《Linux基础》05. 定时任务调度 · 磁盘分区与挂载 · 网络配置
@
本文以 CentOS7.6 为例
1:定时任务调度
任务调度是指系统在某个时间执行特定的命令或程序。
任务调度分类:
- 系统工作:有些重要的工作必须周而复始地执行。如病毒扫描等。
- 用户工作:个别用户可能希望执行某些程序,比如对 mysql 数据库的备份。
1.1:crontab
功能描述:用来设置定期执行任务。定时任务以类似文本的形式保存,称为时程表。
任务调度配置文件:/etc/crontab
重启任务调度:
service crond restart
基本语法:
crontab 选项
常用选项:
| 参数 | 说明 |
|---|---|
| -l | 查询定时任务,列出时程表。 |
| -e | 编辑个人定时任务,执行文本编辑器(默认为 vi 编辑器)来设定时程表。 |
| -r | 删除当前用户所有定时任务,即清空时程表。 |
编辑时程表时,任务可为命令,也可为 shell 脚本。另外,涉及到路径,最好使用绝对路径。
时程表占位符说明:
| 占位符 | 含义 | 范围 |
|---|---|---|
| 第一个 “ * ” | 分钟 | 0 ~ 59 |
| 第二个 “ * ” | 小时 | 0 ~ 23 |
| 第三个 “ * ” | 一个月中的第几天 | 1 ~ 31 |
| 第四个 “ * ” | 月份 | 1 ~ 12 |
| 第五个 “ * ” | 一周当中的星期几 | 0 ~ 6(0为星期天) |
特殊符号说明:
| 特殊符号 | 含义 |
|---|---|
| “ * ” | 代表任何时间。比如第一个 “ * ” 就代表每分钟都执行一次。 |
| “ , ” | 代表不连续的时间。如 “ 0 8,12,16 * * * ” 就代表在每天的 8:00,12:00,16:00 都执行一次。 |
| “ - ” | 代表连续的时间范围。如 “ 30 5 * * 1-6 ” 就代表在周一到周六的凌晨 5:30 执行。 |
| “ */n ” | 代表每隔多久执行一次。如 “ */10 * * * * ” 就代表每隔 10 分钟执行一次。 |
时间执行示例:
* * * * * 每分钟定时执行一次
0 * * * * 每小时整点定时执行一次
0 0 * * * 每天 0:00 定时执行一次
*/1 * * * * 每分钟定时执行一次
45 22 * * * 每天 22:45 执行
0 17 * * 1 每周一 17:00 执行
0 5 1,15 * * 每月 1 号和 15 号的 5:00 执行
40 4 * * 1-5 每周一到周五的 4:00 执行
*/10 4 * * * 每天的 4:00,每隔 10 分钟执行一次(5:00 过后不再执行)
0 0 1,15 * 1 每月 1 号和 15 号,和每周一的 0:00 执行
注意:星期几和几号最好不要同时出现,阅读时容易引起混乱
示例:
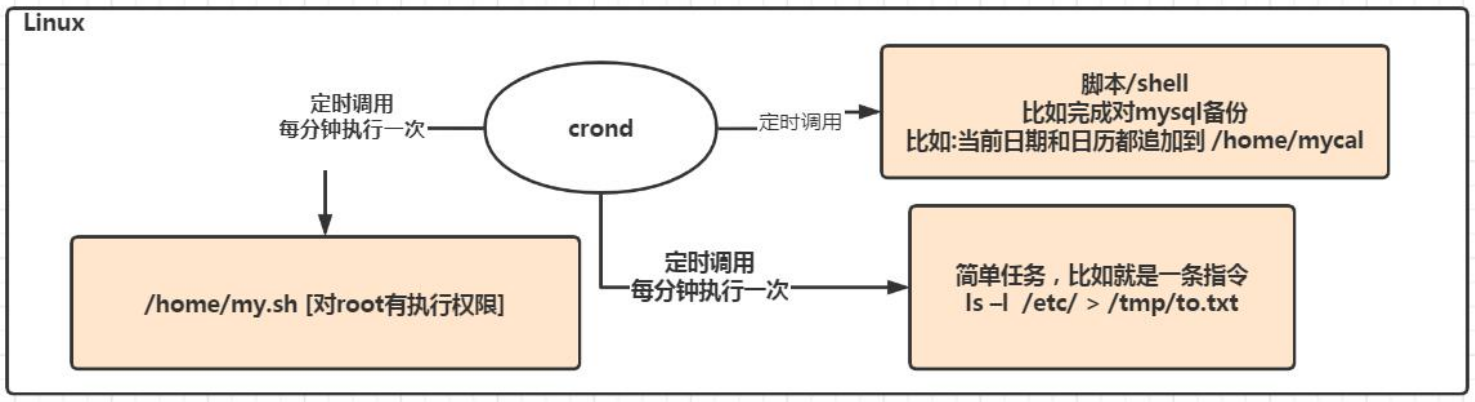
/*
每隔 5 分钟,就将当前的日期信息,追加到 /tmp/mydate.txt 文件中
*/
# 设定时程表,编辑定时任务
crontab -e
# 进入 vi 编辑器的形式,编辑定时任务指令
*/5 * * * * date >> /tmp/mydate.txt
/*
在 /home/ 目录下,创建 shell 脚本 my.sh,实现上一个示例.
