实例讲解多处理器下的计算机启动(xv6的启动过程)
启动
启动方面的文章之前也写过,那是我的第一篇文章,本文在前文的基础之上完善,然后增加了多处理器启动的情况,废话不多说直接来看。
启动可以分为两种,一种为冷启动,是指计算机在关机状态下按 POWER 键启动,又叫硬件启动,比如开机,这种启动方式在启动之前计算机处于断电状态,像内存这种需要加电维持的存储部件里面的内容都丢失了,加电开机那一刻里面的值都是随机的,操作系统会对其进行初始化。
而热启动是在加电的情况下启动,又叫软件启动,比如重启,这种启动方式在启动之前和启动之后电没断过,内存等存储部件里面的值不会改变,但毕竟是启动过程,操作系统会对其进行初始化。
不论是哪种启动,都会向 CPU 发送启动的信号,然后开始启动。同第一篇文章,我们分五个大的步骤讲述启动,BIOS->MBR->Bootloader->OS->Multiprocessor,咱们一个一个的来看。
BIOS
启动的瞬间会将寄存器 CS 和 IP 初始化:
C
S
=
0
x
f
000
,
I
P
=
0
x
f
f
f
0
CS=0xf000,IP=0xfff0
CS=0xf000,IP=0xfff0。
刚启动的时候正处于实模式,实模式下地址总线只用了 20 位,只有
2
20
=
1
M
2^{20}=1M
220=1M 的寻址空间,也就是只用到的内存的低
1
M
1M
1M,这个时候分页机制还没有建立起来,CPU 运行时的地址都是实际的物理地址。
但实模式下寄存器只用到了 16 位寄存器,如何使用寄存器来寻址 20 位的地址空间?Intel 采用分段的机制来访问内存,也就是采用
段
基
址
:
段
偏
移
,
地
址
=
段
基
址
+
偏
移
量
段基址:段偏移,地址=段基址+偏移量
段基址:段偏移,地址=段基址+偏移量 的方式来访问,但是实模式下的寄存器只能使用 16 位,所以规定实模式下
地
址
=
段
基
址
×
16
+
偏
移
量
地址=段基址\times16+偏移量
地址=段基址×16+偏移量 。
因此根据
C
S
=
0
x
f
000
,
I
P
=
0
x
f
f
f
0
CS=0xf000,IP=0xfff0
CS=0xf000,IP=0xfff0,得到的
a
d
d
r
e
s
s
=
0
x
f
000
<
<
4
+
0
x
f
f
f
0
=
0
x
f
f
f
f
0
address=0xf000<<4+0xfff0=0xffff0
address=0xf000<<4+0xfff0=0xffff0 。
这个地址是啥?来看内存低
1
M
1M
1M 的内存布局:
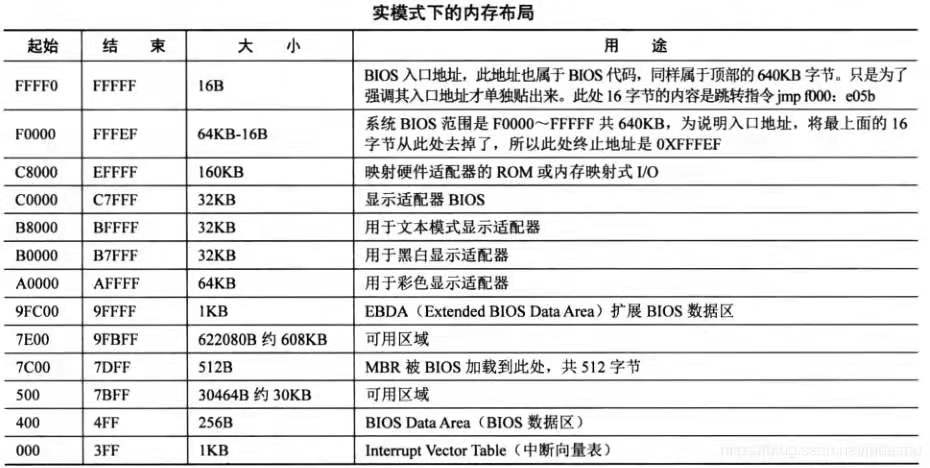
看最上面两行,可以知道
0
x
f
f
f
f
0
0xffff0
0xffff0 地址上存放的是一个跳转指令,CPU 执行这个命令然后跳转到 BIOS 代码的主体部分,BIOS 主要做一下几件事:
- 自检,然后对一些硬件设备做简单的初始化
- 构建中断向量表加载中断服务程序
- 将硬盘(通常引导设备就是硬盘)最开始那个扇区 MBR 加载到
0
x
7
c
00
0x7c00
0x7c00
MBR
关于 MBR(Master Boot Record),我在 一文讲的比较详细了,这里不赘述,简单再说一下 MBR 的结构:
- 引导程序和一些参数,446 字节
- 分区表 DPT,64字节
- 结尾标记签名,0x55 和 0xaa,两字节
MBR 的代码在分区表中寻找可以引导存在操作系统的分区,也就是寻找标记为 0x80 的活动分区,然后加载该活动分区的引导块,再执行其中的操作系统引导程序 Bootloader。
Bootloader
Bootloader,操作系统引导程序,操作系统加载器,不论怎么叫,它的主要作用就是将操作系统加载到内存里面。操作系统也是一个程序,需要加载到内存里面才能运行。平常正在运行的计算机我们可以使用 exec 族函数来加载运行一个程序,同样的要加载运行操作系统这个程序就使用 Bootloader。
在 Bootloader 里面还做了一些其他事情,比如进入保护模式,开启分页机制,建立内存的映射等等。像 GRUB,U-Boot 等都属于 Bootloader,只是功能更多更强大。
OS
操作系统内核加载到内存之后,就做一些初始化工作建立好工作环境,比如各个硬件的初始化,重新设置 GDT,IDT 等等初始的操作。初始化启动其他处理器(如果有多个处理器的话)。这里不细说,也不好叙述,等下面直接看实例 xv6 做了哪些事,怎么做的。
Multiprocessor
