Hibernate4教程六:性能提升和二级缓存
- User user = (User) session.createCriteria(User.class)
- .setFetchMode("permissions", FetchMode.JOIN)
- .add( Restrictions.idEq(userId) )
- .uniqueResult();
- 当宿主被加载时,关联、集合或属性被立即抓取。
-对集合类中的每个元素而言,都是直到需要时才去访问数据库。除非绝对必要,Hibernate不会试图去把整个集合都抓取到内存里来(适用于非常大的集合)。
- 对返回单值的关联而言,当其某个方法被调用,而非对其关键字进行get操作时才抓取。
- 对返回单值的关联而言,当实例变量被访问的时候进行抓取。与上面的代理抓取相比,这种方法没有那么“延迟”得厉害(就算只访问标识符,也会导致关联抓取)但是更加透明,因为对应用程序来说,不再看到proxy。这种方法需要在编译期间进行字节码增强操作,因此很少需要用到。
- 对属性或返回单值的关联而言,当其实例变量被访问的时候进行抓取。需要编译期字节码强化,因此这一方法很少用到。
- public class HibernateSessionRequestFilter implements Filter {
- private SessionFactory sf;
- public void doFilter(...)throws...{
- sf.getCurrentSession().beginTransaction();
- chain.doFilter(request, response);
- sf.getCurrentSession().getTransaction().commit();
- }
- public void init(FilterConfig filterConfig) throws ServletException {
- sf = new Configuration().configure().buildSessionFactory();
- }
- public void destroy() {}
- }
- Parent p = (Parent) sess.load(Parent.class, id);
- Child c = new Child();
- c.setParent(p);
- p.getChildren().add(c); //不用抓取集合
- sess.flush();
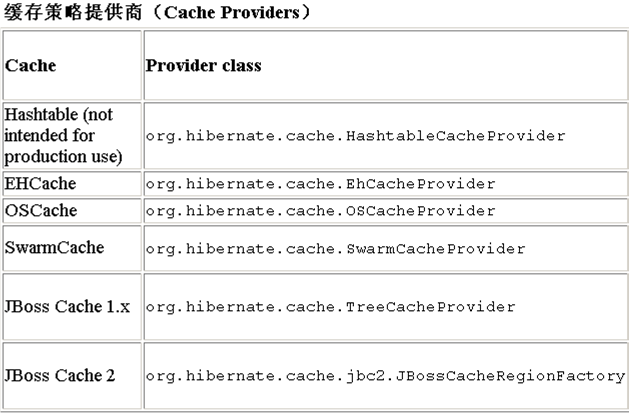
- <property name="cache.region.factory_class">org.hibernate.cache.EhCacheRegionFactory</property>
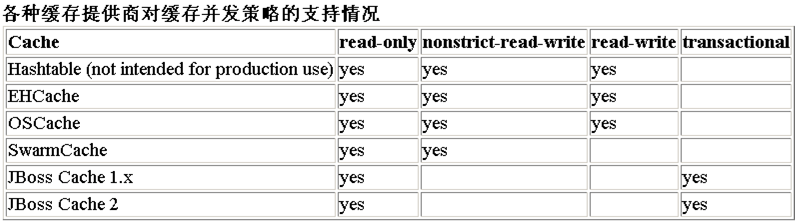
- <cache
- usage="transactional|read-write|nonstrict-read-write|read-only" (1)
- region="RegionName" (2)
- include="all|non-lazy" (3) />
- <class name="eg.Immutable" mutable="false">
- <cache usage="read-only"/>
- ....
- </class>
- <class name="eg.Cat" .... >
- <cache usage="read-write"/>
- <set name="kittens" ... >
- <cache usage="read-write"/>
- ....
- </set>
- </class>
ScrollableResult cats = sess.createQuery(“from Cat as cat”).scroll(); //很大的结果集,可滚动的结果集
while ( cats.next() ) {
Cat cat = (Cat) cats.get(0);
doSomethingWithACat(cat);
sess.evict(cat);
}- sessionFactory.evict(Cat.class, catId); //evict a particular Cat
- sessionFactory.evict(Cat.class); //evict all Cats
- sessionFactory.evictCollection(“Cat.kittens”, catId); //evict a particular collection of kittens
- sessionFactory.evictCollection(“Cat.kittens”); //evict all kitten
- <?xml version="1.0" encoding="UTF-8"?>
- <ehcache>
- <diskStore path="java.io.tmpdir"/>
- <defaultCache
- maxElementsInMemory="10000"
- eternal="false"
- timeToIdleSeconds="120"
- timeToLiveSeconds="120"
- overflowToDisk="true"
- />
- </ehcache>
- <property name="hibernate.cache.use_second_level_cache">true</property>
- <property name="cache.provider_class">org.hibernate.cache.EhCacheProvider</property>
- <property name="cache.use_query_cache">false</property>
- <property name="cache.use_query_cache">false</property>
- <property name="cache.use_second_level_cache">true</property>
- <property name="cache.region.factory_class">org.hibernate.cache.EhCacheRegionFactory</property>
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um1 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um1=="+um1);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um2 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um2=="+um2);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- UserModel um3 = (UserModel)s.load(UserModel.class, "1");
- System.out.println("um3=="+um3);
- t.commit();
true);
- s = sf.openSession();
- t = s.beginTransaction();
- Query query1 =s.createQuery("select Object(o) from UserModel o");
- query1.setCacheable(true);
- List list1 = query1.list();
- System.out.println("list1=="+list1);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- Query query2 =s.createQuery("select Object(o) from UserModel o");
- query2.setCacheable(true);
- List list2 = query2.list();
- System.out.println("list2=="+list2);
- t.commit();
- s = sf.openSession();
- t = s.beginTransaction();
- Query query3 =s.createQuery("select Object(o) from UserModel o");
- query3.setCacheable(true);
- List list3 = query3.list();
- System.out.println("list3=="+list3);
- t.commit();
Hibernate4教程六:性能提升和二级缓存的更多相关文章
- Atitit.h5 web webview性能提升解决方案-----fileStrore缓存离线存储+http方案
Atitit.h5 web webview性能提升解决方案-----fileStrore缓存离线存储+http方案 1. 业务场景 android+webview h5 css背景图性能提升1 2. ...
