cassandra百亿级数据库迁移实践
迁移背景
cassandra集群隔段时间出现rt飙高的问题,带来的影响就是请求cassandra短时间内出现大量超时,这个问题发生已经达到了平均两周一次的频率,已经影响到正常业务了。而出现这些问题的原因主要有以下3点:
- 当初设计表的时候partition key设计的不是很合理,当数据量上去(最大的单表行数达到百亿级)之后,出现了一些数据量比较大的partition。单partition最多的数据量达到了上百万行(cassandra不支持mysql的limit m, n的查询),当查询这个partition的数据时,会带来比较大的压力。
- cassandra本身的墓碑机制,cassandra的一大特性就是快速写入,如果遇到delete一条记录时,cassandra并不会实时的对这条记录做物理删除,而是在这行记录上添加一个逻辑删除的标志位,而下次查询会load出这些已经删除了的记录,再做过滤。这样就可能带来及时某个partition的查询出的数据量不大,但是墓碑比较多的时候会带来严重的性能问题。
- 公司dba也不推荐使用cassandra,出现问题的时候,难于定位解决问题。所以决定将cassandra数据库迁移至社区比较成熟的关系型数据库mysql。
迁移方案
整个迁移方案主要分为以下5个步骤:
- 全量迁移:搬迁当前库中所有的历史数据(该过程会搬掉库中大部分数据)
- 增量迁移:记录全量迁移开始的时间,搬迁全量迁移过程中变更了的数据
- 数据比对:通过接口比对cassandra和mysql中的数据,最终数据一致性达到一定99.99%以上
- 开双写:通过数据比对确保全量迁移和增量迁移没问题以后,打开双写。如果双写有问题,数据比对还可以发现双写中的问题。
- 切mysql读:确保双写没问题以后,然后根据服务的重要性级别,逐步按服务切mysql读。所有服务切mysql读以后,确保没问题后关闭cassandra写,最终下线cassandra。
mysql的分库分表方案
- 分多少张表?在DBA的推荐下,单表的数据最好不要超过200w,估算了下最大一张表数据量100亿左右,再考虑到数据未来数据增长的情况,最大的这张表分了8192张表,单表的数据量120w左右,总共分了4个物理库,每个库2048张表。
- 字段对应的问题? 这里需要权衡一个问题,cassandra有List、Set、Map等结构,到mysql这边怎么存?这里可以根据自己实际情况选择,
- 集合结构的转成json之后长度都在1000个字符以内的,可以直接转成json用varchar来保存,优点:处理起来简单。缺点:需要考虑集合的数据增长问题。
- 转成json之后长度比较长,部分已经达到上万个字符了,用单独的一张表来保存。优点:不用考虑集合的数据增长问题。缺点:处理起来麻烦,需要额外维护新的表。
- mysql分片键的选择,我们这里直接采用的cassandra的partition key。
- mysql表的主键和cassandra表保持一致。
全量迁移方案调研
copy导出:通过cqlsh提供的copy命令,把keyspace导出到文件。
缺陷:- 在测试过程中,导出速度大概4500行每秒,在导出过程中偶尔会有超时,导出如果中断,不能从中断处继续。
- 如果keyspace比较大,则生成的文件比较大。所以这种方式不考虑
sstableloader方式:这种方式仅支持从一个cassandra集群迁移到另一个cassandra集群。所以该方式也不考虑
token环遍历方式:cassandra记录的存储原理是采用的一致性hash的策略
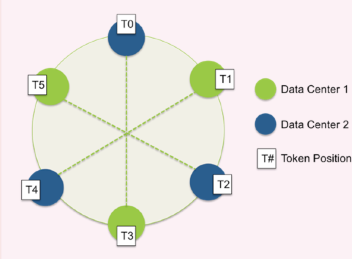
整个环的范围是[Long.MIN_VALUE, Long.MAX_VALUE],表的每条记录都是通过partition key进行hash计算,然后确定落到哪个位置。- 例如有这样一张表:
CREATE TABLE test_table ( a text, b INT, c INT, d text, PRIMARY KEY ( ( a, b ), c ) );
- 通过以下两个cql就可以遍历该张表:
cqlsh:> select token(a,b), c, d from test_table where token(a,b) >= -9223372036854775808 limit 50; token(a, b) | c | d
----------------------+---+----
-9087493578437596993 | 2 | d1
...