上述的启动过程是单处理情况下的启动过程,多处理器的情况下有些不同,用一句话先来简单概括多处理器情况下的启动:先启动一个 CPU,用它作为基础启动其他的处理器。
先启动的这个 CPU 称作 BSP(BootStrap Processor),其他处理器叫做 AP(Application Processor)。BSP 是由系统硬件或者 BIOS 动态选择决定的。
多处理器启动过程大致分为以下几个大步骤:
- BIOS 启动 BSP,流程与上述讲的 BIOS-MBR-bootloader-OS 差不多
- BSP 从 MP Configuration Table 中获取多处理器的的配置信息
- BSP 启动 APs,通过发送 INIT-SIPI-SIPI 消息给 APs
- APs 启动,各个 APs 处理器要像 BSP 一样建立自己的一些机制,比如保护模式,分页,中断等等
这里我们主要关注第二点,获取多处理器的配置信息,计算机里面专门设有数据 MP Configuration Table 来描述,还有一个数据结构 Floating Pointer Structure 来指向 MP Configuration Table。
先来看 Floating Pointer 的结构:
struct mp { // floating pointer
uchar signature[4]; // "_MP_"
void *physaddr; // phys addr of MP config table MP配置表地址
uchar length; // 1 结构长度
uchar specrev; // [14] MP版本
uchar checksum; // all bytes must add up to 0 校验和应为0
uchar type; // MP system config type 如果为0表示配置表存在
uchar imcrp; //只使用了第7位,0表示pic模式,1表示apic模式
uchar reserved[3];
};
这个结构只可能出现在三个位置,寻找 floating pointer 的时候就按下面的循序查找:
- EBDA(Extended BIOS Data Area)最开始的 1KB
- 系统基本内存的最后 1KB (对于 640 KB 的基本内存来说就是 639KB-640KB,对于 512KB 的基本内存来说就是 511KB-512KB)
- BIOS 的 ROM 区域,在
0
x
0
f
0000
0x0f0000
0x0f0000 到
0
x
f
f
f
f
f
0xfffff
0xfffff 之间
然后是 MP Configuration Table Header 的结构,它是配置表的头部:
struct mpconf { // configuration table header
uchar signature[4]; // "PCMP",签名
ushort length; // total table length
uchar version; // [14],版本
uchar checksum; // all bytes must add up to 0,校验和和应为0
uchar product[20]; // product id 产品的id
uint *oemtable; // OEM table pointer,OEM表可选,若无则0
ushort oemlength; // OEM table length OEM表胀肚
ushort entry; // entry count 表项个数
uint *lapicaddr; // address of local APIC Lapic地址
ushort xlength; // extended table length 扩展表的长度
uchar xchecksum; // extended table checksum 扩展表的校验和
uchar reserved; //保留
};
接着是 MP Configuration Table Entry 的结构,它是配置表的表项,表项种类有很多,我们只列出处理器的表项结构:
struct mpproc { // processor table entry
uchar type; // entry type (0) 表项类型:处理器
uchar apicid; // local APIC id Lapic id
uchar version; // local APIC verison 版本
uchar flags; // CPU flags 0x02表示这是BSP
#define MPBOOT 0x02 // This proc is the bootstrap processor.
