一文带你搞懂如何优化慢SQL
作者:京东科技 宋慧超
一、前言
最近通过SGM监控发现有两个SQL的执行时间占该任务总执行时间的90%,通过对该SQL进行分析和优化的过程中,又重新对SQL语句的执行顺序和SQL语句的执行计划进行了系统性的学习,整理的相关学习和总结如下;
二、SQL语句执行顺序
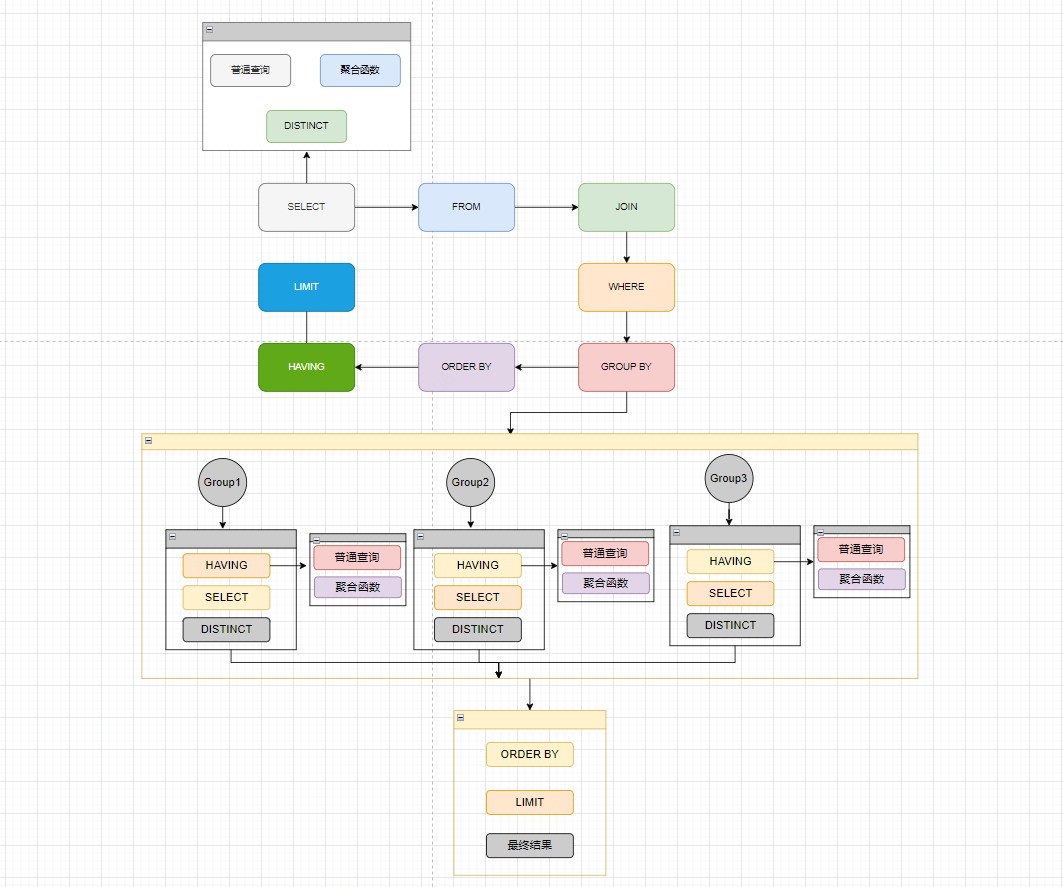
要想优化慢SQL语句首先需要了解SQL语句的执行顺序,SQL语句中的各关键词执行顺序如下:
◦首先执行from、join 来确定表之间的连接关系,得到初步的数据。
◦然后利用where关键字后面的条件对符合条件的语句进行筛选。
from&join&where:用于确定要查询的表的范围,涉及到哪些表。
选择一张表,然后用join连接:
from table1 join table2 on table1.id=table2.id
选择多张表,用where做关联条件:
from table1,table2 where table1.id=table2.id
最终会得到满足关联条件的两张表的数据,不加关联条件会出现笛卡尔积。