*/
# 准备脚本文件
vim /home/my.sh
# 写入以下命令
date >> /tmp/mydate.txt
# 给 my.sh 增加执行权限
chmod u+x /home/my.sh
# 设定时程表,编辑定时任务
crontab -e
# 进入 vi 编辑器的形式,编辑定时任务指令
*/5 * * * * /home/my.sh
1.2:at
功能描述:一次性定时计划任务。默认从标准输入读取要执行的命令。(并非所有 Linux 发行版都自带 at 命令)
at 的守护进程 atd 会以后台模式运行,检查作业队列来运行。
默认情况下,atd 守护进程每 60 秒检查作业队列,有作业时,会检查作业运行时间,如果时间与当前时间匹配,则运行此作业。
在使用 at 命令的时候,一定要保证 atd 进程的启动 , 可以使用相关指令来查看。
检测 atd 是否在运行:
ps -ef | grep atd
查看未执行的任务:
atq
查询到的第一列即为任务编号。
删除未执行的任务:
atrm 编号
基本语法:
at 选项
常用选项:
| 参数 | 说明 |
|---|---|
| 时间 | 以标准输入(命令行)来输入定时任务。需要按两次【ctrl】+【D】来结束输入。 |
| -I(大写 i) | atq 别名,相当于 atq 指令。 |
| -d | atrm别名,相当于 atrm 指令。 |
| -v | 显示任务将被执行的时间。 |
| -t 时间参数 | 以时间参数的形式提交要运行的任务。 |
| -f 文件 | 从指定文件读入任务而不是从标准输入读入。 |
指定时间的方法:
- 接受 hh:mm(小时:分钟)式的时间指定。假如该时间在当天已过去,那就放在第二天执行。例如:at 04:00。
- 使用 midnight(深夜),noon(中午),teatime(饮茶时间,一般是下午 4 点)等比较模糊的词语来指定时间。
- 采用 12 小时计时制,即在时间后面加上 AM(上午)或 PM(下午)来说明是上午还是下午。例如:at 12pm。
- 使用相对计时法。指定格式为:
now + 数字 时间单位,now 就是时间(默认当前,可自己设定),时间单位能够是 minutes(分钟)、hours(小时)、days(天)、weeks(星期)。例如:at now + 5 minutes、at 5pm + 5 days。 - 直接使用 today(今天)、tomorrow(明天)来指定完成命令的时间。
- 指定命令执行的具体日期,指定格式为
month day(月 日)或mm/dd/yy(月/日/年)或dd.mm.yy(日.月.年),指定的日期必须跟在指定时间的后面。例如:at 04:00 2021-03-1
比较抽象。。。由于非常复杂且不常用,这里只举几个简单例子。
示例:
/*
2 天后的下午 5 点执行 /bin/ls /home 命令
*/
# 输入 at 指令并执行
at 5pm + 2 days
# 输入要执行的指令。此时有 “ at> ” 提示。完成后需按两次【ctrl】+【D】来结束
/bin/ls /home
/*