uchar signature[4]; // CPU signature CPU签名
uint feature; // feature flags from CPUID instruction
uchar reserved[8];
};
上面这些数据结构了解就好(好吧我承认是有些我也不清楚),这些数据结构的布局关系图如下:
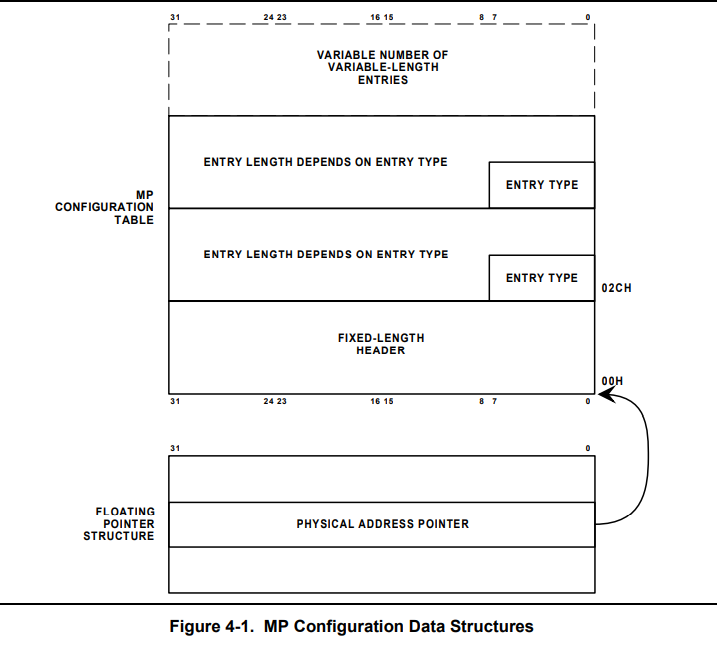
这些结构后面主要用来探寻 CPU 的个数,关于多处理器的配置数据结构就先了解到这儿, 具体怎么使用后面的实例讲解。
Xv6
前面都是一些理论知识,下面来实际看一个操作系统 xv6 是如何启动,先来看看 xv6 启动的整体流程图,好有个大概认识:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pqKUX6fa-1627530387384)(https://cdn.jsdelivr.net/gh/Rand312/Rand_Picture_System@main/xv6/xv6启动流程1.2vuw2zh54es0.png)]
不要被这么一大坨吓到,xv6 的启动过程算简单的,在启动方面做了很多简化,应该说整个操作系统都做了简化,不然整体也就不会才几千行代码。因为做了一些简化,可能过程不向上述那么分明,但也是类似相通的。
BIOS 是一个只读的 ROM 区域,操作系统无能为力,但是我们知道它的执行流程,从
0
x
f
f
f
f
0
0xffff0
0xffff0 开始执行 BIOS 的代码,然后将磁盘上的第 0 扇区(LBA 寻址方式)也就是最开始那个扇区的 MBR 加载到
0
x
7
c
00
0x7c00
0x7c00,然后开始执行。
接下来的代码操作系统就可以来掌控了,但 xv6 并没有实际构造 MBR 结构,从 Makefile 中可以知晓最开始那个扇区写入的是 bootblock,bootblock 又是由 bootasm.S 和 bootmain.c 两文件经过一些列编译汇编链接再转换格式得来。
bootblock: bootasm.S bootmain.c
################################
dd if=bootblock of=xv6.img conv=notrunc
这是从 Makefile 中截取的两句,bootblock 依赖 bootasm.S 和 bootmain.c 生成,然后使用 dd 命令将其写入 xv6.img。这个 xv6.img 可以看作是磁盘映像。
dd 命令简单解释:
- i
f
=
F
I
L
E
if=FILE
if=FILE,指定要读取的文件
- o
f
=
F
I
L
E
of=FILE
of=FILE,指定要将数据输出到的文件
- b
s
=
B
Y
T
E
S
bs=BYTES
bs=BYTES,指定块的大小,dd 操作 IO 的基本单位为一个块,未指定是默认 512 字节
- c
o
u
n
t
=
B
L
O
C
K
S
count=BLOCKS
count=BLOCKS,指定操作的块数
- s
e
e
k
=
B
L
O
C
K
S
seek=BLOCKS
seek=BLOCKS,指定把块输出到文件时要跳过多少块
- c
o
n
v
=
C
O
N
V
S
conv=CONVS
conv=CONVS,指定如何转换文件,一般指定为 notrunc,一维不打断截短文件
因此上述的 dd 命令就是将 bootblock 写到 xv6.img,没有指定 seek,所以不跳过,那就是写到第零块/扇区,相当于写到硬盘最开始的扇区。
bootasm.S
这一节来具体分析 bootasm.S ,主要做了一件事:进入保护模式,主要分四步:打开A20 -> 构建加载 GDT -> 设置 CR0寄存器 -> start32 调用 bootmain。启动其实涉及了很多后面的东西,比如硬盘,APIC,各种机制的建立等等,一些地方的细节不做详细说明留待后面讲解,废话不再多说,一个一个的来看:
打开 A20
我在前面的文章分页机制,讲述过一种打开 A20 的方法,使用系统端口 0x92,这种方法很简单,但是非常危险容易导致和其他硬件冲突而强制关机。xv6 使用了另一种方法:使用键盘控制器来打开 A20,直接来看码:
seta20.1: # Wait for not busy 等待i8042缓冲区为空
inb $0x64,%al # 从0x64端口读出键盘状态
testb $0x2,%al # 测试键盘是否忙
jnz seta20.1 # 忙的话跳转到seta20.1,循环等待
movb $0xd1,%al # 发送0xd1到端口0x64,表示准备向0x60端口写入命令
outb %al,$0x64
seta20.2:
inb $0x64,%al # Wait for not busy 同上
testb $0x2,%al
jnz seta20.2
movb $0xdf,%al # 向端口0x60写入0xdf,打开A20
outb %al,$0x60
关于键盘的操作,前面也写过一篇文章键盘,可以参考参考,这里不赘述,上面的注释也应该看得懂,简单来说就是向特定的端口写入命令打开 A20。
打开 A20 后,地址总线可以使用 32 根,寻址范围达到
2
32
=
4
G
2^{32} = 4G
232=4G。
构建加载 GDT
I 构建GDT(bootasm.h)
# 设置段描述符的宏
#define SEG_NULLASM \
.word 0, 0; \
.byte 0, 0, 0, 0
#define SEG_ASM(type,base,lim) \
.word (((lim) >> 12) & 0xffff), ((base) & 0xffff); \
.byte (((base) >> 16) & 0xff), (0x90 | (type)), \
(0xC0 | (((lim) >> 28) & 0xf)), (((base) >> 24) & 0xff)
#构建GDT
gdt:
SEG_NULLASM # null seg GDT中第一个段描述符不用
SEG_ASM(STA_X|STA_R, 0x0, 0xffffffff) # code seg 代码段描述符 执行,读权限
