5105 pa3 Distributed File System based on Quorum Protocol
1 Design document
1.1 System overview
We implemented a distributed file system using a quorum based protocol. The basic idea of this protocol is that the clients need to obtain permission from multiple servers before either reading or writing a file to the server. Using this system, multiple clients can share files together. The whole system is composed of 1 coordinator (also a server), 1 or more clients, and several other nodes.
Our system also supports multiple reads on the same file.
- Multiple writes or read+writes to the same file is not allowed.
- Writes to a single file is processed in the order of request sequence.
The client can write (update) files in the file system, or read files. If there is no corresponding filename on the file system, the client will see an appropriate error message.
The nodes will contain replicas of the files and listen to requests from the clients. When a node wants to join the file system, it contacts the coordinator using Thrift. The coordinator will then add it to the server list. A file server which gets a request from the client will contact the coordinator to carry out the operation. That is, any servers can receive read/write requests from users and they will forward the requests to the coordinator.
The coordinator could listen to requests from the servers, and record the information whether a file is free, being read/ written/ synchronizing. The coordinator will build the quorum and then contact the other randomly chosen servers needed for the quorum to complete the operation requested by the server node. The coordinator will be well known to all file servers.
pa3要求实现一个基于Quorum协议的分布式文件系统。 整个系统由若干个client和若干个node组成(其中一个node还兼任Coordinator)。client有两种操作:
- a. Write (update) files in the file system. (可以理解成<文件名, 内容>组成的key-value对)
- b. Read files. If there is no corresponding filename on file system, the client will seeappropriate error message.
每个文件都有版本号,文件内容被更新后版本号会+1。为了在多个replica之间实现同步(保证用户read时总是能得到最新版本的文件内容),需要实现Quorum Protocol。
client可以连接任意一个node来操作文件系统。node读写文件系统时,需要连接coordinator,由coordinator来确定一个Quorum包含哪些机器。Quorum协议中的参数NR和NW是可以让用户来设置的。
Quorum的原理:
Operations are sent (from one replica) to a subset of replicas. 读写操作都要在一坨replicas上进行。读的时候选择整个Quorum中最新的版本作为结果。写的时候一个Quorum里所有机器都要写入。
For N replicas, where Read quorum need NR replicas to agree, and Write quorum need NW replicas to agree. Need to satisfy:
- NR + NW > N (Avoid read-write conflicts, 一坨NR读, 正好另一坨NW写时, 读不到最新版本)
- NW > N/2 (Avoid write-write conflicts, NW不够大时,两坨互不相交的NW同时读到的版本可能不一样)

1.2 Assumptions
We made these assumptions in this system:
• Assume all the files are text file only and ignore its encoding-format.
• The number of files you need to handle will be small (< 10).
• Servers know other servers’ and coordinator’s information (IP and port).
• The file contents will be very simple (e.g., a file name with version number).
• The coordinator will hold a lock for each file.
• Accessing different files should is done concurrently.
• The system works on the CSELabs machines (separate machines), e.g., KH 4-250 (csel-kh4250-xx.cselabs.umn.edu).
1.3 Component design
1.3.1 Common part
In the common part, we defined a Thrift struct Address, which is used to describe a node (IP, port).
1.3.2 Coordinator
Coordinator维护了以下数据结构:
- int NR, NW:记录Quorum协议的参数
- ConcurrentHashMap FSLock:记录每个文件的锁状态(正在write、正在read、free)
- ConcurrentHashMap FSVersion:
- ConcurrentHashMap FSCurrentReadNumber:记录每个文件当前有多少个线程(node)在读
- ConcurrentLinkedDeque requestQueue:记录不同request从node到达Coordinator的顺序。Coordinator中的Coord_Read()和Coord_Write()都按requestQueue中的顺序处理任务并返回。
- ArrayList serverList:记录所有的node节点
To initiate the supernode, input java -cp ".:/usr/local/Thrift/*" Coordinator Port NR NW, for example, “java -cp ".:/usr/local/Thrift/*" Coordinator 9090 4 4”.
