RDD练习:词频统计
一、词频统计:
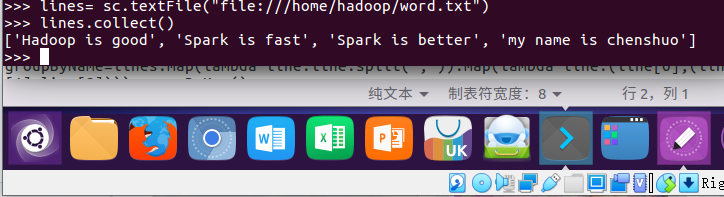
1.读文本文件生成RDD lines
lines=sc.textFile("file:///home/hadoop/word.txt") #读取本地文件
lines.collect()
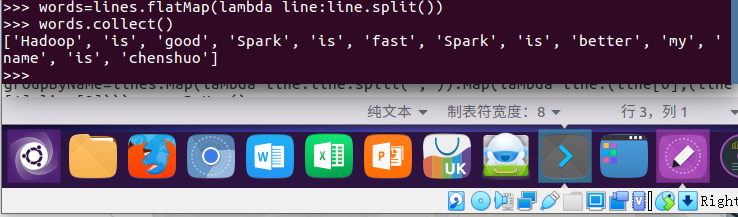
2.将一行一行的文本分割成单词 words flatmap()
words=lines.flatMap(lambda line:line.split()) #划分单词
words.collect()
3.全部转换为小写 lower()
words=words.map(lambda line:line.lower()) #变为小写
words.collect()

4.去掉长度小于3的单词 filter()
words=words.filter(lambda word:len(word)>3)
words.collect()

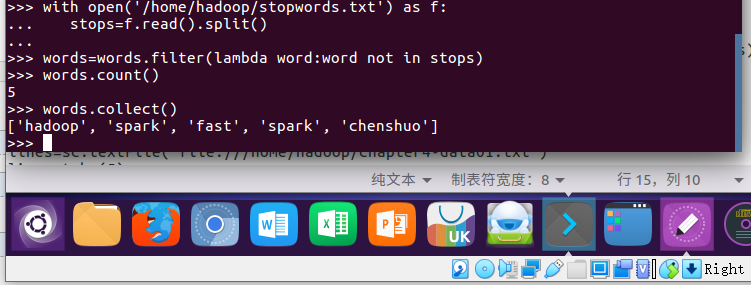
5.去掉停用词
with open('/home/hadoop/stopwords.txt')
stops=f.read().split()
words=words.filter(lambda word:word not in stops)
words.count()
words.collect()
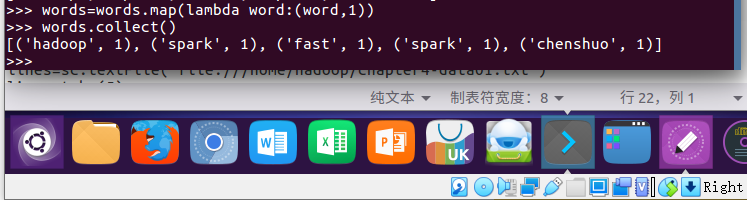
6.转换成键值对 map()
words=words.map(lambda word:(word,1))
words.collect()
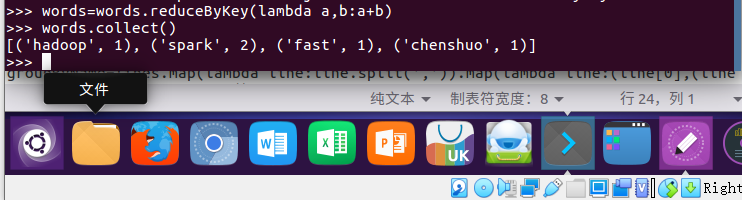
7.统计词频 reduceByKey()
words=words.reduceByKey(lambda a,b:a+b)
words.collect()
二、学生课程分数 groupByKey()
-- 按课程汇总全总学生和分数
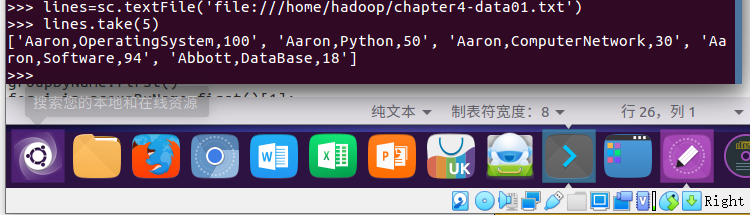
