flume采集nginx日志文件数据到Kafka
flume官网地址http://flume.apache.org/

#下载
wget https://mirrors.bfsu.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz
#解压
tar -zxvf apache-flume-1.9.0-bin.tar.gz
#flume-env.sh中配置JAVA_HOME
cd apache-flume-1.9.0-bin/conf
cp flume-env.sh.template flume-env.sh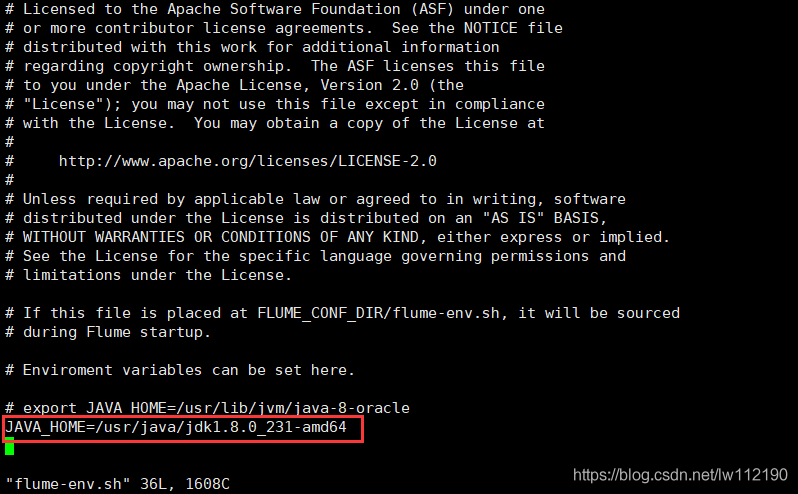
新建flume-conf文件,内容如下
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /usr/local/nginx/logs/mylog.log
# Describe the sink
#a1.sinks.k1.type = logger
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = topic_log
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092,node04:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sinks.k1.kafka.producer.compression.type = snappy
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动flume
./bin/flume-ng agent --conf conf --conf-file conf/flume-conf --name a1 -Dflume.root.logger=INFO,consoleflume采集nginx日志文件数据到Kafka的更多相关文章
- Centos7 搭建 Flume 采集 Nginx 日志
版本信息 CentOS: Linux localhost.localdomain 3.10.0-862.el7.x86_64 #1 SMP Fri Apr 20 16:44:24 UTC 2018 x ...
- Flume采集处理日志文件
Flume简介 Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据 ...
- Flume采集Nginx日志到HDFS
下载apache-flume-1.7.0-bin.tar.gz,用 tar -zxvf 解压,在/etc/profile文件中增加设置: export FLUME_HOME=/opt/apache-f ...
- 使用flume抓取tomcat的日志文件下沉到kafka消费
Tomcat生产日志 Flume抓取日志下沉到kafka中 将写好的web项目打包成war包,eclise直接导出export,IDEA 在artifact中添加新的artifact-achieve项 ...
- apache与nginx日志文件的区别(转载)
apache与nginx日志文件的区别 转载:http://www.xfcodes.com/apache/log/3270.htm 导读:apache与nginx日志文件的区别,在apache与ngi ...
- elk系列3之通过json格式采集Nginx日志【转】
转自 elk系列3之通过json格式采集Nginx日志 - 温柔易淡 - 博客园http://www.cnblogs.com/liaojiafa/p/6158245.html preface 公司采用 ...
- nginx日志文件的配置
文章来源 运维公会: nginx日志文件的配置 1.日志介绍 nginx有两种日志,一种是访问日志,一种是错误日志. 访问日志中记录的是客户端对服务器的所有请求. 错误日志中记录的是在访问过程中,因为 ...
- [日志分析]Graylog2采集Nginx日志 被动方式
graylog可以通过两种方式采集nginx日志,一种是通过Graylog Collector Sidecar进行采集(主动方式),另外是通过修改nginx配置文件的方式进行收集(被动方式). 这次说 ...
- 使用logrotate管理nginx日志文件
本文转载自:http://linux008.blog.51cto.com/2837805/555829 描述:linux日志文件如果不定期清理,会填满整个磁盘.这样会很危险,因此日志管理是系统管理员日 ...
- nginx(四)初识nginx日志文件
nginx 日志相关指令主要有两条,一条是log_format,用来设置日志格式,另外一条是access_log,用来指定日志文件的存放路径.格式和缓存大小,通俗的理解就是先用log_format来定 ...
随机推荐
- 【OpenGL ES】基于ValueAnimator的旋转、平移、缩放动效
1 前言 ValueAnimator 基于 Choreographer 的 frame callback 机制,周期性(约16.7ms,与屏幕帧率相关)执行其 doAnimationFrame() ...
- 【Android】MediaCodec详解
1 前言 MediaCodec 主要用于视频解码和编码操作,可以实现视频倍速播放.全关键帧转换.视频倒放等功能. MediaCodec 的工作原理图如下: MediaCodec 的主要接口 ...
- Table布局
Table布局 <table>最常用的也是最正确的使用方法是制作表格,由于其对占据的空间有着划分的作用,便可以使用<table>来布局. 实例 实现一个简单的布局,将表格的bo ...
- python-鼠标宏
按下鼠标左键, 连击 按下鼠标右键, 停止 import win32api import time from pynput.mouse import Button, Controller mouse ...
- python中的泛型使用TypeVar
引入为什么需要TypeVar PEP484的作者希望借助typing模块引入类型提示,不改动语言的其它部分.通过精巧的元编程技术,让类 支持[]运算不成问题.但是方括号内的T变量必须在某处定义,否则要 ...
- 【webserver 前置知识 02】Linux网络编程入门其一
网络结构模式 C/S结构 服务器 - 客户机,即 Client - Server(C/S)结构.C/S 结构通常采取两层结构.服务器负责数据的管理,客户机负责完成与用户的交互任务.客户机是因特网上访问 ...
- [Rust] 命名习惯
[Rust] 命名习惯 通用习惯 CamelCase: 首位是大写字母的单词,没有分隔符: snake_case: 使用下划线作为分隔符,小写单词: SCREAMING_SNAKE_CASE: 使用下 ...
- 【Azure Redis 缓存】Redis 连接失败
问题描述 Azure Redis 出现连接失败,过一会儿后,又能自动恢复. 问题解答 其实,因为Azure Redis服务一直都有升级维护的操作(平均每月一次),Redis服务更新是平台自动进行的计划 ...
- 可视化技术在 Nebula Graph 中的应用
本文首发于 Nebula Graph Community 公众号 本文整理自 #可视化 on Live 主题直播,在本期直播中 3 位可视化嘉宾讲述了他们眼中的可视化,以及他们在可视化项目实践中踩过的 ...
- 高性能图计算系统 Plato 在 Nebula Graph 中的实践
本文首发于 Nebula Graph Community 公众号 1.图计算介绍 1.1 图数据库 vs 图计算 图数据库是面向 OLTP 场景,强调增删改查,并且一个查询往往只涉及到全图中的少量数据 ...