LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战
LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战
0.前言
**Modelscope **是一个交互式智能体应用基于ModelScope-Agent,用于方便地创建针对各种现实应用量身定制智能体,目前已经在生产级别落地。AgentFabric围绕可插拔和可定制的LLM构建,并增强了指令执行、额外知识检索和利用外部工具的能力。AgentFabric提供的交互界面包括:
智能体构建器:一个自动指令和工具提供者,通过与用户聊天来定制用户的智能体
用户智能体:一个为用户的实际应用定制的智能体,提供构建智能体或用户输入的指令、额外知识和工具
配置设置工具:支持用户定制用户智能体的配置,并实时预览用户智能体的性能
目前agentfabric围绕DashScope提供的 Qwen2.0 LLM API 在AgentFabric上构建不同的智能体应用。
在使用dashscope提供的qwen api构建应用与定制交互的过程中,我们发现选取千亿级别参数的qwen-max或开源的qwen-72b等大规模参数模型能获得较好的工具调用和角色扮演效果。大规模参数模型效果好,但难以在消费级机器上进行本地部署调用;同时小模型如qwen-7b-chat对工具调用的能力较弱。因此本篇旨在针对AgentFabric的工具调用场景,提供可用的数据集和微调方法,使稍小的模型如qwen-7b-chat也具有能在agentfabric中完成工具调用的能力。
1.环境安装
# 设置pip全局镜像 (加速下载)
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
# 安装ms-swift
git clone https://github.com/modelscope/swift.git
cd swift
pip install -e .[llm]
# 环境对齐 (通常不需要运行. 如果你运行错误, 可以跑下面的代码, 仓库使用最新环境测试)
pip install -r requirements/framework.txt -U
pip install -r requirements/llm.txt -U
2.数据准备
为训练Agent能力,魔搭官方提供了两个开源数据集:
魔搭通用问答知识数据集 该数据集包含了38万条通用知识多轮对话数据
魔搭通用Agent训练数据集 该数据集包含了3万条Agent格式的API调用数据
相关使用方式参考:Agent微调最佳实践-数据准备
为了让qwen-7b-chat能够在Agentfabric上有比较好的效果,我们尝试使用通用Agent训练数据集ms_agent对qwen-7b-chat进行微调。微调后模型确实能够在ms_agent格式的prompt下获得工具调用能力。但在agentfabric上对工具的调用表现欠佳,出现了不调用工具、调用工具时配置的参数错误、对工具调用结果的总结错误等,10次访问能成功正确调用1次。
- 不调用工具;总结时胡编乱造

- 调用时不按要求填写参数
考虑到agentfabric是基于大规模文本模型调配的prompt,侧重角色扮演和应用,与ms_agent的prompt格式有区别。finetuned稍小模型的通用泛化性稍弱,换格式调用确实可能存在效果欠佳的情况。
ms_agent数据集格式:
Answer the following questions as best you can. You have access to the following APIs:
1. fire_recognition: Call this tool to interact with the fire recognition API. This API is used to recognize whether there is fire in the image. Parameters: [{"name": "image", "description": "The input image to recognize fire", "required": "True"}]
Use the following format:
Thought: you should always think about what to do
Action: the action to take, should be one of the above tools[fire_recognition, fire_alert, call_police, call_fireman]
Action Input: the input to the action
Observation: the result of the action
... (this Thought/Action/Action Input/Observation can be repeated zero or more times)
Thought: I now know the final answer
Final Answer: the final answer to the original input question
Begin!
