计算机系统结构总结_Memory Review
这次就边学边总结吧,不等到最后啦
Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
Ch3. Memory Hierarchy
1. Physical Memory
SRAM:CPU缓存(比如PentiumII的外置二级缓存芯片)
DRAM:内存芯片,需要Dynamic刷新。关于DRAM的详细介绍在这里。
2. Locality(PPT P12/HI P253)
Programs tend to reuse data and instructions near those they have used recently, or that were recently referenced themselves.
- Temporal locality: Recently referenced items are likely to be referenced in the near future.
- Spatial locality: Items with nearby addresses tend to be referenced close together in time.
利用局部性原理,可以将存储器组织成存储器层次结构。相邻两层之间数据交换的单位叫做块(block)
3. Cache(PPT P15 / HI P254)
以块为单位从level k+1 cache到 level k
- Cache hit: level k中有目标块
- Cache miss: 块在level k中没有,要从level k+1中读进来
- Placement policy: where can the new block be placed in level k? E.g., b mod 4
- Replacement policy: which block should be evicted from level k? E.g., LRU
4. Question about caching
1,2: Where can a block be placed in the upper level? • How is a block found if it is in the upper level? (PPT P17 / HI P259)
地址映像方式:内存中block地址与cache中block地址的对应方式(内存和cache中一个块的大小都相等)。缓存中这个block又叫做cacheline。
cache分成多个组,每个组分成多个行,cacheline是cache的基本单位,从主存向cache迁移数据按照cacheline为单位替换。(也叫做cache block)
- 全相连:主存中的一块可以映象到Cache中的任意一块。在cache中维护一个目录表,记录主存块号对应的cache块号
- 直接相联:主存储器中一块只能映象到Cache的一个特定的块中。(HI P260-P264)
- N路组相连(HI P272-P275,HI P309):缓存分为M个组,每组N个块(N*M=总block数)。主存地址按一定对应方法(比如取部分位作为block_idx)映射到缓存的某个组内,然后可以被放在该组内N个块中的任意一个位置上。如下图就是一个2路组相连的Cache:

可以看到,如果路数太少了,那么每一组的容量就会变少。当多个地址映射到这一组时,就会导致这一组装不下,然后有些块就要被淘汰出缓存,导致性能降低。下面会提到这种cache miss叫做conflict miss。(所以Celeron III的L2缓存路数比Pentium III要少......)
关于组相连的cache后面还会有一个更详细的例子。
Ref:
https://blog.csdn.net/onlyoncelove/article/details/80426874
https://zhuanlan.zhihu.com/p/60843893
https://zhuanlan.zhihu.com/p/37749443
3: Which block should be replaced on a miss? (PPT P22,HI P312)
3种cache miss:
- Compulsory—The first access to a block is not in the cache, so the block must be brought into the cache. Also called cold start misses or first reference misses.
- Capacity—If the cache cannot contain all the blocks needed during execution of a program, capacity misses will occur due to blocks being discarded and later retrieved.
- Conflict—If block-placement strategy is set associative or direct mapped, conflict misses (in addition to compulsory & capacity misses) will occur because a block can be discarded and later retrieved if too many blocks map to its set. Also called collision misses or interference misses.