The coordinator implements the following methods:
1. String Coord_Read(String filename): When a node wants to read a file, it sends the read request to the coordinator by this method. The coordinator will check whether the file can be read first (not being written). If could, the coordinator will build a quorum with NR servers. The coordinator then asks these servers to read files and pick the latest version to get it back to the server. 检查FSLock中对应文件的锁状态,如果在write就忙等(死循环等待)直到解锁。然后正式开始读:给FSLock标记read,给FSCurrentReadNumber加一,生成一个Quorum,读取这个Quorum内所有node上该文件的版本号并取最新(如果每个node上都不存在这个文件就返回-1),在版本最新的server上rpc调用DirectRead读取该机器上的文件内容。结束后释放FSLock和FSCurrentReadNumber(如果这时FSCurrentReadNumber==0了就置FSLock为free),返回结果。
2. boolean Coord_Write(String filename, String fileContent): When a node wants to write a file, it sends the write request to the coordinator by this method. The coordinator will check whether the file can be written first (not being written or read). If could, the coordinator will build a quorum with NW servers. The coordinator then asks these servers to update the files. 检查FSLock中对应文件的锁状态,如果在write或者read就忙等(死循环等待)直到解锁(如果直接是null表示文件还不存在,直接往下执行即可)。然后正式开始写:给FSLock标记write,生成一个Quorum,获取这一Quorum内所有node上该文件的版本号并取最新(用于写文件的时候生成最新版本号),在这一Quorum的所有node上都执行写入并更新版本号。结束后释放FSLock,返回success。
3. void sync(): In the quorum protocol, replicas can get out of synch. That is, a reader is always guaranteed to get the most recent file (i.e., the latest version) from one of the replicas, but there is no guarantee that the history of updates will be preserved at all replicas. (其实感觉没有sync这一步,Quorum也能一直正常运行下去。sync()只是为了实现eventual consistency,以及TA吃饱撑的hhhhh) To fix this problem, implement a synch operation that brings all replicas up to date with each other and can be called periodically in the background. This operation will be done eventually (with eventual consistency). This is the background synchronization function. It updates all the files to the latest version every 5 seconds. When the file is not being processed, the synchronization function will get the latest version from all the server and then distribute it to all server nodes. sync在一个单独的线程里进行,每五秒sync一次。sync扫描文件系统里的所有文件,如果某个文件的FSLock状态是free,就开始sync它:给FSLock标记write(此时所有对它的读/写操作都要暂停啦),扫描所有node上该文件的版本看是否有不一致(并记下最新版本的文件版本号和内容),如果有就在所有的node上update这个文件。结束后释放FSLock=free,sleep五秒等待下一次sync。
4. ConcurrentHashMap<String, Integer> Coord_lsDir(): this function return all the files in the system and its version number.
5. boolean Join(Address server): The server node calls this function to notify the coordinator to join the file system.
6. boolean reset(int NR, int NW): The function is used to reset the value of NR and NW.
其实用busy waiting不大好...被扣分了qwq
1.3.3 Client
The client is the user interface. It will connect to an arbitrary node.
To initiate it, input “java -cp ".:/usr/local/Thrift/*" Client <nodeIP> <nodePort>”, for example, “java -cp ".:/usr/local/Thrift/*" Client cuda02 7625”.
The client could handle the following operations:
<setdir> local_dirname : Set the local working directory
<getdir> : Show the local working directory. The default working directory is ./ClientDir/
<read> remote_filename : Read a remote file. The client will call read() function on server.
<write> remote_filename local_filename : Write a remote file with the content of a local file. The client will call write() function on server.
<lsremote> : Show the list of all remote files (filename and its version) on the file system. The client will call lsDir() function on server.
<lslocal> : Show the list of all local files in working directory.
<bench-write> : Perform a benchmark: write all files in local working directory to remote file system.
<bench-read> : Perform a benchmark: read all files in remote file system.
<benchmark> tw tr : Perform a benchmark: tw times of [bench-write], then tr times of [bench-read].
<setcod> nr nw : set NR / NW on coordinator. The client will call Coord_reset() function on server.
<quit> : Quit
1.3.4 Node
Node本地有一个ConcurrentHashMap来存储本地的文件版本号,还有一个工作文件夹来存放本地文件。二者一开始都是空的。client连接到node后,client发来的所有读写操作都转发给coordinator来完成,并把结果转发回client(真是偷懒的好机会....)。另外client提供rpc函数给coordinator,用来读写client本地的文件。
The nodes will contain replicas of the files and listen to requests from the clients. The working dir of the node is ./ServerDir_xxxxx (xxxxx is a random number to ensure that the working dir is always empty when every time starting the node).