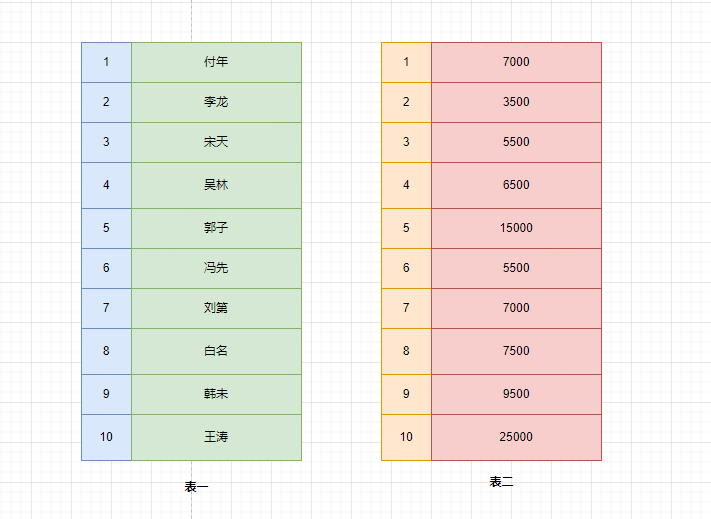
◦然后利用group by对数据进行分组。
按照SQL语句中的分组条件对数据进行分组,但是不会筛选数据。
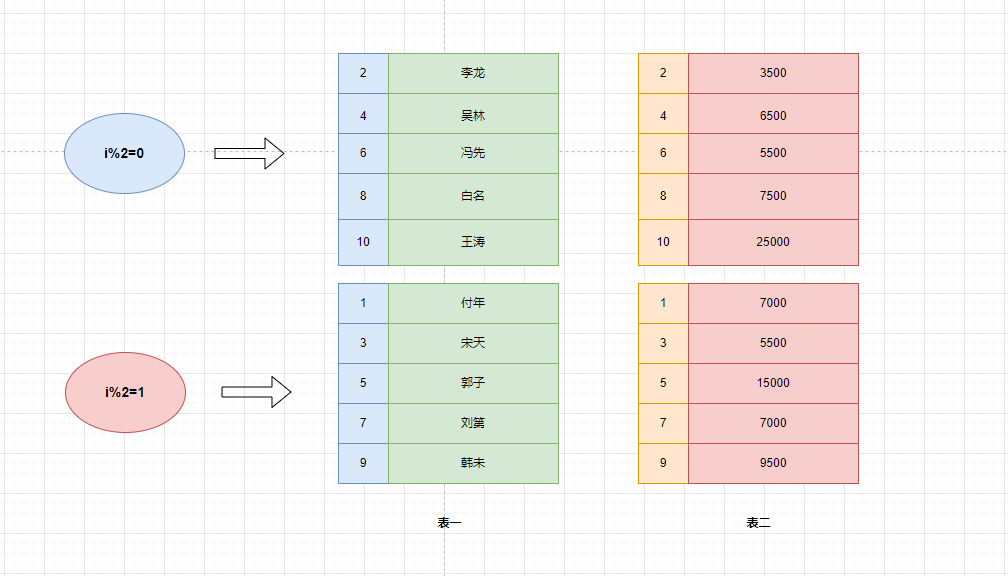
下面用按照id的奇偶进行分组:
◦然后分组后的数据分别执行having中的普通筛选或者聚合函数筛选。
having&where
having中可以是普通条件的筛选,也能是聚合函数,而where中只能是普通函数;一般情况下,有having可以不写where,把where的筛选放在having里,SQL语句看上去更丝滑。
使用where再group by : 先把不满足where条件的数据删除,再去分组。
使用group by 在having:先分组再删除不满足having条件的数据。(该两种几乎没有区别)
比如举例如下:100/2=50,此时我们把100拆分(10+10+10+10+10…)/2=5+5+5+…+5=50,只要筛选条件没变,即便是分组了也得满足筛选条件,所以where后group by 和group by再having是不影响结果的!