Least recently used — LRU
Not most recently used — NMRU
这里举个栗子来说明cache miss。
假设有64B的内存,每个内存块是1Byte。然后有16B的2-way associate的cache,每个cache block是2B,那么这个cache就可以分成16B/2way/2B=4个set。如下图:
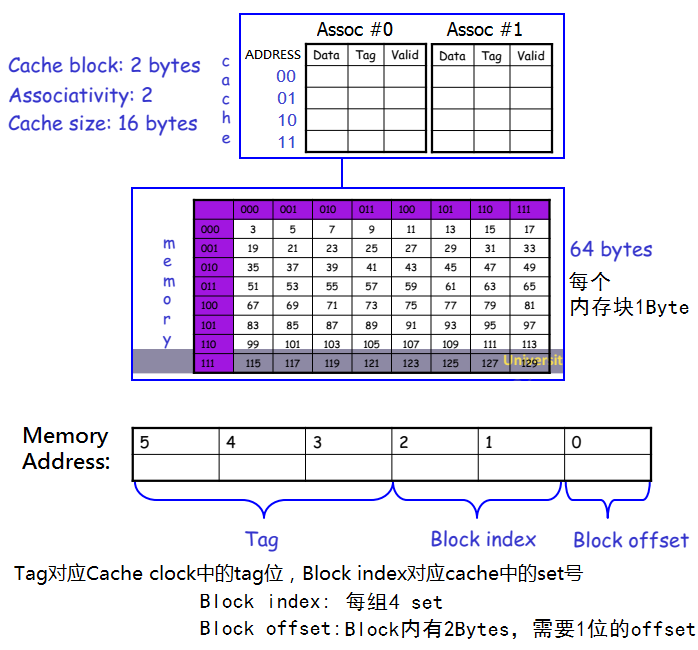
注意:
- Block offset表示块内偏移。一般来说每个内存地址都是存放1Byte,但cache block可能有好几个Bytes,所以要搞个offset。
- Block index用于定位set号。
- 内存地址位数-Block offset-Block Index=Tag位数。Tag位的内容是要存放在cache里的,要占用一部分额外的空间(因为cache的地址位相当于只有Block index和Block offset,显然是比内存地址要少的,需要搞个tag来再比较一次才行)。
假设我们要搞个while循环遍历数组(比如 for i:=1 to 100 writeln(a[i]) )要访问以下内存地址,那么cache会怎么变化呢?
miss 因为一个block size=2B,所以会把010000, 010001两个地址里的数据都读进来
block_idx=,因此对应set=。里面任选一个Assoc存放内容(假设Assoc #)
此时{Assoc=, set=}区域内容为{Data: , Tag: }
Hit 此时该区域已经在cache里了。可以在前面那个block中找到(spatial locality)
miss block_idx=, 进入set=,发现啥也没有。因此将010010,010011读入。
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
miss block_idx=, set10里啥也没有,读入010100,。
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
miss 同上
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit miss block_idx=, 查询set=00区域里每个块的tag,发现没有当前这个地址(tag=),读入
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
miss 同上
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
miss
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
miss
此时{Assoc=, set=}区域的内容为{Data: , Tag=}
Hit
经过这波for之后,cache就被写满啦:
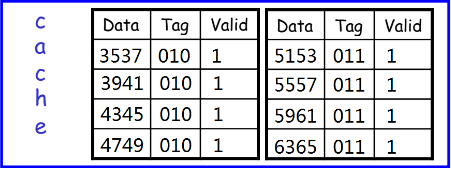
但此时我们的for还在继续,还要读下面的内存地址,那么cache会怎么跟着变化呢?
miss block_idx=, 发现set=00都满了,踢出去Assoc0这个块(假设是LRU),然后写入新的
此时{Assoc=, set=}区域内容为{Data: , Tag: }
注意:假设我们现在不for了,用一个while(1)然后还是循环遍历刚才这些地址,就会发现:
:被100000踢掉了,重新读进来,踢掉原来的{Assoc=, set=}
:被100000踢掉了,重新读进来,踢掉原来的{Assoc=, set=}
010010:Hit
010011:Hit
010100:Hit
010101:Hit
010110:Hit
010111:Hit
011000:被010000踢掉了,重新读进来,踢掉原来的{Assoc=1, set=00}
011001:被010000踢掉了,重新读进来,踢掉原来的{Assoc=1, set=00}
011010:Hit
011011:Hit
011100:Hit
011101:Hit
011110:Hit
011111:Hit
100000:踢掉原来的{Assoc=0, set=00}
......