SEG_ASM(STA_W, 0x0, 0xffffffff) # data seg 数据段描述符 写权限
段选择子(mmu.h):
#define SEG_KCODE 1 // kernel code
#define SEG_KDATA 2 // kernel data+stack
根据 SEG_ASM 宏构建了两个段描述符:代码段描述符和数据段描述符,因为代码段在 GDT 中的索引设为 1,所以先构建的代码段描述符。GDT 第一个描述符是没用的,所以直接设置为 0。
II 构建 GDTR 数据
CPU 需要知道构建的 GDT 在哪,所以需要将 GDT 的起始地址和界限这两样信息加载到 GDTR 寄存器
gdtdesc: # 构造gdtr用到的6字节数据
.word (gdtdesc - gdt - 1) # sizeof(gdt) - 1 界限=大小-1
.long gdt # address gdt gdt起始地址
上述的 gdtdesc 即为 GDTR 需要的 48 位数据,它包括了 GDT 的起始位置和界限
III 加载 GDT
lgdt gdtdesc #加载gdt
加载 GDT 有专门的指令 lgdt,使用方法很简单,如上图所示
设置 cr0 寄存器
将 CR0 寄存器的 PE 位置 1 开启保护模式
movl %cr0, %eax
orl $CR0_PE, %eax
movl %eax, %cr0
从此开始进入保护模式,16 位的 CPU 变成了 32 位的 CPU,此刻前后的指令格式也是不一样的,在此之前使用的 16 位指令,在此之后使用的 32 位指令,这里所说的多少位的指令不是说这个指令的长度,而是两种模式下指令的编码都不一样,也就是说同一条指令在两种模式下的机器码可能不一样。
但是我们应该都知道,为了加快 CPU 执行指令的效率,存在着一种机制:流水线,简单来说,就是把多条指令加载到流水线上,同时运行不同指令不同部分。问题就出在这儿,进入保护模式后流水线上可能还存在 16位的指令,所以进入保护模式后需要清空流水线,无条件跳转 jmp 指令可以用来清空流水线:
ljmp $(SEG_KCODE<<3), $start32 #跳到 CS=(SEG_KODE<<3) EIP=start32,段基址为0,所以就是跳到start32处
#使用长跳刷新流水线,因为目前的流水线里面有16位实模式下的指令,而后面应该用32位保护模式下的指令
另外,进入保护模式之后,段寄存器里面存放的不再是段基址,而是段选择子,使用段选择子的高 13 位作为索引去 GDT 获取相应的段基址,加上偏移量便为最后的地址。因为多了这么一个步骤,加之段选择子,段描述符里面都有一些属性位,访问内存增加了限制,是为保护。(所以对计算机的保护就是限制它的自由?)
现今关于内存的分段大都为平坦模式,许多段共用一个段选择子,而且段描述符里面的段基址大都为 0,因为地址总线和常用的一些寄存器的位数都扩展到了 32 位(除段寄存器),寻址范围为
2
32
=
4
G
2^{32}=4G
232=4G,能够寻址到所有的地址。不像实模式下单一 16 位的寄存器是不能够寻到 20 位的地址空间的,需要段寄存器里面的段基址左移 4 位再和段偏移相加来寻址。
start32
上面那个长跳跳转到下面的代码:
movw $(SEG_KDATA<<3), %ax # Our data segment selector 设置段寄存器,DS,ES,SS共用一个段选择子
movw %ax, %ds # -> DS: Data Segment
movw %ax, %es # -> ES: Extra Segment
movw %ax, %ss # -> SS: Stack Segment
movw $0, %ax # Zero segments not ready for use FS,GS设为0,不用
movw %ax, %fs # -> FS
movw %ax, %gs # -> GS
没什么说的,设置段寄存器,
S
E
G
K
D
A
T
A
<
<
3
SEG_KDATA<<3
SEGKDATA<<3,左移三位移动的是属性位,全设置成 0 了,具体各个位表示什么,参考我前面也写过相应的文章实模式到保护模式。上面没有设置 CS 寄存器,CS 在长跳那个指令设置的。
bootasm.S 最后做的工作:
movl $start, %esp #将start0x7c00设为栈顶
call bootmain
设置栈顶为 0x7c00,然后调用 bootmain。一个操作系统栈的变化一直是一个很迷很迷很迷的过程,要把握好栈的变化。
bootmain
相当于 bootloader,主要就是加载内核,整个内核就是一个 elf 文件,关于 elf 文件可以参考我写的这篇文章,本文不赘述。加载内核,内核在哪?在磁盘上,所以要先读取磁盘。bootmain.c 里面有三个关于磁盘操作的函数,目前细节看不懂没关系,我们先了解三个函数的具体意思就可以了,实现细节放后面文章讲解。
- void waitdisk(void) //等待磁盘空闲就绪
- void readsect(void *dst, uint offset) //读取单个扇区 offset 到 dst
- void readseg(unchar *pa, uint count, uint offset) //从offset所在的扇区加1读取count字节到pa,加1是因为内核从扇区1开始
有了上面三个函数的了解来看函数 bootmain:
void bootmain(void)
{
struct elfhdr *elf;
struct proghdr *ph, *eph;
void (*entry)(void);
uchar* pa;
elf = (struct elfhdr*)0x10000; // scratch space 内核从这个位置开始
// Read 1st page off disk
readseg((uchar*)elf, 4096, 0); //从扇区 1 开始读,读4096个字节到0x10000,即8个扇区
// Is this an ELF executable?
