第3章 python 爬虫抓包与数据解析
第 3章 Python 爬虫抓包与数据解析
3.1 抓包进阶
目前,我们已经会使用 Chrome 浏览器自带的开发者工具来抓取访问网页的数据包,但是这种抓包方法有局限性,比如只能监听一个浏览器选项卡,如果想监听多个选项卡,必须打开多个页面。
另外,随着智能手机的普及,企业也不像以前一样必须开发一个 PC 端的网站,而是更倾向于制作自己的 App 或微信小程序等。另外比较重要的一点是,App 端的反爬虫没有Web 端那么强,所以移动端的抓包也是一门必备技能。
3.1.1 HTTPS 介绍
HTTP,它使用 TCP 进行数据传输,数据没有加密,直接明文传输,意味着可能会泄露传输内容,被中间人劫持,从而修改传输内容。最常见的是运营商劫持对网页内容进行修改并添加广告。HTTPS 的出现旨在解决这些风险因素:保证信息加密传输,避免被第三方窃取;为信息添加校验机制,避免被第三方破坏;配置身份证书,防止第三方伪装参与通信。
HTTPS(Hyper Text Transfer Protocol over Secure Socket Laye,安全超文本传输协议),
HTTP 是应用层协议,TCP 是传输层协议,HTTPS 是在这两层之间添加一个安全套接层SSL/TLS。HTTPS 可以理解成 HTTP 的安全版。在介绍 HTTPS 的工作流程之前,先要了解一些名词。
- 对称加密:加密用的密钥和解密用的密钥是一样的。
- 非对称加密:加密用的密钥(公钥)和解密用的密钥(私钥)是不一样的,公钥
- 加密过的数据只能通过私钥解开,私钥加密过的数据只能通过公钥解开。
- 公钥:公开的密钥,所有人都能查到。
- 私钥:非公开的密钥,一般由网站的管理员持有。
- 证书:网站的身份证,包含了很多信息,包括公钥。
- CA(证书颁发机构):颁布证书的机构,可以颁发证书的 CA 很多,只有少数被认为是权威的 CA,浏览器才会信任。比如 12306 网站的 CA 证书,就是由中国铁道部自行签发的,而这个证书是不被 CA 机构信任的,在浏览器的左上角有一个感叹号,单击会弹出如图 3.1 所示的警告信息。所以,在12306 网站的首页有提示,安装完根证书后就不会有这样的提示了。

另外,免费的 SSL 证书比较少,一般是收费的且功能越强大的证书费用越高。
3.1.2 HTTPS 的工作流程
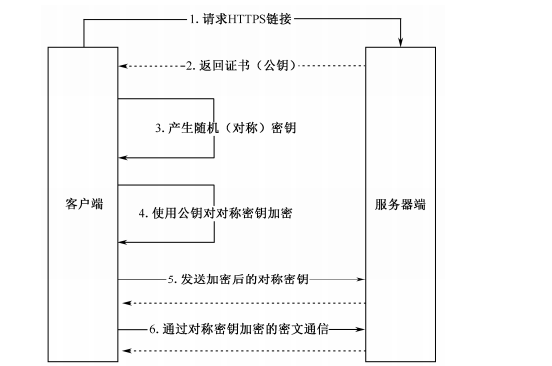
流程详解如下:
(1)客户端使用 HTTPS 的 URL 访问服务器端,要求与服务器端建立 SSL 连接。
(2)服务器端接收到请求后,会给客户端传送一份网站的证书信息(证书中包含公钥)。
(3)客户端浏览器与服务器端开始协商 SSL 连接的安全等级,即信息加密的等级。
(4)客户端浏览器根据双方同意的安全等级,建立会话密钥,然后利用网站的公钥将会话密钥加密,并传送给服务器端。
(5)服务器端利用自己的私钥解密出会话密钥。
(6)服务器端利用会话密钥加密与客户端之间的通信。
最后还有一点要注意,并不是使用了 HTTPS 就绝对安全,它只是增加了中间人攻击的成本,但是它比没有任何加密的 HTTP 安全。另外,建议重要的数据要单独进行加密。
3.1.3 Charles 抓包
Charles 是一款常用的全平台抓包工具,其抓包原理是通过将软件本身设置为系统的网络代理服务器,从而让所有的网络请求都经过 Charles 代理。开发商可以利用 Charles 截取相关站点的网络数据包进行数据包分析。
Charles 是一款收费软件,有 30 天的免费试用体验,试用期过后,未付费还能继续使用,只是每次只能使用 30 分钟,然后需要重启软件。Charlse 的主要功能如下:
- 截取 HTTP 和 HTTPS 网络封包。
- 支持重发网络请求,用于请求调试。
- 支持修改网络请求参数。
- 支持网络请求的截获和动态修改。
- 支持模拟慢速网络。
3.1.4 Packet Capture 抓包
使用 Charles 抓包比较简单,但是有一个缺点是:它要求手机和电脑要在同一个局域网内,而且每次抓包都要先查看本机 IP,然后在手机上配置代理,如果手机处于移动数据环境,Charles 则显得有些无能为力了。
这时可以使用 App 流量抓包工具来帮忙抓包。 Packet Capture 可以捕获 Android 手机上的任何网络流量,其利用 Android 系统的 VPN Service 来完成网络请求的捕获,无须使用root,并可以通过中间人技术抓取 HTTPS 请求,使用非常简单。
3.2 Requests HTTP 请求库
Python 自带的 urllib 网络请求库基本可满足我们的需要,但是在实际开发过程中使用起来还是有些烦琐,表现在以下几个方面:
- 发送 GET 和 POST 请求。
- Cookie 处理。
- 设置代理。
urllib 默认不支持压缩,要返回压缩格式,必须在请求头里写明 accept- encoding,然后在获取返回数据时,它以响应头里是否有 accept-encoding 来判断是否需要解码。当然也可以对 urllib 进行一些常用的封装,以规避此类问题。而更多时候,我们会选择使用 Requests库来模拟请求。
3.2.1 Requests 库简介
Requests 库基于 urllib 库,是采用 Apache2 Licensed 开源协议的 HTTP 库,更加简单且功能强大。该库支持如下功能。
- International Domains and URLs:国际化域名和 URL。
- Keep-Alive & Connection Pooling:Keep-Alive & 连接池。
- Sessions with Cookie Persistence:带持久 Cookie 的会话。
- Browser-style SSL Verification:浏览器式的 SSL 认证。
- Basic/Digest Authentication:基本/摘要式的身份认证。
- Elegant Key/Value Cookies:简洁的 Key/Value Cookie。
- Automatic Decompression:自动解压。
- Automatic Content Decoding:自动内容解码。
- Unicode Response Bodies:Unicode 响应体。
- Multipart File Uploads:文件分块上传。
- HTTP(S) Proxy Support:HTTP(S)代理支持。
- Connection Timeouts:连接超时。
- Streaming Downloads:流下载。
