跟我学丨如何用鲲鹏服务器搭建Hadoop全分布式集群
摘要:今天教大家如何利用鲲鹏服务器搭建Hadoop全分布式集群,动起来···
一、Hadoop常见的三种运行模式
1、单机模式(独立模式)(Local或Standalone Mode)
默认情况下Hadoop就是处于该模式,用于开发和调式。不对配置文件进行修改。使用本地文件系统,而不是分布式文件系统。
Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
用于对MapReduce程序的逻辑进行调试,确保程序的正确。
2、伪分布式模式(Pseudo-Distrubuted Mode)
Hadoop的守护进程运行在本机机器,模拟一个小规模的集群,在一台主机模拟多主机。
Hadoop启动NameNode、DataNode、JobTracker、TaskTracker这些守护进程都在同一台机器上运行,是相互独立的Java进程。
在这种模式下,Hadoop使用的是分布式文件系统,各个作业也是由JobTraker服务,来管理的独立进程。在单机模式之上增加了代码调试功能,允许检查内存使用情况,HDFS输入输出,以及其他的守护进程交互。类似于完全分布式模式,因此,这种模式常用来开发测试Hadoop程序的执行是否正确。
3、全分布式集群模式(Full-Distributed Mode)
Hadoop的守护进程运行在一个集群上 Hadoop的守护进程运行在由多台主机搭建的集群上,是真正的生产环境。
- 下载并解压Hadoop、JDK安装包并配置好环境变量、节点域名解析、防火墙、端口等组成相互连通的网络。
- 进入Hadoop的解压目录,编辑hadoop-env.sh文件(注意不同版本后配置文件的位置有所变化)
- 编辑Hadoop中配置文件core-site.xml(Hadoop集群的特性,作用于全部进程及客户端)、hdfs-site.xml(配置HDFS集群的工作属性)、mapred-site.xml(配置MapReduce集群的属性)、yarn-site.xml四个核心配置文件
- 配置ssh,生成密钥,使到ssh可以免密码连接localhost,把各从节点生成的公钥添加到主节点的信任列表。
- 格式化HDFS后 使用./start-all.sh启动Hadoop集群
二、Hadoop常见组件
Hadoop由HDFS、Yarn、Mapreduce三个核心模块组成,分别负责分布式存储、资源分配和管理、分布式计算。
1、Hadoop-HDFS模块
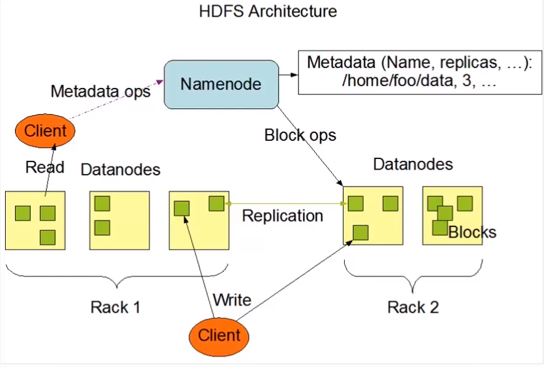
- HDFS:是一种分布式存储系统,采用Master和Slave的主从结构,主要由NameNode和DataNode组成。HDFS会将文件按固定大小切成若干块,分布式存储在所有DataNode中,每个文件块可以有多个副本,默认副本数为3。
- NameNode: Master节点,负责元数据的管理,处理客户端请求。
- DataNode: Slave节点,负责数据的存储和读写操作。
2、Hadoop-Yarn模块
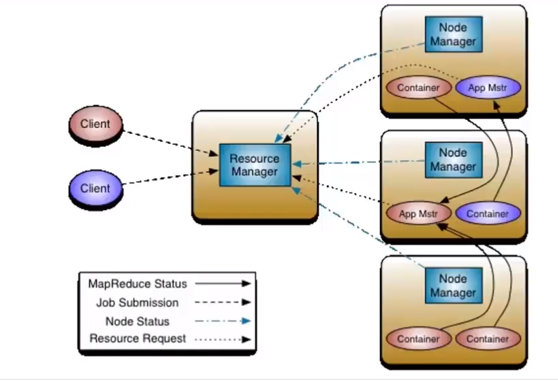
- Yarn:是一种分布式资源调度框架,采用Master和Slave的主从结构,主要由ResourceManager . ApplicationMaster和NodeManager组成,负责整个集群的资源管理和调度。
- ResourceManager:是一个全局的资源管理器,负责整个集群的资源管理和分配。
- ApplicationMaster:当用户提交应用程序时启动,负责向ResourceManager申请资源和应用程序的管理。
- NodeManager:运行在Slave节点,负责该节点的资源管理和使用。
- Container: Yarn的资源抽象,是执行具体应用的基本单位,任何一个Job或应用程序必须运行在一个或多个Container中。
3、Hadoop-Mapreduce模块
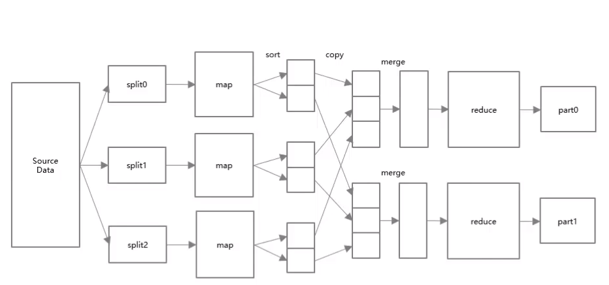
- Mapreduce:是一种分布式计算框架,主要由Map和Reduce两个阶段组成。支持将一个计算任务划分为多个子任务,分散到各集群节点并行计算。
- Map阶段:将初始数据分成多份,由多个map任务并行处理。
- Reduce阶段:收集多个Map任务的输出结果并进行合并,最终形成一个文件作为reduce阶段的结果。
全分布式集群模式(Full-Distributed Mode)搭建
【基本环境】
三台鲲鹏km1.2xlarge.8内存优化型 8vCPUs | 64GB CentOS 7.6 64bit with ARM CPU:Huawei Kunpeng 920 2.6GHz
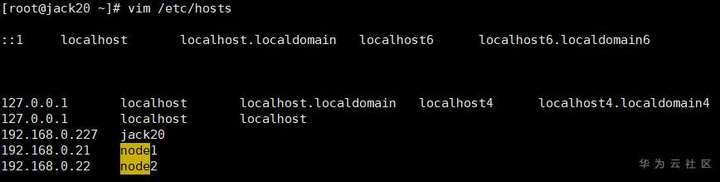
其中jack20节点作为NameNode, Node1、 Node2作为DataNode,而Node1也作为辅助NameNode ( Secondary NameNode )。

【基本流程】
- 下载并解压Hadoop、JDK安装包并配置好环境变量、节点域名解析、防火墙、端口