if(elf->magic != ELF_MAGIC) //判断是否是elf文件
return; // let bootasm.S handle error //不是就返回
// Load each program segment (ignores ph flags).
ph = (struct proghdr*)((uchar*)elf + elf->phoff); //第一个程序头的位置
eph = ph + elf->phnum; //最后一个程序头的位置
for(; ph < eph; ph++){ //for循环读取程序段
pa = (uchar*)ph->paddr; //程序段的位置
readseg(pa, ph->filesz, ph->off); //off是该相对于elf的偏移量,filesz是该段的大小,即从off所在的扇区读取filesz到内存地址为pa的地方
if(ph->memsz > ph->filesz) //因为 bss节的存在,elf文件并不需要存在bss的实体,但是内存中需要占位,所以可能大些
stosb(pa + ph->filesz, 0, ph->memsz - ph->filesz); //调用 stosb 将段的剩余部分置零
}
// Call the entry point from the ELF header.
// Does not return!
entry = (void(*)(void))(elf->entry); //entry,程序的入口点
entry(); //调用entry
}
如果对 elf 文件很熟悉的话,上面程序应该很好理解,有详细的注释我就不解释了,如果有哪儿不懂,请参考文章 讲解 elf 的部分。
所以 bootmain 就做了一件事,将内核加载到内存,然后调用 entry,加载内核之后内存中的布局如下:
entry
entry 主要也主要做了一件事,开启分页机制然后跳转到 main,主要分四步:构建页表->加载页表->设置 CR3 寄存器->跳转到 main
.globl _start
_start = V2P_WO(entry) //_start汇编的缺省入口,但因为还没有开启分页建立虚拟内存的机制,所以将其转化为物理地址
.globl entry
entry:
# 设置CR4寄存器的PSE位,允许每页大小为4M
movl %cr4, %eax
orl $(CR4_PSE), %eax
movl %eax, %cr4
# 将页目录地址加载到CR3寄存器
movl $(V2P_WO(entrypgdir)), %eax
movl %eax, %cr3
# 设置CR0寄存器的PG位开启分页机制
movl %cr0, %eax
orl $(CR0_PG|CR0_WP), %eax
movl %eax, %cr0
# Set up the stack pointer.
movl $(stack + KSTACKSIZE), %esp //栈顶设置到分配的一页空间顶部
mov $main, %eax //跳转到main
jmp *%eax
.comm stack, KSTACKSIZE //链接时若无法找到stack的定义,则分配KSTACKSIZE的未初始化的内存。
这段代码应该也还是很好理解,有几个点:
- 页表定义在 main.c,只映射了物理内存的低 4 M,关于虚拟内存放在后面的文章讲述,本文使用的也很少
- 又一次换栈,栈顶地址可以查看 kernel.asm 得到,为
0
x
8010
b
5
c
0
0x8010b5c0
0x8010b5c0,似乎没什么特殊之处,就随便找了块合适的地儿作为栈。当然这个内存分配跟链接有关,链接我不太熟悉,或许其中有什么玄机,没有深究下去了,若真另有玄机,有知道的大佬还请告知。
- jmp *%eax,使用间接跳转,直接从 eax 中获取目的地的绝对地址,否者使用直接跳转的话,会生成相对寻址的编码,也就是会将目标指令的地址与紧跟在跳转指令后面那条指令的地址之间的差作为编码
main
终于来到 main 函数,主要是对各种机制的初始化,我们主要来看三个与 CPU 启动相关的,其他的放到后面:
int main(void)
{
mpinit(); // detect other processors 检测其他CPU
startothers(); // start other processors 启动其他CPU
mpmain(); // finish this processor's setup 完成该CPU的启动
}
mpinit
函数 mpinit() 就是从 MP Configuration Table 获取 cpu 的配置信息,根据前面的理论知识,首先要找到 floating pointer,根据其中记录的多处理器配置表的地址找到该表,而 floating pointer 又只可能出现在那三个位置,那么依次寻找就完事了。mpinit() 在文件 mp.c 里面,我们从上至下依次看看里面的函数
static uchar sum(unchar *addr, int len); //计算addr-addr+len这一段的和
static struct mp* mpsearch1(uint a, int len) //在a~a+len这一段寻找floating pointer 结构
{
uchar *e, *p, *addr;
addr = P2V(a); //转换成虚拟地址
e = addr+len; //结尾
for(p = addr; p < e; p += sizeof(struct mp))
if(memcmp(p, "_MP_", 4) == 0 && sum(p, sizeof(struct mp)) == 0) //比较签名和校验和,如果符合则存在floating pointer
return (struct mp*)p;
return 0;
}
static struct mp* mpsearch(void) //寻找mp floating pointer 结构
{
uchar *bda;
uint p;
struct mp *mp;
bda = (uchar *) P2V(0x400); //BIOS Data Area地址
if((p = ((bda[0x0F]<<8)| bda[0x0E]) << 4)){ //在EBDA中最开始1K中寻找
if((mp = mpsearch1(p, 1024)))
return mp;
} else { //在基本内存的最后1K中查找
p = ((bda[0x14]<<8)|bda[0x13])*1024;
if((mp = mpsearch1(p-1024, 1024)))
return mp;
}
return mpsearch1(0xF0000, 0x10000); //在0xf0000~0xfffff中查找
}
上述代码就是用来寻找 floating pointer 结构,应该不难理解,可能迷惑点就在于 mpsearch 函数中 EBDA 和 Base memory 的位置表示,这我们从直接 BDA 中获取位置信息,BDA 是 BIOS 的数据区域,位置固定在 0x400 的地方,里面包括了我们需要的信息。