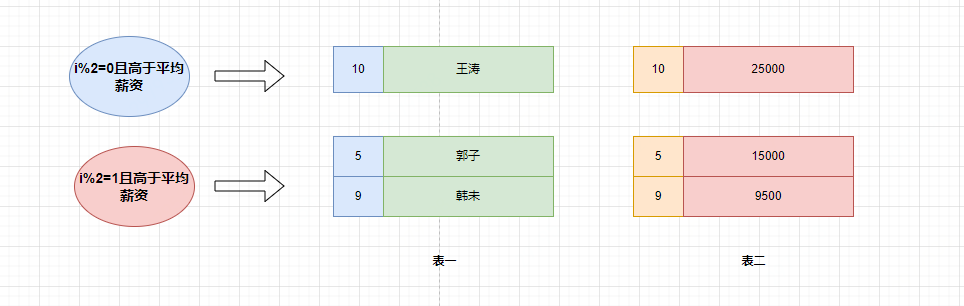
不同的是,having语法支持聚合函数,其实having的意思就是针对每组的条件进行筛选。我们之前看到了普通的筛选条件是不影响的,但是having还支持聚合函数,这是where无法实现的。
当前的数据分组情况
执行having的筛选条件,可以使用聚合函数。筛选掉工资小于各组平均工资的having salary<avg(salary):
然后再根据我们要的数据进行select,普通字段查询或者聚合函数查询,如果是聚合函数,select的查询结果会增加一条字段。
分组结束之后,我们再执行select语句,因为聚合函数是依赖于分组的,聚合函数会单独新增一个查询出来的字段,这里我们两个id重复了,我们就保留一个id,重复字段名需要指向来自哪张表,否则会出现唯一性问题。最后按照用户名去重。
select employee.id,distinct name,salary, avg(salary)

将各组having之后的数据再合并数据。

◦然后将查询到的数据结果利用distinct关键字去重。
◦然后合并各个分组的查询结果,按照order by的条件进行排序。
比如这里按照id排序。如果此时有limit那么查询到相应的我们需要的记录数时,就不继续往下查了。
◦最后使用limit做分页。
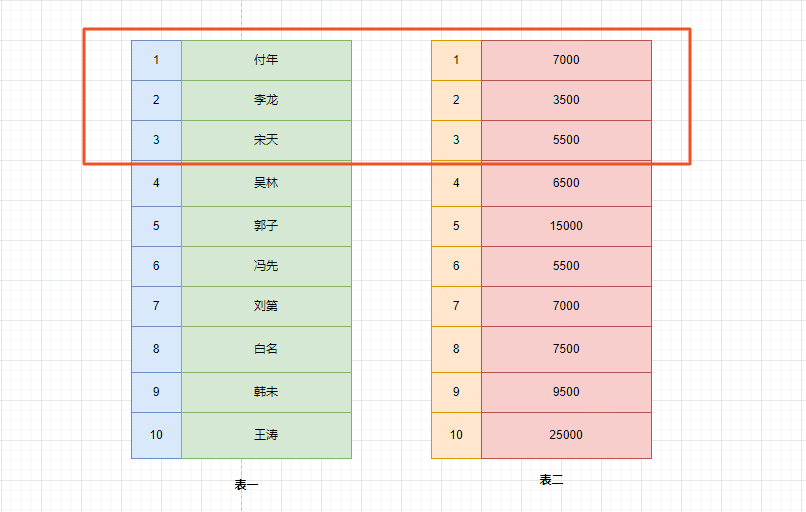
记住limit是最后查询的,为什么呢?假如我们要查询薪资最低的三个数据,如果在排序之前就截取到3个数据。实际上查询出来的不是最低的三个数据而是前三个数据了,记住这一点。
假如SQL语句执行顺序是先做limit再执行order by,执行结果为3500,5500,7000了(正确SQL执行的最低工资的是3500,5500,5500)。
SQL查询时需要遵循的两个顺序:
1、关键字的顺序是不能颠倒的。
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT
2、select语句的执行顺序(在MySQL和Oracle中,select执行顺序基本相同)。
FROM > WHERE > GROUP BY > HAVING > SELECT的字段 > DISTINCT > ORDER BY > LIMIT
以SQL语句举例,那么该语句的关键字顺序和执行顺序如下:
SELECT DISTINCT player_id, player_name, count(*) as num #顺序5
FROM player JOIN team ON player.team_id = team.team_id #顺序1
WHERE height > 1.80 #顺序2
GROUP BY player.team_id #顺序3
HAVING num > 2 #顺序4
ORDER BY num DESC #顺序6
LIMIT 2 #顺序7
三、SQL执行计划
• 为什么要学习SQL的执行计划?