- 进入Hadoop的解压目录,编辑hadoop-env.sh文件(注意不同版本后配置文件的位置有所变化)
- 编辑Hadoop中配置文件core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml四个核心配置文件
- 配置ssh,生成密钥,使到ssh可以免密码连接localhost
- 格式化HDFS后 使用./start-all.sh启动Hadoop集群
关闭防火墙和selinux
(1)各个节点都执行命令关闭防火墙:
systemctl stop firewalld
systemctl disable firewalld
systemctl status firewalld

(2)关闭selinux
进入selinux的config文件,将selinux原来的强制模式(enforcing)修改为关闭模式(disabled)
setenforce 0getenforce
sed -i 's#SELINUX=enforcing#SELINUX=disabled#g' /etc/sysconfig/selinux
grep SELINUX=disabled /etc/sysconfig/selinux
cat /etc/sysconfig/selinux
1.安装openJDK-1.8.0
1.1. 下载安装openJDK-1.8.0
下载openJDK-1.8.0并安装到指定目录(如“/home”)。
进入目录:
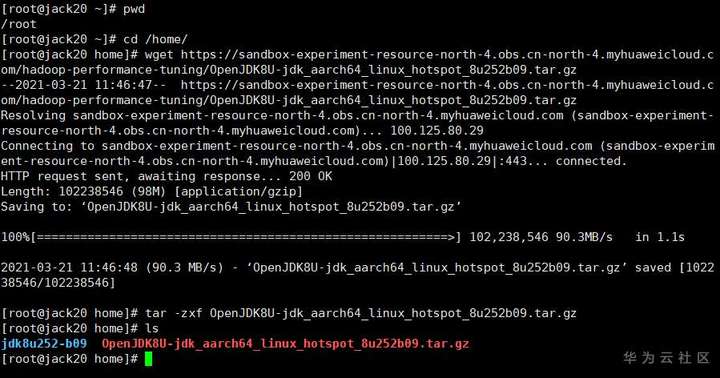
cd /home
下载openJDK-1.8.0并安装:
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/hadoop-performance-tuning/OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gz
#解压
tar -zxf OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gz
1.2. 配置环境变量
执行如下命令,打开/etc/profile文件:
vim /etc/profile
点击键盘"Shift+g"移动光标至文件末尾,单击键盘“i”键进入编辑模式,在代码末尾回车下一行,添加如下内容:
下一行,添加如下内容:
export JAVA_HOME=/home/jdk8u252-b09
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
添加完成,单击键盘ESC退出编辑,键入“:wq”回车保存并退出。

1.3. 环境变量生效
使环境变量生效:
source /etc/profile
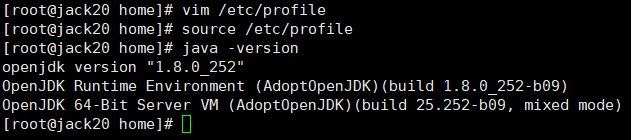
验证openJDK-1.8.0安装是否成功:
java -version
1.4.配置域名解析
vim /etc/hosts
2.安装dstat资源监控工具
yum install dstat-0.7.2-12.el7 -y
验证dstat是否安装成功:
dstat -V

3. 部署hadoop-3.1.1
3. 1. 获取hadoop-3.1.1软件包
①下载hadoop-3.1.1安装包到/home目录下:
cd /home
wget https://sandbox-experiment-resource-north-4.obs.cn-north-4.myhuaweicloud.com/hadoop-performance-tuning/hadoop-3.1.1.tar.gz
#解压hadoop-3.1.1
tar -zxvf hadoop-3.1.1.tar.gz
②建立软链接
ln -s hadoop-3.1.1 hadoop
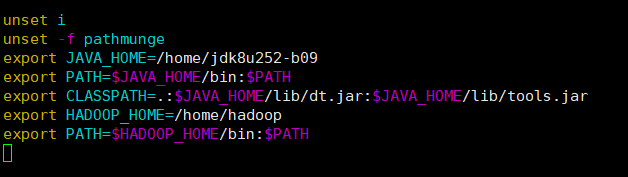
③配置hadoop环境变量,打开/etc/profile文件:
vim /etc/profile
点击键盘"Shift+g"移动光标至文件末尾,单击键盘“i”键进入编辑模式,在代码末尾回车下一行,添加如下内容:
export HADOOP_HOME=/home/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
添加完成,单击键盘ESC退出编辑,键入“:wq”回车保存并退出。
④使环境变量生效:
source /etc/profile
⑤验证hadoop安装是否成功:
hadoop version
执行结果如下图所示,表示安装成功:

3.2. 修改hadoop配置文件
hadoop所有的配置文件都在$HADOOP_HOME/etc/hadoop目录下,修改以下配置文件前,需要切换到"$HADOOP_HOME/etc/hadoop"目录。
cd $HADOOP_HOME/etc/hadoop/
①修改hdfs-env.xml
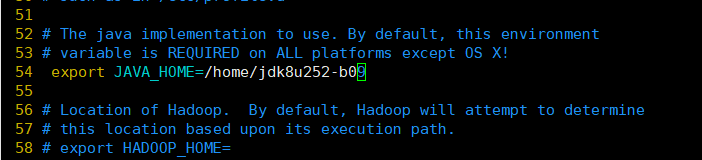
打开hadoop-env.sh文件:
vim hadoop-env.sh
