基于spark邮件自动分类
代码放在github上:click me
一、数据说明
数据集为英文语料集,一共包含20种类别的邮件,除了类别soc.religion.christian的邮件数为997以外每个类别的邮件数都是1000。每份邮件内部包含发送者,接受者,正文等信息。
二、实验方法
2.1 数据预处理
数据预处理阶段采用了几种方案进行测试
直接将邮件内容按空格分词
使用stanford corenlp进行分词,然后使用停词表过滤分词结果
使用stanford corenlp进行分词,并根据词性和停词表过滤分词结果
综合上面三种方案,测试结果最好的是方案二的预处理方式。将所有的邮件预处理之后写入一个文件中,文件每行对应一封邮件,形式如"类别\t按空格分隔的邮件分词"
comp.os.ms-windows.misc I search Ms-Windows logo picture start Windows
misc.forsale ITEMS for SALEI offer item I reserve the right refuse offer Howard Miller
comp.sys.ibm.pc.hardware I hd bad suggest inadequate power supply how wattage
2.2 pipeline建模
基于spark的pipeline构建端到端的分类模型
将数据预处理后得到的文件上传到hdfs上,spark从hdfs上读取文本数据并转换成DataFrame
为DataFrame的邮件类别列建立索引,然后将DataFrame作为Word2Vec的输入获取句子的向量表示
句子向量输入到含有2层隐藏层的多层感知机(MLP)中进行分类学习
将预测结果的索引列转换成可读的邮件类别标签
A[dataset] -- input --> B[Word2Vec]
B[Word2Vec] -- embeddings --> C[MLP]
C[MLP] -- output --> D[prediction]
三、实验结果
将数据集随机划分成8:2,80%的数据作为训练集,20%的数据作为测试集。经过合理的调参,在测试集上的accuracy和F1 score可以达到90.5%左右,关键参数设置如下
// Word2Vec超参
final val W2V_MAX_ITER = 5 // Word2Vec迭代次数
final val EMBEDDING_SIZE = 128 // 词向量长度
final val MIN_COUNT = 1 // default: 5, 词汇表阈值即至少出现min_count次才放入词汇表中
final val WINDOW_SIZE = 5 // default: 5, 上下文窗口大小[-WINDOW_SIZE,WINDOW_SIZE]
// MLP超参
final val MLP_MAX_ITER = 300 // MLP迭代次数
final val SEED = 1234L // 随机数种子,初始化网络权重用
final val HIDDEN1_SIZE = 64 // 第一层隐藏层节点数
final val HIDDEN2_SIZE = 32 // 第二层隐藏层节点数
final val LABEL_SIZE = 20 // 输出层节点数
邮件预测结果输出在hdfs上,文件内容每行的de左边是真实label,右边是预测label

四、实验运行
4.1 环境要求
hadoop-2.7.5
spark-2.3.0
stanford corenlp 3.9.2
4.2 源代码说明
Maven项目文件结构如下
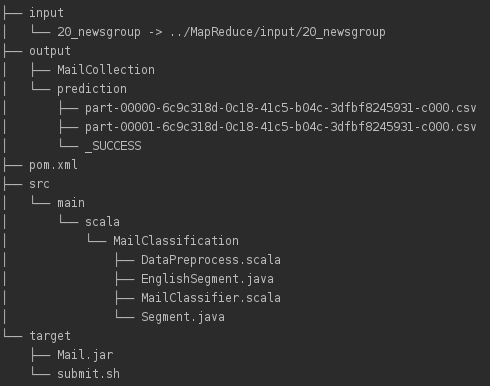
src/main/scala下为源代码,其中Segment.java和EnglishSegment.java用于英文分词,DataPreprocess.scala基于分词作数据预处理,MailClassifier.scala对应邮件分类模型。input下为数据集,output下为数据预处理结果MailCollection和预测结果prediction,target下为maven打好的jar包Mail.jar以及运行脚本submit.sh,pom.xml为maven配置。
4.3 运行方式
将数据集20_newsgroup放在input目录下,确保pom.xml中的依赖包都满足以后运行DataPreprocess得到预处理的结果MailCollection输出到output目录下。启动hadoop的hdfs,将MailCollection上传到hdfs上以便spark读取。然后启动spark,命令行下进入到target路径下运行./submit.sh提交任务,submit.sh内容如下
spark-submit --class MailClassifier --master spark://master:7077 --conf spark.driver.memory=10g --conf spark.executor.memory=4g --conf spark.executor.cores=2 --conf spark.kryoserializer.buffer=512m --conf spark.kryoserializer.buffer.max=1g Mail.jar input/MailCollection output
运行MailClassifier需要两个命令行参数,其中input/MailCollection为上传到hdfs上的路径名,output为预测结果输出到hdfs上的路径名,提交任务前确保输出路径在hdfs上不存在,否则程序会删除输出输出路径以确保程序正确运行。
基于spark邮件自动分类的更多相关文章
- 基于Spark Mllib的文本分类
基于Spark Mllib的文本分类 文本分类是一个典型的机器学习问题,其主要目标是通过对已有语料库文本数据训练得到分类模型,进而对新文本进行类别标签的预测.这在很多领域都有现实的应用场景,如新闻网站 ...