看我标注出来的两项,从地址 0x040E 开始的两字节为 EBDA 的地址右移 4 位。上面代码定义的 bda 为指向 unsigned char 类型的指针,起始地址为 0x400,当然啊转化成虚拟地址了,所以 bda[0xE] << 4 表示 EBDA 地址低 8 位,bda[0xF] << 8 表示 EBDA 的高 8 位,和起来就是 EBDA 的位置
从地址 0x0413 开始的两字节表示 EBDA 前面一共多少个字节,这个数就是基本内存的大小,也是基本内存的末尾地址,代码同样的操作就不再解释。
找到了 floating pointer 结构之后就可以根据其元素 physaddr 找到 MP Configuration Table,这个表又是根据两部分组成,表头和表项,表项中目前很多都用不到,我们只关注处理器的部分,简单来说 mpinit 函数有关处理器的部分就是寻找有多少个处理器表项,多少个处理器表项就代表有多少个处理器,然后将相关信息填进全局的 CPU 数据结构:
struct cpu cpus[NCPU]; //全局CPU数据结构,NCPU表示支持多少个CPU
int ncpu; //CPU数量
for(p=(uchar*)(conf+1), e=(uchar*)conf+conf->length; p<e; ){ //跳过表头,从第一个表项开始for循环
switch(*p){ //选取当前表项
case MPPROC: //如果是处理器
proc = (struct mpproc*)p;
if(ncpu < NCPU) {
cpus[ncpu].apicid = proc->apicid; // apic id可以来标识一个CPU
ncpu++; //找到一个CPU表项,CPU数量加1
}
p += sizeof(struct mpproc); //跳过当前CPU表项继续循环
continue;
虽然是截取的代码部分,加上注释应该也还是没什么问题,xv6 定义了一个全局的 CPU 数据结构,这个 mpinit 函数就是探寻有多少个 CPU 然后初始化一部分 CPU 数据结构,其中涉及到了部分高级中断控制器 APIC 的知识,可以参考文章:再谈中断(APIC)。每个 CPU 都对应着一个 LAPIC,LAPIC 的 ID 也就可以用来唯一标识一个 CPU。
startothers
寻到了有多少个 CPU,而且也有了每个 CPU 的标识信息,就可以去启动它们了,直接来看 startothers 的代码:
static void
startothers(void)
{
extern uchar _binary_entryother_start[], _binary_entryother_size[];
uchar *code;
struct cpu *c;
char *stack;
//entryother.S 是APs启动时要运行的代码,链接器将映像放在_binary_entryother_start
//然后将其移动到0x7000处
code = P2V(0x7000);
memmove(code, _binary_entryother_start, (uint)_binary_entryother_size);
for(c = cpus; c < cpus+ncpu; c++){ //for循环启动APs
if(c == mycpu()) // 排除自个儿
continue;
// Tell entryother.S what stack to use, where to enter, and what
// pgdir to use. We cannot use kpgdir yet, because the AP processor
// is running in low memory, so we use entrypgdir for the APs too.
stack = kalloc(); //给每个AP分配一个栈
*(void**)(code-4) = stack + KSTACKSIZE; //code-4的位置填写栈顶地址
*(void(**)(void))(code-8) = mpenter; //code-8的位置填写mpenter地址
*(int**)(code-12) = (void *) V2P(entrypgdir); //code-12的位置填写页目录地址
lapicstartap(c->apicid, V2P(code)); //调用lapicstartap启动AP,传递参数apic id和要执行的代码地址
// wait for cpu to finish mpmain()
while(c->started == 0) //等待当前AP启动好再进行下一次循环
;
}
}
看起来这函数有点儿复杂啊,咱们一步步来,首先是 entryother.S 这个汇编代码,我就不贴出来了,大家可以自己看看源码,就是 BSP 执行的 bootasm.S 与 entry.S 的结合体,这是 APs 要执行的代码,主要的工作就是进入保护模式,开启分页机制,然后调用 mpenter() 函数,mpenter() 函数就是完成最后的启动工作的,我们后面看。
接着就是一个 for 循环来启动 APs,它会跳过自个儿 BSP,然后循环次数就是 CPU 的数量,这在前面 mpinit() 初始化过了。对于每个 CPU 都有一个栈,BSP 是用 .comm 语句让链接器来分配的,APs 使用 kalloc() 函数来分配,kalloc 同样放在后面内存管理的时候叙述,现在只需要知道 kalloc 可以分配一个物理页,然后返回起始虚拟地址。
然后再 entryother 的代码下方,也就是 0x7000 的下方依次填写栈顶地址,mpenter 地址,页目录地址,因为这三个地址 entryother.S 都要用到,所以先准备好。
最后再调用 lapicstartap() 函数来启动 APs,来看这个函数
lapicstartap
前面说过 BSP 启动主要就是发送 INIT-SIPI-SIPI 信号给 APs,怎么发送呢?我在 一文中提到过一点,简单来说就是一个 CPU 通过写 LAPIC 的 ICR 寄存器来与其他 CPU 进行通信,来看具体代码:
void lapicstartap(uchar apicid, uint addr)
{
int i;
ushort *wrv;
//BSP必须将CMOS状态寄存器A设置为0x0A,这样后面就会跳到40:67h记录的程序入口点
outb(CMOS_PORT, 0xF); // offset 0xF is shutdown code
outb(CMOS_PORT+1, 0x0A);
//在这个位置设置复位向量,其实就相当于填写程序code的地址
wrv = (ushort*)P2V((0x40<<4 | 0x67)); // Warm reset vector
wrv[0] = 0;
wrv[1] = addr >> 4;
发送 INIT 消息
lapicw(ICRHI, apicid<<24);
lapicw(ICRLO, INIT | LEVEL | ASSERT);
microdelay(200);
lapicw(ICRLO, INIT | LEVEL);
microdelay(100); // should be 10ms, but too slow in Bochs!
