SQL中INEXISTS和IN 的区别和联系
SET NOCOUNT ON , SET NOCOUNT OFF
当 SET NOCOUNT 为 ON 时,不返回计数(表示受 Transact-SQL 语句影响的行数)。
当 SET NOCOUNT 为 OFF 时,返回计数。
如果存储过程中包含的一些语句并不返回许多实际的数据, 则该设置由于大量减
少了网络流量,因此可显著提高性能。
SQL 中 IN 和 EXISTS 用法的区别:
NOT IN
SELECT DISTINCT MD001 FROM BOMMD WHERE MD001 NOT IN (SELECT MC001
FROM BOMMC)
NOT EXISTS,exists 的用法跟 in 不一样,一般都需要和子表进行关联,而且关联时,需要
用索引,这样就可以加快速度
select DISTINCT MD001 from BOMMD WHERE NOT EXISTS (SELECT MC001 FROM
BOMMC where BOMMC.MC001 = BOMMD.MD001 )
exists 是用来判断是否存在的, 当 exists( 查询 )中的查询存在结果时则返回真, 否则返回假。
not exists 则相反。
exists 做为 where 条件时,是先对 where 前的主查询询进行查询,然后用主查询的结果
一个一个的代入 exists 的查询进行判断,如果为真则输出当前这一条主查询的结果,否则
不输出。
in 和 exists
in 是把外表和内表作 hash 连接, 而 exists 是对外表作 loop 循环, 每次 loop 循环再对内表
进行查询。一直以来认为 exists 比 in 效率高的说法是不准确的。
如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小, 一个是大表, 则子查询表大的用 exists , 子查询表小的用 in :
例如:表 A(小表),表 B(大表) 1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists (select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的 2 :
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists (select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists 如果查询语句使用了 not in 那么内外表都进行全表扫描, 没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。 所以无论那个表大, 用 not exists 都比 not in
要快。
SQL中 in 与 =的区别:
select name from student where name in ('zhang' ,'wang' ,'li' ,'zhao' );
与
select name from student where name ='zhang' or name ='li' or name ='wang' or name ='zhao'
的结果是相同的。
例子如下(即 exists 返回 where 后 2 个比较的 where 子句中 相同值, not exists 则返回 where 子句中 不同值):
exists (sql 返回结果集为真 )
not exists (sql 不返回结果集为真 )
如下:
表 A
ID NAME
1 A1
2 A2
3 A3
表 B
ID AID NAME
1 1 B1
2 2 B2
3 2 B3
表 A 和表 B 是一对多的关系 A.ID --> B.AID
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
1 A1
2 A2
原因可以按照如下分析
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 1)
-->SELECT * FROM B WHERE B.AID = 1 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 2)
-->SELECT * FROM B WHERE B.AID = 2 有值返回真所以有数据
SELECT ID , NAME FROM A WHERE EXISTS (SELECT * FROM B WHERE B.AID = 3)
-->SELECT * FROM B WHERE B.AID = 3 无值返回真所以没有数据
NOT EXISTS 就是反过来
SELECT ID , NAME FROM A WHERE NOT EXIST ( SELECT * FROM B WHERE A.ID =B.AID)
执行结果为
3 A3
SQL 中 in与 exists区别:
IN
确定给定的值是否与子查询或列表中的值相匹配。
EXISTS
指定一个子查询,检测行的存在。
比较使用 EXISTS 和 IN 的查询
这个例子比较了两个语义类似的查询。 第一个查询使用 EXISTS 而第二个查询使用 IN 。 注
意两个查询返回相同的信息。
USE pubs
SELECT DISTINCT pub_name
FROM publishers
WHERE EXISTS
(SELECT *
FROM titles
WHERE pub_id = publishers.pub_id
AND type = 'business')
using the IN clause:
USE pubs;
SELECT distinct pub_name
FROM publishers
WHERE pub_id IN
(SELECT pub_id
FROM titles
WHERE type = 'business')
GO
下面是任一查询的结果集:
pub_name
----------------------------------------
Algodata Infosystems
New Moon Books
(2 row(s) affected)
exits 相当于存在量词:表示集合存在 ,也就是集合不为空只作用一个集合 .
