代后得到了3个决策点,
最左边的决策点是小于(等于)7的分为+1类,大于7的分为-1类,且分类器的权重为0.5;
中间的决策点是大于(等于)13的分为+1类,小于13分为-1类,权重0.3;
最右边的决策点是小于(等于19)的分为+1类,大于19分为-1类,权重0.4。
对于最左边的弱分类器,它的投票表示,小于(等于)7的区域得0.5,大与7得-0.5,同理对于中间的分类器,它的投票表示大于(等于)13的为0.3,小于13分为-0.3,最右边的投票结果为小于(等于19)的为0.4,大于19分为-0.4,如下图:
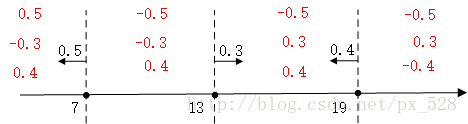
求和可得:
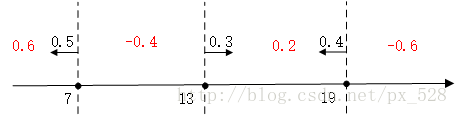
最后进行符号函数转化即可得到最终分类结果:
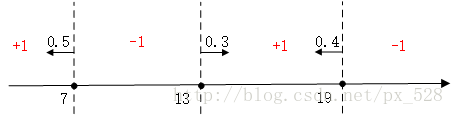
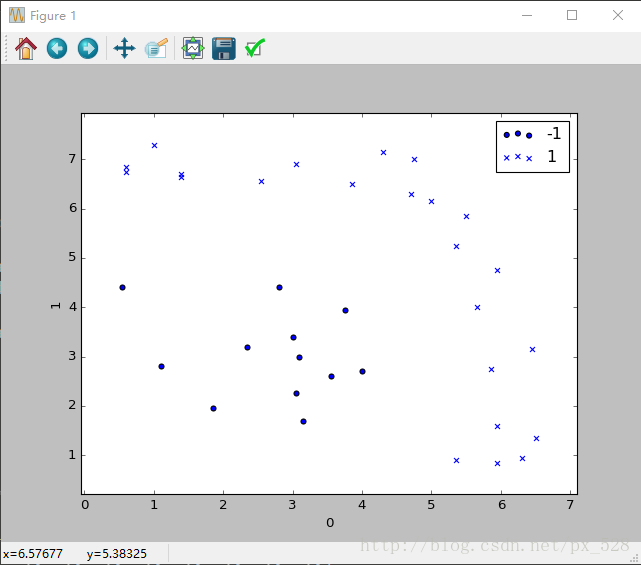
更加直观的,来看一个更复杂的例子。对于二维也是一样,刚好有一个实例可以分析一下,原始数据分布如下图:
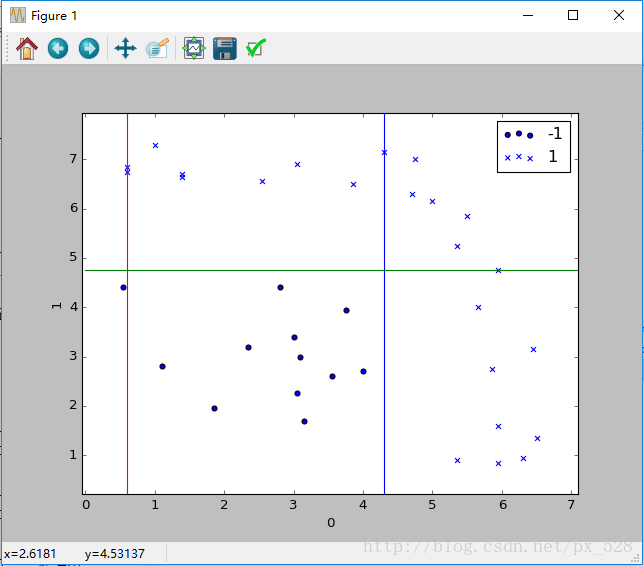
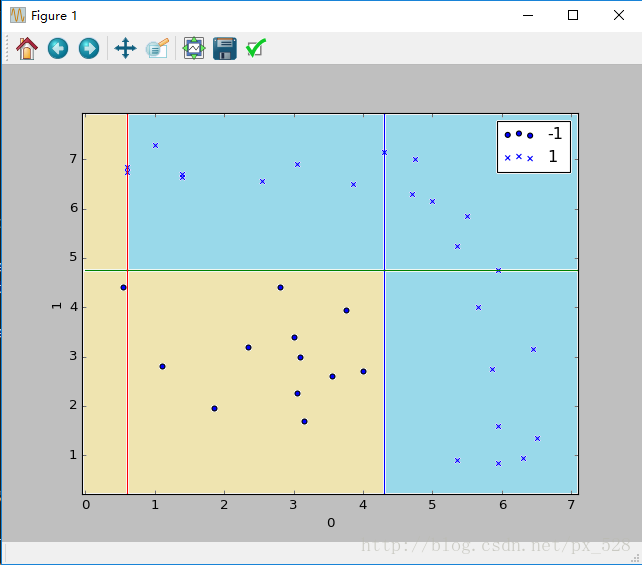
Adaboost分类器试图把两类数据分开,运行一下程序,显示出决策点,如下图:
这样一看,似乎是分开了,不过具体参数是怎样呢?查看程序的输出,可以得到如其决策点与弱分类器权重,在图中标记出来如下:
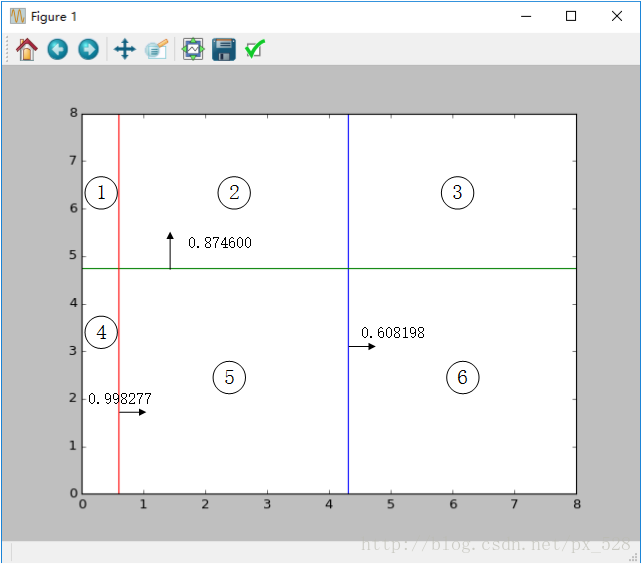
图中被分成了6分区域,每个区域对应的类别就是:
1号:sign(-0.998277+0.874600-0.608198)=-1
2号:sign(+0.998277+0.874600-0.608198)=+1
3号:sign(+0.998277+0.874600+0.608198)=+1
4号:sign(-0.998277-0.874600-0.608198)=-1
5号:sign(+0.998277-0.874600-0.608198)=-1
6号:sign(+0.998277-0.874600+0.608198)=+1
其中sign(x)是符号函数,正数返回1负数返回-1。
最终得到如下效果:
(转)Adaboost的更多相关文章
- boosting、adaboost
1.boosting Boosting方法是一种用来提高弱分类算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数.他是一种框架算法,主要是通过对样本集的操作获 ...