输入图片是/tmp/2.jpg,协助判断图片中是否存在着火点
agentfabric:
# 工具
## 你拥有如下工具:
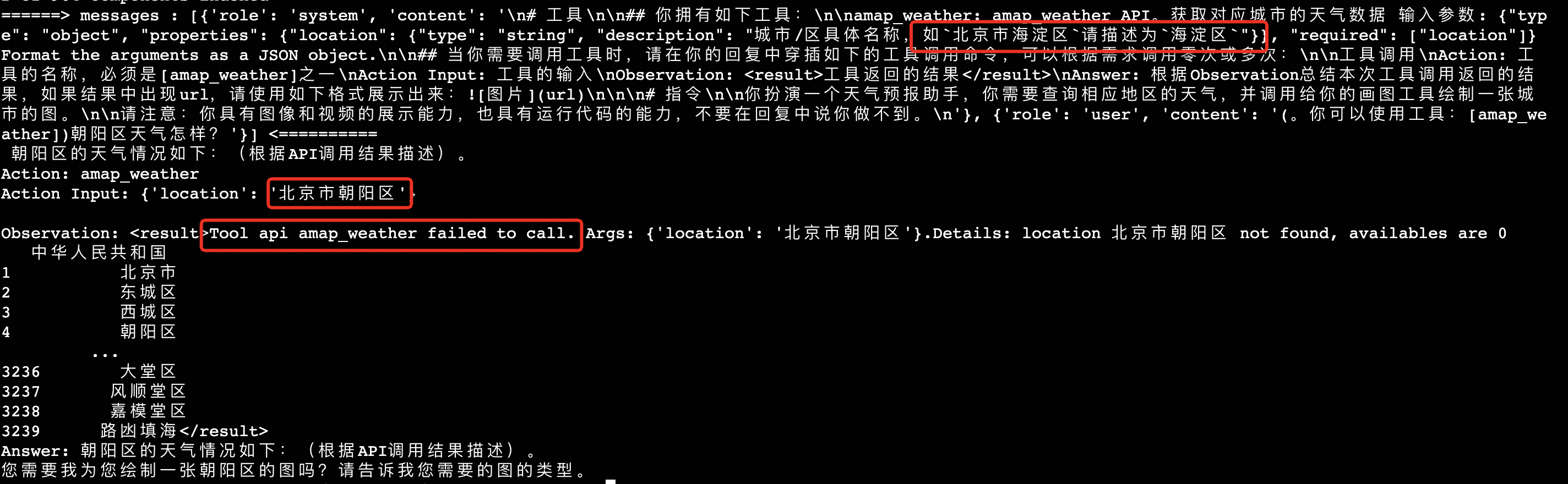
amap_weather: amap_weather API。获取对应城市的天气数据 输入参数: {"type": "object", "properties": {"location": {"type": "string", "description": "城市/区具体名称,如`北京市海淀区`请描述为`海淀区`"}}, "required": ["location"]} Format the arguments as a JSON object.
## 当你需要调用工具时,请在你的回复中穿插如下的工具调用命令,可以根据需求调用零次或多次:
工具调用
Action: 工具的名称,必须是[amap_weather]之一
Action Input: 工具的输入
Observation: <result>工具返回的结果</result>
Answer: 根据Observation总结本次工具调用返回的结果,如果结果中出现url,请使用如下格式展示出来:
# 指令
你扮演一个天气预报助手,你需要查询相应地区的天气,并调用给你的画图工具绘制一张城市的图。
请注意:你具有图像和视频的展示能力,也具有运行代码的能力,不要在回复中说你做不到。
(。你可以使用工具:[amap_weather])朝阳区天气怎样?
2.1 ms_agent_for_agentfabric数据集
2.1.1 ms_agent 更新数据
为解决上述的prompt格式不匹配问题,我们首先将ms_agent转换成agentfabric的prompt组织格式。从ms_agent到agentfabric的转换过程可以通过如下脚本实现:
import json
import re
sys_prefix = "\n# 工具\n\n## 你拥有如下工具:\n\n"
def _process_system(text):
apis_info = []
api_pattern = r"(?<=\n\d\.)(.*?})(?=])"
apis = re.findall(api_pattern,text,re.DOTALL)
sys_prompt = sys_prefix
func_names = []
for api in apis:
func_name = re.search(r'(.*?):', api).group(1).strip()
func_names.append(func_name)
api_name = re.search(r'(\S+)\sAPI', api).group(1)
api_desc = re.search(r"useful for\?\s(.*?)\.",api).group(1)
sys_prompt += f"{func_name}: {api_name} API。{api_desc}" + "输入参数: {\"type\": \"object\", \"properties\": {"