找到hadoop-env.sh的第54行中的java目录(在命令模式下输入“:set nu”,查看行数),输入java的安装目录(),然后删除行左端“#”取消注释,并保存退出
② 修改core-site.xml
打开core-site.xml文件
vim core-site.xml
在<configuration></configuration>标签之间添加如下代码并保存退出
<property>
<name>fs.defaultFS</name>
<value>hdfs://jack20:9000/</value>
<description> 设定NameNode的主机名及端口</description>
</property> <property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp/hadoop-${user.name}</value>
<description>指定hadoop 存储临时文件的目录 </description>
</property> <property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
<description>配置该superUser允许通过代理的用户 </description>
</property> <property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
<description>配置该superUser允许通过代理用户所属组 </description>
</property>
③ 修改hdfs-site.xml,
打开hdfs-site.xml文件
vim hdfs-site.xml
在<configuration></configuration>标签之间添加如下代码并保存退出
<property>
<name>dfs.namenode.http-address</name>
<value>jack20:50070</value>
<description> NameNode 地址和端口 </description>
</property> <property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:50090</value>
<description> Secondary NameNode地址和端口 </description>
</property> <property>
<name>dfs.replication</name>
<value>3</value>
<description> 设定 HDFS 存储文件的副本个数,默认为3 </description>
</property> <property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoop/hadoop3.1/hdfs/name</value>
<description> NameNode用来持续存储命名空间和交换日志的本地文件系统路径</description>
</property> <property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoop/hadoop3.1/hdfs/data</value>
<description> DataNode在本地存储块文件的目录列表</description>
</property> <property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///home/hadoop/hadoop3.1/hdfs/namesecondary</value>
<description> 设置 Secondary NameNode存储临时镜像的本地文件系统路径。如果这是一个用逗号分隔的文件列表,则镜像将会冗余复制到所有目录
</description>
</property> <property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
<description>是否允许网页浏览HDFS文件</description>
</property> <property>
<name>dfs.stream-buffer-size</name>
<value>1048576</value>
<description> 默认是4 KB,作为Hadoop缓冲区,用于Hadoop读HDFS的文件和写HDFS的文件,
还有map的输出都用到了这个缓冲区容量(如果太大了map和reduce任务可能会内存溢出)
</description>
</property>
④修改mapred-site.xml
打开mapred-site.xml文件:
vim mapred-site.xml
在<configuration></configuration>标签之间添加如下代码并保存退出
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description> 指定MapReduce程序运行在Yarn上 </description>
