其它——ASCII码,Unicode和UTF-8编码
文章目录
一 ASCII码
计算机内部,所有信息最终都是一个二进制值。每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。也就是说,一个字节一共可以用来表示256种不同的状态,每一个状态对应一个符号,就是256个符号,从00000000到11111111。上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为 ASCII 码,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格SPACE是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
0
1
1
0
0
0
1
0
统一规定为0
0或1
0或1
0或1
0或1
0或1
0或1
0或1
二 非ASCII编码
如果只表示英语,用128个符号编码就够了,但是用来表示其他语言,128个符号是不够的。
比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。
于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。
比如,法语中的é的编码为130(二进制10000010)。
这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。
不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。
比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。
但是不管怎样,所有这些编码方式中,0–127表示的符号是一样的,不一样的只是128–255的这一段。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。
一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。
比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256 x 256 = 65536 个符号
三 Unicode
世界上存在着多种编码方式,同一个二进制数字可以被解释成不同的符号。
因此,要想打开一个文本文件,就必须知道它的编码方式,否则用错误的编码方式解读,就会出现乱码。
这就是为什么文件经常出现乱码,因为编码和解码用的编码方式不一样
可以想象,如果有一种编码,将世界上所有的符号都纳入其中。每一个符号都给予一个独一无二的编码,那么乱码问题就会消失。
这就是 Unicode,就像它的名字都表示的,这是一种所有符号的编码。
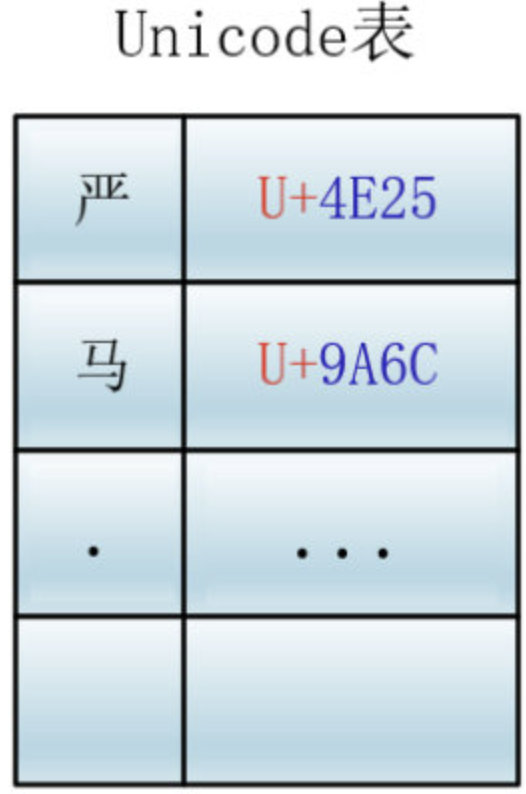
Unicode 为世界上所有字符都分配了一个唯一的数字编号,这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 110 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:
U+9A6C表示汉字马,
U+4E25表示汉字严
U+0639表示阿拉伯字母Ain,
U+0041表示英语的大写字母A,
Unicode 就相当于一张表,建立了字符与编号之间的联系
3.1 Unicode存在的问题
Unicode 只是一个符号集,它只规定了符号的二进制代码,却没有规定这个二进制代码应该如何存储。
比如,汉字严的 Unicode 是十六进制数4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这里就有两个严重的问题:
问题一: 如何才能区别 Unicode 和 ASCII ?计算机怎么知道三个字节表示一个符号,而不是分别表示三个符号呢?
问题二: 英文字母只用一个字节表示就够了,如果 Unicode 统一规定,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍
3.2 它们造成的结果是
结果一: 出现了 Unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 Unicode,主要有 UTF-8,UTF-16,UTF-32。
结果二: Unicode 在很长一段时间内无法推广,直到互联网的出现
四 UTF-8
互联网的普及,强烈要求出现一种统一的编码方式。
UTF-8 就是在互联网上使用最广的一种 Unicode 的实现方式。
其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
注意:UTF-8 是 Unicode 的实现方式之一。
4.1 UTF-8 特点
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
4.2 UTF-8 的编码规则
UTF-8 的编码规则有二条:
**规则一:**对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
**规则二:**对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。下表总结了编码规则,字母x表示可用编码的位。
| 编号范围(编号对应十进制数) | 二进制格式 |
|---|---|
| 十六进制范围:(0x00—0x7f) 十进制范围:(0—127) | 0XXXXXXX |
| 十六进制范围:(0x80—0x7ff) 十进制范围:(128—2047) | 110XXXXX 10XXXXXX |
| 十六进制范围:(0x800—0xffff) 十进制范围:(2048—65535) | 1110XXXX 10XXXXXX 10XXXXXX |
| 十六进制范围:(0x10000—0x10ffff) 十进制范围:(65536以上) | 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX |
五 Unicode和UTF-8之间的转换
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
下面,还是以汉字严为例,演示如何实现 UTF-8 编码。
严的 Unicode 是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5
后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的 UTF-8 编码是11100100 10111000 10100101,转换成十六进制就是E4B8A5
其它——ASCII码,Unicode和UTF-8编码的更多相关文章
- ascii、unicode、utf、gb等编码详解
很久很久以前,有一群人,他们决定用8个可以开合的晶体管来组合成不同的状态,以表示世界上的万物.他们看到8个开关状态是好的,于是他们把这称为"字节".再后来,他们又做了一些可以处理这 ...