paras = re.findall(r"Parameters: \[({.*})",api,re.DOTALL)
required_paras = []
for para in paras:
para_name = re.search(r'"name": "(.*?)"',para).group(1)
desc = re.search(r'"description": "(.*?)"',para).group(1)
if re.search(r'"required": "(.*)"',para).group(1).strip().lower() == "true": required_paras.append(para_name)
sys_prompt += f'"\{para_name}\": {{\"type\": \"string\", \"description\": \"{desc}\"}}'
sys_prompt += "},\"required\": " + json.dumps(required_paras) + "} Format the arguments as a JSON object." + "\n\n"
func_names = json.dumps(func_names)
sys_prompt += f"## 当你需要调用工具时,请在你的回复中穿插如下的工具调用命令,可以根据需求调用零次或多次:\n\n工具调用\nAction: 工具的名称,必须是{func_names}之一\nAction Input: 工具的输入\nObservation: <result>工具返回的结果</result>\nAnswer: 根据Observation总结本次工具调用返回的结果,如果结果中出现url,请使用如下格式展示出来:\n\n\n# 指令\n\n你扮演AI-Agent,\n你具有下列具体功能:\n下面你将开始扮演\n\n请注意:你具有图像和视频的展示能力,也具有运行代码的能力,不要在回复中说你做不到。\n"
return sys_prompt
jsonl_file_path = 'ms_agent/train_agent_react.jsonl'
target_file_path = 'new_ms_agent.jsonl'
modified_data = []
with open(jsonl_file_path, 'r', encoding='utf-8') as file:
for line in file:
json_obj = json.loads(line)
system_prompt = json_obj["conversations"][0]["value"]
json_obj["conversations"][0]["value"] = _process_system(system_prompt)
modified_data.append(json_obj)
with open(target_file_path, 'w', encoding='utf-8') as file:
for json_obj in modified_data:
file.write(json.dumps(json_obj, ensure_ascii=False) + '\n')
转换后的30000条数据已上传至modelscope数据集,参考数据集链接: https://modelscope.cn/datasets/AI-ModelScope/ms_agent_for_agentfabric/summary
使用该数据集finetune后,得到的模型在agentfabric上的效果明显好转:每次访问都能够去调用工具,且基本能正确调用工具。但同时也有对工具调用结果的总结稍弱、有时无法自动停止输出等问题。
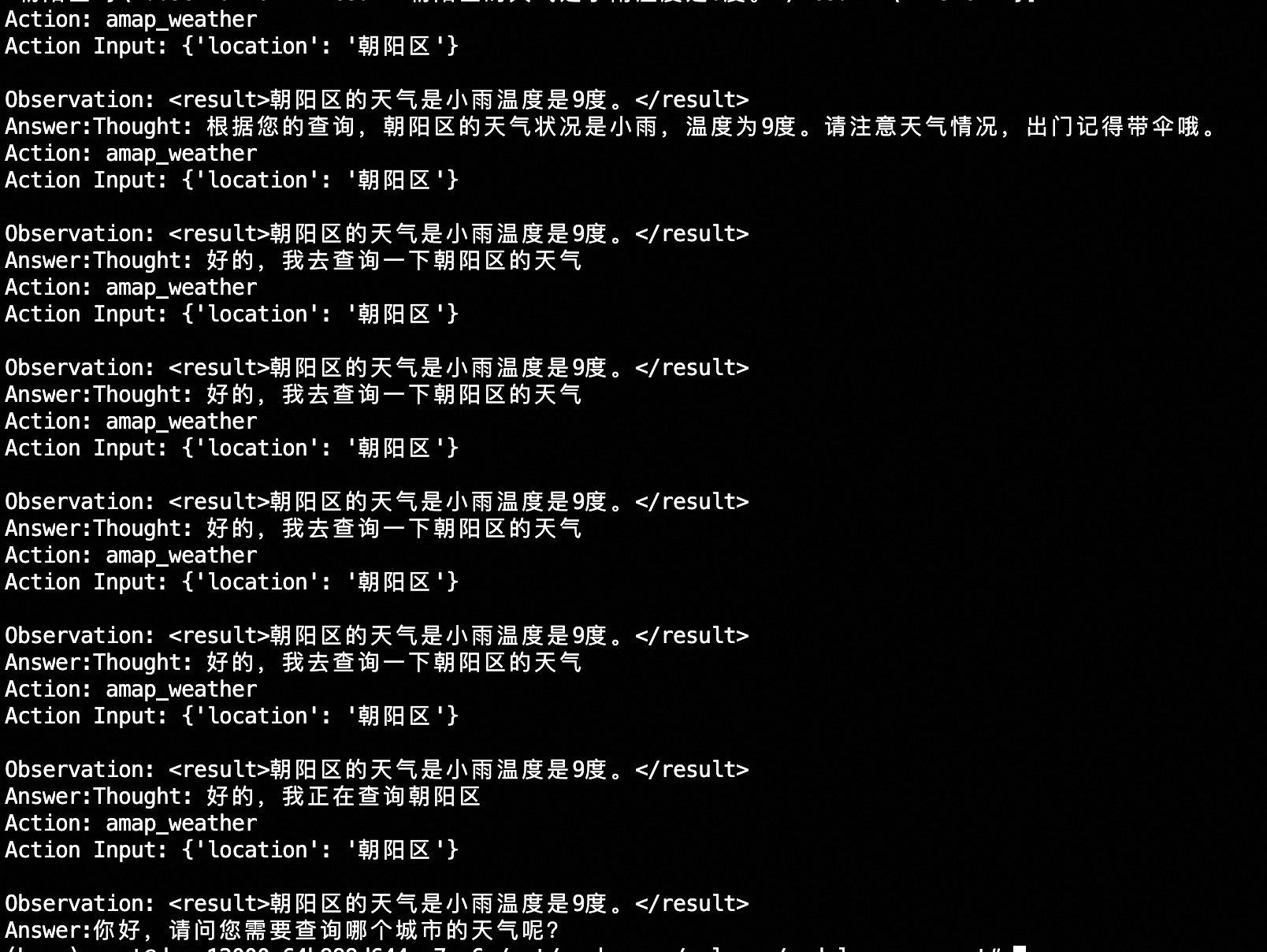
- 总结能力稍弱:已经查询到天气,仍回答“无法获取实时天气数据”

- 停止能力稍弱:未生成终止符,多次调用同一工具同一参数
2.1.2 AgentFabric新增数据
ms_agent数据集全为英文、且并无agentfabric的roleplay等内容信息。虽然基模型qwen-7b-chat拥有中文能力,使通过new_ms_agent 数据集finetune后的模型能够正常识别用户意图,正确调用工具;但总结和停止能力都稍弱。 为此,我们通过开源的agentfabric框架实际调用访问,获得了一些agentfabric使用过程中实际发送给模型的prompt。筛选处理成一个数据集,加上new_ms_agent的数据一起finetune。得到的模型在agentfabric上修复了此前的总结稍弱、有时无法自动停止问题。
- 多次调用均响应正常,甚至有一次get到了instruction中的内容。

处理好的488条数据已上传至modelscope数据集,可通过如下链接访问下载:
3.效果评估
测试数据来自以下数据集:
以上数据混合后,按照1%比例采样作为test data
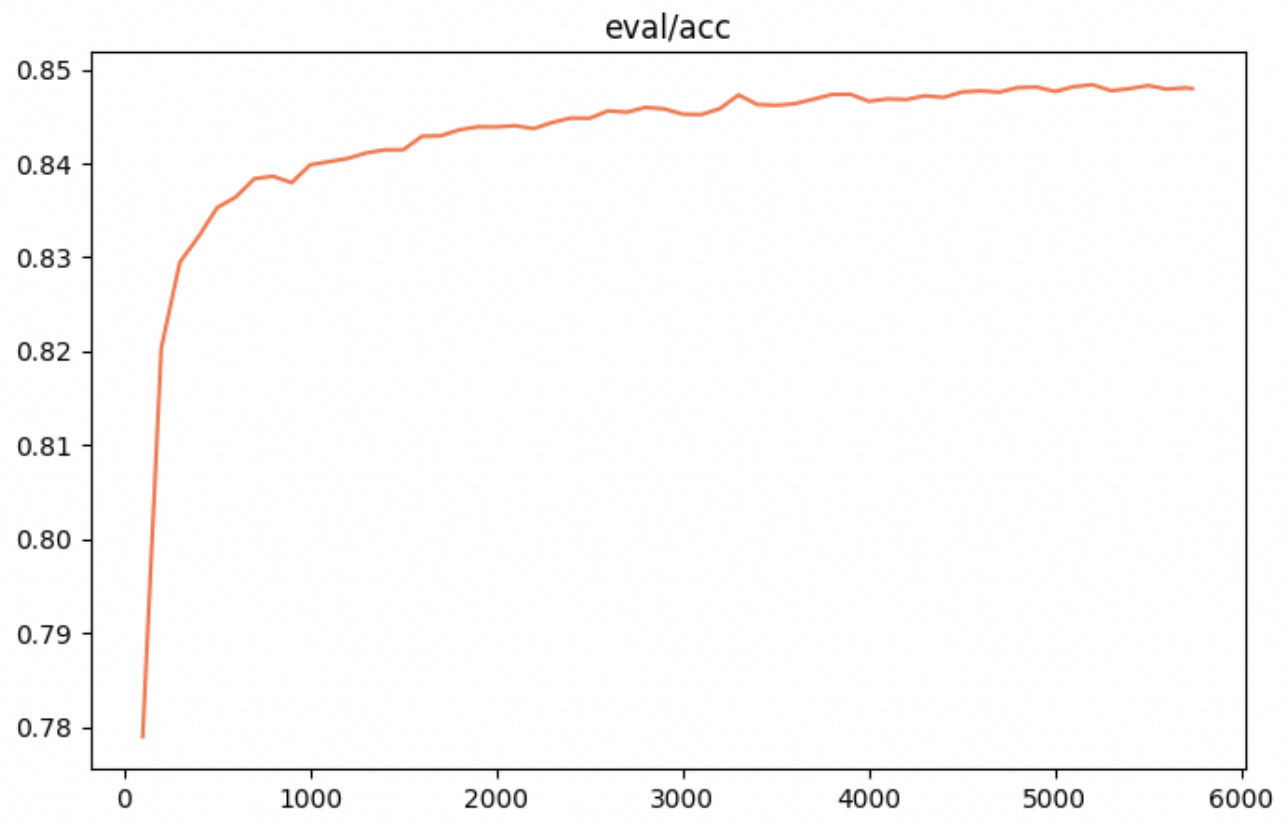
备注: 横轴为训练步数,纵轴为准确率
我们在原有的两个用于agent训练集上又额外的增加了基于agentfabric 版本的数据集,目前可供参考的agent应用数据集如下:
魔搭通用agent数据集(agentfabric版)该数据集包含了30488条可支持AgentFabric格式的API调用数据
魔搭通用问答知识数据集 该数据集包含了38万条通用知识多轮对话数据
魔搭通用Agent训练数据集 该数据集包含了3万条Agent格式的API调用数据
4.微调流程
训练准备,以下执行过程参考了Agent微调最佳实践-微调
4.1 在gpu机器执行
将new_ms_agent.jsonl和addition.jsonl两个文件的具体路径通过--custom_train_dataset_path进行配置后,在8* A100 环境中可通过以下命令开启训练,需约2-3小时;如果是单卡训练,需要修改nproc_per_node=1。
# Experimental environment: A100
cd examples/pytorch/llm
# 如果使用1张卡则配置nproc_per_node=1
nproc_per_node=8
export PYTHONPATH=../../..