- 基于Spark ALS构建商品推荐引擎
基于Spark ALS构建商品推荐引擎 一般来讲,推荐引擎试图对用户与某类物品之间的联系建模,其想法是预测人们可能喜好的物品并通过探索物品之间的联系来辅助这个过程,让用户能更快速.更准确的获得所需 ...
- 【基于spark IM 的二次开发笔记】第一天 各种配置
[基于spark IM 的二次开发笔记]第一天 各种配置 http://juforg.iteye.com/blog/1870487 http://www.igniterealtime.org/down ...
- 大数据实时处理-基于Spark的大数据实时处理及应用技术培训
随着互联网.移动互联网和物联网的发展,我们已经切实地迎来了一个大数据 的时代.大数据是指无法在一定时间内用常规软件工具对其内容进行抓取.管理和处理的数据集合,对大数据的分析已经成为一个非常重要且紧迫的 ...
- 基于Spark和SparkSQL的NetFlow流量的初步分析——scala语言
基于Spark和SparkSQL的NetFlow流量的初步分析--scala语言 标签: NetFlow Spark SparkSQL 本文主要是介绍如何使用Spark做一些简单的NetFlow数据的 ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...
- UserView--第一种方式set去重,基于Spark算子的java代码实现
UserView--第一种方式set去重,基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import java.util.Ha ...
- 基于Spark自动扩展scikit-learn (spark-sklearn)(转载)
转载自:https://blog.csdn.net/sunbow0/article/details/50848719 1.基于Spark自动扩展scikit-learn(spark-sklearn)1 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
随机推荐
- BZOJ 1937 (luogu 4412) (KM+LCA)
题面 传送门 分析 根据贪心的思想我们得到几条性质: 1.生成树上的边权减小,非树边的边权增加 2.每条边最多被修改一次 设改变量的绝对值为d 对于一条非树边\(j:(u,v)\),树上u->v ...
- SLA服务可用性4个9是什么意思?怎么达到?
SLA:服务等级协议(简称:SLA,全称:service level agreement).是在一定开销下为保障服务的性能和可用性,服务提供商与用户间定义的一种双方认可的协定.通常这个开销是驱动提供服 ...
- shell脚本从入门到精通(初级)之入门篇
写在开头 本文是阅读<Linux命令行与shell脚本编程大全>时的一些笔记,主要是shell脚本的一些基本语法, 还有很多细节和高级内容没有写到. 笔者也是shell script菜鸟, ...
- vue iview分页
距离上次博客更新已经快一个月了,期间也有想法在空闲的时候更新几篇博文. 燃鹅,最近懒癌作祟,丢掉的东西越来越多,再不遏止的话就真成癌了. 趁着刚看完一篇心灵鸡汤,让打满鸡血的我总结下前段时间用到的iv ...
- js字符串相关方法
<script> // 使用索引位置来访问字符串中的每个字符: var carname = 'Volvo XC60'; var character = carname[7]; consol ...
- JS面向对象——组合使用构造函数模型与原型模型
该模型为创建自定义类型最常用的方式. <!DOCTYPE html> <html> <head> <title>组合使用构造函数模型和原型模型</ ...
- IDEA中web项目maven项目手动打war包的方式
手动打包 https://blog.csdn.net/ibigboy/article/details/90287963 tomcat部署web项目方法 https://www.cnblogs.com/ ...
- 2018-2-13-C#-复制列表
title author date CreateTime categories C# 复制列表 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17:23:3 +0 ...
- python序列的深拷贝和浅拷贝
python中的不可变类型 列举:数值,字符串.元组.字节串 数值及字符串“可变”'的假象 num = 123 mystr = 'abc' print(id(num), num) print(id(m ...
- ElasticSearch1.7 java api
package cn.xdf.wlyy.solr.utils; import java.util.ArrayList;import java.util.HashMap;import java.util ...