明天 17 点钟,输出时间到指定文件内。比如 /root/date100.log
*/
# 输入 at 指令并执行
at 5pm tomorrow
# 输入要执行的指令。此时有 “ at> ” 提示。完成后需按两次【ctrl】+【D】来结束
date > /root/date100.log
2:磁盘分区与挂载
2.1:原理介绍
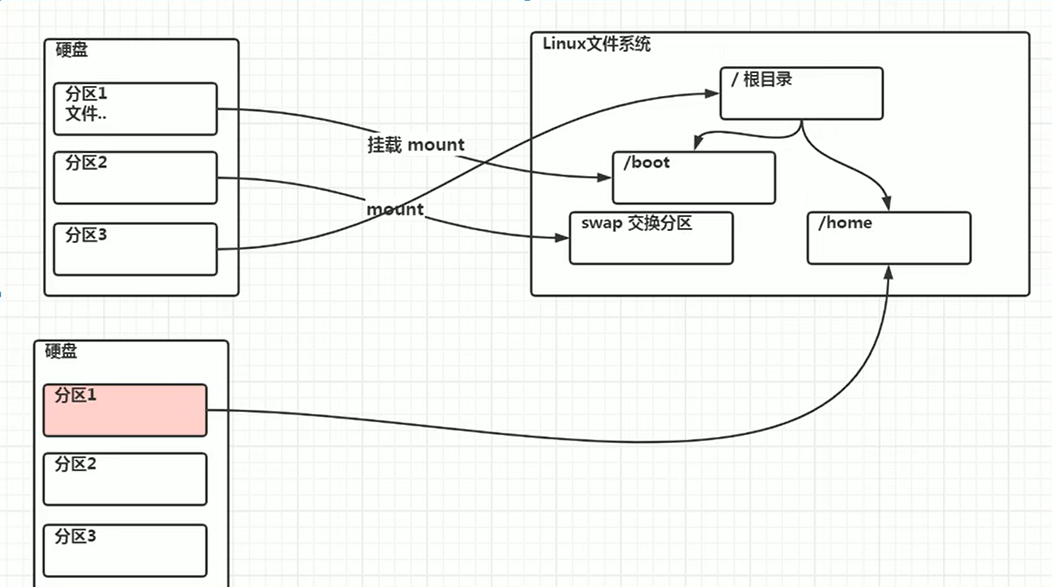
Linux 无论磁盘有几个分区,分给哪一目录使用,归根结底就只有一个根目录,一个独立且唯一的文件结构,Linux 中每个分区都是整个文件系统的一部分。
Linux 采用了一种叫 “ 载入 ” 的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来(挂载)。这时载入的一个分区的存储空间与一个目录(挂载点)对应。
2.2:硬盘说明
Linux 硬盘分 IDE 硬盘和 SCSI 硬盘。目前基本上是 SCSI 硬盘。
- IDE 硬盘
对于 IDE 硬盘,驱动器标识符为 “ hdx~ ”。
其中 “ hd ” 表明分区所在设备的类型是 IDE 硬盘。“ x ” 为盘号(a为基本盘,b 为基本从属盘,c 为辅助主盘,d 为辅助从属盘),“ ~ ” 代表分区,前四个分区用数字 1 到4 表示,它们是主分区或扩展分区,从 5 开始就是逻辑分区。
例,hda3 表示为第一个 IDE 硬盘上的第三个主分区或扩展分区,hdb2表示为第二个 IDE 硬盘上的第二个主分区或扩展分区。
- SCSI 硬盘
对于 SCSI 硬盘,标识符为 “ sdx~ ”。
用 “ sd ” 来表示分区所在设备的类型是 SCSI 硬盘。其余则和 IDE 硬盘的表示方法一样。
2.3:磁盘目录情况查询
2.3.1:lsblk
功能描述:查看设备挂载情况,列出所有可用块设备的信息。(list block)
基本语法:
lsblk [选项]
常用选项:
| 参数 | 说明 |
|---|---|
| -a | 显示所有设备。(不加选项,默认为此选项) |
| -f | 显示文件系统信息。 |
示例:
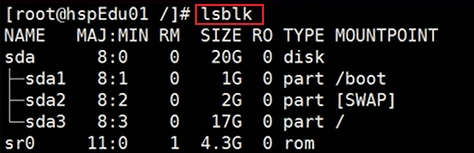
参数说明:
- NAME:块设备名与分区情况。
- MAJ:MIN:表示主要和次要设备号。
- RM:表示设备是否为可移动设备。(1 为可移动设备)
- SIZE:设备的容量大小信息。
- RO:设备是否为只读。(0 代表不是只读的)
- TYPE:表示块设备是否是磁盘或磁盘上的一个分区。(如上图,sda 为磁盘。sda1、sda2、sda3 为 sda 分区。sr0 为只读存储 rom)
- MOUNTPOINT:挂载点。
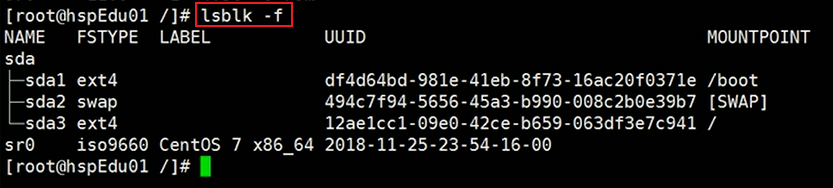
参数说明:
- NAME:块设备名与分区情况。
- FSTYPE:文件类型。
- UUID:分区 40 位唯一标识符。
- MOUNTPOINT:挂载点。
2.3.2:df
功能描述:查询系统整体磁盘使用情况。(disk free)
基本语法:
df [选项] [目录或文件]