// 发送两次 STARTUP IPI 消息
for(i = 0; i < 2; i++){
lapicw(ICRHI, apicid<<24);
lapicw(ICRLO, STARTUP | (addr>>12));
microdelay(200);
}
}
上面的代码其实就是 BSP 设置 ICR 寄存器然后像 APs 发送 INIT-SIPI-SIPI 消息的过程。至于为什么要这么做,要这么设置,没有为什么,Intel 这么规定的,算是固有特性吧。上面使用的具体设置寄存器的函数,CMOS,APIC 等等我们放在中断那一章节讲述,这里就先了解这个过程就好。
当 APs 收到 BSP 发来的三个消息之后,就会去 40:0x67 的位置拿自己的启动代码的地址,也就是 BSP 调用 lapicstartap(c->apicid, V2P(code)) 传的参数 V2P(code),也就是 0x7000,这儿是物理地址,因为对于 APs,还没有进入保护模式,还没有开启分页机制建立虚拟内存。
另外,这段代码执行完之后具体怎么跳转到 0x7000 的我也不太清除,这方面的资料没有找到,我猜测应该是设置 CMOS 状态寄存器A,warm reset vector,以及最后发送 SIPI 设置的 vector,它们之间有着某种关系,vector 嘛中断向量,然后根据中断机制,拿到了 0x7000 这个地址,当然这是猜测,有知道的大佬还请告知。
拿到 code 的地址之后,就可以执行 entryother.S 的代码了,这个汇编代码跟前面的 bootasm.S 和 entry.S 大都是相同的,我们只看两句:
movl (start-4), %esp #将栈顶赋给esp
call *(start-8) #调用mpenter()
前面设置的栈顶地址,mpenter 地址在这儿就体现作用了,现在 AP 也有了自己的栈了,然后运行 mpenter() 完成启动
mpenter
static void mpenter(void)
{
switchkvm(); //切换到内核页表
seginit(); //重新设置和加载GDT
lapicinit(); //初始化APIC
mpmain(); //见下
}
static void mpmain(void)
{
cprintf("cpu%d: starting %d\n", cpuid(), cpuid());
idtinit(); // 加载GDT
xchg(&(mycpu()->started), 1); // 将started置1表启动完成了
scheduler(); // 开始调度进程执行程序了
}
可以看到,这里面所做的工作主要还是初始化建立环境,最后 CPU 这个结构体中的元素 started 置 1 表示这个 CPU 已经启动好了,这里就会通知 startothers 函数,可以启动下一个 AP 了。最后就是调用 scheduler() 可以开始调度执行程序了。
执行完 startothers(),所有的 APs 就启动好了,最后 BSP 本身再执行 mpenter 自身完成启动,到此所有的 CPU 都已经完成启动,也就是计算机的启动工作正式完成,各种环境已经建立好,可以执行各种程序,完成各种任务了。
最后再来看以下 xv6 的启动流程图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-27snuVNW-1627530387391)(https://cdn.jsdelivr.net/gh/Rand312/Rand_Picture_System@main/xv6/xv6启动流程1.2vuw2zh54es0.png)]
本文关于启动的知识就是这么多,可以看出启动是一个很大的工程,涉及了各个部分,本文着重叙述了启动过程,对其中的硬件操作省略了,准备后面讲到各个部分再来细说。
本文参考:
Intel 64 and IA-32 Architectures Software Developer Manuals
MultiProcessor Specification (cmu.edu)
主要就是参考这些吧,当然不止,启动工程涉及的东西太多,第一个是 intel 的开发手册,第八章有讲述多处理器的管理和启动协议,第二个是实模式下的低 1M 的内存映射,第三个是多处理器的规范,配置表等等里面有详细说明。
本文差不多也算是我开启 xv6 这个系列的第一篇,前面的文章差不多大概将操作系统的主体部分讲了,嗯其实还差的多,但是吧我觉得有些东西真的还是得和源码结合实际来讲述,否则空谈真没多大效果,所以剩余部分我打算直接和 xv6 结合起来讲述。都说 MIT 的操作系统课程是学习操作系统的神级课程,那我们就来慢慢剖析 xv6,顺便也将前面讲过的给串起来。但是啊操作系统的涉及的东西的确是太广太广了,我也实在没有那时间那精力去将各个部分都吃透弄懂,从本文就可以看出,有些硬件的细节,链接的细节我也不是太清楚。
另外,人的精力是有限的,一些细节部分不是专门从事那方面研究工作的也的确不用太过深究,把握主体就好,主体方面我还是能够确保提供一个正确完整的闭环。本文到这儿就结束了,有什么错误还请批评指正,也欢迎大家来同我交流学习进步。
实例讲解多处理器下的计算机启动(xv6的启动过程)的更多相关文章
- 实例讲解Linux下的makefile
1.程序代码结构如下 makefile/ |-- Makefile |-- haha.c `-- hehe.c 1.1.需要被编译的源代码如下 $ cat haha.c #include " ...