例如:
exist P 表示 P 不空时为真 ; not exist P 表示 p 为空时 为真
in 表示一个标量和一元关系的关系。
例如:
s in P 表示当 s 与 P 中的某个值相等时 为真 ; s not in P 表示 s 与 P 中的每一个值都不相等时为真
in 和 exists性能比较:
in 是把外表和内表作 hash 连接,而 exists 是对外表作 loop 循环,每次 loop 循环再对内表进行查询。
一直以来认为 exists 比 in 效率高的说法是不准确的。如果查询的两个表大小相当,那么用 in 和 exists 差别不大。
如果两个表中一个较小,一个是大表,则子查询表大的用 exists,子查询表小的用 in。
例如:表 A(小表),表 B(大表)
1:
select * from A where cc in (select cc from B)
效率低,用到了 A 表上 cc 列的索引;
select * from A where exists(select cc from B where cc=A.cc)
效率高,用到了 B 表上 cc 列的索引。
相反的
2:
select * from B where cc in (select cc from A)
效率高,用到了 B 表上 cc 列的索引;
select * from B where exists(select cc from A where cc=B.cc)
效率低,用到了 A 表上 cc 列的索引。
not in 和 not exists性能比较:
如果查询语句使用了 not in 那么内外表都进行全表扫描,没有用到索引;
而 not extsts 的子查询依然能用到表上的索引。
所以无论那个表大,用 not exists 都比 not in 要快。
in 与 =的区别:
select name from student where name in ('zhang','wang','li','zhao');
与
select name from student where name='zhang' or name='li' or name='wang' or name='zhao'
的结果是相同的。
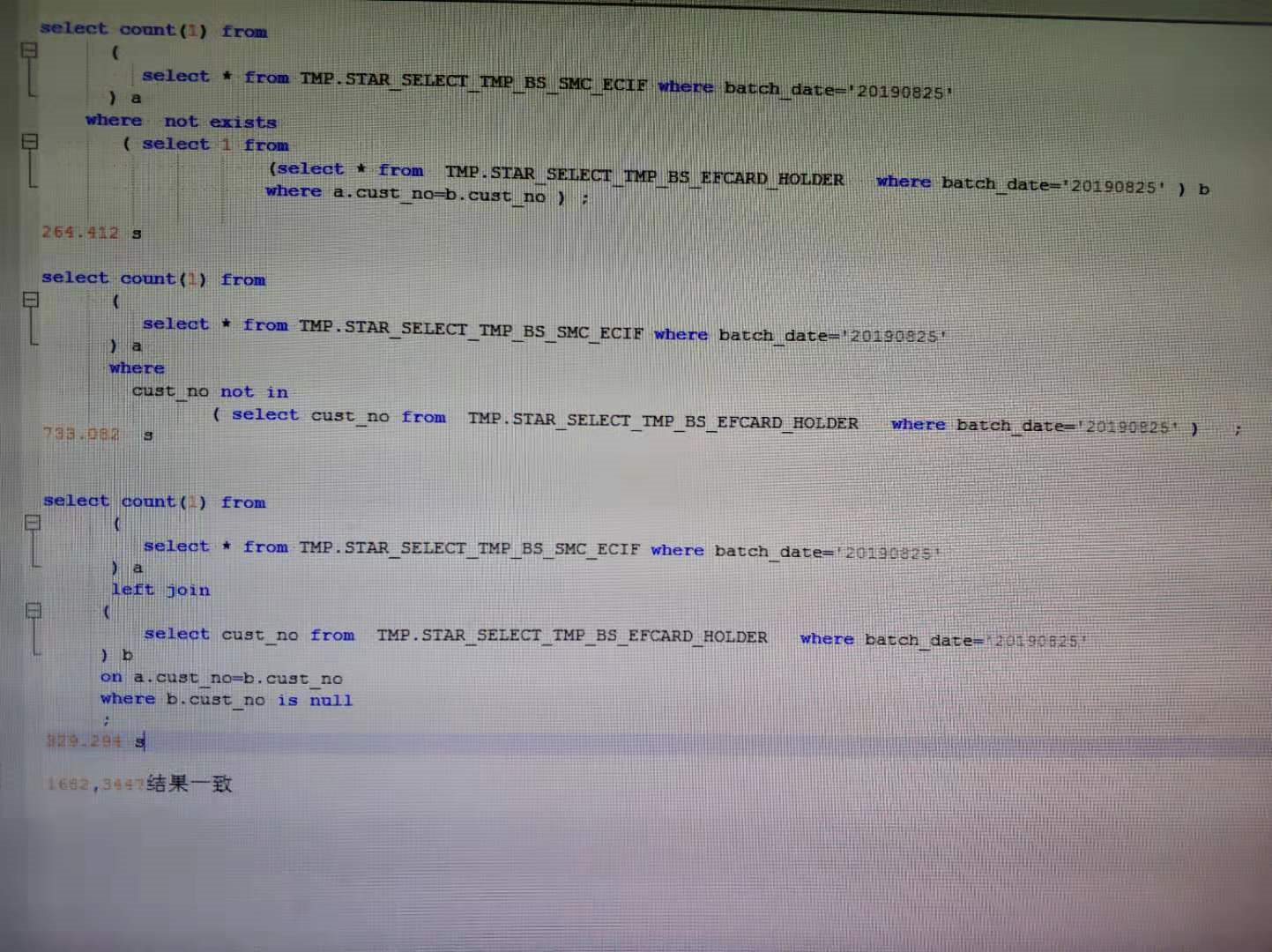
生产环境真实比较:
150节点,数据量 :5000w-3000w:
性能:exists>join null>in
SQL中INEXISTS和IN 的区别和联系的更多相关文章
- SQL中ON和WHERE的区别
SQL中ON和WHERE的区别 - 邃蓝星空 - 博客园 https://www.cnblogs.com/guanshan/articles/guan062.html
- SQL中存储过程和函数的区别
转:https://www.cnblogs.com/jacketlin/p/7874009.html 本质上没区别.只是函数有如:只能返回一个变量的限制.而存储过程可以返回多个. 而函数是可以嵌入在s ...