常用选项:
| 参数 | 说明 |
|---|---|
| -h | 使用便于人类可读的格式列出信息。 |
| -H | 与 -h 类似,但是以 1000 为换算单位而不是用 1024。 |
示例:
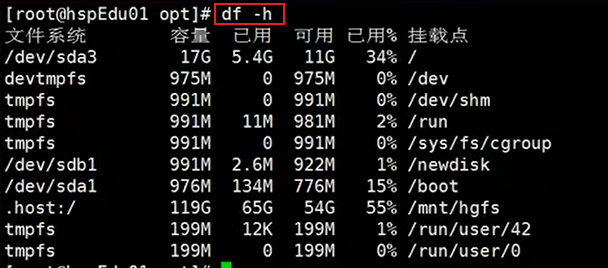
2.3.3:du
功能描述:查询指定目录或文件的磁盘占用情况。(disk usage)
基本语法:
du [选项] [目录或文件]
常用选项:
| 参数 | 说明 |
|---|---|
| -h | 使用便于人类可读的格式列出信息。 |
| -H | 与 -h 类似,但是以 1000 为换算单位而不是用 1024。 |
| -s | 仅显示占用大小汇总。 |
| -a | 列出包含文件在内的大小 |
| -c | 除了显示目录或文件的大小外,也显示占用大小的总和。 |
| --max-depth=数字 | 统计的子目录深度,超过指定层数的目录后,予以忽略。 |
示例:
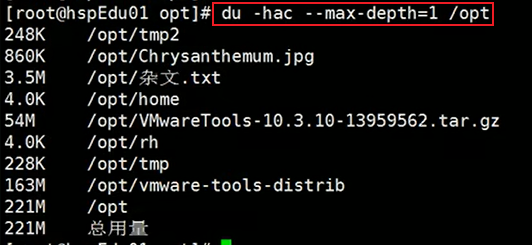
2.3.4:tree
功能描述:以树状图列出目录的内容。(并非所有 Linux 发行版都自带)
基本语法:
tree [选项] 目录
常用选项:
| 参数 | 说明 |
|---|---|
| -a | 显示所有文件和目录。 |
| -C | 在文件和目录清单加上色彩,便于区分各种类型。 |
| -s | 列出文件或目录大小。 |
| -t | 用文件和目录的更改时间排序。 |
2.3.5:其他查看指令示例
# 统计 /opt/ 文件夹下文件的个数
ls -l /opt | grep "^-" | wc -l
# 统计 /opt/ 文件夹下目录的个数
ls -l /opt | grep "^d" | wc -l
# 统计 /opt/ 文件夹下文件的个数,包括子文件夹里的
ls -lR /opt | grep "^-" | wc -l
# 统计 /opt/ 文件夹下目录的个数,包括子文件夹里的
ls -lR /opt | grep "^d" | wc -l
2.4:分区与挂载
2.4.1:fdisk
功能描述:一个创建和维护分区表的程序,即可用来分区。
基本语法:
fdisk [选项]
常用选项:
| 参数 | 说明 |
|---|---|
| /dev/硬盘 | 以命令的方式进行硬盘分区处理。 |
| -l | 查看分区情况。 |
分区时选项说明:
| 选项 | 说明 |
|---|---|
| m | 显示菜单和帮助信息。 |
| p | 显示磁盘分区。同 fdisk -l。 |
| n | 新建分区。 |
| d | 删除分区。 |
| q | 退出不保存。 |
| w | 保存修改并退出。 |
示例:
# 对 /sdb 分区
fdisk /dev/sdb
2.4.2:mkfs
功能描述:用于在特定的分区上建立 Linux 文件系统,即格式化。(make file system)
基本语法:
mkfs [选项] /dev/磁盘分区
常用选项:
| 参数 | 说明 |
|---|---|
| -t 分区类型 | 将磁盘分区格式化为指定格式。 |