也就是说set=00的两个块始终是miss,但其它块始终是Hit。有趣吧(并不
——————————————————————————————————————————————————————————————————
好的再来换个栗子:这次我们不按顺序访问地址了,而是有跳跃的:
for(int i=;i<=;i++){
printf("%d\n", A[i]);
printf("%d\n", B[i]);
printf("%d\n", C[i]);
}
然后再来人肉simulate一下:
miss {Assoc=, set=}:={Data: , Tag: }
miss {Assoc=, set=}:={Data: , Tag: }
miss {Assoc=, set=}:={Data: , Tag: }
miss {Assoc=, set=}:={Data: , Tag: }
注意:读入时要以cache block为单位,起始地址要mask掉后三位的block_idx和block_offset。在本例中也就是从010000起始的2Byte。也就是3537,而不是3739
miss
miss
这时miss率也还挺高的...因为associativity只有2,set=00里只有两个块,太小啦。这种叫做conflict miss
有人说for循环的速度可能和cache有关系,其实就是这个原因。后面我们还会见到这种例子。
4: What happens on a write(PPT P29-35 / HI P266)
假设我们从内存中读了一个block到cache,然后对它进行了修改,那么怎么把它同步回内存中的旧数据呢?有两种策略:
- write-through:改写cache内容的同时,改写内存中的对应内容。
- 但是写内存是很慢的....因此有一个优化策略是write buffer:先不改写内存,而是把修改信息放到write buffer。等write buffer满了再把buffer中的内容写回内存
- 这种write buffer的策略不仅在cpu和内存之间,任意两级存储系统之间都可以有(比如读写U盘时,直接拔掉u盘可能write buffer的东西没来得及写回去,导致数据丢失)
- 这是基于一个思想:刚被改写过的东西接着就要读的概率不大,所以write的优先级比read低一些,write latency高一点点不要紧
- write-back:一开始只改写cache内容(并记录一个dirty_bit:=1)。当这个块要被从cache中淘汰时才写回内存。可以减少访存次数
当一个写操作遇到cache miss时,遇到的情况会比读操作复杂一些。那么此时改写这个block又有两种策略:
- write-allocate:先在cache中分配一块,将数据从内存读到cache的这一块中,然后改写
- no-write-allocate:只改写内存中的对应块,不写入cache
- 这种机制产生的原因是,有时程序会写整个块,就像有时操作系统会将存储器中的一页全部填零一样。在这种情况下,由初始的写缺失引起的取数据就不必要了。一些计算机允许基于每一页来更改写分配策略
这几种策略的组合可以搞成一张表,详细介绍每种策略下memory和cache的动作:

Write Policy Write Alloc Hit/Miss Write Buffer writes to
Back Yes Both Cache 因为有write back,只改写cache就行了
Back No Hit Cache 因为有write back,而且cache hit,不用碰内存,只改写cache就行了