- Hibernate(十六):Hibernate二级缓存
Hibernate缓存 缓存(Cache):计算机领域非常通用的概念.它介于应用程序和永久性数据存储源(如磁盘上的文件或者数据库)之间,起作用是降低应用程序直接读取永久性数据存储源的频率,从而提高应用 ...
- Hibernate 性能优化之二级缓存
二级缓存是一个共享缓存,在二级缓存中存放的数据是共享数据特性 修改不能特别频繁 数据可以公开二级缓存在sessionFactory中,因为sessionFactory本身是线程安全,所 ...
- Hibernate4教程六(2):基本实现原理
整体流程 1:通过configuration来读cfg.xml文件 2:得到SessionFactory 工厂 3:通过SessionFactory 工厂来创建Session实例 4:通过Sessio ...
- paip.cache 缓存架构以及性能提升总结
paip.cache 缓存架构以及性能提升总结 1 缓存架构以及性能(贯穿读出式(LookThrough) 旁路读出式(LookAside) 写穿式(WriteThrough) 回写式 ...
- SQL Server 2014里的性能提升
在这篇文章里我想小结下SQL Server 2014引入各种惊艳性能提升!! 缓存池扩展(Buffer Pool Extensions) 缓存池扩展的想法非常简单:把页文件存储在非常快的存储上,例如S ...
- 【.NET Core项目实战-统一认证平台】第十五章 网关篇-使用二级缓存提升性能
[.NET Core项目实战-统一认证平台]开篇及目录索引 一.背景 首先说声抱歉,可能是因为假期综合症(其实就是因为懒哈)的原因,已经很长时间没更新博客了,现在也调整的差不多了,准备还是以每周1-2 ...
- ssh整合hibernate 使用spring管理hibernate二级缓存,配置hibernate4.0以上二级缓存
ssh整合hibernate 使用spring管理hibernate二级缓存,配置hibernate4.0以上二级缓存 hibernate : Hibernate是一个持久层框架,经常访问物理数据库 ...
- CRL快速开发框架系列教程六(分布式缓存解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
随机推荐
- Linux学习笔记之VIM编辑器
此处根据需要,只罗列一些常用的指令和用法 五.VIM程序编辑器 Vi与vim Vi打开文件没有高亮注释,vim有,且vim是vi的高级版本 Vim默认打开文件为命令模式 i ...
- Spring-DI控制反转和IOC依赖注入
Spring-DI控制反转和IOC依赖注入 DI控制反转实例 IDEAJ自动导入Spring框架 创建UserDao.java接口 public interface UserDao { public ...
- sql for loop
--step1 disable constraint begin for i in (select uc.constraint_name, uc.table_name from user_constr ...
- zookeeper与kafka安装搭建
1.2181:对cline端提供服务 2.3888:选举leader使用 3.2888:集群内机器通讯使用(Leader监听此端口)
- java23种设计模式(五)--组合模式
转载:https://www.cnblogs.com/V1haoge/p/6489827.html定义:所谓组合模式,其实说的是对象包含对象的问题,通过组合的方式(在对象内部引用对象)来进行布局,我认 ...
- windows H2database 安装
转载百度经验 H2是一个开源的.纯java实现的关系数据库,小巧并且使用方便,十分适合作为嵌入式数据库使用 首先打开浏览器进入H2官网http://www.h2database.com/html/ma ...
- JSOI2018冬令营游记&总结(迁移自洛谷博客)
游记 一开始在冬令营还没开始的时候,十分期待,殊不知每天都有一场浩劫在等着我. Day0 10:50出发,看见lbn同学发了一条说说,也随便发了一个. 然后在车上一直在睡觉,现在感觉挺后悔的,其实可以 ...
- 5G如何让智能手机再次变得丑陋?
第一批5G移动终端将于明年到货,这意味着智能手机制造商现在正在研究细节.与过去十年智能手机所看到的很多其他组件改进不同,像更好的相机,更快的处理器和更亮的屏幕,5G无线电将需要一些设计上的妥协,而且看 ...
- BZOJ2002 [HNOI2010] 弹飞绵羊
LCT access完了一定splay再用!!! 悲伤= = LCT裸题 把调出去设虚点n+1即可 //Love and Freedom. #include<cstdio> #includ ...
- tmux使用——2019年11月20日16:40:15
1.tmux 命令行的典型使用方式是,打开一个终端窗口(terminal window,以下简称"窗口"),在里面输入命令.用户与计算机的这种临时的交互,称为一次"会话& ...