示例:
# 将 sdb1 分区格式化为 ext4 格式
mkfs -t ext4 /dev/sdb1
2.4.3:mount
功能描述:用于挂载 Linux 系统外的文件。即将一个分区与一个目录联系起来。
注:以命令行的方式操作,重启后会失效。如需永久生效,要在 /etc/fstab 配置文件中编辑。
基本语法:
mount [选项] 磁盘分区 挂载目录
常用选项:
| 参数 | 说明 |
|---|---|
| -o ro | 以只读模式挂上。 |
| -o rw | 以可读写模式挂上。(默认为此) |
| -a | 将 /etc/fstab 中的定义立即生效。 |
示例:
# 将 /dev/sdb1 以只读模式挂在 /newdisk/ 之下。
mount -o ro /dev/sdb1 /newdisk
# # 将 /dev/sdb1 以可读写模式挂在 /newdisk/ 之下。
mount /dev/sdb1 /newdisk
2.4.4:umount
功能描述:用于卸除文件系统。即移除挂载。(unmount)
注:以命令行的方式操作,重启后会失效。如需永久生效,要在 /etc/fstab 配置文件中编辑。
基本语法:
umount name
“ name ” 可以用分区名称或挂载点。
示例:
# 将上例中 sdb1 卸载。
方式一、 umount /dev/sdb1
方式二、 umount /newdisk
2.4.5:相关配置文件
有关挂载的配置,保存在 /etc/fstab 文件。
可通过编辑此文件来改变挂载。
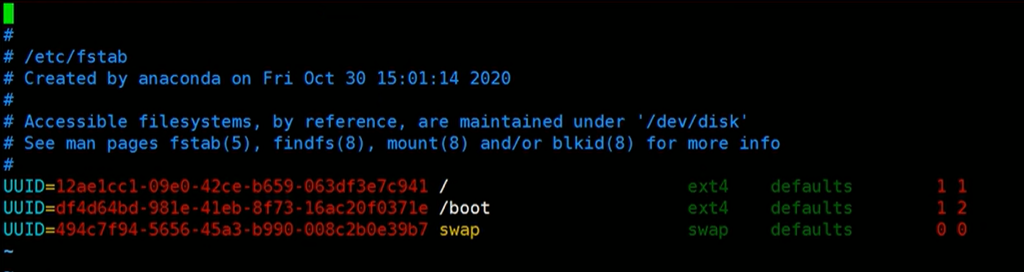
可用分区 UUID 或路径进行挂载。
示例:
将 /dev/sdb1 挂在 /newdisk/ 之下。
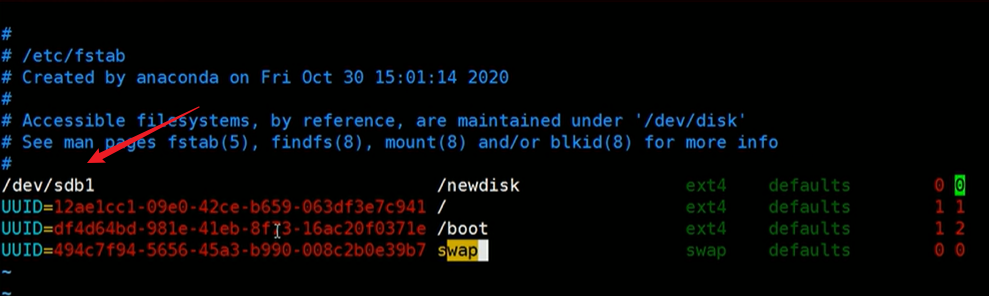
2.5:挂载案例
这里以增加一块硬盘为例(虚拟机进行),进行磁盘分区、挂载、卸载。
总体步骤:
- 添加硬盘。
- 给硬盘分区。
- 格式化。
- 挂载。
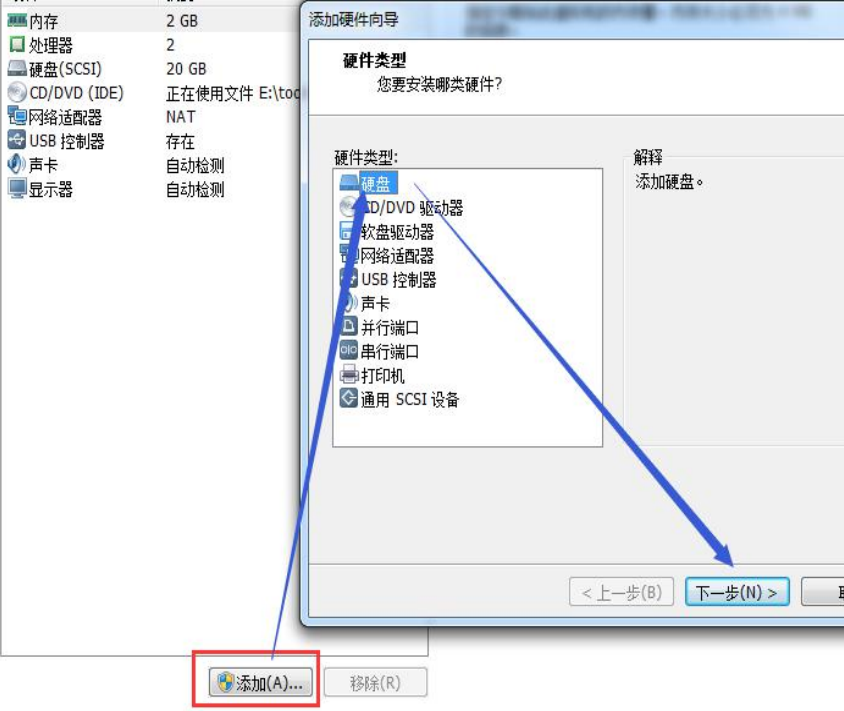
2.5.1:虚拟机添加硬盘
在设备列表里添加硬盘,然后只需一直【下一步】,只有选择磁盘大小的地方需要修改,直到完成。然后重启系统才能识别。
可以看到硬盘为 sdb。还没有分区。
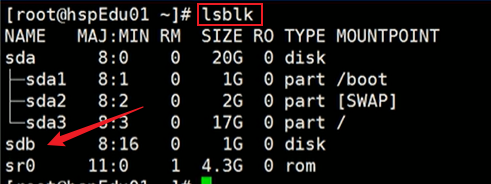
2.5.2:硬盘分区
给添加的硬盘分区。这里为了方便,只分一个区。
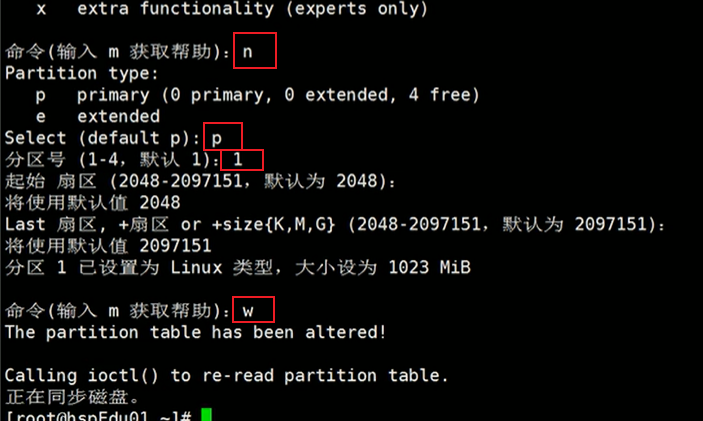
fdisk /dev/sdb

输入 n,新增分区;然后输入 p(分区类型为主分区);两次回车默认分配剩余全部空间。最后输入 w ,写入分区并退出。分区完成。
可以看到有了一个分区。
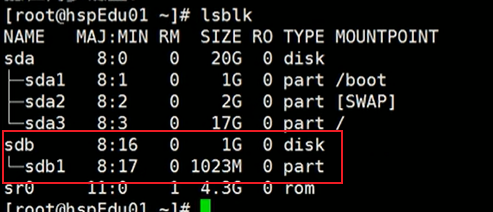
2.5.3:格式化
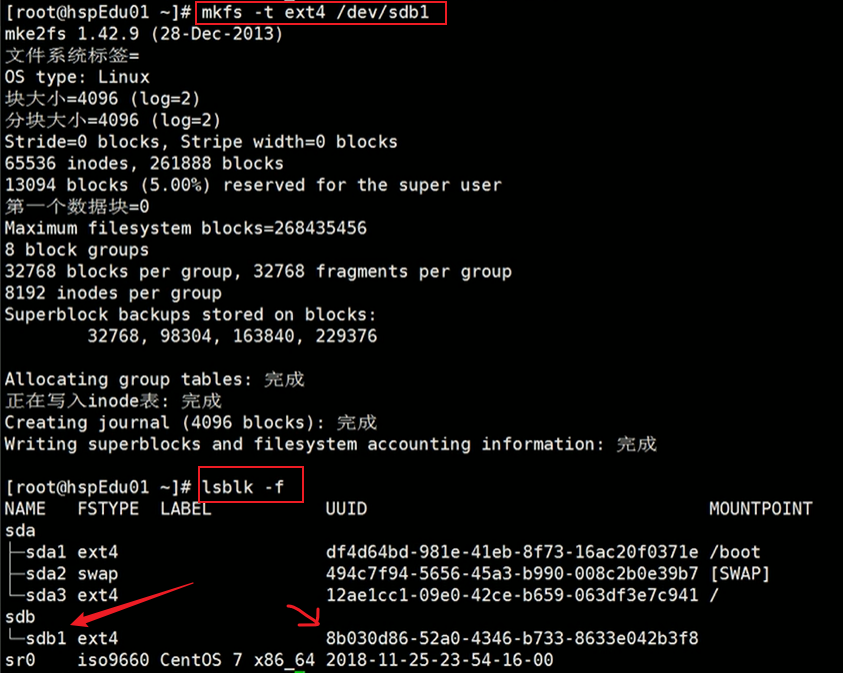
新增分区需格式化后才能分配 UUID。