lines = sc.textFile('file:///home/hadoop/chapter4-data01.txt')
lines.take(5)
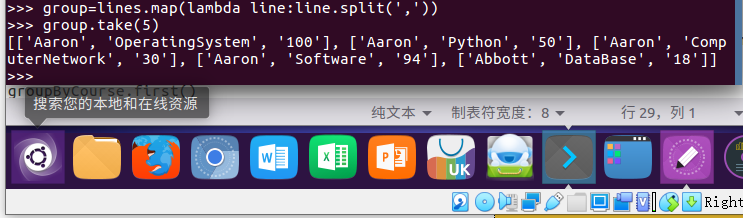
1. 分解出字段 map()
group=lines.map(lambda line:line.split(','))
group.take(5)
2. 生成键值对 map()
group=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],(line[0],line[2])))
group.take(5)

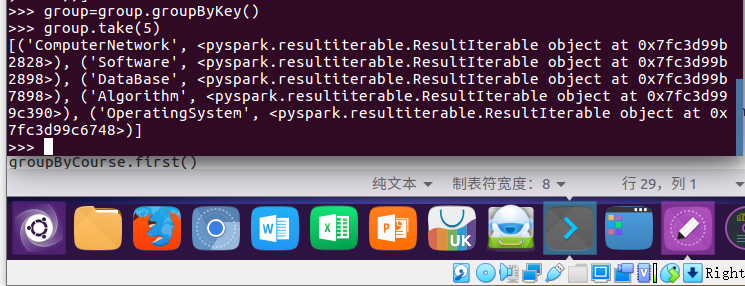
3. 按键分组
group=group.groupByKey()
group.take(5)
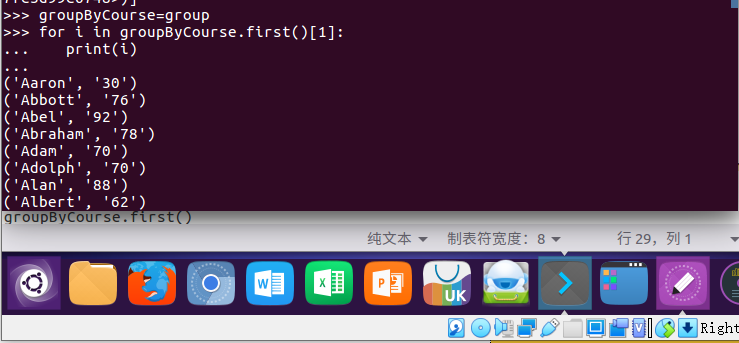
4. 输出汇总结果
groupByCourse=group
for i in groupByCourse.first()[1]:
print(i)
三、学生课程分数 reduceByKey()
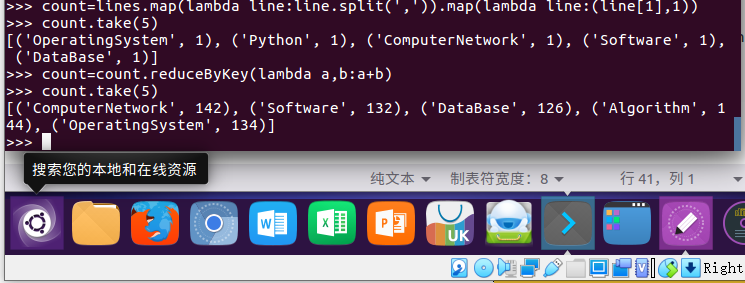
-- 每门课程的选修人数
count=lines.map(lambda line:line.split(',')).map(lambda line:(line[1],1))
count=count.reduceByKey(lambda a,b:a+b)
count.take(5)
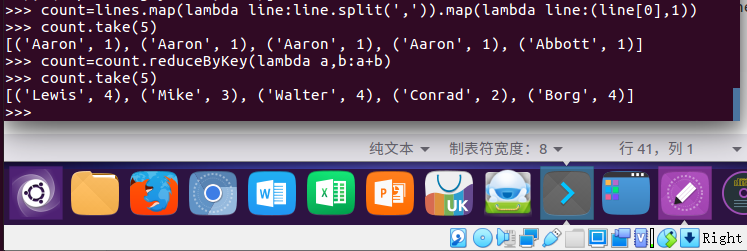
-- 每个学生的选修课程数
count=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],1))
count=count.reduceByKey(lambda a,b:a+b)
count.take(5)
RDD练习:词频统计的更多相关文章
- 05 RDD练习:词频统计,学习课程分数
.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5. ...