- .netrc Support:支持.netrc。
- Chunked Requests:Chunked 请求。
直接通过 pip 安装库:
pip install requests
3.2.2 Requests HTTP 基本请求
Requests 支持各种请求方式:GET、POST、PUT、DELETE、HEAD、OPTION。使用代码示例如下:
r1 = requests.get("http://xxx", params={"x": 1, "y": 2})
r2 = requests.post("http://xxx", data={"x": 1, "y": 2})
r3 = requests.put("http://xxx")
r4 = requests.delete("http://xxx")
r5 = requests.head("http://xxx")
r6 = requests.options("http://xxx")
注意事项:
- URL 链接里有中文时会自动转码。
- 使用 post 时,如果传递的是一个 str 而不是一个 dict,则会直接发送出去(如 JSON
- 字符串)。
- 2.4.2 版新增:可以通过 json 参数传递 dict,会自动把 dict 转换为 JSON 字符串。
- post 可以通过 file 参数上传文件,如 post(url, files={'file': open('report.xls', 'rb')})。
3.2.3 Requests 请求常用设置
Requests 请求的相关设置如下:
设置请求头:headers={'xxx':'yyy'}
代理:proxies={'https':'xxx'}
超时(单位秒):timeout=15
3.2.4 Requests 处理返回结果
Requests 请求会返回一个 requests.models.Response 对象,可以通过调用字段获取响应信息。
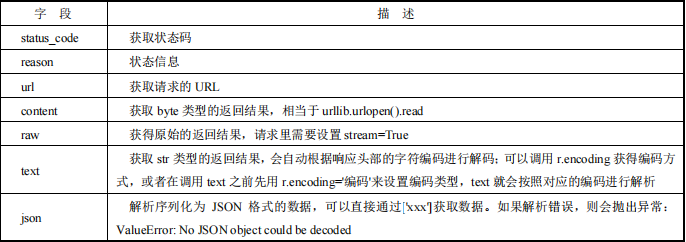
除此之外,还可以使用 headers 获得响应头,代码示例如下:
r = requests.get('http://gank.io/api/data/Android/50/1')
# 直接根据键获得值
print(r.headers.get('Date'))
# 遍历获得请求头里所有键值
for key, value in r.headers.items():
print(key + " : " + value)
如 果 想 获 取 请 求 头 信 息 , 可 以 调 用 r.request.headers 。 除 此 之 外 , 还 可 调 用raise_for_status(),当响应码不是 200 时,会抛出 HTTPError 异常,可用于响应码校验。另外,由 Requests 发起的请求,当相应内容经过 gzip 或 deflate 压缩时,Requests 会自动解包,可以通过 content 获得 byte 方式的响应结果。
3.2.5 Requests 处理 Cookie
通过r.cookies即可获得RequestsCookieJar对象,其行为与字典类似;如果想带着Cookies
去访问,可以在请求里添加 cookies={'xxx':'yyy'}参数;也可以通过 requests.cookies.RequestsCookieJar()调用 set 方法进行构造,比如:
jar.set('gross_cookie', 'blech', domain='httpbin.org', path='/elsewhere')
# 遍历cookies:
for c in r.cookies:
print(c.name + ":" + c.value)
CookieJar 与字典间互转的代码示例如下:
# 字典 -> CookieJar
cookies = requests.utils.cookiejar_from_dict(cookie_dict, cookiejar=None, overwrite=True)
# CookieJar-> 字典
cookies = requests.utils.dict_from_cookiejar(r.cookies)
3.2.6 Requests 重定向与请求历史
除了 HEAD 请求,Requests 会自动处理所有重定向,可以在执行请求时使用allow_redirects=False 禁止重定向,也可以使用响应对象的 history 属性来追踪请求历史。该
属性是一个 Response 对象的列表,该对象列表按照请求时间的先后顺序进行排序。
3.2.7 Requests 错误与异常处理
使用 Requests 的常见异常如下:
- 遇到网络问题,会抛出 requests.ConnectionError 异常。
- 请求超时,会抛出 requests.Timeout 异常。
- 请求超过了设定的最大重定向次数,会抛出 requests.TooManyRedirects 异常。
- HTTP 错误,会抛出 requests.HTTPError 异常。
- URL 缺失,会抛出 requests.URLRequired 异常。
- 连接远程服务器超时,会抛出 requests.ConnectTimeout 异常。
另外,Requests 显式抛出的异常都继承自 requests.exceptions.RequestException。
3.2.8 Requests Session 会话对象
用于跨请求保持一些参数,最常见的就是保留 Cookies,Session 对象还提供了 Cookies持久化和连接池功能。Session 使用代码示例如下:
s = request.Session() # 建立会话
s.post('http://xxx.login',data={'xx':'xx'}) # 登录信息
s.get('http://xxx.user') # 登录
s.close() # 关闭会话
3.2.9 Requests SSL 证书验证
现在大部分站点都采用 HTTPS,不可避免会涉及证书问题。如果遇到 12306 这种自发CA 证书的站点,会抛出requests.exception.SSLError 异常。可以添加参数 verify=False,但是设置后还是会有下面这样的提示:
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate
verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.