- Ascii码 unicode码 utf-8编码 gbk编码的区别
ASCII码: 只包含英文,数字,特殊符号的编码,一个字符用8位(bit)1字节(byte)表示 Unicode码: 又称万国码,包含全世界所有的文字,符号,一个字符用32位(bit)4字节(byte ...
- ASCII,Unicode和UTF-8字符编码
ASCII码 我们知道,在计算机内部,所有的信息最终都表示为一个二进制的字符串.每一个二进制位(bit)有0和1两种状态,因此八个二进制位就可以组合出256种状态,这被称为一个字节(byte).也就是 ...
- ASCII、Unicode、UTF-8字符集编码
ASCII码 计算机内部,所有信息都是由二进制的字符串表示 每一个二进制位有“0”.“1”两种状态,因此8个二进制位可以表示256个状态,每个状态代表一个符号就是256个符号,从0000000到111 ...
- ASCII、UNICODE、UTF
在计算机中,一个字节对应8位,每位可以用0或1表示,因此一个字节可以表示256种情况. ascii 美国人用了一个字节中的后7位来表达他们常用的字符,最高位一直是0,这便是ascii码. 因此asci ...
- python中的字符串编码问题——2.理解ASCII码、ANSI码、Unicode编码、UTF-8编码
ASCII码:全名是American Standard Code for Information Interchange,ASCII码中,一个英文字母(不分大小写)占一个字节的空间,范围0x00~0x ...
- ASCII与Unicode编码消息写文件浅析
[文章摘要] ASCII与Unicode是两种常见的字符编码. 它们的表示方法不一样,因而在程序中就要差别处理. 本文基于作者的实际开发经验,对ASCII与Unicode两种字符编码消息的写文件过程进 ...
- 字符编码笔记:ASCII,Unicode 和 UTF-8(理解)
1.ASCII 码 美国制定的字符编码规则,对英语字符与二进制位之间的关系做了统一规定. 占一个字节,8 位,最多可表示 2^8 = 256 种状态(字符) 实际共有 128 个字符,只占用一个字节的 ...
- 【python路飞】编码 ascii码(256位 =1个字节)美国;unicode(万国码)中文 一共9万个 用4个字节表示这9万个子 17位就能表示
8位一个字节 1024字节 1KB 1024KB 1MB ASCII码不能包含中文.创建了unicode,一个中文4个字节.UTF-8一个中文3个.GBK中国人用的只包含中文2个字节 升级 Un ...
- Java基础笔记(六)——进制表示、ASCII码和Unicode编码
Java中有三种表示整数的方法:十进制.八进制.十六进制. 八进制:以0开头,包括0~7的数字.如:int octal=020; //定义int型变量存放八进制数据 十六进制:以0x或0X开头,包括 ...
随机推荐
- SpringBoot定义优雅全局统一Restful API 响应框架六
闲话不多说,继续优化 全局统一Restful API 响应框架 做到项目通用 接口可扩展. 如果没有看前面几篇文章请先看前面几篇 SpringBoot定义优雅全局统一Restful API 响应框架 ...
- CKS 考试题整理 (15)-镜像扫描ImagePolicyWebhook
Context cluster 上设置了容器镜像扫描器,但尚未完全集成到cluster 的配置中. 完成后,容器镜像扫描器应扫描并拒绝易受攻击的镜像的使用. Task 注意:你必须在 cluster ...
- HTML5新特性之Web Storage
Web Storage是HTML5新增的特性,能够在本地浏览器存储数据,对数据的操作很方便,最大能够存储5M. Web Storage有两种类型: SessionStorage 和 LocalStor ...
- 从零开始整SpringBoot-工具与插件
工具 工具 名称 地址 IDEA https://www.jetbrains.com/idea/ JDK1.8 https://www.oracle.com/java/technologies/jav ...
- O2OA(翱途)开发平台如何在流程表单中使用基于Vue的ElementUI组件?
本文主要介绍如何在O2OA中进行审批流程表单或者工作流表单设计,O2OA主要采用拖拽可视化开发的方式完成流程表单的设计和配置,不需要过多的代码编写,业务人员可以直接进行修改操作. 在流程表单设计界面, ...
- 如何使用libavfilter库给pcm音频采样数据添加音频滤镜?
一.初始化音频滤镜 初始化音频滤镜的方法基本上和初始化视频滤镜的方法相同,不懂的可以看上篇博客,这里直接给出代码: //audio_filter_core.cpp #define INPUT_SAMP ...
- 【websocket】小白快速上手flask-socketio
大家好,我是一个初级的Python开发工程师.本文是结合官方教程和代码案例,简单说下我对flask-socketio的使用理解. 一.websocket简介 websocket 说白一点就是,建立客户 ...
- ZIM|一站式接入,打通 RTC 和 IM 组合拳
从用户信息.用户心跳到用户间私人与聊天室通信,IM 一直是互联网世界中不可或缺的基础建设之一.早在连麦和直播诞生之前,IM 就已是在通讯领域内服役多年的老兵,而随着线上音视频的兴起,IM 不仅没有没落 ...
- Nextcloud允许不被信任的域访问 取消 trusted domains
在服务器部署了Nextcloud,由于测试需要,经常从不同的地址访问,但是每次访问都要把域名添加到受信任域,反反复复修改也挺麻烦,暂时又没找到通配符或者禁用的方法. 不过网上提供了一个替代方法,动态生 ...
- ChatGPT插件开发实战
1.概述 ChatGPT是一款由OpenAI推出的先进对话模型,其强大的自然语言处理能力使得它成为构建智能对话系统和人机交互应用的理想选择.为了进一步拓展ChatGPT的功能和适应不同领域的需求,Op ...