-8987733732583272758 | 9 | x1 (50 rows)
cqlsh:> select token(a,b), c, d from test_table where token(a,b) >= -8987733732583272758 limit 50
- 循环以上两个过程,直到token(a, b) = LONG.MAX_VALUE,表示整个表遍历完成。最终采用了该方式。以上几个方案都有一个共同的问题,在迁移过程中,数据有变更,这种情况需要额外考虑。
全量迁移详细过程
最终采用了以上方案3,通过遍历cassandra表的token环的方式,遍历表的所有数据,把数据搬到mysql中。具体如下:
- 把整个token环分为2048段,这么做的目的是为了,把每张表的一个大的迁移任务,划分为2048个小任务,当单个迁移任务出现问题的时候,不用所有数据重头再来,
只需要把出问题的一个小任务重跑就好了。这里采用多线程。 - 迁移模式:主要有single和batch两种模式:
- single模式:逐一insert至mysql。数据量不大的情况选择,单表亿级别以下选择,在64个线程情况下,16个线程读cassandra的情况下,速度可以达到1.5w行每秒。
- batch模式:batch insert至mysql。数据量比较大的情况下选择,单表过亿的情况下选择。最大的一张100亿数据量的表,迁移过程实际上峰值速度只有1.6w行每秒的速度。这是因为cassandra读这部分达到瓶颈了。本身线上应用耗掉了部分资源。如果cassandra读没有达到瓶颈,速度翻倍是没问题的。
- 迁移性能问题:这时候cassandra和mysql和应用机器本身都可能成为瓶颈点,数据量比较大,尽量采用性能好一点的机器。我们当时迁移的时候,采用的一台40核、100G+内存的机器。
- 该过程遇到的一些问题:
- 异常处理问题:由于本身cassandra和mysql的字段限制有一定区别。在这个过程肯定会遇到部分记录因为某列不符合mysql列的限制,导致写入失败,写入失败的记录会记录到文件。这一过程最好是在测试过程中覆盖的越全越好。具体的一些case如下:
- cassandra text长度超过mysql的限制长度
- cassandra为null的情况,mysql字段设置为is not null(这种情况需要创建表的时候多考虑)
- cassandra的timestamp类型超过了mysql的datetime的范围(eg:1693106-07-01 00:00:00)
- cassandra的decimail类型超过了mysql的decimail范围(eg:6232182630000136384.0)
- 数据遗漏问题:由于部分表的字段比较多,代码中字段转换的时候最好仔细一点。我们这边遇到过字段错乱、字段漏掉等问题。再加上该过程没有测试接入,自己开发上线了,数据迁移完成后才发现字段漏掉,然后又重头再来,其中最大的一张表,从头迁一次差不多需要花掉2周的时间。现在回过头去看,这张表当初迁移的时候,还不止返工一次。这个过程实际上是非常浪费时间的。
- 慢查询问题:在最大的一张表的迁移过程中,超时比其他小表要严重一些。并且在跑的过程中发现,速度越跑越慢,排查发现是部分线程遇到了某个token查询始终超时的情况。然后线程一直死循环查询查token。当把cassandra超时时间设置为30s时,这种情况有所改善,但还存在极个别token存在该问题。此处有一点奇怪的是,通过登录到线上cassandra机器,通过cqlsh直接查询,数据是能够查询出来的。最终处理方案是针对该token加了5次重试,如果还是不成功,则记录日志单独处理。
- 异常处理问题:由于本身cassandra和mysql的字段限制有一定区别。在这个过程肯定会遇到部分记录因为某列不符合mysql列的限制,导致写入失败,写入失败的记录会记录到文件。这一过程最好是在测试过程中覆盖的越全越好。具体的一些case如下:
增量迁移详细过程
记录全量迁移开始的时间,以及记录这段时间所有变更的account(一个user包含多个account),把这部分数据发往kafka。再通过额外的增量迁移程序消费kakfa的方式把这部分数据搬到mysql,循环往复该过程,直到mysql中的数据追上cassandra中的数据。
- 消费两个kafka队列,一个为全量迁移这段时间离线变更的account队列,另一个是当前业务实时变更的account队列。
- 处理过程中需要考虑两个队列中account冲突的问题,可以根据accountid进行加锁。
- 起初是按照user维度,进行增量迁移。实际上线后发现,按照user维度搬迁速度根本追不上正常业务数据变更的速度。然后选择了比user低一个维度的account(一个user包含多个account)进行迁移。
数据比对
为什么有该步骤?为了确保cassandra和mysql数据源尽可能的一致。
- 在全量迁移完成以后,增量迁移过程中,便上线了该比对功能。如何比对?当线上业务产生了数据变更,根据accountid,把该accountid下的cassandra的所有数据和mysql的所有数据通过调接口的形式查询出来进行比对。精确到具体字段的值