html#ssl-warnings InsecureRequestWarning)
此时还需要添加urllib3.disable_warnings(),也可以通过 cert 参数放入证书路径。代码示例如下:
import requests
# 忽略证书
from requests.packages import urllib3
urllib3.disable_warnings()
resp = requests.get("https://www.12306.cn",verify=False)
print(response.status_code)
# 设置本地证书
resp = requests.get('https://www.12306.cn', cert=('**.crt', '**.key'))
以上就是 Requests 库的常见用法,如果想了解更多内容,可以到官方文档中自行查阅,下面通过一个实战例子来帮大家巩固 Requests 库的使用。
3.3 实战:爬取微信文章中的图片、音频和
3.3.1 爬取标题
打开一篇微信文章,如 https://mp.weixin.qq.com/s/JHioeDcopm-98R5lGVemqw ,分析页面结构,首先我们要用一个文章标题作为文件夹的文件名。按 F12 键打开开发者工具,按Ctrl+F 组合键查找标题。
import requests
from lxml import etree
def get_article_title(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 '
'(KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
try:
with requests.Session() as session: # 使用Session来提高性能
response = session.get(url, headers=headers)
if response.status_code == 200:
html = etree.HTML(response.text)
title_elements = html.xpath('//*[@id="activity-name"]/text()')
if title_elements: # 检查是否有找到标题
return title_elements[0].strip() # 返回第一个标题,去除首尾空格
else:
return "Title not found."
else:
return f"Failed to retrieve the article, status code: {response.status_code}"
except requests.RequestException as e:
return f"Error occurred: {e}"
# 使用函数
url = 'https://mp.weixin.qq.com/s/JHioeDcopm-98R5lGVemqw'
article_title = get_article_title(url)
print(article_title)
代码执行结果如下:
致前任:愿我们各自安好,不再打扰
3.3.2 爬取图片
成功拿到标题后,接下来获取图片,找到网页中的一张图片。
import requests
url = 'https://mmbiz.qpic.cn/mmbiz_jpg/TsomEQAKP4ezzbMTkM3SuEKxRxq4X3JuUMVwRicd41fsc0HDSwMAEIfmHVqH9etROKkHjc2eHJcsGekuia8ic9Kdg/640?wx_fmt=jpeg&wxfrom=5&wx_lazy=1&wx_co=1'
try:
response = requests.get(url)
if response.status_code == 200:
with open('q.jpg', "wb") as f:
f.write(response.content)
print("Image downloaded successfully.")
else:
print(f"Failed to download the image, status code: {response.status_code}")
except requests.RequestException as e:
print(f"Error occurred during the request: {e}")
3.3.3 爬取音频
图片下载成功,接着就到音频了,这篇公众号文章中没有音频,我们换一篇文章,链
接为 https://mp.weixin.qq.com/s/JHioeDcopm-98R5lGVemqw ,我们定位页面元素对应的节点
import requests
url = 'https://res.wx.qq.com/voice/getvoice?mediaid=MzA4MzE0NjE3Ml8yNjU1NDgxOTU3'
try:
response = requests.get(url)
if response.status_code == 200:
with open('voice.mp3', "wb") as f:
f.write(response.content)
print("Audio file downloaded successfully.")