- 面试问题 - SQL 中存储过程与函数的区别
SQL 中的存储过程与函数没有本质上的区别 函数 -> 只能返回一个变量. 函数可以嵌入到sql中使用, 可以在select 中调用, 而存储过程不行. 但函数也有着更多的限制,比如不能使用临 ...
- SQL中Where与Having的区别
“Where” 是一个约束声明,使用Where来约束来之数据库的数据,Where是在结果返回之前起作用的,且Where中不能使用聚合函数. “Having”是一个过滤声明,是在查询返回结果集以后对查询 ...
- SQL中 WHERE与HAVING的区别
SQL语句中的Having子句与where子句之区别 在说区别之前,得先介绍GROUP BY这个子句,而在说GROUP子句前,又得先说说“聚合函数”——SQL语言中一种特殊的函数.例如SUM, COU ...
- SQL中ON和WHERE的区别(转)
原文:https://www.cnblogs.com/guanshan/articles/guan062.html 数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时 ...
- SQl中drop与truncate的区别
在对SQL的表操作时,我们因不同的需求做出相应的操作. 我来对比一下truncate table '表明'与drop table '表格名'的区别,跟大家一起学习. drop table '表格名'- ...
- SQL 中having 和where的区别分析
在select语句中可以使用groupby子句将行划分成较小的组,然后,使用聚组函数返回每一个组的汇总信息,另外,可以使用having子句限制返回的结果集 在select语句中可以使用groupby子 ...
- sql中Statement与PreparedStatement的区别
1.Statement用于执行静态sql语句,在执行时,必须指定一个事先准备好的sql语句,也就是说sql语句是静态的. 2.PrepareStatement是预编译的sql语句对象,sql语句被预编 ...
随机推荐
- LeetCode.942-DI字符串匹配(DI String Match)
这是悦乐书的第361次更新,第388篇原创 01 看题和准备 今天介绍的是LeetCode算法题中Easy级别的第223题(顺位题号是942).给定仅包含I(增加)或D(减少)的字符串S,令N = S ...
- 【计算机视觉】Emvisi2
Emvisi2: A background subtraction algorithm, robust to sudden light changes Making Background Subtra ...
- poj1042(贪心+枚举)
题目链接:https://vjudge.net/problem/POJ-1042 题意:给n个湖,给出每个湖第一次打捞时鱼的数量f[i],每单位时间鱼减少的数量d[i],从湖i到湖i+1用时t[i], ...
- Luogu P1631 序列合并
题目 开一个堆,先把所有\(a[i]+b[1]\)压进优先队列. 然后每次把最小的取出来,把对应的\(a[i]\)的下一个\(b[j]\)拿出来加进去. #include<bits/stdc++ ...
- mycat schema server rule
schema <?xml version="1.0"?> <!DOCTYPE mycat:schema SYSTEM "schema.dtd" ...
- CF528E Triangles 3000
cf luogu 既然要求三角形面积,不如考虑三角形的面积公式.因为是三条直线,所以可以考虑利用三个交点来算面积,如果这个三角形按照逆时针方向有\(ABC\)三点,那么他的面积为\(\frac{\ve ...
- vue history模式 ios微信分享坑
vue history模式 ios微信分享坑 问题分析:因为苹果分享会是调取签名失败是因为:苹果在微信中浏览器机制和安卓不同,有IOS缓存问题,和IOS对单页面的优化问题,通俗点说安卓进行页面跳转分享 ...
- GUID在安全中作用及生成方法
参考改进于http://blog.csdn.net/jcicheng/article/details/743934 全球唯一标识符 (GUID) 是一个字母数字标识符,用于指示产品的唯一性安装.在许多 ...
- 69. Sqrt(x) (JAVA)
Implement int sqrt(int x). Compute and return the square root of x, where x is guaranteed to be a no ...
- 集合类Hash Set,LinkedHashSet,TreeSet
集合(set)是一个用于存储和处理无重复元素的高效数据结构.映射表(map)类似于目录,提供了使用键值快速查询和获取值的功能. HashSet类是一个实现了Set接口的具体类,可以使用它的无参构造方法 ...