To initiate the node, input “java -cp ".:/usr/local/Thrift/*" Node <coordinatorIP> <coordinatorPort> <nodePort>”, for example, “java -cp ".:/usr/local/Thrift/*" Node csel-kh1250-02 9090 7625”.
The node implements the following methods:
string Read(1: string FileName): client call Read() to read a file. It will call Coord_read() on coordinator.
i32 Write(1: string FileName, 2: string FileContent): client call Write() to write a file. It will call Coord_write() on coordinator.
map<string,i32> lsDir(): client call Write() to write a file. It will call Coord_lsDir() on coordinator.
i32 GetVersion(1: string FileName): coordinator call this to get the version of file on this server. It will return the local version of the specific local file. Return -1 if the file does not exist. 直接读取本地的文件版本号(每个Node都有一个ConcurrentHashMap来存储本地的文件版本号)
string DirectRead(1: string FileName): a coordinator call DirectRead() to read file. It will return the local content of the specific local file. Return “NULL” if the file does not exist. 直接读取本地文件
i32 DirectWrite(1: string FileName, 2: string FileContent, 3: i32 FileNewVer): a coordinator call DirectWrite() to write file. It will write the file on local server, and set its version to FileNewVer. 直接写本地文件
bool Coord_reset(1: i32 nr, 2: i32 nw): client call Coord_reset() to reset parameters on coordinator. It will call reset on coordinator.
2 User document
2.1 How to compile
We have written a make script to compile the whole project.
cd pa3/src
./make.sh
2.2 How to run the project
. Run Coordinator
cd pa3/src/
java -cp ".:/usr/local/Thrift/*" Coordinator Port NR NW
<Port>: The port of super
<NR>: quorum size for read operation
<NW>: quorum size for write operation
Eg: java -cp ".:/usr/local/Thrift/*" Coordinator
. Run compute node
Start compute node on 7different machines.
cd pa2/src/
java -cp ".:/usr/local/Thrift/*" Node <coordinatorIP> <coordinatorPort> <nodePort>
<coordinatorIP>: The ip address of coordinator
<coordinatorPort>: The port of coordinator
<NodePort>: The port of node
Eg: java -cp ".:/usr/local/Thrift/*" Node csel-kh1250-
. Run client
cd pa2/src/
java -cp ".:/usr/local/Thrift/*" Client <nodeIP> <nodePort>
<nodeIP>: The ip address of node
<nodePort>: The port of node
E.g: java -cp ".:/usr/local/Thrift/*" Client cuda02
Sample operations on client:
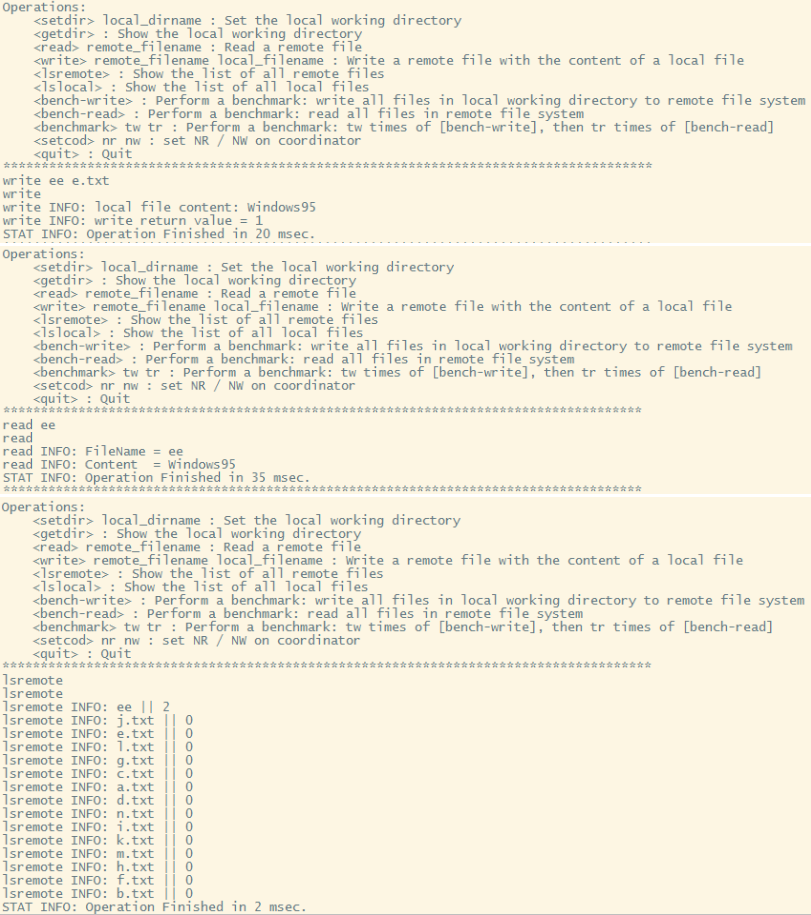
2.3 What will happen after running
The results and log (operation return, succeed flag, time spent, synchronization condition, file version) will be output on the screen. You will be asked to input the next command.