- 实例讲解Nginx下的rewrite规则
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
- 实例讲解Nginx下的rewrite规则(转)
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
- MetaSploit攻击实例讲解------终端下PostgreSQL数据库的使用(包括kali linux 2016.2(rolling) 和 BT5)
不多说,直接上干货! 配置msf连接postgresql数据库 我这里是使用kali linux 2016.2(rolling) 用过的博友们都知道,已经预安装好了PostgreSQL. 1. p ...
- 实例讲解Nginx下的rewrite规则 来源:Linux社区
一.正则表达式匹配,其中:* ~ 为区分大小写匹配* ~* 为不区分大小写匹配* !~和!~*分别为区分大小写不匹配及不区分大小写不匹配二.文件及目录匹配,其中:* -f和!-f用来判断是否存在文件* ...
- 实例讲解启动mysql server失败的解决方法
MySQL 实例讲解启动mysql server失败的解决方法 来源: 作者: 发表于: 启动mysql server 失败,查看/var/log/mysqld.err 080329 16:01:29 ...
- (转)SQLServer实例讲解
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...
- 基于tcpdump实例讲解TCP/IP协议
前言 虽然网络编程的socket大家很多都会操作,但是很多还是不熟悉socket编程中,底层TCP/IP协议的交互过程,本文会一个简单的客户端程序和服务端程序的交互过程,使用tcpdump抓包,实例讲 ...
- spring事务传播机制实例讲解
http://kingj.iteye.com/blog/1680350 spring事务传播机制实例讲解 博客分类: spring java历险 天温习spring的事务处理机制,总结 ...
- TCP入门与实例讲解
内容简介 TCP是TCP/IP协议栈的核心组成之一,对开发者来说,学习.掌握TCP非常重要. 本文主要内容包括:什么是TCP,为什么要学习TCP,TCP协议格式,通过实例讲解TCP的生命周期(建立连接 ...
随机推荐
- pip(国内常用镜像源)安装地址
国内常用镜像源 清华大学:https://pypi.tuna.tsinghua.edu.cn/simple/ 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中国 ...
- SQL server 批量删除表
select 'drop table '+name+';' from sys.tables declare c cursor forselect NAME from sysobjects where ...
- [Python急救站]人脸识别技术练习
这段时间做了一个用于初学者学习人脸识别系统的程序,在上代码时,先给说说事前准备: 首先我们需要一个OpenCV的一个haarcascade_frontalface_default.xml文件,只要去G ...
- 快速搭建Zookeeper和Kafka环境
前言 由于项目需要涉及到zookeeper和Kafka的使用,快速做了一篇笔记,方便小伙伴们搭建环境. zookeeper 官方定义 What is ZooKeeper? ZooKeeper is a ...
- 阿里巴巴MySQL开源中间件Canal入门
前言 距离上一篇文章发布又过去了两周,这次先填掉上一篇秒杀系统文章结尾处开的坑,介绍一下数据库中间件Canal的使用. Canal用途很广,并且上手非常简单,小伙伴们在平时完成公司的需求时,很有可能会 ...
- 一键入门到精通:sd-webui-prompt-all-in-one 项目大揭秘!
今天向大家推荐一个宝藏项目.在创意无限的AI艺术生成世界中,sd-webui-prompt-all-in-one 项目如一股清流,为广大创作者和开发者带来了前所未有的便捷和灵感.这不仅仅是一个项目,它 ...
- Mybatis学习五($和#区别以及其他tips)
1.$和#区别 1 #是将传入的值当做字符串的形式,eg:select id,name,age from student where id =#{id},当前端把id值1,传入到后台的时候,就相当于 ...
- 【保姆级Python入门教程】马哥手把手带你安装Python、安装Pycharm、环境配置教程
您好,我是 @马哥python说 ,一枚10年程序猿. 我的社群中小白越来越多,咨询讨论的问题很多集中在python安装上,故输出此文,希望对大家起步有帮助. 下面开始,先安装Python,再安装py ...
- 一键接入大模型:One-Api本地安装配置实操
前言 最近准备学习一下 Semantic Kernel, OpenAI 的 Api 申请麻烦,所以想通过 One-api 对接一下国内的在线大模型,先熟悉一下 Semantic Kernel 的基本用 ...
- C语言:将文件中所得到的单词表保存到一个顺序表中--使用动态分配数组。
在很多时候我们想要在程序中存储想要的信息,但是又不知道该信息的大小或者说不知道需要多长的数组来存放.动态分配空间这个很好的解决了这个问题,动态分配不仅只可以用在链表中分配节点空间,其实更多时候用来分配 ...