mkfs -t ext4 /dev/sdb1
格式化后分配了 UUID。
2.5.4:挂载
将 /dev/sdb1 挂在 /newdisk/ 之下。/newdisk/ 即为挂载点,挂载点可随意更改。
mount /dev/sdb1 /newdisk
如需永久挂载,只需在 /etc/fstab 中配置。
3:网络配置
3.1:相关指令
3.1.1:ifconfig
功能描述:用于显示或设置网络配置。
基本语法:
ifconfig
ifconfig 指令也可搭配相关选项参数来进行网络配置设置。
3.1.2:ping
功能描述:用于检测主机,测试是否可以连接目的主机。
基本语法:
ping [选项] 目的主机
“ 目的主机 ” 可以是 ip 地址,可以是域名,也可以是主机名。
常用选项:
| 参数 | 说明 |
|---|---|
| -c 数字 | 设置收到指定次数包后,自动停止 |
| -i 数字 | 指定收发信息的间隔时间,单位为秒。 |
| -s 数字 | 设置发送包的大小。 |
| -t | 设置存活数值 TTL 的大小。 |
3.1.3:netstat
功能描述:用于查看网络状态。
基本语法:
netstat [选项]
常用选项:
| 参数 | 说明 |
|---|---|
| -a 或 --all | 显示所有连接和监听端口。 |
| -n | 以数字形式显示地址和端口号。 |
| -p | 显示建立相关连接的程序名。 |
| -t | 仅显示 tcp 相关。 |
| -u | 仅显示 udp 相关。 |
3.1.4:其他指令
重启网络服务:
service network restart
查看主机名:
hostname
3.2:网络环境配置
3.2.1:指定静态 ip
Linux 启动后会通过 DHCP 自动获取 IP 地址。如果需要指定固定的 ip 地址,需要在 /etc/sysconfig/network-scripts/ifcfg-ens33 文件中配置。
ifcfg-ens33文件参数:
| 参数 | 说明 |
|---|---|
| TYPE | 网卡类型(通常是 Ethemet 以太网) |
| PROXY_METHOD | 代理方式 |
| BROWSER_ONLY | 只是浏览器 |
| BOOTPROTO | 网卡的引导协议(static:静态IP。dhcp:动态IP。bootp:BOOTP 协议。none:不指定) |
| DEFROUTE | 默认路由 |
| IPV4_FAILURE_FATAL | 是否开启 IPv4 致命错误检测 |
| IPV6INIT | IPV6是否自动初始化 |
| IPV6_AUTOCONF | IPv6 是否自动配置 |
| IPV6_DEFROUTE | IPv6 是否可以为默认路由 |
| IPV6_FAILURE_FATAL | 是否开启 IPv6 致命错误检测 |
| IPV6_ADDR_GEN_MODE | IPv6 地址生成模型 |
| NAME | 网卡物理设备名称 |
| UUID | 通用唯一识别码 |
| DEVICE | 网卡设备名称,必须和 “ NAME ” 值一样 |