</property> <property>
<name>mapreduce.jobhistory.address</name>
<value>jack20:10020</value>
<description> 指定历史服务器端地址和端口 </description>
</property> <property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>jack20:19888</value>
<description> 历史服务器web端地址和端口</description>
</property> <property>
<name>mapreduce.application.classpath</name>
<value>
/home/hadoop/etc/hadoop,
/home/hadoop/share/hadoop/common/*,
/home/hadoop/share/hadoop/common/lib/*,
/home/hadoop/share/hadoop/hdfs/*,
/home/hadoop/share/hadoop/hdfs/lib/*,
/home/hadoop/share/hadoop/mapreduce/*,
/home/hadoop/share/hadoop/mapreduce/lib/*,
/home/hadoop/share/hadoop/yarn/*,
/home/hadoop/share/hadoop/yarn/lib/*
</value>
</property> <property>
<name>mapreduce.map.memory.mb</name>
<value>6144</value>
<description> map container配置的内存的大小(调整到合适大小防止物理内存溢出)</description>
</property> <property>
<name>mapreduce.reduce.memory.mb</name>
<value>6144</value>
<description> reduce container配置的内存的大小(调整到合适大小防止物理内存溢出)</description>
</property> <property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property> <property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property> <property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/home/hadoop</value>
</property>
⑤修改yarn-site.xml
打开yarn-site.xml文件:
vim yarn-site.xml
在<configuration></configuration>标签之间添加如下代码并保存退出
<property>
<name>yarn.resourcemanager.hostname</name>
<value>jack20</value>
<description> 指定ResourceManager的主机名</description>
</property> <property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>53248</value>
<description> NodeManager总的可用物理内存。
注意:该参数是不可修改的,一旦设置,整个运行过程中不可动态修改。
该参数的默认值是8192MB,即使你的机器内存不够8192MB,YARN也会按照这些内存来使用,
因此,这个值通过一定要配置。
</description>
</property> <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description> 指定MapReduce走shuffle</description>
</property> <property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property> <property>
<name>yarn.resourcemanager.address</name>
<value>jack20:8032</value>
<description> 指定ResourceManager对客户端暴露的地址和端口,客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property> <property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>jack20:8030</value>
<description> 指定ResourceManager对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等</description>