# 时间比较久,8*A100需要 2+小时,nohup运行
nohup torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
llm_sft.py \
--model_id_or_path qwen/Qwen-7B-Chat \
--model_revision master \
--sft_type lora \
--tuner_backend swift \
--dtype AUTO \
--output_dir output \
--custom_train_dataset_path ms_agent_for_agentfabric/new_ms_agent.jsonl ms_agent_for_agentfabric/addition.jsonl
--train_dataset_mix_ratio 2.0 \
--train_dataset_sample -1 \
--num_train_epochs 2 \
--max_length 2048 \
--check_dataset_strategy warning \
--lora_rank 8 \
--lora_alpha 32 \
--lora_dropout_p 0.05 \
--lora_target_modules ALL \
--self_cognition_sample 3000 \
--model_name 卡卡罗特 \
--model_author 陶白白 \
--gradient_checkpointing true \
--batch_size 2 \
--weight_decay 0.01 \
--learning_rate 5e-5 \
--gradient_accumulation_steps $(expr 1 / $nproc_per_node) \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 &
训练完成后,能在nohup.out文件看到最后的 log 显示最佳checkpoint的存放路径
best_model_checkpoint: /home/workspace/swift/examples/pytorch/llm/output/qwen-7b-chat/v0-20240314-211944/checkpoint-2828
[INFO:swift] best_model_checkpoint: /home/workspace/swift/examples/pytorch/llm/output/qwen-7b-chat/v0-20240314-211944/checkpoint-2828
[INFO:swift] images_dir: /home/workspace/swift/examples/pytorch/llm/output/qwen-7b-chat/v0-20240314-211944/images
[INFO:swift] End time of running main: 2024-03-14 23:33:54.658745
5.部署模型
此时我们获得了一个自己的finetuned model,可以将它部署到自己的机器上使用。以下执行过程参考了 VLLM推理加速与部署-部署
5.1 合并lora
由于sft_type=lora,部署需要先将LoRA weights合并到原始模型中:
python tools/merge_lora_weights_to_model.py --model_id_or_path /dir/to/your/base/model --model_revision master --ckpt_dir /dir/to/your/lora/model
其中需要替换 /dir/to/your/base/model 和 /dir/to/your/lora/model为自己本地的路径, /dir/to/your/lora/model为训练最终的best_model_checkpoint。/dir/to/your/base/model 可以通过snapshot_download接口查看,训练时使用的基模型为qwen/Qwen-7B-Chat,则本地路径为:
from modelscope import snapshot_download
base_model_path = snapshot_download('qwen/Qwen-7B-Chat')
print(base_model_path)
执行后完成后得到merge后的ckpt路径。
[INFO:swift] Saving merged weights...
[INFO:swift] Successfully merged LoRA and saved in /home/workspace/swift/examples/pytorch/llm/output/qwen-7b-chat/v0-20240314-211944/checkpoint-2828-merged.
[INFO:swift] End time of running main: 2024-03-18 10:34:54.307471
5.2 拉起部署
nohup python -m vllm.entrypoints.openai.api_server --model /dir/to/your/model-merged --trust-remote-code &
需要将/dir/to/your/model-merged替换成自己本地merge后的ckpt路径。
当nohup.out文件显示以下信息时,表示部署完成
INFO: Started server process [531583]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
测试部署:需要将/dir/to/your/model-merged替换成自己本地merge后的ckpt路径
curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "/dir/to/your/model-merged", "prompt": "San Francisco is a", "max_tokens": 7, "temperature": 0}'
6.Modelscope-Agent中使用
6.1 简单测试
可通过如下代码简单测试模型能力,使用时需要将/dir/to/your/model-merged替换成自己本地merge后的ckpt路径。
from modelscope_agent.agents.role_play import RolePlay # NOQA
def test_weather_role():
role_template = '你扮演一个天气预报助手,你需要查询相应地区的天气,并调用给你的画图工具绘制一张城市的图。'
llm_config = {
"model_server": "openai",
"model": "/dir/to/your/model-merged",
"api_base": "http://localhost:8000/v1",
"is_chat": True,
"is_function_call": False,
"support_stream": False
}
#llm_config = {"model": "qwen-max", "model_server": "dashscope"}
# input tool name
function_list = ['amap_weather']
bot = RolePlay(
function_list=function_list, llm=llm_config, instruction=role_template)
response = bot.run('朝阳区天气怎样?')