Back No Miss Memory miss了,一定要去内存。然后又因为no write alloc,所以直接改写mem就行,不动cache
Through Yes Both Both write alloc,就一定要改写cache。然后write through又要求得改写内存
Through No Hit Both cache hit了,那么cache里的是必须得改的。然后write through又要求得改写内存
Through No Miss Memory miss了说明cache里没有,但no write alloc,那直接写内存就行了
5. 计算(PPT P36-P40)
AMAT = Average Memory Access Time
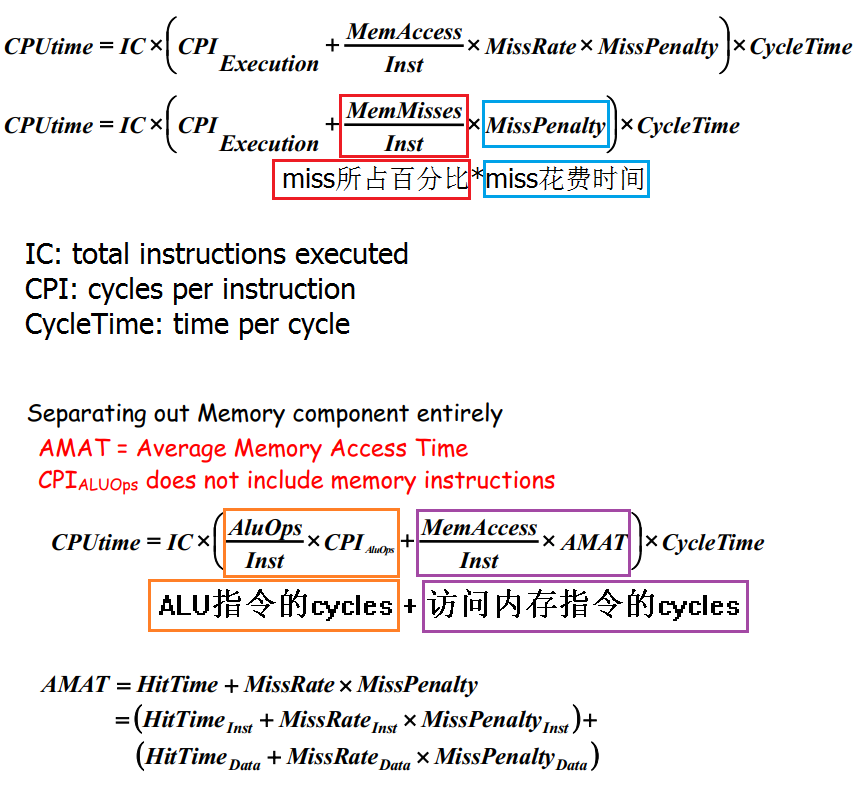

6. Virtual Memory (PPT P41-P61,HI chapter5.7)
虚拟存储器:实现虚拟地址和物理地址之间的转换。
这一段我们补充到之前OS笔记的 5. 内存管理 这一节
7. Others
有几个奇怪的概念,我们来拉出来比较一下:
一个物理内存地址的容量
一般是1 Byte。可以参考下面这张图:
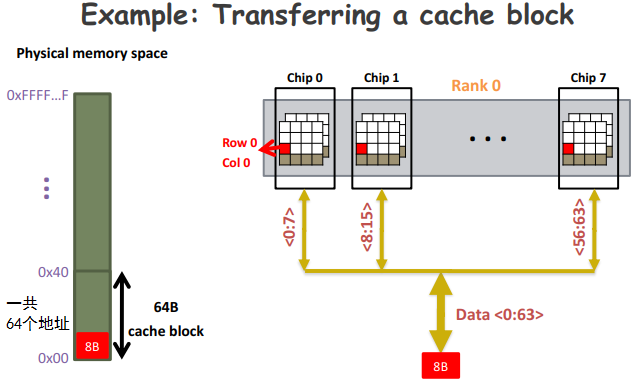
如图,每个内存地址存放1Byte,所以0x00到0x40这64个地址一起存放64 Bytes。所以说32bit内存最多能寻址2^32 Bytes = 4GB的内存。
然后因为我们这里的内存位宽是64bit,所以内存一次读出来8 Bytes。具体过程可以参考这一节。
cacheline 和 cache block size
一般来说这俩是一个意思...就是每个cache block的大小。
因为一个cache block可能有好几个字节,但每个物理内存地址都是只有1 Byte的,所以有了前面讲的块内偏移(Block offset)
Word
在本科计组课上我们学过字的概念:字长就是代表CPU单个指令的最大处理长度。(小于字长的指令肯定没毛病。大于字长的指令有可能也可以处理,但要花费更多的cycles)
字长进而也决定了虚拟地址内存空间的大小。因为一个内存地址也必须要能被一条指令装得下嘛。
从Pentium到PentiumIII其实都已经使用了64 bit的数据总线(Wikipedia:64-bit external databus doubles the amount of information possible to read or write on each memory access and therefore allows the Pentium to load its code cache faster than the 80486; it also allows faster access and storage of 64-bit and 80-bit x87 FPU data.),这样一次memory access可以读取更多的数据。但因为CPU内部的寄存器仍然是32bit,那么地址寄存器也只有32bit了,所以只能寻址32 bit的内存。一般还是叫它32位处理器。
而到了Pentium Pro处理器中加入了PAE的黑科技,扩大了地址总线的位数,配合Windows2000 Advanced Server就可以寻址更大的内存了。
(数据总线和地址总线的区别:数据总线用于把数据从内存传到CPU,地址总线用来传输地址)
后期的Pentium 4开始真正支持64bit,但实际上也没有用满64位的内存地址......