| ONBOOT | 是否开机启动 |
| IPADDR | 本机IP,通常与静态 ip 配合使用。 |
| NETMASK | 子网掩码,通常与静态 ip 配合使用。 |
| GATEWAY | 默认网关,通常与静态 ip 配合使用。 |
| DNS1 | 域名解析器,通常与静态 ip 配合使用。 |
设置静态 ip,一般情况只需更改 BOOTPROTO、IPADDR、GATEWAY、DNS1。如果没有参数自己添加即可。
然后重启网络服务或者重启系统即可生效。
示例(ip 部分改为自己的相应设置):
BOOTPROTO="static"
IPADDR=192.168.200.130
GATEWAY=192.168.200.2
DNS1=192.168.200.2
3.2.2:设置主机名
为了方便记忆,可以给 Linux 主机设置主机名,也可以根据需要修改主机名。
只需编辑 /etc/hostname 配置文件即可。重启后生效。
3.2.3:设置 hosts 映射
为了能够通过主机名找到某个 linux 主机(比如 ping),需要设置 hosts 映射。
只需配置 /etc/hosts 文件:
# 在文件中添加:
ip 主机名
示例:
192.168.200.1 myThinkPad
对于 Windows 系统,hosts 映射在 C:\Windows\System32\drivers\etc\hosts 文件配置。
3.3:防火墙
在真实生产环境,需要将防火墙打开,并打开指定的端口。
关闭防火墙:
systemctl stop firewalld
开启防火墙:
systemctl start firewalld
重载防火墙:
firewall-cmd --reload
查询端口是否开放:
firewall-cmd --query-port=端口/协议
打开端口:
firewall-cmd --permanent --add-port=端口号/协议
关闭端口:
firewall-cmd --permanent --remove-port=端口号/协议
不祈多积,多文以为富。
——《礼记 · 儒行》
《Linux基础》05. 定时任务调度 · 磁盘分区与挂载 · 网络配置的更多相关文章
- linux中利用fstab实现磁盘分区自动挂载
如何格式化磁盘.给磁盘分区以及挂载,参考我的另一篇博客: https://www.cnblogs.com/mediocreWorld/p/11123786.html 博客中有一个格式化分区的命令: m ...
- Linux基础(一)磁盘分区
磁盘分区 一.磁盘结构 先来看看老磁盘 1)磁头(head):不解释 2)扇区(sector):磁盘的最小存储单位,大小为512bytes或者4k 3)磁道(trcack):扇区组成的一个圆 4)柱面 ...
- Linux 实用指令(7)--Linux 磁盘分区、挂载
目录 Linux 磁盘分区.挂载 1 分区基础知识 1.1 分区的方式: 1.2 windows 下的磁盘分区 2 Linux分区 2.1 原理分析 2.2 磁盘说明 2.3 使用lsblk指令查看当 ...