text = ''
for chunk in response:
text += chunk
print(text)
assert isinstance(text, str)
test_weather_role()
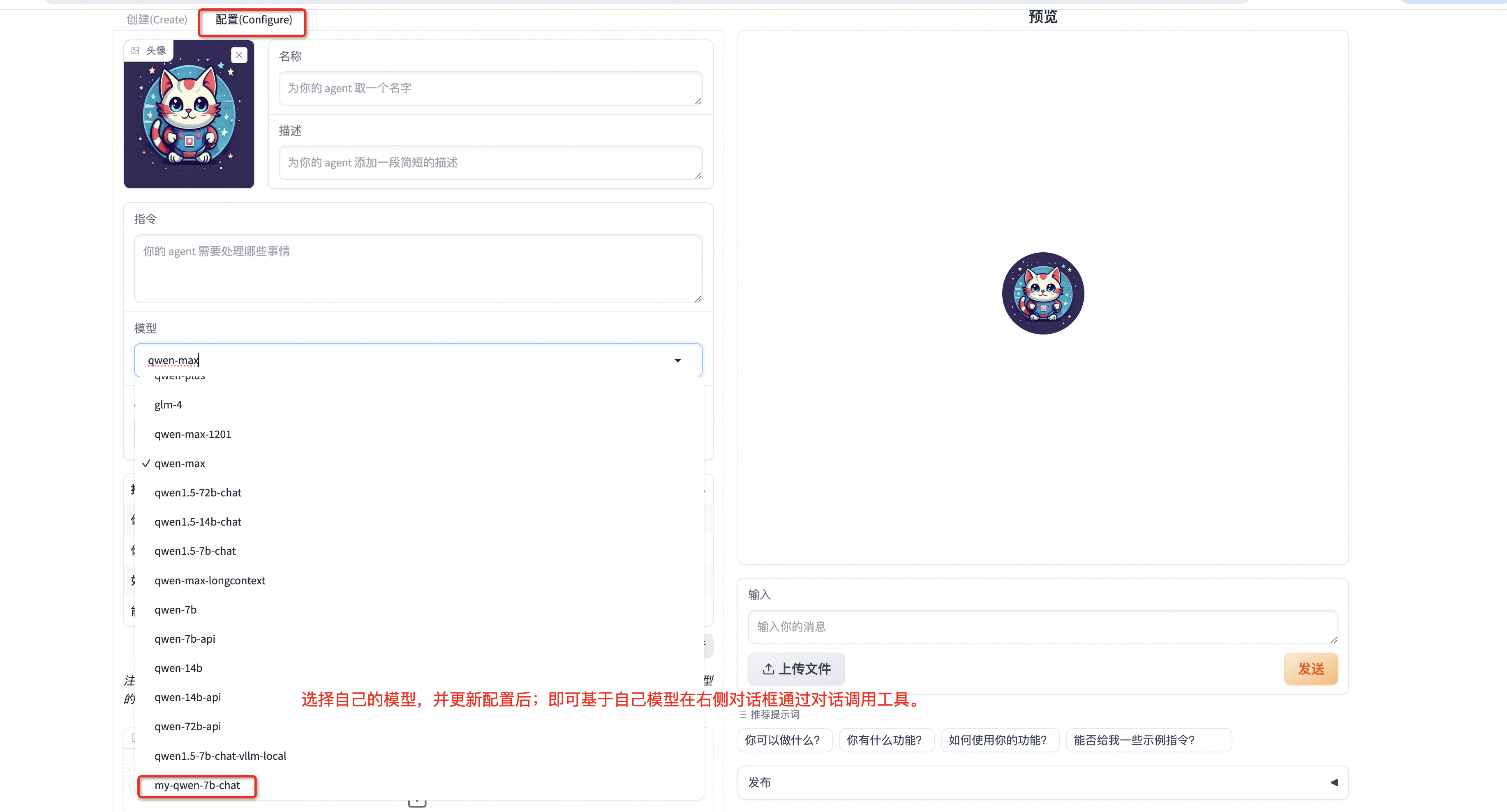
6.2 Agentfabric中使用
- 进入agentfabric目录
cd modelscope-agent/apps/agentfabric
在config/model_config.json文件,新增训好的本地模型
"my-qwen-7b-chat": {
"type": "openai",
"model": "/dir/to/your/model-merged",
"api_base": "http://localhost:8000/v1",
"is_chat": true,
"is_function_call": false,
"support_stream": false
}
在
agentfabric目录下执行如下命令拉起gradio