else:
print(f"Failed to download the audio file, status code: {response.status_code}")
except requests.RequestException as e:
print(f"Error occurred during the request: {e}")
3.4 Beautiful Soup 解析库
前面我们解析网络都是通过lxml 库来完成的,下面来学习功能强大的解析库——Beautiful Soup。
3.4.1 Beautiful Soup 简介
Beautiful Soup 是一个用于解析 HTML 和 XML 结构文档的功能强大的 Python 库。
通过 pip 安装即可:
pip install beautifulsoup4
3.4.2 Beautiful Soup 对象实例化
Beautiful Soup 的使用非常简单,直接把 HTML 作为 Beautiful Soup 对象的参数,可以是请求后的网站,也可以是本地的 HTML 文件,第二个参数是指定解析器,可供选择的解
析器。
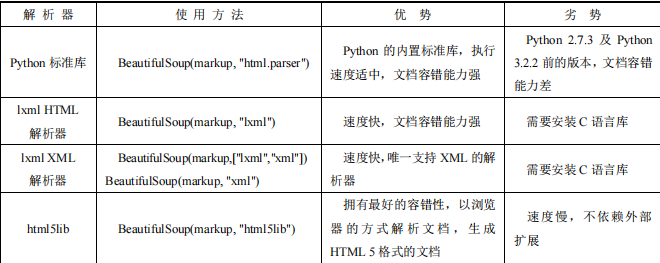
实例化代码示例如下(还可以调用prettify()方法格式化输出 HTML):
# 网站
soup = BeautifulSoup(resp.read(), 'html.parser')
# 本地
soup = BeautifulSoup(open('index.html'),'lxml')
3.4.3 Beautiful Soup 的四大对象
- Tag(标签)
如果查找的标签是在所有内容中第一个符合要求的标签,比较常用的两个属性如下。
- tag.name:获得标签的名称。
- tag.attrs:获取标签内的所有属性,返回一个字典,可以根据键取值,也可以直接调用 get('xxx')获到属性。还有一个方法是根据标签层级的形式查找到标签,如soup.body.div.div.a 就是绝对定位,实用性不高。
- NavigableString(内部文字)
如果想获取标签的内部文字,可直接调用.string。 - BeautifulSoup(文档的全部内容)
可以把它当作一个 Tag 对象,只是可以分别获取它的类型、名称,具有一级属性。 - Comment(特殊的 NavigableString)
这种对象调用.string 来输出内容,会把注释符号去掉,直接把注释里的内容打印出来,需要加以判断,示例如下:
if type(soup.a.string)==bs4.element.Comment:
print soup.a.string
3.4.4 Beautiful Soup 的各种节点
当目标节点不好定位时,我们可以找到目标节点附近的节点,然后顺藤摸瓜找到目标节点。可以通过下述字段获取附近节点。
- 子节点与子孙节点
- contents:把标签下的所有子标签存入列表,返回列表。
- children:和 contents 一样,但是返回的不是一个列表,而是一个迭代器,只能通过循环的方式获取信息,类型是list_iterator,仅包含 tag 的直接子节点,如果想找出子孙节点,可以使用 descendants,会把所有节点都剥离出来,生成一个生成器对象<class 'generator'>。
- 父节点与祖先节点
- parent:返回父节点 tag。
- parents:返回祖先节点,返回一个生成器对象。
- 兄弟节点
兄弟节点是处于同一层级的节点,节点不存在则返回 None。
- next_sibling:下一个兄弟节点。
- previous_sibling:上一个兄弟节点。
所有兄弟节点 next_siblings 和 previous_sibling,返回一个生成器对象。
- 前后节点
- next_element:下一个节点。
- previous_element:上一个节点。
所有前后节点 next_elements 和 previous_elements,返回一个生成器对象。
3.4.5 Beautiful Soup 文档树搜索
最常用的当属 find_all 方法,方法定义如下:
find_all (self, name=None, attrs={}, recursive=True, text=None, limit=None, kwargs)
- name:通过 HTML 标签名直接搜索,会自动忽略字符串对象,参数可以是字符串、
- 正则表达式、列表、True 或自定义方法。
- keyword:通过 HTML 标签的 id、href(a 标签)和 title(class 要写成 class_),可以同时过滤多个,对于不能用的 tag 属性,可以直接使用一个 attrs 字典,如 find_all(attrs={'data-foo': 'value'}。
- text:搜索文档中的字符串内容。
- limit:限制返回的结果数量。
- recursive:是否递归检索所有子孙节点。
- find(self, name=None, attrs={}, recursive=True, text=None, kwargs):和 find_all 作用一样,只是返回的不是列表,而是直接返回结果。
- find_parents()和 find_parent():find_all() 和 find() 只搜索当前节点的所有子节点、子孙节点等。find_parents() 和 find_parent()用来搜索当前节点的父辈节点,搜索方法与普通 tag 的搜索方法相同,搜索文档包含的内容。
- find_next_sibling()和 find_next_siblings():这两个方法通过 next_siblings 属性对当前 tag 的所有后面解析的兄弟 tag 节点进行迭代,find_next_siblings()方法返回所有符合条件的后面的兄弟节点,find_next_sibling()只返回符合条件的后面的第一个 tag 节点。
- find_previous_siblings() 和 find_previous_sibling(): 这 两 个 方 法 通 过 previous_siblings 属性对当前 tag 的前面解析的兄弟 tag 节点进行迭代,find_previous_
- siblings()方法返回所有符合条件的前面的兄弟节点,find_previous_sibling()方法返回第一个符合条件的前面的兄弟节点。
- find_all_next()和 find_next():这两个方法通过 next_elements 属性对当前 tag 之后的tag和字符串进行迭代,find_all_next() 方法返回所有符合条件的节点,find_next() 方法返回第一个符合条件的节点。
- find_all_previous()和 find_previous():这两个方法通过 previous_elements 属性对当前节点前面的 tag 和字符串进行迭代,find_all_previous()方法返回所有符合条件的节点,find_previous()方法返回第一个符合条件的节点。
3.4.6 Beautiful Soup 使用 CSS 选择器
Beautiful Soup 支持大部分 CSS 选择器,Beautiful Soup 对象调用 select()方法传入字符串参数,即可使用 CSS 选择器的语法来找到对应的 tag。
下面我们通过一个实战案例来熟悉 Beautiful Soup 的使用方法。
3.5 实战:爬取壁纸站点的壁纸
先打开想爬取的壁纸站点:https://www.dpm.org.cn/Home.html
爬取第一张图片
import requests
from bs4 import BeautifulSoup
url = "https://www.dpm.org.cn/lights/royal/p/1.html"