因为一个sql的执行计划可以告诉我们很多关于如何优化sql的信息 。通过一个sql计划,如何访问表中的数据 (是使用全表扫描还是索引查找?)一个表中可能存在多个不同的索引,表中的类型是什么、是否子查询、关联查询等…
• 如何获取SQL的执行计划?
在SQL语句前加上explain关键词皆可以得到相应的执行计划。其中:在MySQL8.0中是支持对select/delete/inster/replace/update语句来分析执行计划,而MySQL5.6前只支持对select语句分析执行计划。 replace语句是跟instert语句非常类似,只是插入的数据和表中存在的数据(存在主键或者唯一索引)冲突的时候**,****replace**语句会把原来的数据替换新插入的数据,表中不存在唯一的索引或主键,则直接插入新的数据。
•如何分析SQL语句的执行计划?
下面对SQL语句执行计划中的各个字段的含义进行介绍并举例说明。

◦id列
id标识查询执行的顺序,当id相同时,由上到下分析执行,当id不同时,由大到小分析执行。
id列中的值只有两种情况,一组数字(说明查询的SQL语句对数据对象的操作顺序)或者NULL(代表数据由另外两个查询的union操作后所产生的结果集)。
explain
select course_id,class_name,level_name,title,study_cnt
from imc_course a
join imc_class b on b.class_id=a.class_id
join imc_level c on c.level_id =a.level_id
where study_cnt > 3000

返回3行结果,并且ID值是一样的。由上往下读取sql的执行计划,第一行是table c表作为驱动表 ,等于是以C表为基础来进行循环嵌套的一个关联查询。 (4 *100*1 =400 总共扫描400行等到数据)
◦select_type列
| 值 | 含义 |
|---|---|
| SIMPLE | 不包含子查询或者UNION操作的查询(简单查询) |
| PRIMARY | 查询中如果包含任何子查询,那么最外层的查询则被标记为PRIMARY |
| SUBQUERY | select列表中的子查询 |
| DEPENDENT SUBQUERY | 依赖外部结果的子查询 |
| UNION | union操作的第二个或者之后的查询值为union |
| DEPENDENT UNION | 当union作为子查询时,第二或是第二个后的查询的值为select_type |
| UNION RESULT | union产生的结果集 |
| DERIVED | 出现在from子句中的子查询(派生表) |
例如:查询学习人数大于3000, 合并 课程是MySQL的记录。
EXPLAIN
SELECT
course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id =a.class_id
join imc_level c on c.level_id = a.level_id
WHERE study_cnt > 3000
union
SELECT course_id,class_name,level_name,title,study_cnt
FROM imc_course a
join imc_class b on b.class_id = a.class_id
join imc_level c on c.level_id = a.level_id
WHERE class_name ='MySQL'

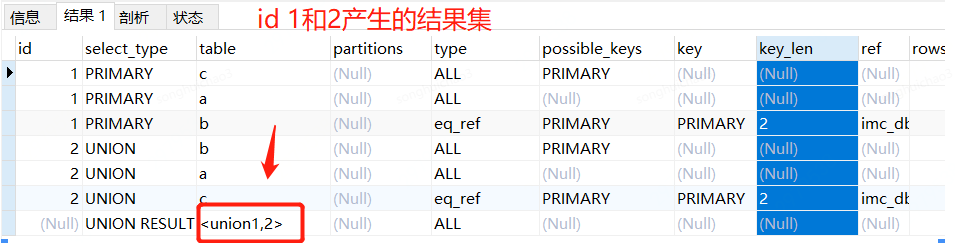
分析数据表:先看id等于2
id=2 则是查询mysql课程的sql信息,分别是b,a,c 3个表,是union操作,selecttype为是UNION。
id=1 为是查询学习人数3000人的sql信息,是primary操作的结果集,分别是c,a,b3个表,select_type为PRIMARY。
最后一行是NULL, select_type是UNION RESULT 代表是2个sql 组合的结果集。
◦table列
指明是该SQL语句从哪个表中获取数据
| 值 | 含义 | ||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