</property> <property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>jack20:8031</value>
<description> 指定ResourceManager对NodeManager暴露的地址。NodeManager通过该地址向RM汇报心跳,领取任务等</description>
</property> <property>
<name>yarn.resourcemanager.admin.address</name>
<value>jack20:8033</value>
<description> 指定ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property> <property>
<name>yarn.resourcemanager.webapp.address</name>
<value>jack20:8088</value>
<description> 指定ResourceManager对外web UI地址。用户可通过该地址在浏览器中查看集群各类信息</description>
</property> <property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description> 开启日志聚集功能</description>
</property> <property>
<name>yarn.log.server.url</name>
<value>http://jack20:19888/jobhistory/logs</value>
<description> 设置日志聚集服务器地址</description>
</property> <property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
<description> 设置日志保留时间为7天</description>
</property>
⑥将各个节点加入到workers
echo jack20 > workers
echo node1 > workers
echo node2 > workers
⑦修改dfs和yarn的启动脚本,添加root用户权限
(1)打开start-dfs.sh和stop-dfs.sh文件:
vim /home/hadoop/sbin/start-dfs.sh
vim /home/hadoop/sbin/stop-dfs.sh
单击键盘“i”键进入编辑模式,在两个配置文件的第一行添加并保存退出:
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
(2)打开start-yarn.sh 和 stop-yarn.sh文件
vim /home/hadoop/sbin/start-yarn.sh
vim /home/hadoop/sbin/stop-yarn.sh
单击键盘“i”键进入编辑模式,在两个配置文件的第一行添加并保存退出:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
4.集群配置&节点间免密登录
(1)连通性测试
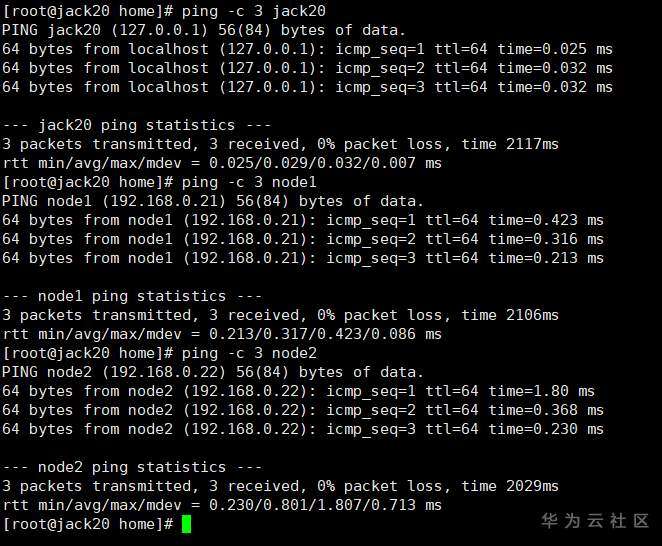
(2)从主节点同步各个节点域名解析文件
scp /etc/hosts node1:/etc/hosts
scp /etc/hosts node2:/etc/hosts
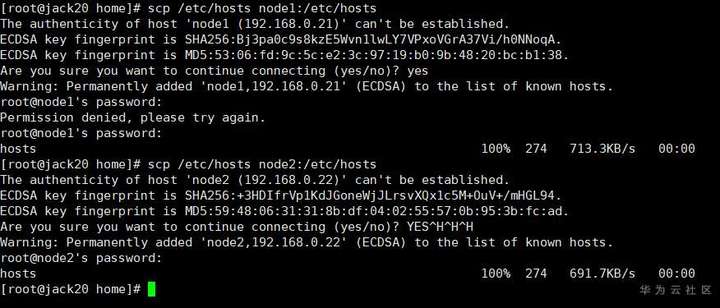
(3) 配置各节点间SSH免密登录
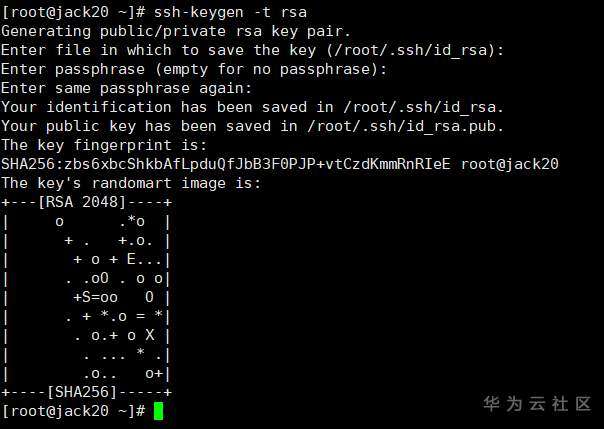
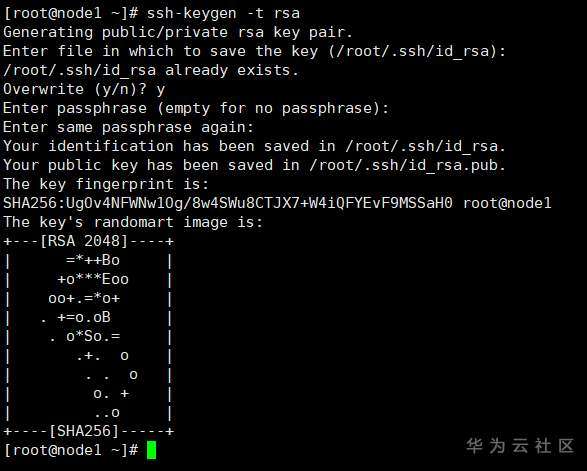
分别在三台服务器中输入命令生成私钥和公钥(提示输入时按回车即可):
ssh-keygen -t rsa
jack20:
node1:
node2:

然后分别在三台服务器上输入命令以复制公钥到服务器中:
ssh-copy-id -i ~/.ssh/id_rsa.pub root@jack20
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2
①继续连接:输入“yes”回车;
②输入密码(输入密码时,命令行窗口不会显示密码,输完之后直接回车)
查看所有协商的秘钥
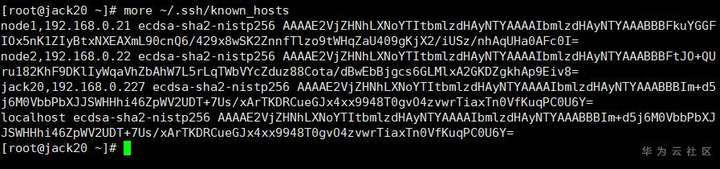
SSH免密登录测试:
Jack20->node1->node2->jack20->node2->node1->jack20
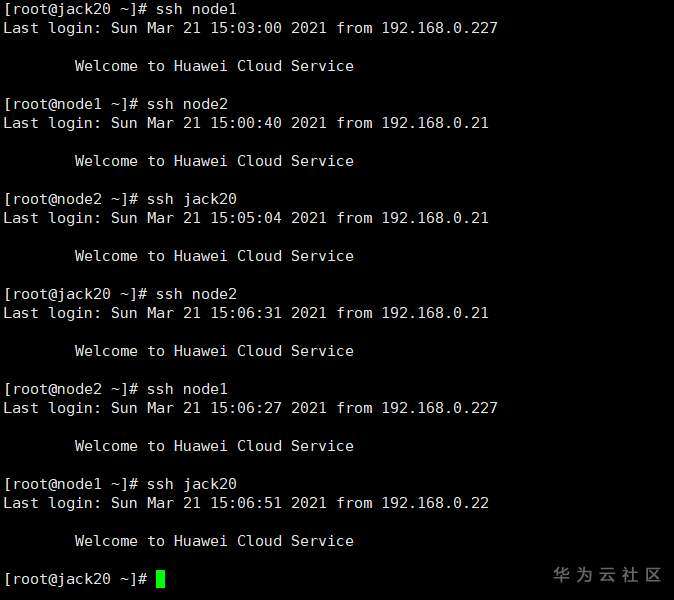
(4) 复制hadoop到各datanode并修改
把jack20的hadoop目录、jdk目录、/etc/hosts、/etc/profile复制到node1,node2节点
cd $HADOOP_HOME/..