3 Testing Document
3.1 Testing Environment
Machines:
We use 10 machines to perform the test, including 1 coordinator machine (csel-kh1250-01), 6 server machines (csel-kh4250-03, csel-kh4250-01, csel-kh4250-22, csel-kh4250-25, csel-kh4250-34), 3 client machines (csel-kh1250-03).
Test Set:
We use a test set (./ClientDir) including 10 items, totally 314 bytes. The data uses a shared directory via NSF.
Logging:
Logging (operation return, succeed flag, time spent, synchronization condition, file version) is output on the window.
Testing Settings:
We test:
3 clients
read-heavy/ write-heavy workloads
small/big value of NR/NW
3.2 read/write mixed (300 read, 100 read for each client, 300 write, 100 write for each client)
Unit: ms
1)NR = 4, NW = 4
Client 1, read time: 812, write time: 2007
Client 2, read time: 817 , write time: 1876
Client 3, read time: 809, write time: 1796
2)NR = 1, NW = 7
Client 1, read time: 531, write time: 2970
Client 2, read time: 565, write time: 3276
Client 3, read time: 706 , write time: 3606
3)NR = 7, NW = 7
Client 1, read time: 1081, write time: 2754
Client 2, read time: 774, write time: 2854
Client 3, read time: 644, write time: 2875
4)NR = 7, NW = 4
Client 1, read time: 802, write time: 1822
Client 2, read time: 946, write time: 1820
Client 3, read time: 1031, write time: 2225
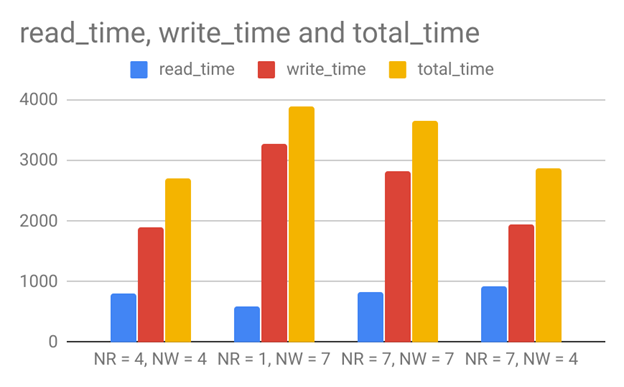
When NR=1, the read time is the shortest. When NW=4, the write time is the shortest. NR = 4, NW = 4 reach the shortest total time. Maybe that’s because the size of the quorum is small, less time were spent in distributing updates to quorum and collect the latest version from Quorum. Also, we found that the time spent on single write operation is much longer than a single read operation.
3.3 write heavy (120 read, 40 read for each client, 480 write, 160 write for each client)
1)NR = 4, NW = 4
Client 1, read time: 284, write time: 2693
Client 2, read time: 228, write time: 2693
Client 3, read time: 262, write time: 2629
2)NR = 1, NW = 7
Client 1, read time: 180, write time: 4052
Client 2, read time: 248, write time: 4083
Client 3, read time: 266, write time: 4117
3)NR = 7, NW = 7
Client 1, read time: 310, write time: 4961
Client 2, read time: 453, write time: 4793
Client 3, read time: 374, write time: 4693
4)NR = 7, NW = 4
Client 1, read time: 301, write time: 2539
Client 2, read time: 317, write time: 2601
Client 3, read time: 361, write time: 2585

When NR=1, the read time is the shortest. When NW=4, the write time is the shortest. NR=4/NW=4 and NR=7/NW=4 reaches the best performance. Since this is the write heavy case, so minimal NW could get the best performance.