- 原本认为全量迁移和增量迁移基本没什么问题了,但是通过数据比对还发现了不少的数据不一致地方。排查发现有全量迁移过程导致的,也有增量迁移过程导致的,都是代码bug导致。发现了问题如果某张表全量迁移过程都出了问题,除了需要重新全量迁移该表。并且增量迁移也需要重头再来。
- 所有的比对结果存入数据库,然后定时任务发现比对不过的数据,再按照account维度进行增量迁移。
- 遇到的主要问题如下:
- 时间精度的问题:cassandra的timestamp时间戳精确到毫秒(cassandra的一个客户端工具DevCenter查询出来的时间只精确到秒,毫秒部分被截断了,如果通过该工具肉眼比对,不容易发现该问题),而mysql的datetime默认条件只精确到了秒。
- decimal小数位问题:cassandra中采用的decimal,对应mysql的字段类型是decimal(18,2),cassandra中如果是0或者0.000,迁移到mysql中会变成0.00,需要注意该精度问题。
- 两张表来保存同一份数据导致脏数据问题:由于cassandra查询有很多限制,为了支持多种查询类型。创建了两张字段一模一样的表,除了primary key不一样。然后每次增删改的时候,两张表分别都增删改,虽然这种方式带来了查询上的遍历,但是产生脏数据的几率非常大。在比对的过程中,发现同一份数据两张表的数据量相差不小,排查发现由于早期代码bug导致表一写成功,表二写失败这种情况(好在的是这些数据都是很早之前的数据,所以直接忽略该问题)。而迁移至mysql,只迁移一张表过去。如果两张表的数据不能完全一致,必然有接口表现不一致。我个人对这种一份数据保存两份用法也是不推荐的,如果不在物理层做限制,只通过代码逻辑层来保证数据的一致性,是几乎不可能的事。
- 空字符和NULL的问题:cassandra中""空字符串的情况下转换至mysql变为了NULL,这种情况会带来接口返回的数据不一致的问题,在不确定下游如何使用该数据的时候,最好保证完全一致。
- 字段漏掉的问题:比对发现有张表的一个字段漏掉了,根本没有迁移过去,除了需要重新全量迁移该表。并且增量迁移也需要重头再来(尽量避免该问题,该过程是非常耗时的)。
- cassandra数据不一致的问题:同一条select查询语句,连续查询两次返回的结果数不一致。这个比例在万分之一-千分之一,带来的问题就是有的数据始终是比较不过的。
- 应用本地时钟不一致导致的问题:现象就是随着应用的发版,某张表的lastModifyTime的时间,出现了cassandra比mysql小的情况,而从业务角度来说,mysql的时间是正确的。大概有5%的这种情况,并且不会降下去。可能随着下一次发版,该问题就消失了。近10次发版有3次出现了该问题,最终排查发现,由于部署线上应用机器的本地时钟相差3秒,而cassandra会依赖客户端的时间,带来的问题就是cassandra后提交的写入,可能被先提交的写入覆盖。为什么该问题会随着发版而偶然出现呢?因为应用是部署在容器中,每次发版都会分配新的容器。
开双写
经过以上步骤,基本可以认为cassandra和mysql的数据是一致的。然后打开双写,再关闭增量迁移。这时候如果双写有问题,通过比对程序也能够发现。
切mysql读
双写大概一周后,没什么问题的话,就可以逐步按服务切mysql读,然后就可以下线cassandra数据库了。
总结
- cassandra的使用:
- 表的设计:特别需要注意partition key的设计,尽量要保证单个partition的数据量不要太大。
- 墓碑机制:需要注意cassandra的本身的墓碑机制,主要产生的墓碑的情况,主要是delete操作和insert null字段这两种情况。我们这里曾经因为某个用户频繁操作自己app的某个动作,导致数据库这边频繁的对同一个partition key执行delete操作再insert操作。用户执行操作接近上百次后,导致该partition产生大量墓碑,最终查询请求打到该partition key。造成慢查询,应用超时重试,导致cassandra cpu飙升,最终导致其他partition key也受到影响,大量查询超时。
- cassandra客户端时钟不一致的问题,可能导致写入无效。
- 迁移相关:
- 全量迁移和增量迁移,最好在上线之前测试充分,千万注意字段漏掉错位的问题,尽可能的让测试参与。在正式迁移之前,最好在线上创建一个预备库,先可以预跑一次。尽可能的发现线上正式迁移时遇到的问题。否则正式迁移的时候遇问题的时候,修复是比较麻烦的。
- 在切或关闭读写过程中,一定要有回滚计划。
版权声明
作者:wycm
出处:https://www.cnblogs.com/w-y-c-m/p/10823662.html
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。

cassandra百亿级数据库迁移实践的更多相关文章
- 百亿级小文件存储,JuiceFS 在自动驾驶行业的最佳实践
自动驾驶是最近几年的热门领域,专注于自动驾驶技术的创业公司.新造车企业.传统车厂都在这个领域投入了大量的资源,推动着 L4.L5 级别自动驾驶体验能尽早进入我们的日常生活. 自动驾驶技术实现的核心环节 ...