#hadoop目录
scp -r hadoop node1:/home
scp -r hadoop node2:/home
#java目录
scp -r jdk8u252-b09 node1:/home
scp -r jdk8u252-b09 node2:/home
登录修改各服务器java和haoop环境变量
vim /etc/profile
点击键盘"Shift+g"移动光标至文件末尾,单击键盘“i”键进入编辑模式,在代码末尾回车下一行,添加如下内容并保存退出:
export JAVA_HOME=/home/jdk8u252-b09
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export HADOOP_HOME=/home/hadoop
export PATH=$HADOOP_HOME/bin:$PATH
使环境变量生效:
source /etc/profile
5.启动hadoop
注意:如果启动报错,请检查hadoop配置文件是否配置有误。
第一次启动前一定要格式化HDFS:
hdfs namenode -format
注意:提示信息的倒数第2行出现“>= 0”表示格式化成功,如图。在Linux中,0表示成功,1表示失败。因此,如果返回“1”,就应该好好分析前面的错误提示信息,一 般来说是前面配置文件和hosts文件的问题,修改后同步到其他节点上以保持相同环境,再接着执行格式化操作

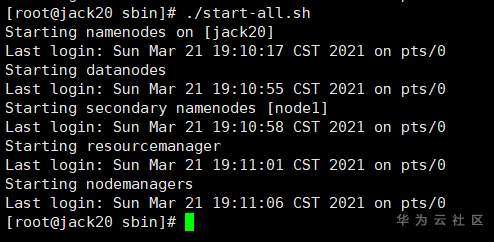
执行脚本命令群起节点
cd /home/hadoop/sbin
#群起节点
./start-all.sh
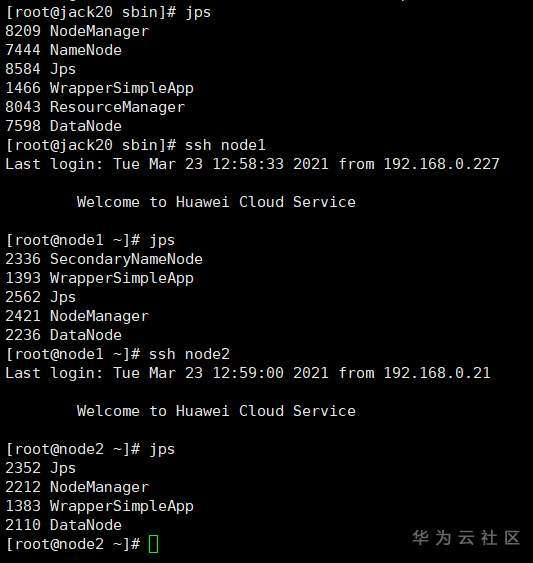
启动HDFS后,可以发现jack20节点作为NameNode, Node1、 Node2作为DataNode,而Node1也作为辅助NameNode ( Secondary NameNode )。可以通过jps命令在各节点上验证HDFS是否启动。jps 也是Windows中的命令,表示开启的Java进程如果出现下图所示的结果,就表示验证成功。
客户端Web访问测试:
(1)RMwebUI界面http://IP:8088
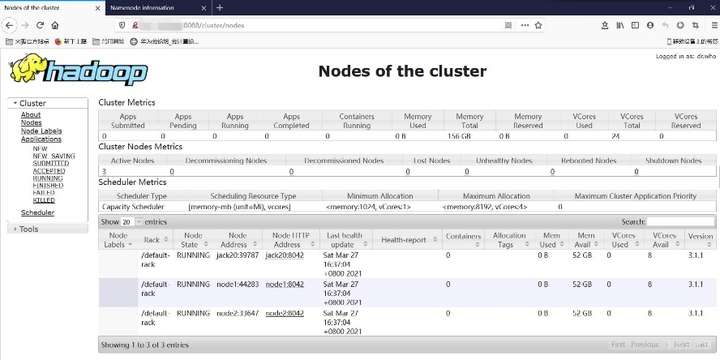
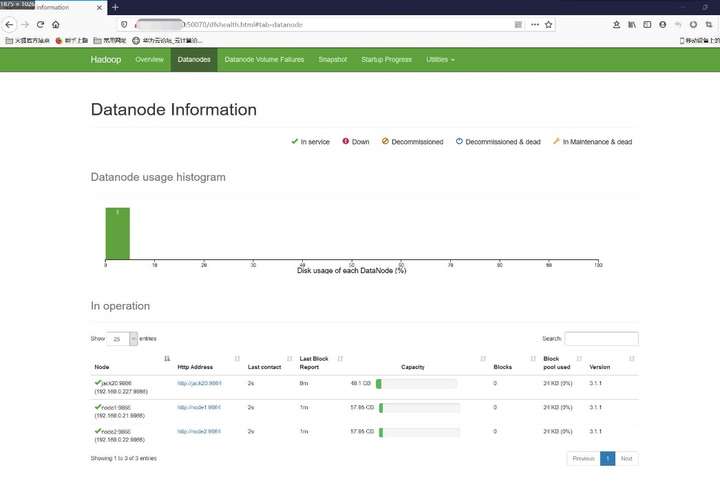
(2)NameNode的webUI界面http://IP:50070
6.集群基准测试
(1)使用Hadoop自带的WordCount例子/share/Hadoop/mapredu icehadoop-mapreduce-examples-3.1.1.jar验证集群
#创建目录,目录/data/wordcount用来存储Hadoop自带的WordCount例子的数据文件,运行这个MapReduce任务的结果输出到目录中的/output/wordcount文件中
hdfs dfs -mkdir -p /data/wordcount