- linux学习之路第九天(磁盘分区,挂载详解)
磁盘分区,挂载 -----分区基础知识 分区的方式 1)mbr分区: 1.最多支持四个主分区 2.系统只能安装在主分区 3.扩展分区要占一个主分区 4.mbr最大只支持2TB,但拥有最好的兼容性 -- ...
- Linux磁盘分区和挂载
Linux磁盘分区和挂载 分区 分区的方式: mbr分区 最多支持4个主分区 系统只能安装到主分区上 扩展分区要占用一个主分区 MBR最大支持2TB,但拥有最好的兼容性 gtp分区 支持无线多个主分区 ...
- Linux下磁盘分区、挂载、卸载操作记录
Linux下磁盘分区.挂载.卸载操作记录. 操作环境:CentOS release 6.5 (Final) Last :: from 118.230.194.76 [root@CentOS ~]# [ ...
- linux磁盘分区、挂载、查看
实战: 34 查看本机所有磁盘 fdisk -l 35 查看磁盘挂载情况 lsblk -f 36 39: ...
- Linux磁盘分区、挂载、查看文件大小
快速查看系统文件大小命令 du -ah --max-depth=1 后面可以添加文件目录 ,如果不添加默认当前目录. 下面进入正题~~ 磁盘分区.挂载 引言: ①.分区的方式 a)mbr分区: 最多支 ...
- 初始化Linux数据盘、磁盘分区、挂载磁盘(fdisk)
1.操作场景 2.前提条件 3.划分分区并挂载磁盘 4.设置开机自动挂载磁盘分区 1.操作场景 本文以云服务器的操作系统为"CentOS 7.4 64位"为例,采用fdisk分区工 ...
- Linux 磁盘分区和挂载
目录 Linux 磁盘分区和挂载 windows 下的分区 磁盘管理 相关命令 分区及挂载实现步骤 添加硬盘 分区步骤 步骤 挂载步骤 卸载分区步骤 补充: Linux 磁盘分区和挂载 windows ...
随机推荐
- 简要介绍django框架
Django是一个高级的Python Web框架,它鼓励快速开发和干净.实用的设计. Django遵循MVC(模型-视图-控制器)设计模式,使得开发者能够更轻松地组织代码和实现功能.以下是Django ...
- T-SQL——批量刷新视图
目录 0. 背景说明 1. 查询出所有使用了指定表的视图并生成刷新语句 2. 创建存储过程批量刷新 3. 刷新全部的视图 4. 参考 shanzm--2023年5月16日 0. 背景说明 为什么要刷新 ...
- Cobalt Strike 连接启动教程,制作图片🐎(2)
扫描有两种方式:arp 和 icmp 查看进程列表 攻击----生成后门-----Payload 可以生成各类语言免杀牧马---(输出:选择C或者python或者php) go.咕.com 生成c语言 ...
- 驱动开发:内核RIP劫持实现DLL注入
本章将探索内核级DLL模块注入实现原理,DLL模块注入在应用层中通常会使用CreateRemoteThread直接开启远程线程执行即可,驱动级别的注入有多种实现原理,而其中最简单的一种实现方式则是通过 ...
- Kubernetes——构建平台工程的利器
作者|Loft Team 翻译|Seal软件 链接|https://loft.sh/blog/why-platform-engineering-teams-should-standardize-on- ...
- 鸟类识别系统Python+Django+TensorFlow+卷积神经网络算法【完整代码】
一.介绍 鸟类识别系统,使用Python作为主要开发语言,基于深度学习TensorFlow框架,搭建卷积神经网络算法.并通过对数据集进行训练,最后得到一个识别精度较高的模型.并基于Django框架,开 ...
- LLE算法在自然语言处理中的应用:从文本到实体识别和关系抽取
目录 文章介绍: 自然语言处理(Natural Language Processing,NLP)是人工智能领域的重要分支,它研究如何将人类语言转化为计算机可理解的格式.NLP的应用非常广泛,从语言翻译 ...
- AI 和 DevOps:实现高效软件交付的完美组合
AI 时代,DevOps 与 AI 共价结合.AI 由业务需求驱动,提高软件质量,而 DevOps 则从整体提升系统功能.DevOps 团队可以使用 AI 来进行测试.开发.监控.增强和系统发布.AI ...
- C#.NET Framework 使用BC库(BouncyCastle) RSA 公钥加密 私钥解密 ver:20230706
C#.NET Framework 使用BC库(BouncyCastle) RSA 公钥加密 私钥解密 ver:20230706 环境说明: .NET Framework 4.6 的控制台程序 . 20 ...
- 使用C#编写.NET分析器(三)
译者注 这是在Datadog公司任职的Kevin Gosse大佬使用C#编写.NET分析器的系列文章之一,在国内只有很少很少的人了解和研究.NET分析器,它常被用于APM(应用性能诊断).IDE.诊断 ...