◦type列 注意: 在MySQL中不一定是使用JOIN才算是关联查询,实际上MySQL会认为每一个查询都是连接查询,就算是查询一个表,对MySQL来说也是关联查询。 type的取值是体现了MySQL访问数据的一种方式。type列的值按照性能高到低排列
•如果where like “MySQL%”,type类型为? 虽然class_name 加了索引 ,但是使用where的like% 右统配, 所以会走索引范围扫描。
•如果where like “%MySQL%”,type类型为? 虽然class_name 加了索引 ,但是使用where的%like% 左右统配, 所以会走全索引扫描,如果不加索引的话,左右统配会走全表扫描。
◦possible_key、key列
如果在表中没有可用的索引,那么key列 展示NULL,possible_keys是NULL,这说明查询到覆盖索引。 ◦key_len列 实际用的的索引使用的字节数。 注意,在联合索引中,如果有3列,那么总字节是长度是100个字节的话,那么 key_len的长度是由表中的定义的字段长度来计算的,并不是存储的实际长度,所以满足数据最短的实际字段存储,因为会直接影响到生成执行计划的生成 。 ◦ref列 指出那些列或常量被用于索引查找 ◦rows列 ( 有2个含义)1、根据统计信息预估的扫描行数。 2、另一方面是关联查询内嵌的次数,每获取匹配一个值都要对目标表查询,所以循环次数越多性能越差。 因为扫描行数的值是预估的,所以并不准确。 ◦filtered列 表示返回结果的行数占需读取行数的百分比。 filtered列跟rows列是有关联的,是返回预估符合条件的数据集,再去取的行的百分比。也是预估的值。数值越高查询性能越好。 ◦Extra列 包括了不适合在其他列中所显示的额外信息。
四、SQL索引失效 ◦最左前缀原则:要求建立索引的一个列都不能缺失,否则会出现索引失效。 ◦索引列上的计算,函数、类型转换(列类型是字符串在条件中需要使用引号,否则不走索引)、均会导致索引失效。 ◦索引列中使用is not null会导致索引列失效。 ◦索引列中使用like查询的前以%开头会导致索引列失效。 ◦索引列用or连接时会导致索引失效。 五、实际优化慢SQL中遇到问题 下面是在慢SQL优化过程中所遇到的一些问题。 •MySQL查询到的数据排序是稳定的么? •force_index的使用方式? •为什么有时候order by id会导致索引失效? •........未完整理中...... 六、总结 通过本次对慢SQL的优化的需求进而发现有关SQL语句执行顺序、执行计划、索引失效场景、底层SQL语句执行原理相关知识还存在盲区,得益于此次需求的开发,有深入的对相关知识进行学习和总结。接下来会对SQL底层是如何执行SQL语句 |



一文带你搞懂如何优化慢SQL的更多相关文章
- 一文带你搞懂java中的变量的定义是什么意思
前言 在之前的文章中,壹哥给大家讲解了Java的第一个案例HelloWorld,并详细给大家介绍了Java的标识符,而且现在我们也已经知道该使用什么样的工具进行Java开发.那么接下来,壹哥会集中精力 ...
- 【springcloud】一文带你搞懂API网关
作者:aCoder2013 https://github.com/aCoder2013/blog/issues/35 前言 假设你正在开发一个电商网站,那么这里会涉及到很多后端的微服务,比如会员.商品 ...
- 一文带你搞懂 Kafka 的系统架构(深度好文,值得收藏)
Kafka 简介 Kafka 是一种高吞吐.分布式.基于发布和订阅模型的消息系统,最初是由 LinkedIn 公司采用 Scala 和 java 开发的开源流处理软件平台,目前是 Apache 的开源 ...
- 一文带你搞懂 RPC 到底是个啥
RPC(Remote Procedure Call),是一个大家既熟悉又陌生的词,只要涉及到通信,必然需要某种网络协议.我们很可能用过HTTP,那么RPC又和HTTP有什么区别呢?RPC还有什么特点, ...
- 一文带你搞懂 Google 发布的新开源项目 GUAC
随着软件供应链攻击的显著增加,以及 Log4j 漏洞带来的灾难性后果和影响,软件供应链面临的风险已经成为网络安全生态系统共同关注的最重要话题之一.根据业内权威机构 Sonatype 发布的2022软件 ...