- Adaboost提升算法从原理到实践
1.基本思想: 综合某些专家的判断,往往要比一个专家单独的判断要好.在"强可学习"和"弱科学习"的概念上来说就是我们通过对多个弱可学习的算法进行"组合 ...
- scikit-learn Adaboost类库使用小结
在集成学习之Adaboost算法原理小结中,我们对Adaboost的算法原理做了一个总结.这里我们就从实用的角度对scikit-learn中Adaboost类库的使用做一个小结,重点对调参的注意事项做 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 【十大经典数据挖掘算法】AdaBoost
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 集成学习 集成学习(ensem ...
- 机器学习——AdaBoost元算法
当做重要决定时,我们可能会考虑吸取多个专家而不只是一个人的意见.机器学习处理问题也是这样,这就是元算法(meta-algorithm)背后的思路. 元算法是对其他算法进行组合的一种方式,其中最流行的一 ...
- Adaboost\GBDT\GBRT\组合算法
Adaboost\GBDT\GBRT\组合算法(龙心尘老师上课笔记) 一.Bagging (并行bootstrap)& Boosting(串行) 随机森林实际上是bagging的思路,而GBD ...
- AdaBoost算法分析与实现
AdaBoost(自适应boosting,adaptive boosting)算法 算法优缺点: 优点:泛化错误率低,易编码,可用在绝大部分分类器上,无参数调整 缺点:对离群点敏感 适用数据类型:数值 ...
- 7. ensemble learning & AdaBoost
1. ensemble learning 集成学习 集成学习是通过构建并结合多个学习器来完成学习任务,如下图: 集成学习通过将多个学习学习器进行结合,常可以获得比单一学习器更优秀的泛化性能 从理论上来 ...
- 机器学习实战4:Adaboost提升:病马实例+非均衡分类问题
Adaboost提升算法是机器学习中很好用的两个算法之一,另一个是SVM支持向量机:机器学习面试中也会经常提问到Adaboost的一些原理:另外本文还介绍了一下非平衡分类问题的解决方案,这个问题在面试 ...
随机推荐
- vue (UI)
- 调用js方法返回值为undefined
问题描述: 我写的js方法: function getname(code){ var name $.post("",{ code:code },function(resurlt){ ...
- python基础篇(文件操作)
Python基础篇(文件操作) 一.初始文件操作 使用python来读写文件是非常简单的操作. 我们使用open()函数来打开一个文件, 获取到文件句柄. 然后通过文件句柄就可以进行各种各样的操作了. ...
- netbean out of memory java heap space
When run test file in netbean. all dependency and resource are right, but it raise up java.lang.OutO ...
- win10下RabbitMQ的安装和配置
在win10环境下安装RabbitMQ的步骤 第一步:下载并安装erlang 原因:RabbitMQ服务端代码是使用并发式语言Erlang编写的,安装Rabbit MQ的前提是安装Erlang. 下载 ...
- CentOS7.6系统安装详解(含真机装系统的采坑之旅)!
刚开始学习linux操作系统是总是很茫然,无所适从,以下是自己总结的工作经验,仅供参考! 一.准备资源 安装前需要准备的资源有linux系统centos7.6发行版系统镜像,vmware workst ...
- 一、Redis的安装
1.下载.解压.编译.安装 # 下载地址 wget http://download.redis.io/redis-stable.tar.gz # 解压 tar xzf redis-stable.tar ...
- 【Database】MySQL实战45讲
01 | 基础架构:一条SQL查询语句是如何执行的? 1. MySQL 的基本架构图: MySQL可以分成: Server层 和 存储引擎层 两部分. Server层:包含连接器.查询缓存.分析器.优 ...
- ECUST_Algorithm_2019_2
简要题意及解析 1001 \(N\)个数分为\(K+8\)组,每组三个,记为\((a,b,c)\),方便起见要求\(a \leq b \leq c\),每组的代价是\((a-b)^2\),总代价为每组 ...
- laravel5.6 基于redis,使用消息队列(邮件推送)
邮件发送如何配置参考:https://www.cnblogs.com/clubs/p/10640682.html 用到的用户表: CREATE TABLE `recruit_users` ( `id` ...