hdfs dfs -mkdir -p /output/ #将本地文件上传到HDFS中(这里上传一个配置文件),执行如下命令
hdfs dfs -put /home/hadoop/etc/hadoop/core-site.xml /data/wordcount

可以查看,上传后的文件情况,执行如下命令
hdfs dfs -ls /data/wordcount

下面运行WordCount案例,执行如下命令
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.1.jar wordcount /data/wordcount /output/wordcount
(2)DFSIO测试
使用hadoop的DFSIO写入50个文件,每个文件1000M
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.1-tests.jar TestDFSIO -write -nrFiles 50 -filesize 1000
可以在RMwebUI界面查看当前任务的基本情况,包括内存使用量,CPU使用量等
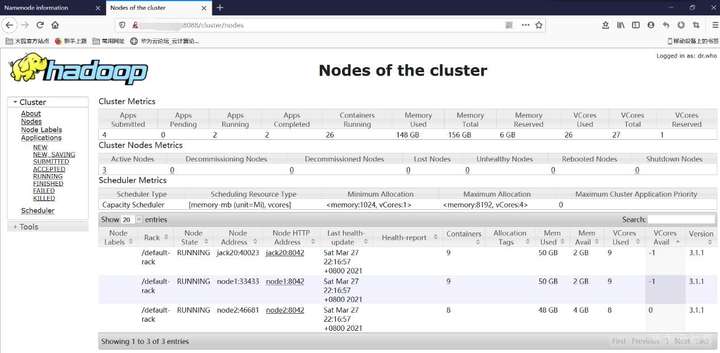
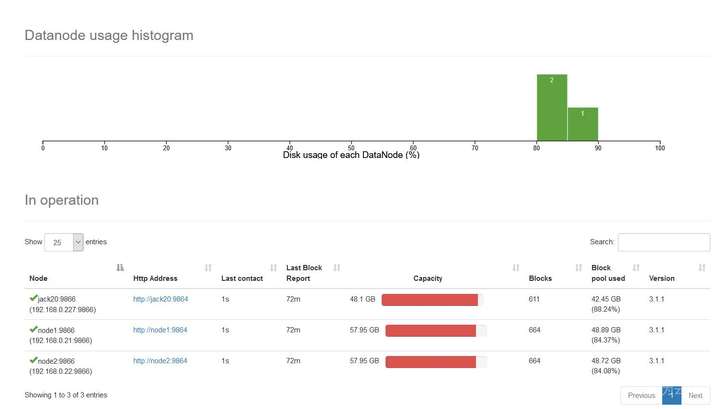
在NameNode的webUI界面查看刚刚DFSIO测试的各个节点HDFS占用情况
(3)计算圆周率的大小
hadoop jar /home/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.1-tests.jar pi 20 20
静静等待结果就可以~
本文分享自华为云社区《利用鲲鹏服务器快速搭建一个Hadoop全分布式集群笔记分享》,原文作者:Jack20。
跟我学丨如何用鲲鹏服务器搭建Hadoop全分布式集群的更多相关文章
- Redis集群搭建,伪分布式集群,即一台服务器6个redis节点
Redis集群搭建,伪分布式集群,即一台服务器6个redis节点 一.Redis Cluster(Redis集群)简介 集群搭建需要的环境 二.搭建集群 2.1Redis的安装 2.2搭建6台redi ...
- 阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建
准备: 两台配置CentOS 7.3的阿里云ECS服务器: hadoop-2.7.3.tar.gz安装包: jdk-8u77-linux-x64.tar.gz安装包: hostname及IP的配置: ...
- 使用三台云服务器搭建真正的Redis集群
三台云服务器搭建redis集群# 今天花了一天的时间弄集群redis:遇到了很多坑,从头开始吧 环境讲解: 两台配置:1核2G,另一台:1核1G: 操作系统:Centos 7.6 Redis:3.2. ...
- 在 Linux 内公网、云服务器搭建一套 K8s 集群
前言 本文讲述如果在 Linux 搭建内/公网 Kubernetes 集群的详细步骤,解决搭建过程中的问题. 准备工作 Linux CentOS 7.x 两台及以上,本文用的 7.6 本文配置默认是在 ...