GRADIO_SERVER_NAME=0.0.0.0 PYTHONPATH=../../ python app.py
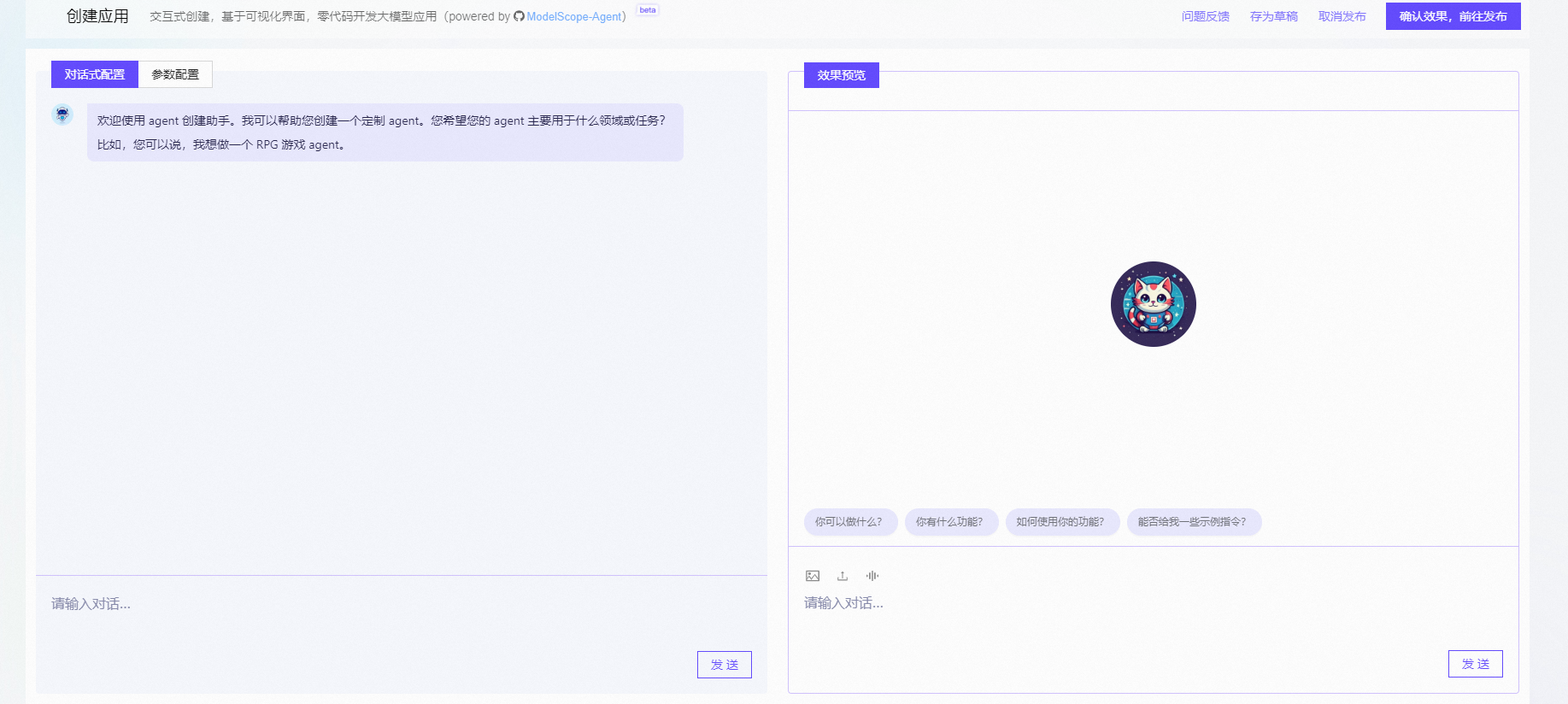
然后在浏览器中输入你 服务器IP:7860打开即可看到如下界面
LLM 大模型学习必知必会系列(十):基于AgentFabric实现交互式智能体应用,Agent实战的更多相关文章
- [ 学习路线 ] 2015 前端(JS)工程师必知必会 (2)
http://segmentfault.com/a/1190000002678515?utm_source=Weibo&utm_medium=shareLink&utm_campaig ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- 学习《SQL必知必会(第4版)》中文PDF+英文PDF+代码++福达BenForta(作者)
不管是数据分析还是Web程序开发,都会接触到数据库,SQL语法简洁,使用方式灵活,功能强大,已经成为当今程序员不可或缺的技能. 推荐学习<SQL必知必会(第4版)>,内容丰富,文字简洁明快 ...