3.4 read heavy (480 read, 160 read for each client, 120 write, 40 write for each client)
1)NR = 4, NW = 4
Client 1, read time: 1114, write time: 781
Client 2, read time: 893, write time: 751
Client 3, read time: 818, write time: 539
2)NR = 1, NW = 7
Client 1, read time: 880, write time: 1252
Client 2, read time: 690, write time: 1028
Client 3, read time: 584, write time: 982
3)NR = 7, NW = 7
Client 1, read time: 1841, write time: 1646
Client 2, read time: 1740, write time: 1697
Client 3, read time: 1929, write time: 2082
4)NR = 7, NW = 4
Client 1, read time: 1205, write time: 729
Client 2, read time: 1233, write time: 876
Client 3, read time: 1503, write time: 1255
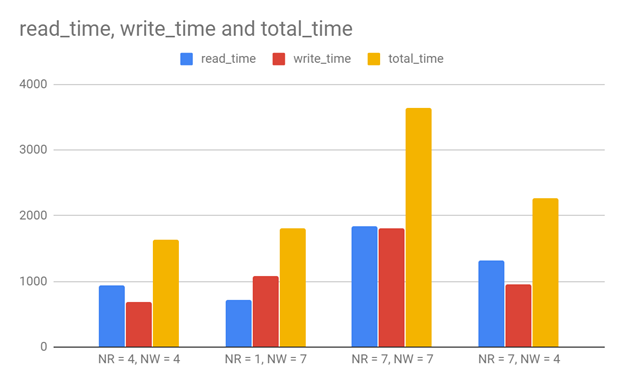
When NR=1, the read time is the shortest. When NW=4, the write time is the shortest. NR=4/NW=4 reaches the best performance. Since this is the read heavy case, so minimal NR could get the best performance.
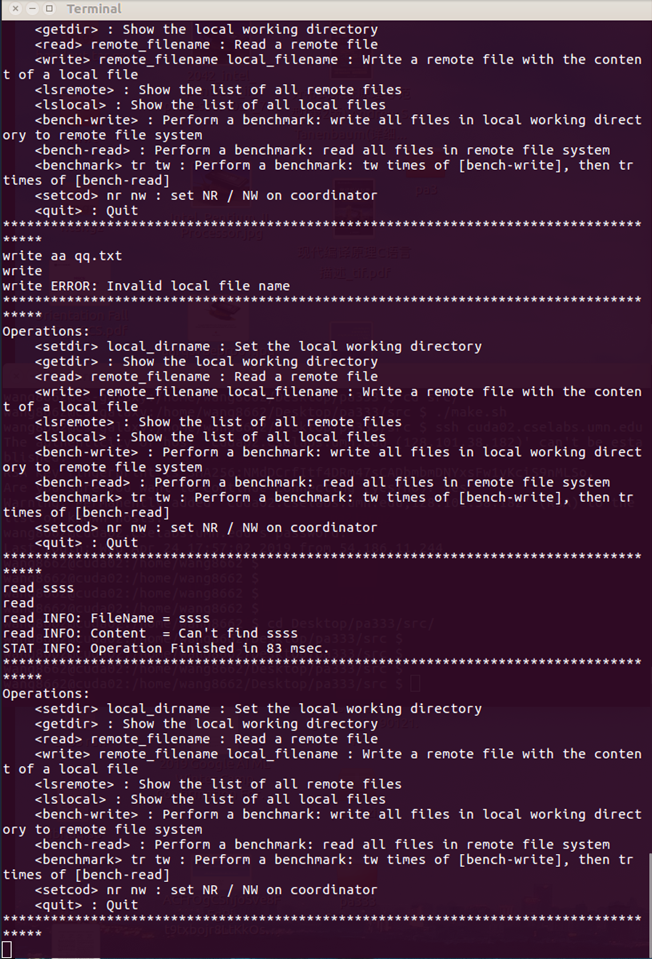
3.5 Negative cases
We tested the 2 cases:
1. read a remote file, while the file does not exist in remote file system
2. write a local file to remote, while the file does not exist in client
5105 pa3 Distributed File System based on Quorum Protocol的更多相关文章
- HDFS(Hadoop Distributed File System )
HDFS(Hadoop Distributed File System ) HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.是根据google发表 ...
- Ceph: A Scalable, High-Performance Distributed File System译文
原文地址:陈晓csdn博客 http://blog.csdn.net/juvxiao/article/details/39495037 论文概况 论文名称:Ceph: A Scalable, High ...
- HDFS分布式文件系统(The Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is designed to store very large data sets reliably, and to ...