计算机系统结构总结_Memory Review的更多相关文章
- 计算机系统结构总结_Memory Hierarchy and Memory Performance
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR 这是youtube上一个非常好的memory syst ...
- 【5分钟+】计算机系统结构:CPU性能公式
计算机系统结构:CPU性能公式 基础知识 CPU 时间:一个程序在 CPU 上运行的时间.(不包括I/O时间) 主频.时钟频率:CPU 内部主时钟的频率,表示1秒可以完成多少个周期. 例如,主频为 4 ...
- 计算机系统结构总结_Multiprocessor & cache coherence
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 最后一节来看看如何实现parallelism 在多处 ...
- 计算机系统结构总结_Branch prediction
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR Branch Prediction 对于下面的指令: ...
- 计算机系统结构总结_Scoreboard and Tomasulo
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 超标量 前面讲过超标量的概念.超标量的目的就是实现指 ...
- 计算机系统结构总结_Instruction Set Architecture
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 这节我们来看CPU内部的一些东西. Instruct ...
- 计算机系统结构总结_Cache Optimization
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR Ch4. Cache Optimization 本章要 ...
- 计算机体系结构——CH1基本概念
CH1基本概念 右键点击查看图像,查看清晰图像 CH1基本概念 目的与内容 了解计算机系统的完整概念 学习计算机系统的分析方法与设计方法 编写程序所必需了解的计算机属性 计算机系统结构简介 为什么要研 ...
- 团队项目之Scrum2
小组:BLACK PANDA 时间:2019.11.17 每天举行站立式会议 提供当天站立式会议照片一张 2 昨天已完成的工作 2 确定用户登录与注册和编辑页面的接口 前端方面:详细确定页面的功能,并 ...
随机推荐
- druid配置以及监控
1.druid监控的功能: . 数据源 . SQL监控 对执行的MySQL语句进行记录,并记录执行时间.事务次数等 . SQL防火墙 对SQL进行预编译,并统计该条SQL的数据指标 . Web应用 对 ...
- Java多线程的创建方法
Java 线程类也是一个 object 类,它的实例都继承自java.lang.Thread 或其子类. 可以用如下方式用 java 中创建一个线程,执行该线程可以调用该线程的 start()方法: ...
- Shell test命令/流程控制
Shell test命令 Shell中的 test 命令用于检查某个条件是否成立,它可以进行数值.字符和文件三个方面的测试. 数值测试 参数,说明 -eq等于则为真 -ne不等于则为真 -gt 大于则 ...
- 大哥带的MSsql注入(SQL Server)--预习
①判断数据库类型and exists (select * from sysobjects)--返回正常为mssql(也名sql server)and exists (select count(*) f ...
- sqli-labs(21)
cookie注入 引号和括号闭合 base64编码 0X01 看了题目应该是 cookie注入 闭合是') 那么base64编码是什么鬼?? 看源码解决吧 https://www.cnblogs.co ...
- Oracle数据库备份还原
导出备份的命令: 开始->运行->cmd->exp username/password@tns_name file=d:\backup.dmp 导入备份的命令: 开始->运行- ...
- leetcode-mid-backtracking -46. Permutations-NO
mycode 没有通过,其实只需要把temp.append改为temp+[nums[i]]即可 def permute(nums): def dfs(res,nums,temp): print(num ...
- Python深度学习读书笔记-5.Keras 简介
Keras 重要特性 相同的代码可以在 CPU 或 GPU 上无缝切换运行. 具有用户友好的 API,便于快速开发深度学习模型的原型. 内置支持卷积网络(用于计算机视觉).循环网络(用于序列处理)以及 ...
- 三十九、python面向对象一
A.python面向对象 1.面向对象基础:面向对象三个特性:封装,继承,多态C# java 只能用面向对象编程Ruby,python 函数+面向对象 函数式编程:def 函数def f1(a): r ...
- Git-Runoob:Git 分支管理
ylbtech-Git-Runoob:Git 分支管理 1.返回顶部 1. Git 分支管理 几乎每一种版本控制系统都以某种形式支持分支.使用分支意味着你可以从开发主线上分离开来,然后在不影响主线的同 ...