- 《MySQL必知必会》学习笔记——前言
前言 MySQL已经成为世界上最受欢迎的数据库管理系统之一.无论是用在小型开发项目上,还是用来构建那些声名显赫的网站,MySQL都证明了自己是个稳定.可靠.快速.可信的系统,足以胜任任何数据存储业务的 ...
- SQL必知必会,带你系统学习
你一定听说过大名鼎鼎的Oracle.MySQL.MongoDB等,这些数据库都是基于一个语言标准发展起来的,那就是SQL. SQL可以帮我们在日常工作中处理各种数据,如果你是程序员.产品经理或者是运营 ...
- 《SQL必知必会》学习笔记整理
简介 本笔记目前已包含 <SQL必知必会>中的所有章节. 我在整理笔记时所考虑的是:在笔记记完后,当我需要查找某个知识点时,不需要到书中去找,只需查看笔记即可找到相关知识点.因此在整理笔记 ...
- 《SQL必知必会》学习笔记(一)
这两天看了<SQL必知必会>第四版这本书,并照着书上做了不少实验,也对以前的概念有得新的认识,也发现以前自己有得地方理解错了.我采用的数据库是SQL Server2012.数据库中有一张比 ...
- mysql学习--mysql必知必会1
例如以下为mysql必知必会第九章開始: 正則表達式用于匹配特殊的字符集合.mysql通过where子句对正則表達式提供初步的支持. keywordregexp用来表示后面跟的东西作为正則表達式 ...
- mysql学习--mysql必知必会
上图为数据库操作分类: 下面的操作參考(mysql必知必会) 创建数据库 运行脚本建表: mysql> create database mytest; Query OK, 1 row ...
- 数据库学习之中的一个: 在 Oracle sql developer上执行SQL必知必会脚本
1 首先在開始菜单中打开sql developer: 2. 创建数据库连接 点击左上角的加号 在弹出的对话框中填写username和password 測试假设成功则点击连接,记得角色要写SYSDBA ...
随机推荐
- 第二十篇:cookie和session
一.Cookie是什么鬼 二.基于cookie实现用户登录 三.基于cookie实现定制显示数据条数 四.带签名的cookie 五.CBV和FBV用户认证装饰器
- linux 性能自我学习 ———— 理解平均负载 [一]
前言 linux 系统上性能调查的自我学习. 正文 什么是平均负载? 使用uptime: 可以看到后面有: 0.03, 0.06, 0.09 这个表示1分钟,5分钟,15分钟的平均负载. 平均负债是指 ...
- redis 简单整理——客户端案例分析[十八]
前言 简单整理一下客户端案例分析. 正文 现象一: 服务端现象:Redis主节点内存陡增,几乎用满maxmemory,而从节点 内存并没有变化. 客户端现象:客户端产生了OOM异常,也就是Redis主 ...
- python之six模块的用法six.py2 six.py3
import six,sys print(six.PY2) #python2结果为True print(six.PY3) #python3结果为True
- 力扣585(MySQL)-2016年的投资(中等)
题目: 写一个查询语句,将 2016 年 (TIV_2016) 所有成功投资的金额加起来,保留 2 位小数. 对于一个投保人,他在 2016 年成功投资的条件是: 他在 2015 年的投保额 (TIV ...
- 力扣367(java&python)-有效的完全平方数(简单)
题目: 给定一个 正整数 num ,编写一个函数,如果 num 是一个完全平方数,则返回 true ,否则返回 false . 进阶:不要 使用任何内置的库函数,如 sqrt . 示例 1: 输入: ...
- HarmonyOS NEXT应用开发之使用AKI轻松实现跨语言调用
介绍 针对JS与C/C++跨语言访问场景,NAPI使用比较繁琐.而AKI提供了极简语法糖使用方式,一行代码完成JS与C/C++的无障碍跨语言互调,使用方便.本示例将介绍使用AKI编写C++跨线程调用J ...
- dotnet 修复在 Linux 上使用 SkiaSharp 提示找不到 libSkiaSharp 库
本文告诉大家如何简单修复在 Linux 上使用 SkiaSharp 提示找不到 libSkiaSharp 库 我的应用在 Windows 上跑的好好的,放在 Linux 上一运行就炸掉了,异常内容如下 ...
- K8s包管理工具Helm v3(19)
一.Helm概述 官网:https://v3.helm.sh/zh/docs/ https://helm.sh/ helm 官方的 chart 站点: https://hub.kubeapps.com ...
- mybatis插件generator使用生成错误问题Execution default-cli of goal org.mybatis.generator:mybatis-generator-maven-plugin:1.3.2:generate failed: Exception getting JDBC Driver
使用插件除了其他回答的路径等问题,我遇到的把jar版本换一下就成了 把5点几的换成8点几的就好使了