- 阿里云ECS服务器部署HADOOP集群(二):HBase完全分布式集群搭建(使用外置ZooKeeper)
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 阿里云ECS服务器部署HADOOP集群(三):ZooKeeper 完全分布式集群搭建
本篇将在阿里云ECS服务器部署HADOOP集群(一):Hadoop完全分布式集群环境搭建的基础上搭建,多添加了一个 datanode 节点 . 1 节点环境介绍: 1.1 环境介绍: 服务器:三台阿里 ...
- 分布式集群中,设定时间同步服务器,以及ntpd与ntpdate的区别
什么时候配置时间同步? 当分布式集群配置好了以后,马上配置的是SSH无密钥配置,然后就是配置时间同步. 时间同步在集群中特别重要. 一:时间同步 1.时间同步 集群中必须有一个统一的时间 如果是内网, ...
- 030 分布式集群中,设定时间同步服务器,以及ntpd与ntpdate的区别
什么时候配置时间同步? 当分布式集群配置好了以后,马上配置的是SSH无密钥配置,然后就是配置时间同步. 时间同步在集群中特别重要. 一:时间同步 1.时间同步 集群中必须有一个统一的时间 如果是内网, ...
- [link] 构建负载均衡服务器之一 负载均衡与集群详解
一.什么是负载均衡 首先我们先介绍一下什么是负载均衡: 负载平衡(Load balancing)是一种计算机网络技术,用来在多个计算机(计算机集群).网络连接.CPU.磁盘驱动器或其他资源中分配负载, ...
- Solr系列二:solr-部署详解(solr两种部署模式介绍、独立服务器模式详解、SolrCloud分布式集群模式详解)
一.solr两种部署模式介绍 Standalone Server 独立服务器模式:适用于数据规模不大的场景 SolrCloud 分布式集群模式:适用于数据规模大,高可靠.高可用.高并发的场景 二.独 ...
随机推荐
- Subtree 题解
Subtree 题目大意 给定一颗树,你可以选出一些节点,你需要对于每个点求出在强制选这个点的情况下所有选择的点联通的方案数,对给定模数取模. 思路分析 对于这种求树上每一个点方案数的题目,首先考虑换 ...
- LLM在text2sql上的应用
一.前言: 目前,大模型的一个热门应用方向text2sql它可以帮助用户快速生成想要查询的SQL语句.那对于用户来说,大部分简单的sql都是正确的,但对于一些复杂逻辑来说,需要用户在产出SQL的基础上 ...
- Redis 6 学习笔记 2 —— 简单了解订阅和发布(Pub/Sub),JDK17环境下用Jedis 4.3.1连接Redis并模拟验证码发送
REDIS pubsub -- Redis中国用户组(CRUG) 什么是发布和订阅 Redis发布订阅是一种通信模式:发送者(Pub)发送消息,订阅者(Sub)接收消息.Redis客户端可以订阅任意数 ...
- LCT(link cut tree) 详细图解与应用
樱雪喵用时 3days 做了 ybtoj 的 3 道例题,真是太有效率了!!1 写死自己系列. 为了避免自己没学明白就瞎写东西误人子弟,这篇 Blog 拖到了现在. 图片基本沿用 OIwiki,原文跳 ...
- nginx参数调优能提升多少性能
前言 nginx安装后一般都会进行参数优化,网上找找也有很多相关文章,但是这些参数优化对Nginx性能会有多大影响?为此我做个简单的实验测试下这些参数能提升多少性能. 声明一下,测试流程比较简单,后端 ...
- 单个Nginx发布多个react静态页面
在有些网络环境中,端口是一种比较稀缺的资源,而我们又恰好有多个前端项目需要发布,我们可以采取将多个项目映射到同一个端口上面的方案加以解决. 本教程前端项目主要以react为主,部署在linux服务器上 ...
- 【scipy 基础】--线性代数
SciPy的linalg模块是SciPy库中的一个子模块,它提供了许多用于线性代数运算的函数和工具,如矩阵求逆.特征值.行列式.线性方程组求解等. 相比于NumPy的linalg模块,SciPy的li ...
- Redmi AC2100 路由器 官方固件允许IPv6外网访问下游设备
升级/降级 至 官方固件版本: 2.0.23 稳定版.操作入口在路由器常用设置-系统状态-升级检测处. 开启SSH权限.F12打开浏览器的开发者模式,并切换至终端选项卡,复制以下代码至终端处,并敲回车 ...
- ERP大作业进度(一)
ERP和进销存的区别 ERP(企业资源计划)和进销存(进货.销售和库存管理)是两个不同的概念,尽管它们在企业管理中通常存在交集.以下是它们之间的主要区别: 范围: ERP:ERP系统是一个综合性的.集 ...
- 重写Nacos服务发现逻辑动态修改远程服务IP地址
背景 还是先说下做这个的背景,开发环境上了K8S,所有的微服务都注册在K8S内的Nacos,注册地址为K8S内部虚拟IP,K8S内的服务之间相互调用没有问题,但是本机开发联调调用其他微服务就访问不到. ...