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pic=soup.find("div", class_="pic")
x=pic.find("img")
img_url=x.attrs["src"]
imgmz=x.attrs["title"].strip()
content =requests.get(img_url).content
with open(f'{imgmz}.png', 'wb') as f:
f.write(content)
爬取整页的图片
import requests
from bs4 import BeautifulSoup
url = f"https://www.dpm.org.cn/lights/royal/p/{page}.html"
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pics=soup.findAll("div", class_="pic")
for pic in pics:
x=pic.find("img")
img_url=x.attrs["src"]
imgmz=x.attrs["title"].strip()
content =requests.get(img_url).content
with open(f'./pic_set/{imgmz}.png', 'wb') as f:
f.write(content)
爬取前四页
import requests
from bs4 import BeautifulSoup
for page in range(1,5):
url = f"https://www.dpm.org.cn/lights/royal/p/{page}.html"
r=requests.get(url)
r.encoding = 'utf-8'
soup=BeautifulSoup(r.text,"html.parser")
pics=soup.findAll("div", class_="pic")
for pic in pics:
x=pic.find("img")
img_url=x.attrs["src"]
imgmz=x.attrs["title"].strip()
content =requests.get(img_url).content
with open(f'./pic_set/{imgmz}.png', 'wb') as f:
f.write(content)
所有图片都下载到对应的文件夹中了。
3.6 正则表达式
学过编程的或多或少都听说过正则表达式,但是大部分人都对此非常畏惧,而且觉得使用时到网上搜索就行了,不用浪费时间自己编写。但是有个问题是你去爬取别人的数据时,不一定有满足需求的正则表达式,大多数情况下要自己动手编写。
其实正则表达式并没有想象中的那么难,主要是练得不够多。除了了解字符串相关的处理函数外,掌握正则表达式也非常必要。本节我们来学习正则表达式在 Python 中的应用。
3.6.1 re 模块
Python 中通过 re 模块使用正则表达式,该模块提供的几个常用方法如下。
- 匹配
- re.match(pattern, string, flags=0)
参数:匹配的正则表达式,要匹配的字符串,标志位(匹配方法)尝试从字符串的开头进行匹配,匹配成功会返回一个匹配的对象,类型是<class '_sre.SRE_Match'>。 - re.search(pattern, string, flags=0)
参数:同 match 函数,扫描整个字符串,返回第一个匹配的对象,否则返回 None。
注意:match 方法和 search 方法的最大区别是,match 如果开头就不和正则表达式匹配,则直接返回 None,而 search 则是匹配整个字符串。
- 检索与替换
- re.findall(pattern, string, flags=0)
参数:同 match 函数,遍历字符串,找到正则表达式匹配的所有位置,并以列表的形式返回。 - re.finditer(pattern, string, flags=0)
参数:同 match 函数,遍历字符串,找到正则表达式匹配的所有位置,并以迭代器的形式返回。 - re.sub(pattern, repl, string, count=0, flags=0)
参数:repl 为替换的字符串,可以是函数,把匹配到的结果进行一些转换;count 为替换的最大次数,默认值 0 代表替换所有的匹配。找到所有匹配的子字符串,并替换为新的内容。 - re.split(pattern, string, maxsplit=0, flags=0)
参数:maxsplit 设置分割的数量,默认值 0,对所有满足匹配的字符串进行分割,并返回一个列表。
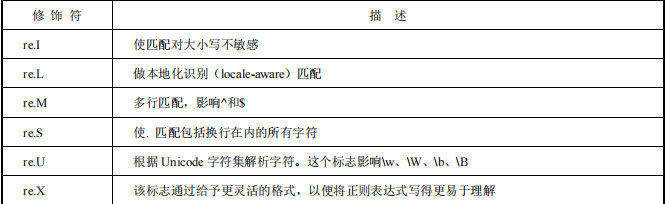
- 编译成 Pattern 对象
对于会多次用到的正则表达式,我们可以调用 re 的 compile()方法编译成 Pattern 对象,调用的时候直接使用 Pattern 对象.xxx 即可,从而提高运行效率。flags(可选标志位)。另外,多个标志可通过按位 OR(|)进行连接,如 re.I|re.M。
3.6.2 正则规则详解
加在正则字符串前的'r
为了告诉编译器这个 string 是一个 raw string(原字符串),不要转义反斜杠,比如在 raw string 里\n 是两个字符——''和'n',不是换行。字符
正则表达式中的字符规则:

数量
正则表达式中的数量规则:
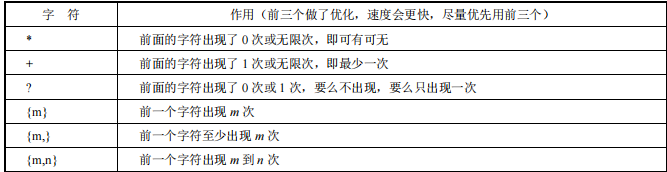
边界
正则表达式中的边界规则:

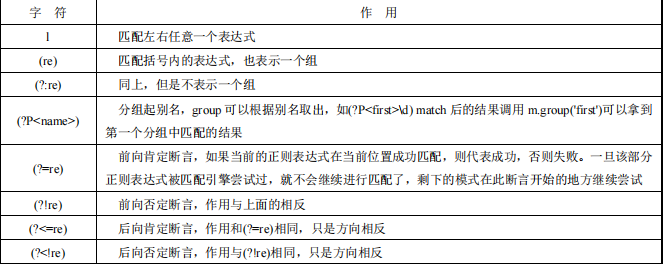
分组
用()表示的就是要提取的分组,一般用于提取子串,如^(\d{3})-(\d{3,8})$,从匹配的字符串中提取出区号和本地号码,具体规则:
group()方法与其他方法详解
如果将整个表达式作为一个组,可以使用group(0)或 group();如果作为多个分组,可以传入对应组的序号,获取对应匹配的子串,代码示例如下,如下面的例子:
import re
ret = re.match(r'^(\d{4})-(\d{3,8})$','0756-3890993')
print(ret.group())
print(ret.group(0))
print(ret.group(1))
print(ret.group(2))
代码执行结果如下:
0756-3890993
0756-3890993
0756
3890993
除group()方法外,还有以下四个常用的方法。
- groups():从 group(1)开始往后的所有的值,返回一个元组。
- start():返回匹配的开始位置。
- end():返回匹配的结束位置。
- span():返回一个元组,表示匹配位置(开始,结束)。
- 贪婪与非贪婪
正则匹配默认是贪婪匹配,也就是匹配尽可能多的字符。比如:ret = re.match(r'^(\d+)(0*)\(','12345000').groups(),原意是想得到('12345','000')这样的结果,但是输出的却是('12345000','')。由于贪婪,直接把后面的0全给匹配了,结果 0*只能匹配空字符串。如果想尽可能少地匹配,可以在\d+后加上一个?,采用非贪婪匹配,改成 r'^(\d+?)(0)\)',输出结果就变成了('12345','000')。
3.6.3 正则练习
- 例子:简单验证手机号码格式
import re
def validate_phone_number(phone_number):
# 定义手机号码的正则表达式
pattern = r'^1[3-9]\d{9}$'
# 使用re.match来检查手机号码是否匹配给定的正则表达式
if re.match(pattern, phone_number):