- 从SQL Server到MySQL,近百亿数据量迁移实战
从SQL Server到MySQL,近百亿数据量迁移实战 狄敬超(3D) 2018-05-29 10:52:48 212 沪江成立于 2001 年,作为较早期的教育学习网站,当时技术选型范围并不大:J ...
- 支撑百亿级应用的 NewSQL
支撑百亿级应用的 NewSQL https://zhuanlan.zhihu.com/newsql/ 项目背景 初次接触 TiDB,是通过同程网首席架构师王晓波先生的分享,当时同程网正在使开发和数据库 ...
- [NewLife.XCode]分表分库(百亿级大数据存储)
NewLife.XCode是一个有15年历史的开源数据中间件,支持netcore/net45/net40,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量 ...
- [NewLife.XCode]百亿级性能
NewLife.XCode是一个有10多年历史的开源数据中间件,支持nfx/netcore,由新生命团队(2002~2019)开发完成并维护至今,以下简称XCode. 整个系列教程会大量结合示例代码和 ...
- Redis百亿级Key存储方案(转)
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- Redis百亿级Key存储方案
1 需求背景 该应用场景为DMP缓存存储需求,DMP需要管理非常多的第三方id数据,其中包括各媒体cookie与自身cookie(以下统称supperid)的mapping关系,还包括了supperi ...
- 涂鸦智能 dubbo-go 亿级流量的实践与探索
涂鸦智能 dubbo-go 亿级流量的实践与探索 dubbo 是一个基于 Java 开发的高性能的轻量级 RPC 框架,dubbo 提供了丰富的服务治理功能和优秀的扩展能力.而 dubbo-go 在 ...
- 【转】百亿级实时大数据分析项目,为什么不用Hadoop?
百亿数量级的大数据项目,软硬件总体预算只有30万左右,需求是进行复杂分析查询,性能要求多数分析请求达到秒级响应. 遇到这样的项目需求,预算不多的情况,似乎只能考虑基于Hadoop来实施. ...
随机推荐
- centos7.4 搭建lnmp
系统:阿里云 centos7.4 Php:PHP 7.1.13 (cli) Mysql:mysql5.7 Nginx:nginx/1.12.2 一.更新centos7 yum源 cp /etc/yum ...
- centos6.2 shutdown now关机进入单用户模式
在centos5.5时当我们输入 shutdown now 系统会进入关机状态.而centos6.2时并非如此,其他版本不清楚,而进入了单用户模式.(进入系统后想维护可做此操作.)会出现如下提示:(注 ...
- Use sed and awk to prettify json
$ cat prettify.sed s/,/,\r\n/g s/\[/\r\n\[\r\n/g s/\]/\r\n\]\r\n/g s/{/\r\n{\r\n/g s/}/\r\n}\r\n/g $ ...
- hdu3518 Boring counting(后缀数组)
Boring counting 题目传送门 解题思路 后缀数组.枚举每种长度,对于每个字符串,记录其最大起始位置和最小起始位置,比较是否重合. 代码如下 #include <bits/stdc+ ...
- dubbo远程服务调用和maven依赖的区别
dubbo:跨系统通信.比如:两个系统,一个系统A作客户端,一个系统B作服务器, 服务器B把自己的接口定义提供给客户端A,客户端A将接口定义在spring中的bean.客户端A可直接使用这个bean, ...
- ret/retn人为改变执行地址
1.CALL和RET/RETN是一对指令,CALL把返回地址压入堆栈,RET/RETN把返回地址从堆栈取出,然后将IP寄存器改为该返回地址. 2.不使用CALL,而是人为地把地址放入堆栈即可实现.如 ...
- Python基础篇(set集合)
Python基础篇(set集合,深浅拷贝) set集合是Python的一个基本类型,一般是不常用.set中的元素是不重复的.无序的里边 的元素必须是可hash的比如int,str,tuple,bool ...
- Python的基本类型(list,tuple)
Python的基本类型(list,tuple) 一列表: 1.列表是Python基础的数据类型之一,其他语言也有类似的数据类型,比如js中的数组,java中的数组等,它是以[]括起来 ,每个元素用', ...
- Python之执行精确的浮点数运算
有时候:代码上数字计算可能会有如同下面的误差 原因: 这些错误是由底层CPU和IEEE 754标准通过自己的浮点单位去执行算术时的特征. 由于Python的浮点数据类型使用底层表示存储数据,因此你没办 ...
- C#编程--第二天
一.变量:变量先声明,后赋值,再使用. 语法:变量类型 变量名=值: 变量类型: 分为基本数据类型和引用类 基本数据类型:整型.浮点型.字符型.布尔型 引用类:字符串.日期时间.枚举类型.结构类型 i ...