- 从定义到AST及其遍历方式,一文带你搞懂Antlr4
摘要:本文将首先介绍Antlr4 grammer的定义方式,如何通过Antlr4 grammer生成对应的AST,以及Antlr4 的两种AST遍历方式:Visitor方式和Listener方式. 1 ...
- 一文带你搞懂 SSR
欲语还休,欲语还休,却道天凉好个秋 ---- <丑奴儿·书博山道中壁>辛弃疾 什么是 SSR ShadowsocksR?阴阳师?FGO? Server-side rendering (SS ...
- 一文带你搞懂 JWT 常见概念 & 优缺点
在 JWT 基本概念详解这篇文章中,我介绍了: 什么是 JWT? JWT 由哪些部分组成? 如何基于 JWT 进行身份验证? JWT 如何防止 Token 被篡改? 如何加强 JWT 的安全性? 这篇 ...
- 一文带你读懂zookeeper在大数据生态的应用
一个执着于技术的公众号 一.简述 在一群动物掌管的世界中,动物没有人类聪明的思想,为了保持动物世界的生态平衡,这时,动物管理员-zookeeper诞生了. 打开Apache zookeeper的官网, ...
- 【项目实践】一文带你搞定Spring Security + JWT
以项目驱动学习,以实践检验真知 前言 关于认证和授权,R之前已经写了两篇文章: [项目实践]在用安全框架前,我想先让你手撸一个登陆认证 [项目实践]一文带你搞定页面权限.按钮权限以及数据权限 在这两篇 ...
随机推荐
- 打破“双十定律”,华为云AI推动超级抗菌药Drug X研发加速
摘要:学科交叉已经逐渐变成了科技创新的一个主要源泉,成为这个科学时代一个不可替代的研究范式.在科技与技术合力赋能之下,中国科研人创新奋斗再出新成果,人类与病菌的博弈因此有了新武器. 本文分享自华为云社 ...
- 如何利用CANN DVPP进行图片的等比例缩放?
摘要:介绍如何用昇腾AI处理器上的DVPP单元进行,图像的等比例缩放,保证图像不变形. 本文分享自华为云社区<CANN DVPP进行图片的等比例缩放>,作者:马城林 . 1. 为什么需要进 ...
- & 0xFF 作用 取低8位
& 0xFF 取低8位 @Test void byteTest() { byte hex1 = (byte) 127; byte hex2 = (byte) 383; byte hex3 = ...
- Java ZIP文件解压
Java ZIP文件解压 备忘笔记 代码: private byte[] unZip(byte[] data) { byte[] bArr = null; try { ByteArrayInputSt ...
- C# .NET Socket SocketHelper 高性能 5000客户端 异步接收数据
网上有很多Socket框架,但是我想,C#既然有Socket类,难道不是给人用的吗? 写了一个SocketServerHelper和SocketClientHelper,分别只有5.6百行代码,比不上 ...
- [kuangbin]专题九 连通图 题解+总结
kuangbin专题链接:https://vjudge.net/article/752 kuangbin专题十二 基础DP1 题解+总结:https://www.cnblogs.com/RioTian ...
- vivo 商城前端架构升级—前后端分离篇
本文主要以 vivo 商城项目的前后端分离经验,总结前后端分离思路,整理前后端分离方案,以及分离过程中遇到的问题及解决方案. 一.前言 vivo官方商城在2015年创建网上商城,开辟网络销售渠道,几年 ...
- 针对Python基本数据类型的操作
在学习Python语法前,请大家务必注意,Python是通过缩进来定义代码层次的,即同一层次的代码都是左对齐,而下个层次的代码块与当前代码块相比,会有4个空格的缩进. 这里缩进的空格数是约定俗成的,当 ...
- list求交集、并集、差集等//post或者get请求方法
package com.siebel.api.server.config.rest; import com.google.common.base.Joiner; import com.google.c ...
- <vue 路由 6、动态路由-方法传递参数>
一.query效果 点击query按钮 二.param效果 点击param按钮 注意点 1:重新刷新浏览器后,参数都不在了. 2:url中能看不到传递的参数 3.分别用{{$route. params ...