return True
else:
return False
# 测试手机号码
phone_numbers = ['13812345678', '11234567890', '19876543210']
for number in phone_numbers:
print(f"Phone Number: {number}, Valid: {validate_phone_number(number)}")
结果如下:
Phone Number: 13812345678, Valid: True
Phone Number: 11234567890, Valid: False
Phone Number: 19876543210, Valid: True
- 例子:验证身份证(二代)
import re
from datetime import datetime
def validate_id_card_18(id_card):
# 正则表达式验证基本格式
pattern = r'^\d{6}(\d{4})(\d{2})(\d{2})\d{3}[0-9Xx]$'
match = re.match(pattern, id_card)
if not match:
return False
# 验证出生日期合法性
year, month, day = int(match.group(1)), int(match.group(2)), int(match.group(3))
try:
datetime(year, month, day)
except ValueError:
return False
# 计算校验码
coefficients = (7, 9, 10, 5, 8, 4, 2, 1, 6, 3, 7, 9, 10, 5, 8, 4, 2) # 加权因子
checksums = '10X98765432' # 校验码对应值
sum = 0
for i in range(17):
sum += int(id_card[i]) * coefficients[i]
index = sum % 11
check_code = checksums[index]
# 验证校验码
return id_card[-1].upper() == check_code
# 测试用例
id_cards = ['11010519900307857X', '440308199901101512', '130681199302312119']
for id_card in id_cards:
print(f"ID Card: {id_card}, Valid: {validate_id_card_18(id_card)}")
结果如下:
ID Card: 11010519900307857X, Valid: True
ID Card: 440308199901101512, Valid: True
ID Card: 130681199302312119, Valid: False
- 例子:验证 IP 是否正确
验证IPv4地址:IPv4地址由四组数字组成,每组数字范围从0到255,各组之间用点(.)分隔。
import re
def validate_ipv4(ip):
pattern = r'^((25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)$'
return re.match(pattern, ip) is not None
# 测试用例
ips = ['192.168.1.1', '255.255.255.255', '256.100.100.100', '192.168.1']
for ip in ips:
print(f"IP: {ip}, Valid: {validate_ipv4(ip)}")
结果如下:
IP: 192.168.1.1, Valid: True
IP: 255.255.255.255, Valid: True
IP: 256.100.100.100, Valid: False
IP: 192.168.1, Valid: False
验证IPv6地址:IPv6地址由八组四位十六进制数表示,各组之间用冒号(:)分隔。为了简化表示,IPv6地址允许省略前导零,并且可以使用双冒号(::)表示一连串的零。
import re
def validate_ipv6(ip):
pattern = r'^([\da-fA-F]{1,4}:){7}[\da-fA-F]{1,4}$|^::([\da-fA-F]{1,4}:){0,5}[\da-fA-F]{1,4}$|^([\da-fA-F]{1,4}:){1,6}:$|^([\da-fA-F]{1,4}:){0,6}[\da-fA-F]{1,4}$|^([\da-fA-F]{1,4}:){1,7}:$'
return re.match(pattern, ip) is not None
# 测试用例
ips = ['2001:0db8:85a3:0000:0000:8a2e:0370:7334', 'FE80::0202:B3FF:FE1E:8329', '2001:db8::1']
for ip in ips:
print(f"IP: {ip}, Valid: {validate_ipv6(ip)}")
结果如下:
IP: 2001:0db8:85a3:0000:0000:8a2e:0370:7334, Valid: True
IP: FE80::0202:B3FF:FE1E:8329, Valid: False
IP: 2001:db8::1, Valid: False
- 例子:验证各种杂项示例
匹配中文:
[\u4e00-\u9fa5]
匹配双字节字符:
[^\x00-\xff]
匹配数字并输出示例:
str_count = "您的网站被访问了10000次"
match = re.match(r"^您的网站被访问了(\d{1,6})次$", str_count)
print(match.group(1))
输出结果如下:
10000
匹配开头结尾示例:
content = ['喜欢Android', '喜欢Python', '喜欢你', '你不喜欢我', '哈哈']
pattern = re.compile(r'^.*喜欢.*$')
for i in content:
match = pattern.match(i)
if match:
print(match.group())
输出结果如下:
喜欢Android
喜欢Python
喜欢你
你不喜欢我
3.7 实战:爬取市级编码列表
市级编码的作用非常多,特别是查询天气时会用到,比如查询深圳的天气:http://www.weather.com.cn/weather1dn/101280601.shtml ,后面这个 101280601 就是深圳的市级编码。
3.7.1 获取所有市级的跳转链接列表
import requests as r
from bs4 import BeautifulSoup
base_url = 'http://www.weather.com.cn'
city_referer_url = 'http://www.weather.com.cn/textFC/hb.shtml'
# 获取所有的城市列表
def fetch_city_url_list():
city_url_list = []
resp = r.get(city_referer_url)
resp.encoding = 'utf-8'
bs = BeautifulSoup(resp.text, 'lxml')
content = bs.find('div', attrs={'class': 'lqcontentBoxheader'})
if content is not None:
a_s = content.find_all('a')
if a_s is not None:
for a in a_s:
city_url_list.append(base_url + a.get('href'))
return city_url_list
if __name__ == '__main__':
city_list = fetch_city_url_list()
for city in city_list:
print(city)
代码执行后部分输出结果如下:
http://www.weather.com.cn/textFC/beijing.shtml
http://www.weather.com.cn/textFC/guangzhou.shtml
http://www.weather.com.cn/textFC/chongqing.shtml
3.7.2 解析表格获得所有市级天气链接
接下来编写代码来提取市级天气跳转链接,代码如下:
import requests as r
from bs4 import BeautifulSoup
base_url = 'http://www.weather.com.cn'
city_referer_url = 'http://www.weather.com.cn/textFC/hb.shtml'
# 获取所有的城市列表
def fetch_city_url_list():
city_url_list = []
resp = r.get(city_referer_url)
resp.encoding = 'utf-8'
bs = BeautifulSoup(resp.text, 'lxml')
content = bs.find('div', attrs={'class': 'lqcontentBoxheader'})
if content is not None:
a_s = content.find_all('a')
if a_s is not None:
for a in a_s:
city_url_list.append(base_url + a.get('href'))
return city_url_list
# 获取市级天气跳转链接列表
def fetch_city_weather_url_list(url):
resp = r.get(url)
resp.encoding = 'utf-8'
bs = BeautifulSoup(resp.text, 'lxml')
a_s = bs.select('div.conMidtab a')
for a in a_s:
if a.get("href") is not None and a.text != '详情' and a.text != '返回顶部':
print(a.text + "-" + a.get("href"))
if __name__ == '__main__': fetch_city_weather_url_list('http://www.weather.com.cn/textFC/guangdong.shtml')
代码执行后部分输出结果如下:
广州-http://www.weather.com.cn/weather/101280101.shtml
深圳-http://www.weather.com.cn/weather/101280601.shtml
重庆-http://www.weather.com.cn/weather/101040100.shtml
3.7.3 提取市级编码
以获取一个市级链接为例子,如 http://www.weather.com.cn/weather/101280101.shtml ,我们编写一个提取的正则表达式^.?weather/(.?).shtml$,用简单的代码进行测试:
code_regex = re.compile('^.*?weather/(.*?).shtml$', re.S)
result = code_regex.match('http://www.weather.com.cn/weather/101280101.shtml')
print(result.group(1))
代码执行结果如下:
101280101
完整代码:
import requests as r
from bs4 import BeautifulSoup
import re
base_url = 'http://www.weather.com.cn'
city_referer_url = 'http://www.weather.com.cn/textFC/hb.shtml'
# 获取所有的城市列表
def fetch_city_url_list():
city_url_list = []
resp = r.get(city_referer_url)
resp.encoding = 'utf-8'
bs = BeautifulSoup(resp.text, 'lxml')
content = bs.find('div', attrs={'class': 'lqcontentBoxheader'})
if content is not None:
a_s = content.find_all('a')
if a_s is not None:
for a in a_s:
city_url_list.append(base_url + a.get('href'))
return city_url_list
# 获取市级天气跳转链接列表
def fetch_city_weather_url_list(url):
city_code_list = []
resp = r.get(url)
resp.encoding = 'utf-8'
bs = BeautifulSoup(resp.text, 'lxml')
a_s = bs.select('div.conMidtab a')
for a in a_s:
if a.get("href") is not None and a.text != '详情' and a.text != '返回顶部':
city_name = a.text
city_weather_url = base_url + a.get("href")
print(f"{city_name}-{city_weather_url}")
city_code = extract_city_code(city_weather_url)
city_code_list.append((city_name, city_code))
return city_code_list
# 提取城市代码
def extract_city_code(url):
code_regex = re.compile('^.*?weather/(.*?).shtml$', re.S)
result = code_regex.match(url)
if result:
return result.group(1)
else:
return None
if __name__ == '__main__':
city_list = fetch_city_url_list()
# for city in city_list:
# print(city)
guangdong_weather_url = 'http://www.weather.com.cn/textFC/guangdong.shtml'
guangdong_city_codes = fetch_city_weather_url_list(guangdong_weather_url)
for city_code in guangdong_city_codes:
print(city_code)
输出结果如下:
广州-http://www.weather.com.cnhttp://www.weather.com.cn/weather/101280101.shtml
番禺-http://www.weather.com.cnhttp://www.weather.com.cn/weather/101280102.shtml
...