- 05 RDD练习:词频统计
一.词频统计: 1.读文本文件生成RDD lines 2.将一行一行的文本分割成单词 words flatmap() 3.全部转换为小写 lower() 4.去掉长度小于3的单词 filter() 5 ...
- 作业3-个人项目<词频统计>
上了一天的课,现在终于可以静下来更新我的博客了. 越来越发现,写博客是一种享受.来看看这次小林老师的“作战任务”. 词频统计 单词: 包含有4个或4个以上的字 ...
- C语言实现词频统计——第二版
原需求 1.读取文件,文件内包可含英文字符,及常见标点,空格级换行符. 2.统计英文单词在本文件的出现次数 3.将统计结果排序 4.显示排序结果 新需求: 1.小文件输入. 为表明程序能跑 2.支持命 ...
- c语言实现词频统计
需求: 1.设计一个词频统计软件,统计给定英文文章的单词频率. 2.文章中包含的标点不计入统计. 3.将统计结果以从大到小的排序方式输出. 设计: 1.因为是跨专业0.0···并不会c++和java, ...
- 软件工程第一次个人项目——词频统计by11061153柴泽华
一.预计工程设计时间 明确要求: 15min: 查阅资料: 1h: 学习C++基础知识与特性: 4-5h: 主函数编写及输入输出部分: 0.5h: 文件的遍历: 1h: 编写两种模式的词频统计函数: ...
- python瓦登尔湖词频统计
#瓦登尔湖词频统计: import string path = 'D:/python3/Walden.txt' with open(path,'r',encoding= 'utf-8') as tex ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- pyspark进行词频统计并返回topN
Part I:词频统计并返回topN 统计的文本数据: what do you do how do you do how do you do how are you from operator imp ...
- 使用storm分别进行计数和词频统计
计数 直接上代码 public class LocalStormSumTopology { public static void main(String[] agrs) { //Topology是通过 ...
随机推荐
- String API(全)
类型 名称 char charAt(int index)返回 char指定索引处的值. int codePointAt(int index)返回指定索引处的字符(Unicode代码点). int co ...
- kubernetes核心实战(八)--- service
13.service 四层网络负载 创建 [root@k8s-master-node1 ~/yaml/test]# [root@k8s-master-node1 ~/yaml/test]# vim m ...
- kubernetes核心实战(二)---Pod+ReplicaSet
3.pod Pod 是可以在 Kubernetes 中创建和管理的.最小的可部署的计算单元. Pod (就像在鲸鱼荚或者豌豆荚中)是一组(一个或多个) 容器:这些容器共享存储.网络.以及怎样运行这些容 ...
- 【Contest】Nowcoder 假日团队赛1 题解+赛后总结
比赛链接 通过顺序:\(B\rightarrow D\rightarrow I\rightarrow J\rightarrow G\rightarrow H \rightarrow A \righta ...
- DG:RFS[8]: No standby redo logfiles created for thread 2
环境:两节点的RAC在线搭建DG,处理报错 现象:RFS[8]: No standby redo logfiles created for thread 2 ,thread2 没有建立redo Tue ...
- mysql迁移:mysqldump导出数据库
问题描述:要将一个mysql中六个数据库导出来,使用mysqldump导出 mysqldump使用语法:mysqldump -uroot -p -S /data/mysql/db_itax_m/mys ...
- React Native 开发环境搭建——nodejs安装、yarn安装、JDK安装多个版本、安装Android Studio、配置Android SDK的环境变量
一.React Native介绍 二.开发环境的搭建 2.1.Node.js安装 Node.js要求14版或更新 https://nodejs.org/en 查看版本: 2.2.yarn安装 Yarn ...
- JavaScript基础语法-变量
JavaScript JavaScript - 变量 1. 概念 变量是用于存放数据的容器 通过变量名可以获取数据 并且数据是可修改的 2. 使用 声明变量 只声明不赋值 直接调用 程序会输出unde ...
- 3.2 构造器、this、包机制、访问修饰符、封装
构造器 构造器:在实例化的一个对象的时候会给对象赋予初始值,因此我们可以通过修改构造器,来改变对象的初始值,构造器是完成对象的初始化,并不是创建对象 我们也可以创建多个构造器实现不同的初始化,即构造器 ...
- day05-优惠券秒杀01
功能03-优惠券秒杀01 4.功能03-优惠券秒杀 4.1全局唯一ID 4.1.1全局ID生成器 每个店铺都可以发布优惠券: 当用户抢购时,就会生成订单,并保存到tb_voucher_order这张表 ...