- Hadoop ->> HDFS(Hadoop Distributed File System)
HDFS全称是Hadoop Distributed File System.作为分布式文件系统,具有高容错性的特点.它放宽了POSIX对于操作系统接口的要求,可以直接以流(Stream)的形式访问文件 ...
- HDFS(Hadoop Distributed File System )hadoop分布式文件系统。
HDFS(Hadoop Distributed File System )hadoop分布式文件系统.HDFS有如下特点:保存多个副本,且提供容错机制,副本丢失或宕机自动恢复.默认存3份.运行在廉价的 ...
- Yandex Big Data Essentials Week1 Scaling Distributed File System
GFS Key Components components failures are a norm even space utilisation write-once-read-many GFS an ...
- HDFS体系结构:(Distributed File System)
分布式系统的大概图 服务器越来越多,客户端对服务器的管理就会越来越复杂,客户端如果是我们用户,就要去记住大量的ip. 对用户而言访问透明的就是分布式文件系统. 分布式文件系统最大的特点:数据存储在多台 ...
- HDFS(Hadoop Distributed File System)的组件架构概述
1.hadoop1.x和hadoop2.x区别 2.组件介绍 HDFS架构概述1)NameNode(nn): 存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间,副本数,文件权限),以及每个 ...
- HDFS(Hadoop Distributed File System )概述
目录 一.HDFS概述 二.HDFS特点 三.HDFS集群组成:主从架构---一个主节点,多个从节点 1. NameNode(名称节点 / 主节点)----- HDFS集群的管理者 2. DataNo ...
随机推荐
- 一个错误导致懂了mac系统的PATH环境变量
一个完全不懂mac系统的强迫症小白,由于搭建环境都按照百度走,所以在执行命令echo $PATH查看PATH内容时发现怎么有这样一串东西 /usr/local/bin:/usr/bin:/bin:/u ...
- 完美解决linux不能编辑sshd_cofig和实现xshell远程连接的问题
第一步:我们使用命令行vim /etc/ssh/sshd_config 执行修改,强制保持 :wq! 系统不让我们修改这个文件 "/etc/ssh/sshd_config" ...
- Linux内核设计与实现 总结笔记(第十二章)内存管理
内核里的内存分配不像其他地方分配内存那么容易,内核的内存分配不能简单便捷的使用,分配机制也不能太复杂. 一.页 内核把页作为内存管理的基本单位,尽管处理器最小寻址坑是是字或者字节.但是内存管理单元MM ...
- [luogu]P2680 运输计划[二分答案][树上差分]
[luogu]P2680 [NOIP2015]运输计划 题目背景 公元 2044 年,人类进入了宇宙纪元. 题目描述 L 国有 n 个星球,还有 n-1 条双向航道,每条航道建立在两个星球之间,这 n ...
- 「树形结构 / 树形DP」总结
Codeforces 686 D. Kay and Snowflake 要求$O(n)$求出以每个节点为根的重心. 考虑对于一个根节点$u$,其重心一定在[各个子树的重心到$u$]这条链上.这样就能够 ...
- animate(动画)框架 和 swiper (轮播)框架 的使用
swiper.js 框架 网址:https://www.swiper.com.cn/ 是一个专门做轮播,切换特效的轮播 使用方法: 然后进入案例,通过案例来进行各种功能的实现, 这一步是教我们怎么做, ...
- linux中shell变量$#,$@,$0,$1,$2的含义解释<转>
linux中shell变量$#,$@,$,$,$2的含义解释: 变量说明: $$ Shell本身的PID(ProcessID) $! Shell最后运行的后台Process的PID $? 最后运行的命 ...
- React-Native 之 GD (十四)小时风云榜 及 当前时间操作 及 上一小时、下一小时功能实现
1.小时风云榜 GDHourList.js /** * 小时风云榜 */ import React, { Component } from 'react'; import { StyleSheet, ...
- MySQL高可用方案 MHA之三 master_ip_online_change
主从架构master: 10.150.20.90 ed3jrdba90slave: 10.150.20.97 ed3jrdba97 10.150.20.132 ed3jrdba132manager: ...
- 织梦dedecms发布视频文章前台变成一张图片的解决方法
在发布文章的时候,有时需要插入视频的代码,如优酷.腾讯等视频,这样更能让文章变的丰富,但是在发布视频的时候,前台并不能播放视频,而是一张图片 解决这个方法其实很简单,在发布视频文章的时候,将附加选项的 ...