('广州', '101280101')
('番禺', '101280102')
...
使用此类脚本下载网站内容时应遵守网站的使用条款,以及相关的法律法规。
本系列文章皆做为学习使用,勿商用。
第3章 python 爬虫抓包与数据解析的更多相关文章
- Python爬虫的三种数据解析方式
数据解析方式 - 正则 - xpath - bs4 数据解析的原理: 标签的定位 提取标签中存储的文本数据或者标签属性中存储的数据 正则 # 正则表达式 单字符: . : 除换行以外所有字符 [] : ...
- Python爬虫抓取东方财富网股票数据并实现MySQL数据库存储
Python爬虫可以说是好玩又好用了.现想利用Python爬取网页股票数据保存到本地csv数据文件中,同时想把股票数据保存到MySQL数据库中.需求有了,剩下的就是实现了. 在开始之前,保证已经安装好 ...
- python爬虫抓网页的总结
python爬虫抓网页的总结 更多 python 爬虫 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自 ...
- python 爬虫抓取心得
quanwei9958 转自 python 爬虫抓取心得分享 urllib.quote('要编码的字符串') 如果你要在url请求里面放入中文,对相应的中文进行编码的话,可以用: urllib.quo ...
- 转载:用python爬虫抓站的一些技巧总结
原文链接:http://www.pythonclub.org/python-network-application/observer-spider 原文的名称虽然用了<用python爬虫抓站的一 ...
- 用python爬虫抓站的一些技巧总结 zz
用python爬虫抓站的一些技巧总结 zz 学用python也有3个多月了,用得最多的还是各类爬虫脚本:写过抓代理本机验证的脚本,写过在discuz论坛中自动登录自动发贴的脚本,写过自动收邮件的脚本, ...
- python爬虫抓站的一些技巧总结
使用python爬虫抓站的一些技巧总结:进阶篇 一.gzip/deflate支持现在的网页普遍支持gzip压缩,这往往可以解决大量传输时间,以VeryCD的主页为例,未压缩版本247K,压缩了以后45 ...
- Python爬虫----抓取豆瓣电影Top250
有了上次利用python爬虫抓取糗事百科的经验,这次自己动手写了个爬虫抓取豆瓣电影Top250的简要信息. 1.观察url 首先观察一下网址的结构 http://movie.douban.com/to ...
- Python爬虫丨大众点评数据爬虫教程(1)
大众点评数据获取 --- 基础版本 大众点评是一款非常受普罗大众喜爱的一个第三方的美食相关的点评网站. 因此,该网站的数据也就非常有价值.优惠,评价数量,好评度等数据也就非常受数据公司的欢迎. 今天就 ...
- java调用Linux执行Python爬虫,并将数据存储到elasticsearch--(环境脚本搭建)
java调用Linux执行Python爬虫,并将数据存储到elasticsearch中 一.以下博客代码使用的开发工具及环境如下: 1.idea: 2.jdk:1.8 3.elasticsearch: ...
随机推荐
- Debian打开架构支持
第一步检查内核有没有 AMD和i386 dpkg --list | grep linux-image 会出现现在电脑上的内核,可以看到支持的架构 dpkg --print-foreign-archi ...
- 已安装docker-compose,安装harbor时还是提示docker-compose未安装或者Permission denied的解决方案
安装Harbor时,下载安装了docker-compose并赋予权限 sudo curl -L "https://github.com/docker/compose/releases/dow ...
- 记本地新建一个gradle方式springboot项目过程
打算使用gradle在idea新建个springboot项目,然后坑很多,记录一下 原来我的idea应该是社区版,新建项目时候没有可以选择spring相关配置,然后卸载了重装,之前问题是启动是启动起来 ...
- 关于进程同步与互斥的一些概念(锁、cas、futex)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 环境说明 无 前言 最近为了实现在android lin ...
- 记一次 .NET某施工建模软件 卡死分析
一:背景 1. 讲故事 前几天有位朋友在微信上找到我,说他的软件卡死了,分析了下也不知道是咋回事,让我帮忙看一下,很多朋友都知道,我分析dump是免费的,当然也不是所有的dump我都能搞定,也只能尽自 ...
- 【LeetCode刷题】744. 寻找比目标字母大的最小字母
744. 寻找比目标字母大的最小字母(点击跳转LeetCode) 给你一个排序后的字符列表 letters ,列表中只包含小写英文字母.另给出一个目标字母 target,请你寻找在这一有序列表里比目标 ...
- Three.js中加载和渲染3D Tiles
1. 引言 3D Tiles 是 3D GIS 中常见的三维数据格式,能否用Three.js来加载渲染呢?肯定是可以,Three.js只是一个WebGL框架,渲染数据肯定可以,但是加载.解析数据得手动 ...
- 记录--前端实习生的这个 bug 被用做了一道基础面试题
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 前言 测试发现了一个问题,简单描述问题就是通过函数删除一个数组中多个元素,传入的参数是一个数组索引. 然后发现实际效果有时删除的不是想要的 ...
- Scala选择分支if else
1 package com.atguigu.chapter03 2 3 import scala.io.StdIn 4 5 /** 6 * Scala 中 if else 表达式其实是有返回值的,具体 ...
- sql语句TRUNCATE 清空表数据
清空表数据 TRUNCATE TABLE zzsfp_hwmx;